 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images
Apr 12, 2019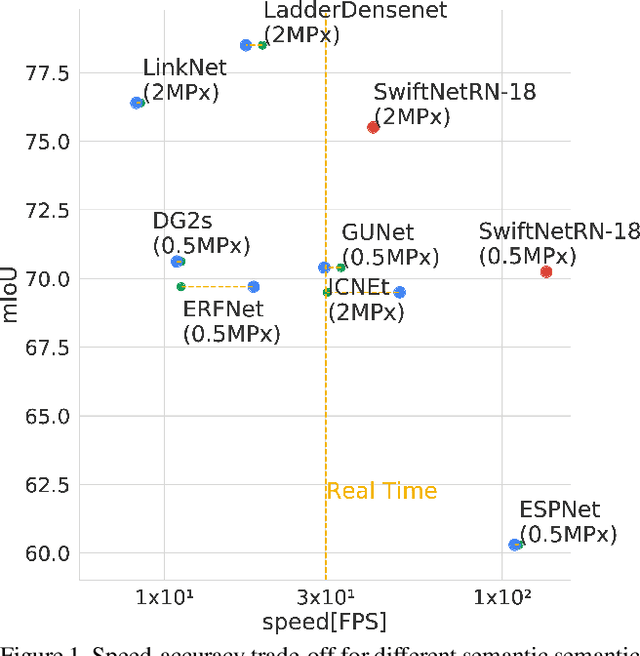
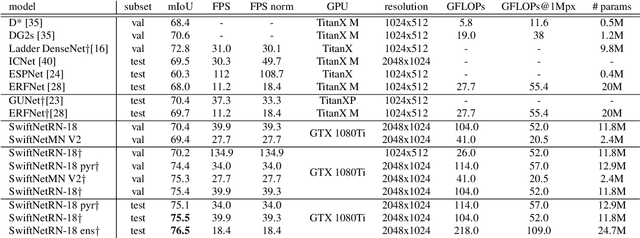
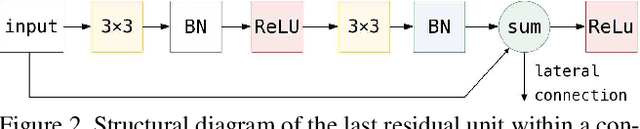
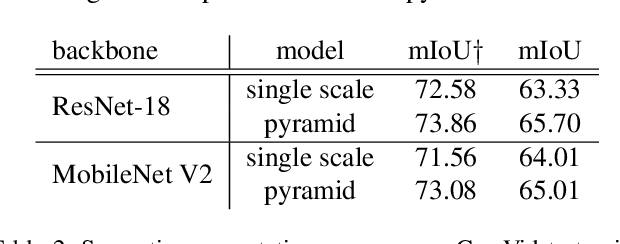
Recent success of semantic segmentation approaches on demanding road driving datasets has spurred interest in many related application fields. Many of these applications involve real-time prediction on mobile platforms such as cars, drones and various kinds of robots. Real-time setup is challenging due to extraordinary computational complexity involved. Many previous works address the challenge with custom lightweight architectures which decrease computational complexity by reducing depth, width and layer capacity with respect to general purpose architectures. We propose an alternative approach which achieves a significantly better performance across a wide range of computing budgets. First, we rely on a light-weight general purpose architecture as the main recognition engine. Then, we leverage light-weight upsampling with lateral connections as the most cost-effective solution to restore the prediction resolution. Finally, we propose to enlarge the receptive field by fusing shared features at multiple resolutions in a novel fashion. Experiments on several road driving datasets show a substantial advantage of the proposed approach, either with ImageNet pre-trained parameters or when we learn from scratch. Our Cityscapes test submission entitled SwiftNetRN-18 delivers 75.5% MIoU and achieves 39.9 Hz on 1024x2048 images on GTX1080Ti.
