 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples to Fool Iris Recognition Systems
Jul 18, 2019
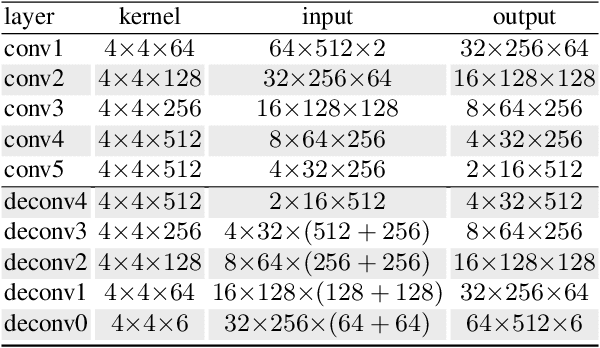
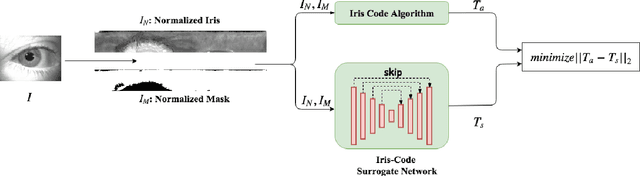
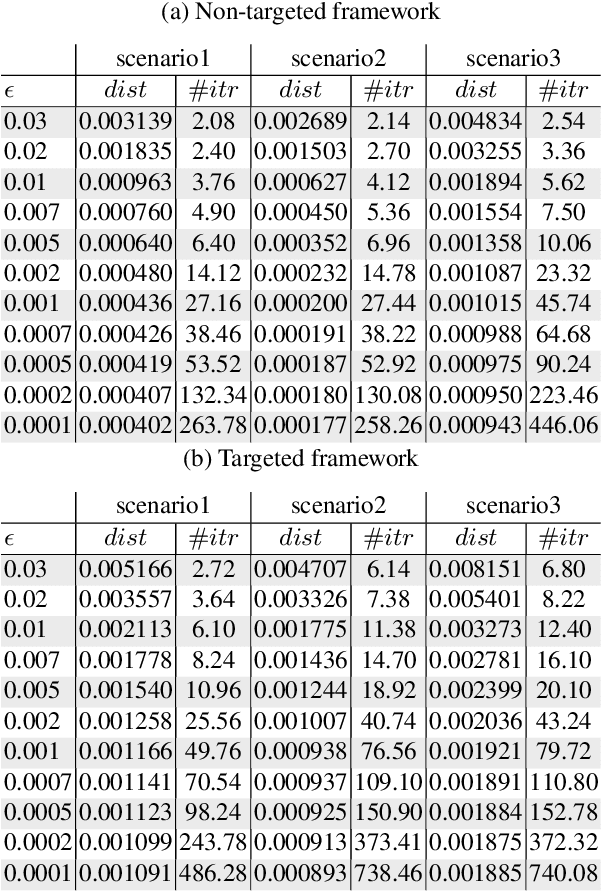
Adversarial examples have recently proven to be able to fool deep learning methods by adding carefully crafted small perturbation to the input space image. In this paper, we study the possibility of generating adversarial examples for code-based iris recognition systems. Since generating adversarial examples requires back-propagation of the adversarial loss, conventional filter bank-based iris-code generation frameworks cannot be employed in such a setup. Therefore, to compensate for this shortcoming, we propose to train a deep auto-encoder surrogate network to mimic the conventional iris code generation procedure. This trained surrogate network is then deployed to generate the adversarial examples using the iterative gradient sign method algorithm. We consider non-targeted and targeted attacks through three attack scenarios. Considering these attacks, we study the possibility of fooling an iris recognition system in white-box and black-box frameworks.
