 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimon S. Du
What Can Neural Networks Reason About?
May 30, 2019
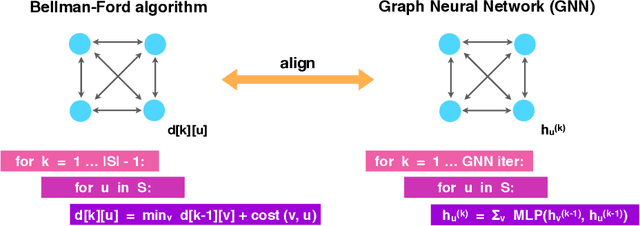
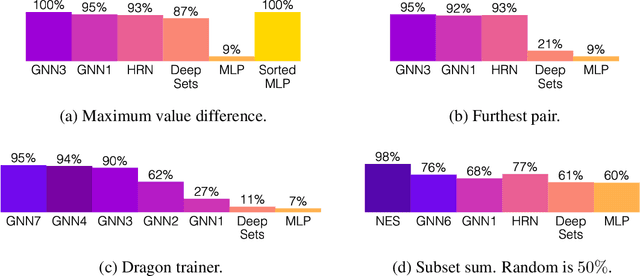
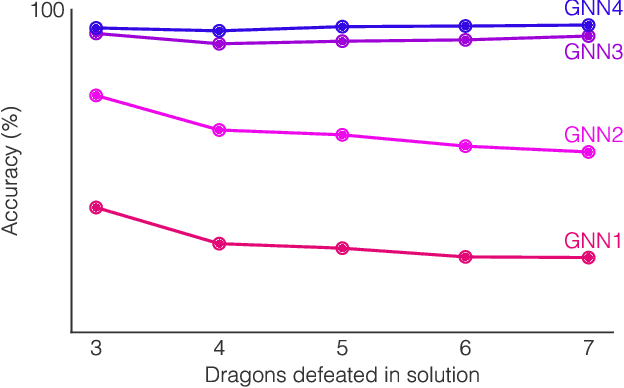
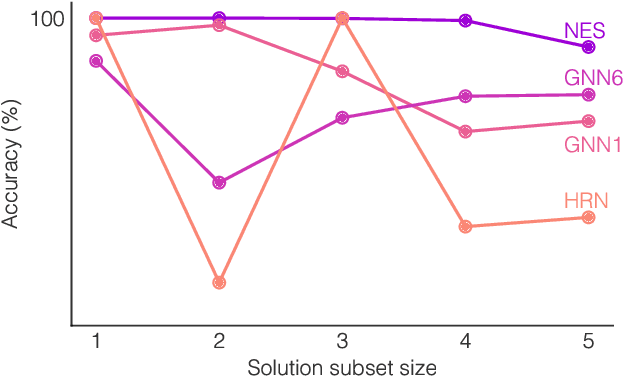
Neural networks have successfully been applied to solving reasoning tasks, ranging from learning simple concepts like "close to", to intricate questions whose reasoning procedures resemble algorithms. Empirically, not all network structures work equally well for reasoning. For example, Graph Neural Networks have achieved impressive empirical results, while less structured neural networks may fail to learn to reason. Theoretically, there is currently limited understanding of the interplay between reasoning tasks and network learning. In this paper, we develop a framework to characterize which tasks a neural network can learn well, by studying how well its structure aligns with the algorithmic structure of the relevant reasoning procedure. This suggests that Graph Neural Networks can learn dynamic programming, a powerful algorithmic strategy that solves a broad class of reasoning problems, such as relational question answering, sorting, intuitive physics, and shortest paths. Our perspective also implies strategies to design neural architectures for complex reasoning. On several abstract reasoning tasks, we see empirically that our theory aligns well with practice.