Discriminative out-of-distribution detection for semantic segmentation
Oct 01, 2018
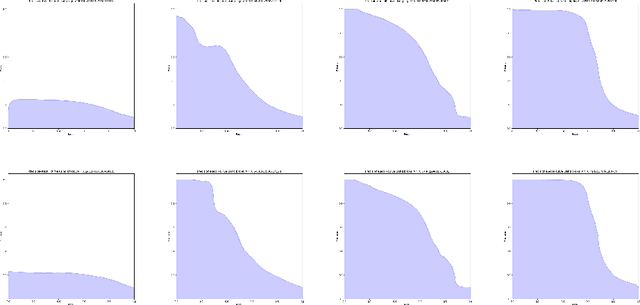


Most classification and segmentation datasets assume a closed-world scenario in which predictions are expressed as distribution over a predetermined set of visual classes. However, such assumption implies unavoidable and often unnoticeable failures in presence of out-of-distribution (OOD) input. These failures are bound to happen in most real-life applications since current visual ontologies are far from being comprehensive. We propose to address this issue by discriminative detection of OOD pixels in input data. Different from recent approaches, we avoid to bring any decisions by only observing the training dataset of the primary model trained to solve the desired computer vision task. Instead, we train a dedicated OOD model which discriminates the primary training set from a much larger "background" dataset which approximates the variety of the visual world. We perform our experiments on high resolution natural images in a dense prediction setup. We use several road driving datasets as our training distribution, while we approximate the background distribution with the ILSVRC dataset. We evaluate our approach on WildDash test, which is currently the only public test dataset that includes out-of-distribution images. The obtained results show that the proposed approach succeeds to identify out-of-distribution pixels while outperforming previous work by a wide margin.
Robust Semantic Segmentation with Ladder-DenseNet Models
Jun 09, 2018
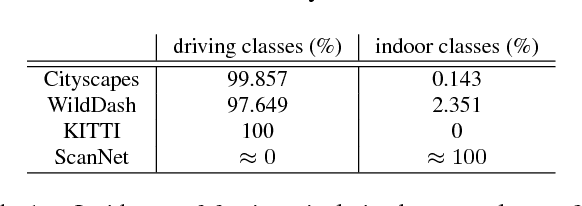


We present semantic segmentation experiments with a model capable to perform predictions on four benchmark datasets: Cityscapes, ScanNet, WildDash and KITTI. We employ a ladder-style convolutional architecture featuring a modified DenseNet-169 model in the downsampling datapath, and only one convolution in each stage of the upsampling datapath. Due to limited computing resources, we perform the training only on Cityscapes Fine train+val, ScanNet train, WildDash val and KITTI train. We evaluate the trained model on the test subsets of the four benchmarks in concordance with the guidelines of the Robust Vision Challenge ROB 2018. The performed experiments reveal several interesting findings which we describe and discuss.
Second Croatian Computer Vision Workshop (CCVW 2013)
Nov 03, 2013Proceedings of the Second Croatian Computer Vision Workshop (CCVW 2013, http://www.fer.unizg.hr/crv/ccvw2013) held September 19, 2013, in Zagreb, Croatia. Workshop was organized by the Center of Excellence for Computer Vision of the University of Zagreb.
Classifying Traffic Scenes Using The GIST Image Descriptor
Oct 01, 2013
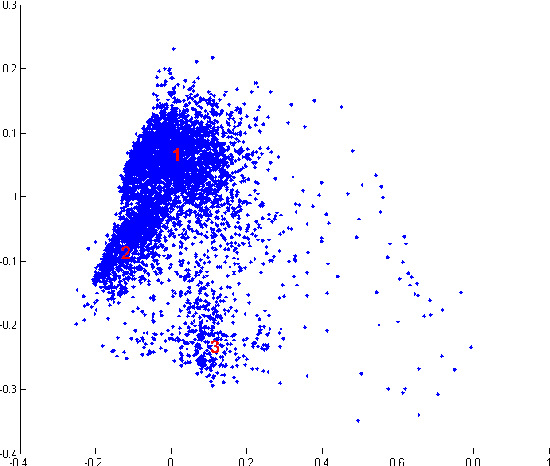


This paper investigates classification of traffic scenes in a very low bandwidth scenario, where an image should be coded by a small number of features. We introduce a novel dataset, called the FM1 dataset, consisting of 5615 images of eight different traffic scenes: open highway, open road, settlement, tunnel, tunnel exit, toll booth, heavy traffic and the overpass. We evaluate the suitability of the GIST descriptor as a representation of these images, first by exploring the descriptor space using PCA and k-means clustering, and then by using an SVM classifier and recording its 10-fold cross-validation performance on the introduced FM1 dataset. The obtained recognition rates are very encouraging, indicating that the use of the GIST descriptor alone could be sufficiently descriptive even when very high performance is required.