Learning to Authenticate with Deep Multibiometric Hashing and Neural Network Decoding
Mar 07, 2019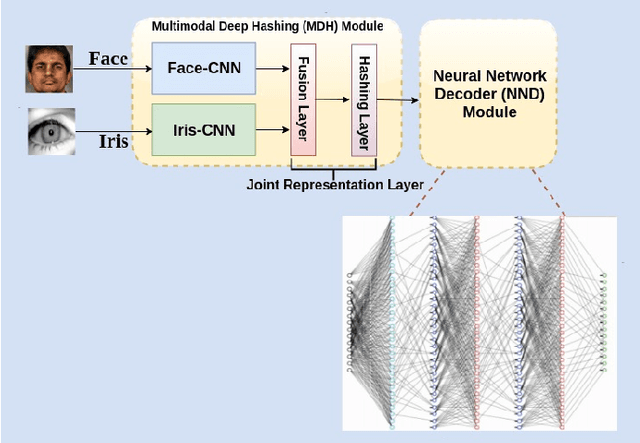
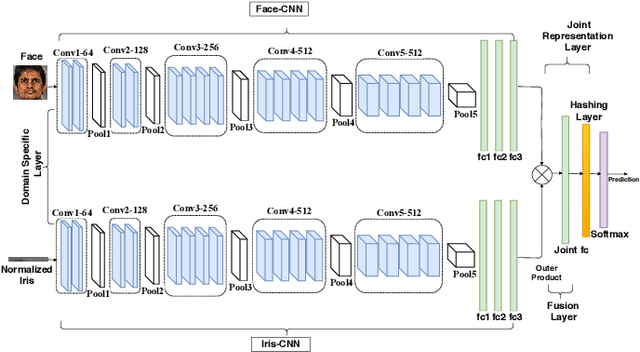
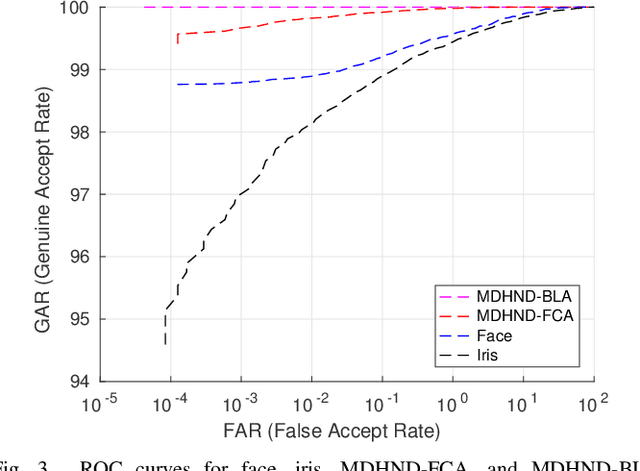
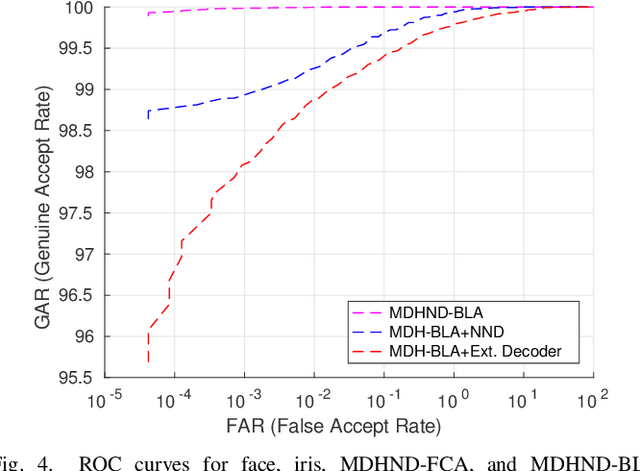
In this paper, we propose a novel multimodal deep hashing neural decoder (MDHND) architecture, which integrates a deep hashing framework with a neural network decoder (NND) to create an effective multibiometric authentication system. The MDHND consists of two separate modules: a multimodal deep hashing (MDH) module, which is used for feature-level fusion and binarization of multiple biometrics, and a neural network decoder (NND) module, which is used to refine the intermediate binary codes generated by the MDH and compensate for the difference between enrollment and probe biometrics (variations in pose, illumination, etc.). Use of NND helps to improve the performance of the overall multimodal authentication system. The MDHND framework is trained in 3 steps using joint optimization of the two modules. In Step 1, the MDH parameters are trained and learned to generate a shared multimodal latent code; in Step 2, the latent codes from Step 1 are passed through a conventional error-correcting code (ECC) decoder to generate the ground truth to train a neural network decoder (NND); in Step 3, the NND decoder is trained using the ground truth from Step 2 and the MDH and NND are jointly optimized. Experimental results on a standard multimodal dataset demonstrate the superiority of our method relative to other current multimodal authentication systems
GASL: Guided Attention for Sparsity Learning in Deep Neural Networks
Jan 15, 2019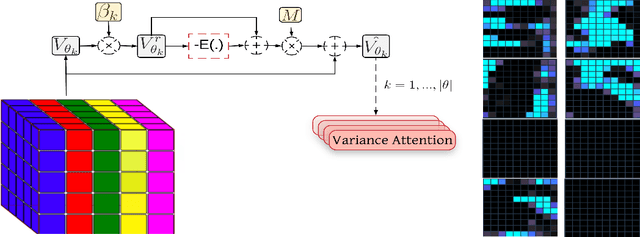
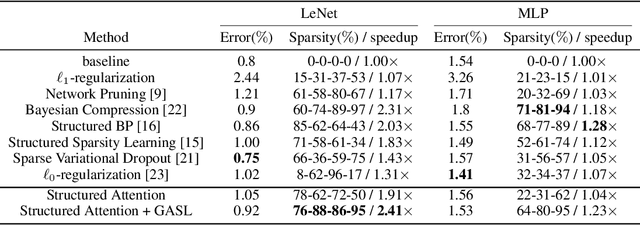
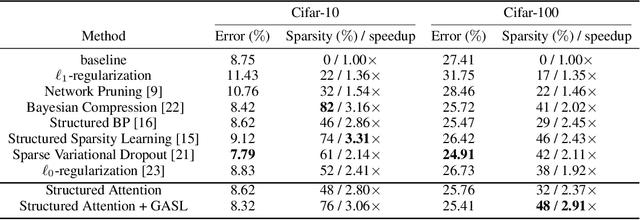
The main goal of network pruning is imposing sparsity on the neural network by increasing the number of parameters with zero value in order to reduce the architecture size and the computational speedup. In most of the previous research works, sparsity is imposed stochastically without considering any prior knowledge of the weights distribution or other internal network characteristics. Enforcing too much sparsity may induce accuracy drop due to the fact that a lot of important elements might have been eliminated. In this paper, we propose Guided Attention for Sparsity Learning (GASL) to achieve (1) model compression by having less number of elements and speed-up; (2) prevent the accuracy drop by supervising the sparsity operation via a guided attention mechanism and (3) introduce a generic mechanism that can be adapted for any type of architecture; Our work is aimed at providing a framework based on interpretable attention mechanisms for imposing structured and non-structured sparsity in deep neural networks. For Cifar-100 experiments, we achieved the state-of-the-art sparsity level and 2.91x speedup with competitive accuracy compared to the best method. For MNIST and LeNet architecture we also achieved the highest sparsity and speedup level.
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
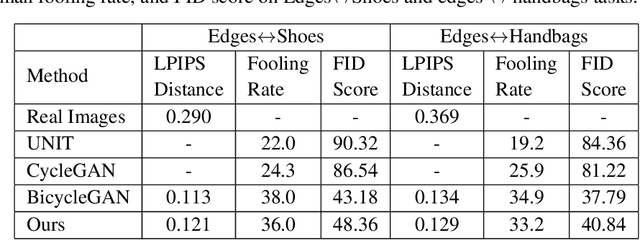
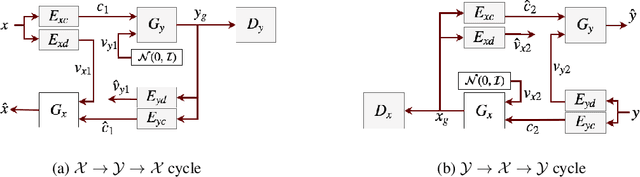
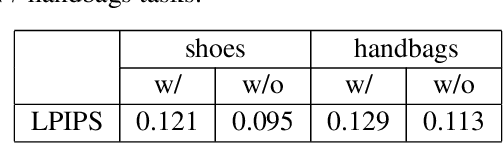
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Fast Geometrically-Perturbed Adversarial Faces
Sep 28, 2018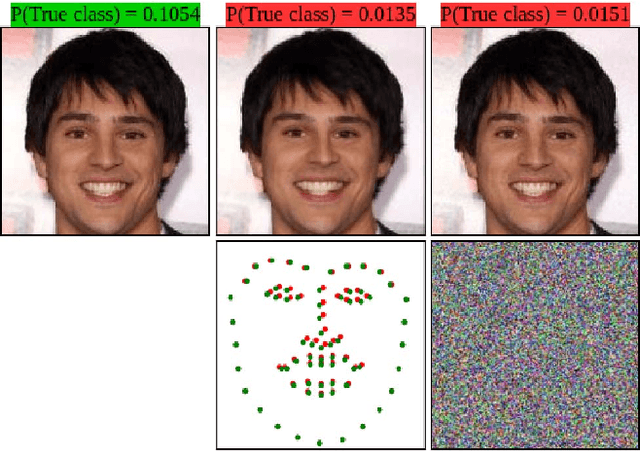
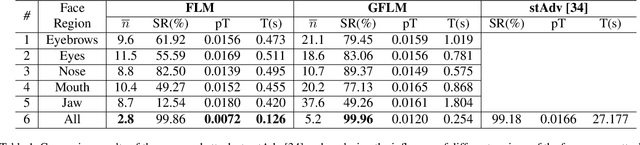
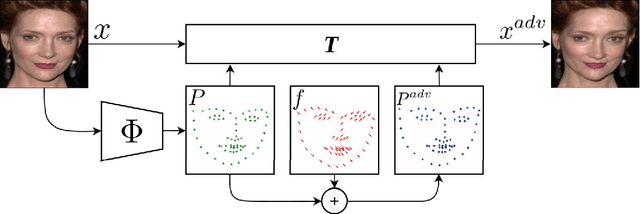
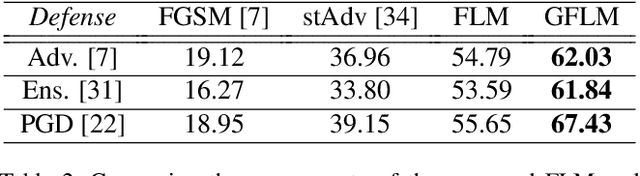
The state-of-the-art performance of deep learning algorithms has led to a considerable increase in the utilization of machine learning in security-sensitive and critical applications. However, it has recently been shown that a small and carefully crafted perturbation in the input space can completely fool a deep model. In this study, we explore the extent to which face recognition systems are vulnerable to geometrically-perturbed adversarial faces. We propose a fast landmark manipulation method for generating