Multiclass Road Sign Detection using Multiplicative Kernel
Oct 01, 2013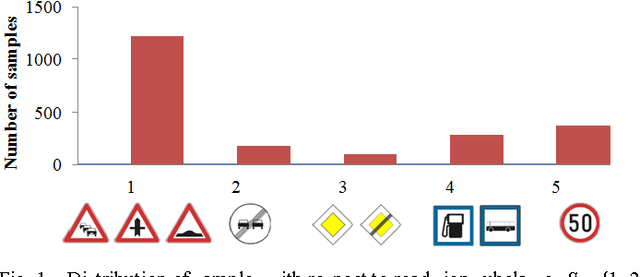

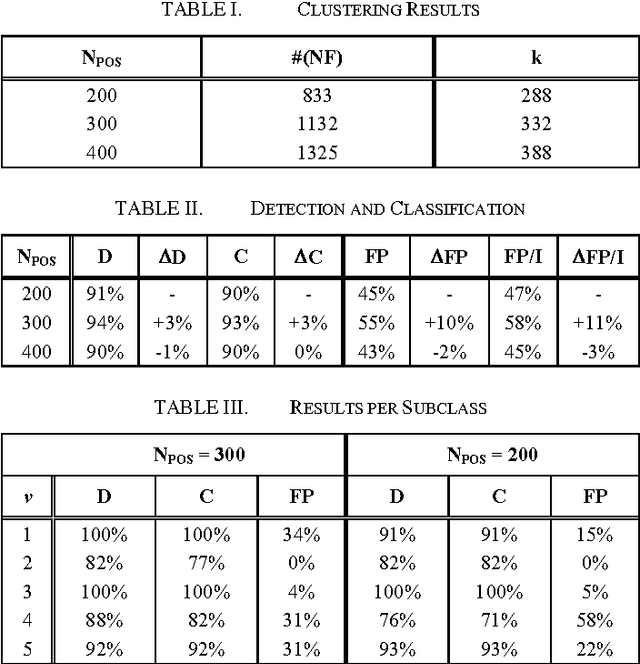
We consider the problem of multiclass road sign detection using a classification function with multiplicative kernel comprised from two kernels. We show that problems of detection and within-foreground classification can be jointly solved by using one kernel to measure object-background differences and another one to account for within-class variations. The main idea behind this approach is that road signs from different foreground variations can share features that discriminate them from backgrounds. The classification function training is accomplished using SVM, thus feature sharing is obtained through support vector sharing. Training yields a family of linear detectors, where each detector corresponds to a specific foreground training sample. The redundancy among detectors is alleviated using k-medoids clustering. Finally, we report detection and classification results on a set of road sign images obtained from a camera on a moving vehicle.
A Novel Georeferenced Dataset for Stereo Visual Odometry
Oct 01, 2013
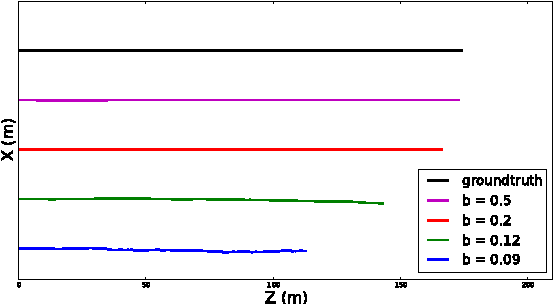
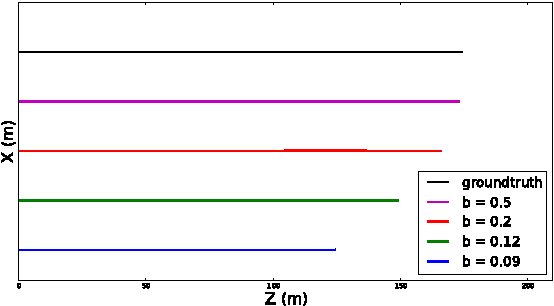
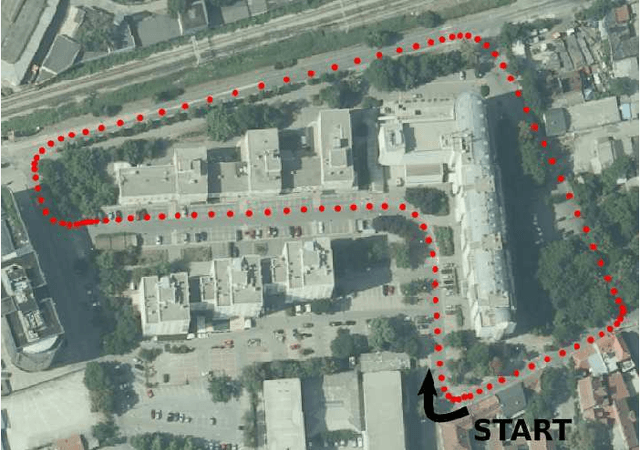
In this work, we present a novel dataset for assessing the accuracy of stereo visual odometry. The dataset has been acquired by a small-baseline stereo rig mounted on the top of a moving car. The groundtruth is supplied by a consumer grade GPS device without IMU. Synchronization and alignment between GPS readings and stereo frames are recovered after the acquisition. We show that the attained groundtruth accuracy allows to draw useful conclusions in practice. The presented experiments address influence of camera calibration, baseline distance and zero-disparity features to the achieved reconstruction performance.