adversarial faces, which is approximately 200 times faster than the previous geometric attacks and obtains 99.86% success rate on the state-of-the-art face recognition models. To further force the generated samples to be natural, we introduce a second attack constrained on the semantic structure of the face which has the half speed of the first attack with the success rate of 99.96%. Both attacks are extremely robust against the state-of-the-art defense methods with the success rate of equal or greater than 53.59%. Code is available at https://github.com/alldbi/FLM
Deep Sketch-Photo Face Recognition Assisted by Facial Attributes
Jul 31, 2018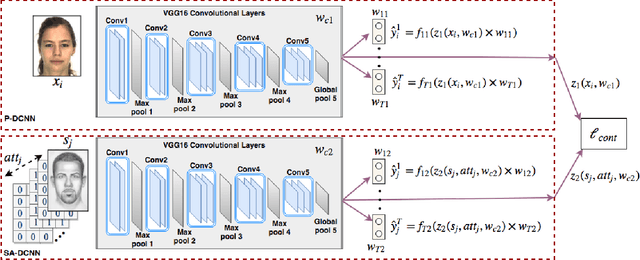

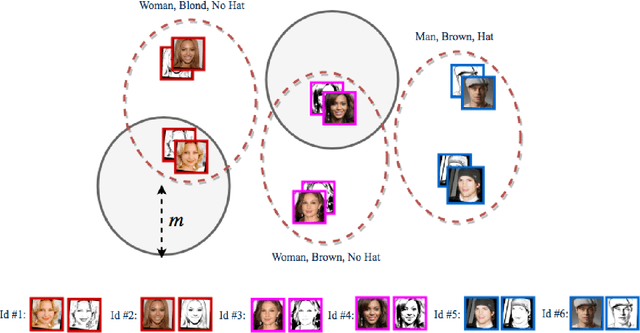
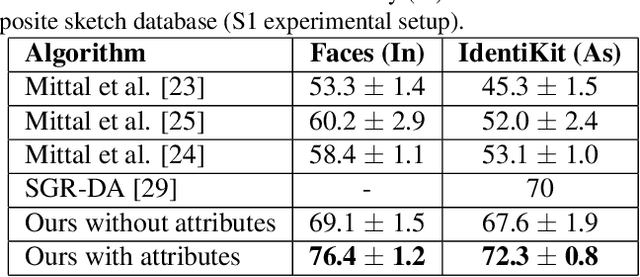
In this paper, we present a deep coupled framework to address the problem of matching sketch image against a gallery of mugshots. Face sketches have the essential in- formation about the spatial topology and geometric details of faces while missing some important facial attributes such as ethnicity, hair, eye, and skin color. We propose a cou- pled deep neural network architecture which utilizes facial attributes in order to improve the sketch-photo recognition performance. The proposed Attribute-Assisted Deep Con- volutional Neural Network (AADCNN) method exploits the facial attributes and leverages the loss functions from the facial attributes identification and face verification tasks in order to learn rich discriminative features in a common em- bedding subspace. The facial attribute identification task increases the inter-personal variations by pushing apart the embedded features extracted from individuals with differ- ent facial attributes, while the verification task reduces the intra-personal variations by pulling together all the fea- tures that are related to one person. The learned discrim- inative features can be well generalized to new identities not seen in the training data. The proposed architecture is able to make full use