Combining Spatio-Temporal Appearance Descriptors and Optical Flow for Human Action Recognition in Video Data
Oct 01, 2013
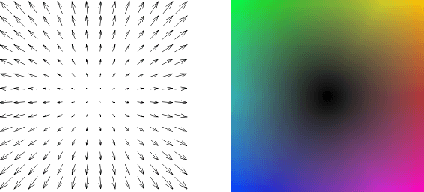
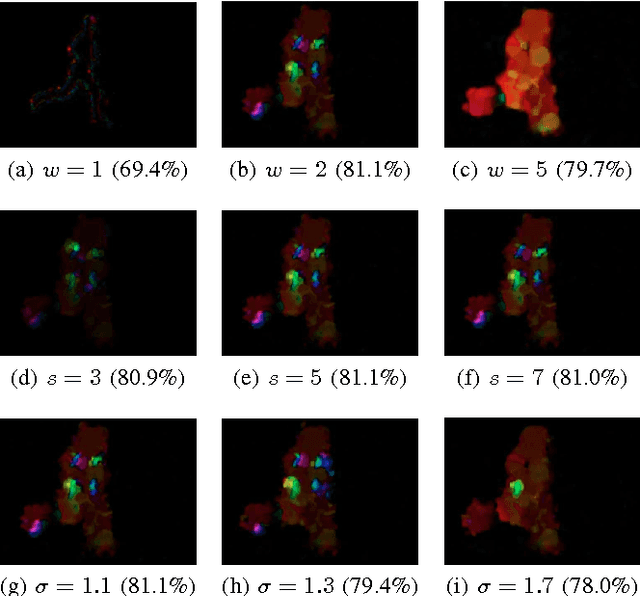
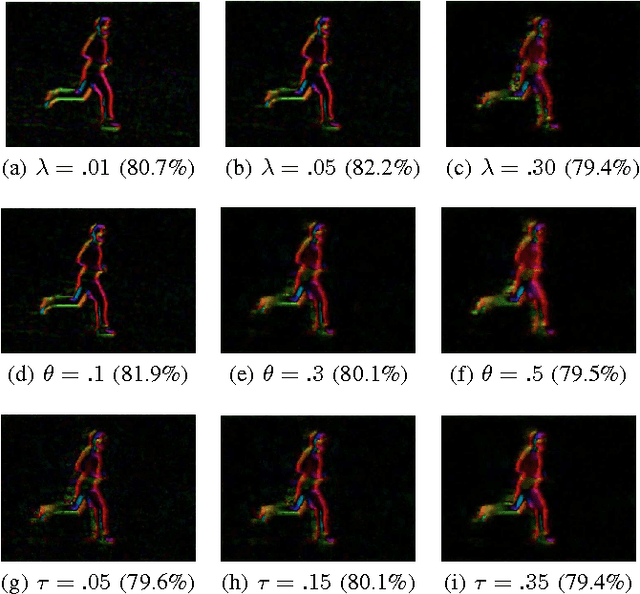
This paper proposes combining spatio-temporal appearance (STA) descriptors with optical flow for human action recognition. The STA descriptors are local histogram-based descriptors of space-time, suitable for building a partial representation of arbitrary spatio-temporal phenomena. Because of the possibility of iterative refinement, they are interesting in the context of online human action recognition. We investigate the use of dense optical flow as the image function of the STA descriptor for human action recognition, using two different algorithms for computing the flow: the Farneb\"ack algorithm and the TVL1 algorithm. We provide a detailed analysis of the influencing optical flow algorithm parameters on the produced optical flow fields. An extensive experimental validation of optical flow-based STA descriptors in human action recognition is performed on the KTH human action dataset. The encouraging experimental results suggest the potential of our approach in online human action recognition.