of the sketch and complementary fa- cial attribute information to train a deep model compared to the conventional sketch-photo recognition methods. Exten- sive experiments are performed on composite (E-PRIP) and semi-forensic (IIIT-D semi-forensic) datasets. The results show the superiority of our method compared to the state- of-the-art models in sketch-photo recognition algorithms
Prosodic-Enhanced Siamese Convolutional Neural Networks for Cross-Device Text-Independent Speaker Verification
Jul 31, 2018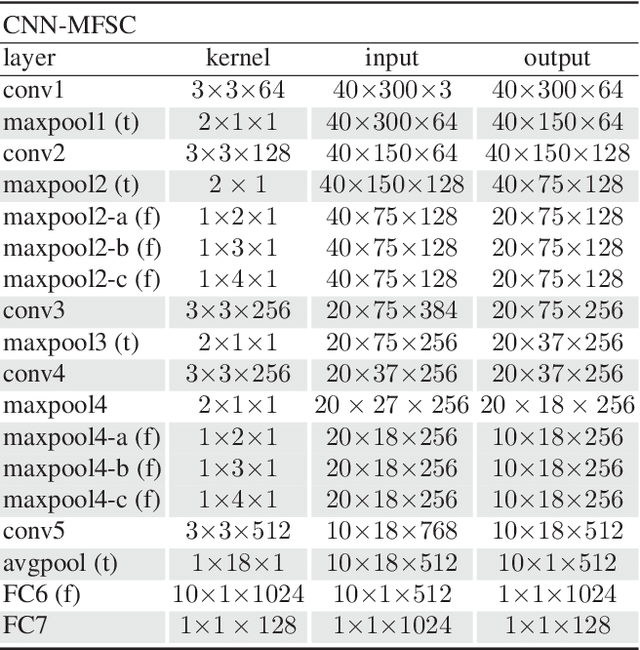
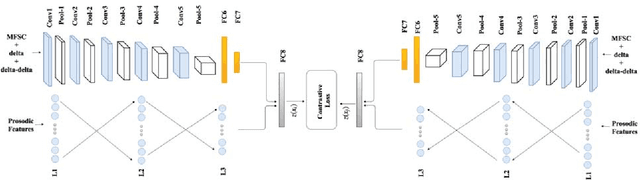
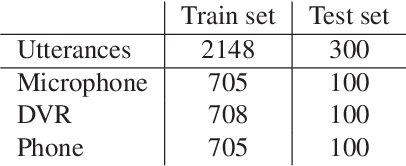
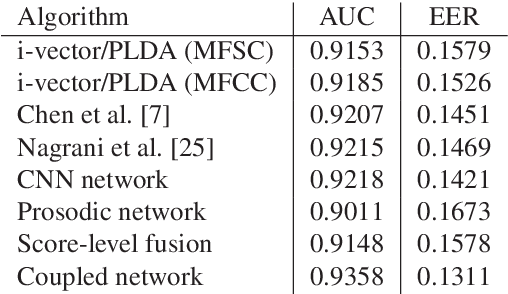
In this paper a novel cross-device text-independent speaker verification architecture is proposed. Majority of the state-of-the-art deep architectures that are used for speaker verification tasks consider Mel-frequency cepstral coefficients. In contrast, our proposed Siamese convolutional neural network architecture uses Mel-frequency spectrogram coefficients to benefit from the dependency of the adjacent spectro-temporal features. Moreover, although spectro-temporal features have proved to be highly reliable in speaker verification models, they only represent some aspects of short-term acoustic level traits of the speaker's voice. However, the human voice consists of several linguistic levels such as acoustic, lexicon, prosody, and phonetics, that can be utilized in speaker verification models. To compensate for these inherited shortcomings in spectro-temporal features, we propose to enhance the proposed Siamese convolutional neural network architecture by deploying a multilayer perceptron network to incorporate the prosodic, jitter, and shimmer features. The proposed end-to-end verification architecture performs feature extraction and verification simultaneously. This proposed architecture displays significant improvement over classical signal processing approaches and deep algorithms for forensic cross-device speaker verification.
ID Preserving Generative Adversarial Network for Partial Latent Fingerprint Reconstruction
Jul 31, 2018
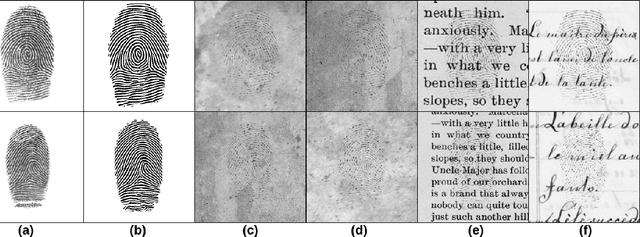

Performing recognition tasks using latent fingerprint samples is often challenging for automated identification systems due to poor quality, distortion, and partially missing information from the input samples. We propose a direct latent fingerprint reconstruction model based on conditional generative adversarial networks (cGANs). Two modifications are applied to the cGAN to adapt it for the task of latent fingerprint reconstruction. First, the model is forced to generate three additional maps to the ridge map to ensure that the orientation and frequency information is considered in the generation process, and prevent the model from filling large missing areas and generating erroneous minutiae. Second, a perceptual ID preservation approach is developed to force the generator to preserve the ID information during the reconstruction process. Using a synthetically generated database of latent fingerprints, the deep network learns to predict missing information from the input latent samples. We evaluate the proposed method in combination with two different fingerprint matching algorithms on several publicly available latent fingerprint datasets. We achieved the rank-10 accuracy of 88.02\% on the IIIT-Delhi latent fingerprint database for the task of latent-to-latent matching and rank-50 accuracy of 70.89\% on the IIIT-Delhi MOLF database for the task of latent-to-sensor matching. Experimental results of matching reconstructed samples in both latent-to-sensor and latent-to-latent frameworks indicate that the proposed method significantly increases the matching accuracy of the fingerprint recognition systems for the latent samples.
Attention-Based Guided Structured Sparsity of Deep Neural Networks
Jul 14, 2018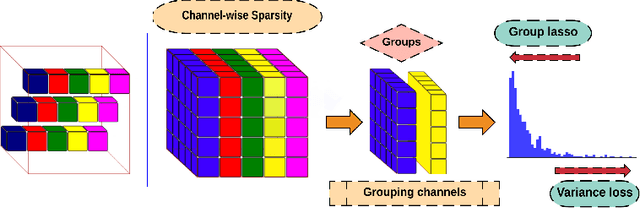
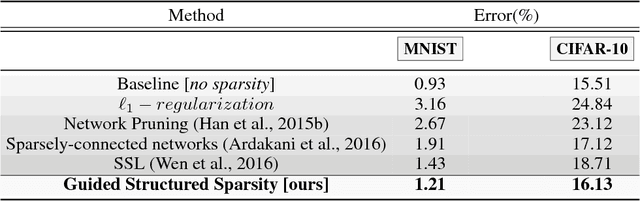
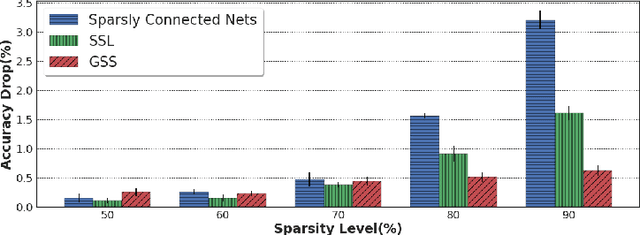
Network pruning is aimed at imposing sparsity in a neural network architecture by increasing the portion of zero-valued weights for reducing its size regarding energy-efficiency consideration and increasing evaluation speed. In most of the conducted research efforts, the sparsity is enforced for network pruning without any attention to the internal network characteristics such as unbalanced outputs of the neurons or more specifically the distribution of the weights and outputs of the neurons. That may cause severe accuracy drop due to uncontrolled sparsity. In this work, we propose an attention mechanism that simultaneously controls the sparsity intensity and supervised network pruning by keeping important information bottlenecks of the network to be active. On CIFAR-10, the proposed method outperforms the best baseline method by 6% and reduced the accuracy drop by 2.6x at the same level of sparsity.
Multi-Level Feature Abstraction from Convolutional Neural Networks for Multimodal Biometric Identification
Jul 03, 2018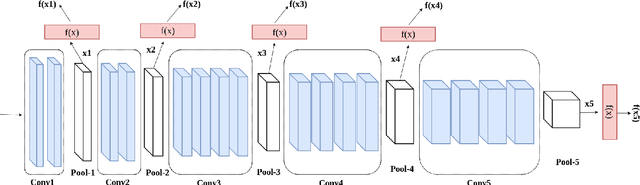
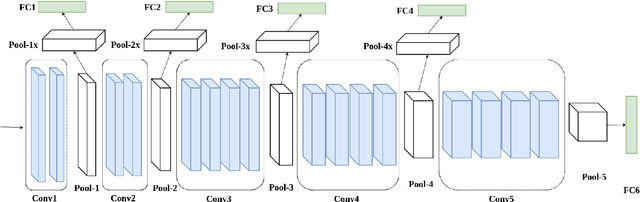
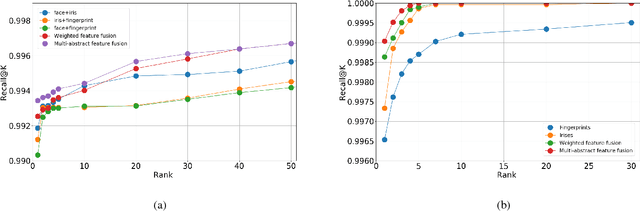
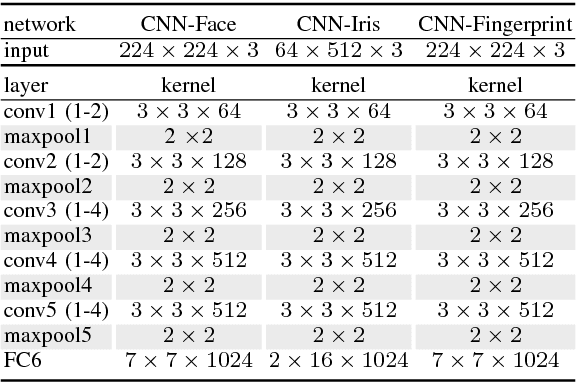
In this paper, we propose a deep multimodal fusion network to fuse multiple modalities (face, iris, and fingerprint) for person identification. The proposed deep multimodal fusion algorithm consists of multiple streams of modality-specific Convolutional Neural Networks (CNNs), which are jointly optimized at multiple feature abstraction levels. Multiple features are extracted at several different convolutional layers from each modality-specific CNN for joint feature fusion, optimization, and classification. Features extracted at different convolutional layers of a modality-specific CNN represent the input at several different levels of abstract representations. We demonstrate that an efficient multimodal classification can be accomplished with a significant reduction in the number of network parameters by exploiting these multi-level abstract representations extracted from all the modality-specific CNNs. We demonstrate an increase in multimodal person identification performance by utilizing the proposed multi-level feature abstract representations in our multimodal fusion, rather than using only the features from the last layer of each modality-specific CNNs. We show that our deep multi-modal CNNs with multimodal fusion at several different feature level abstraction can significantly outperform the unimodal representation accuracy. We also demonstrate that the joint optimization of all the modality-specific CNNs excels the score and decision level fusions of independently optimized CNNs.