Graph Neural Tangent Kernel: Fusing Graph Neural Networks with Graph Kernels
May 30, 2019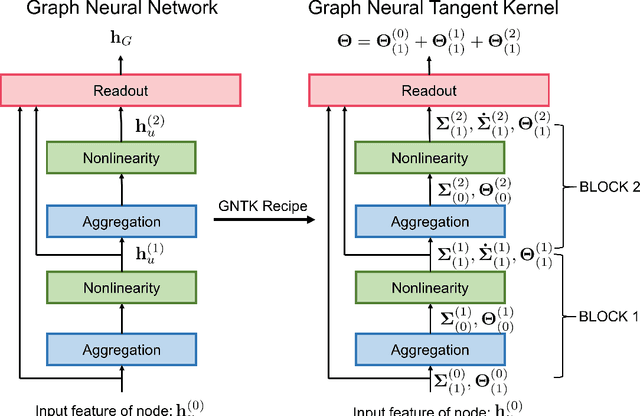
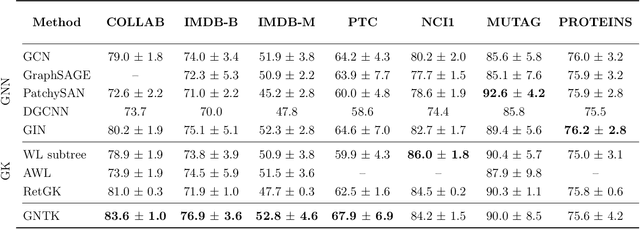
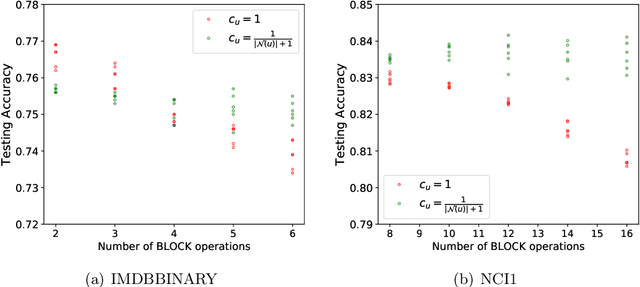
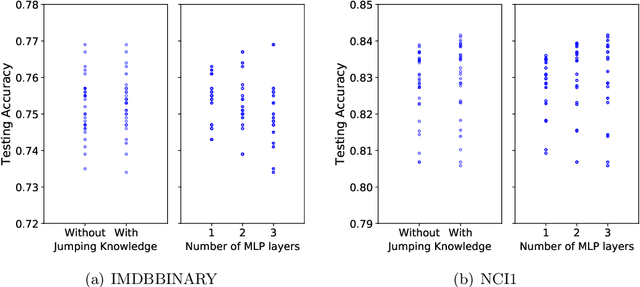
While graph kernels (GKs) are easy to train and enjoy provable theoretical guarantees, their practical performances are limited by their expressive power, as the kernel function often depends on hand-crafted combinatorial features of graphs. Compared to graph kernels, graph neural networks (GNNs) usually achieve better practical performance, as GNNs use multi-layer architectures and non-linear activation functions to extract high-order information of graphs as features. However, due to the large number of hyper-parameters and the non-convex nature of the training procedure, GNNs are harder to train. Theoretical guarantees of GNNs are also not well-understood. Furthermore, the expressive power of GNNs scales with the number of parameters, and thus it is hard to exploit the full power of GNNs when computing resources are limited. The current paper presents a new class of graph kernels, Graph Neural Tangent Kernels (GNTKs), which correspond to \emph{infinitely wide} multi-layer GNNs trained by gradient descent. GNTKs enjoy the full expressive power of GNNs and inherit advantages of GKs. Theoretically, we show GNTKs provably learn a class of smooth functions on graphs. Empirically, we test GNTKs on graph classification datasets and show they achieve strong performance.
Hitting Time of Stochastic Gradient Langevin Dynamics to Stationary Points: A Direct Analysis
May 29, 2019Stochastic gradient Langevin dynamics (SGLD) is a fundamental algorithm in stochastic optimization. Recent work by Zhang et al. [2017] presents an analysis for the hitting time of SGLD for the first and second order stationary points. The proof in Zhang et al. [2017] is a two-stage procedure through bounding the Cheeger's constant, which is rather complicated and leads to loose bounds. In this paper, using intuitions from stochastic differential equations, we provide a direct analysis for the hitting times of SGLD to the first and second order stationary points. Our analysis is straightforward. It only relies on basic linear algebra and probability theory tools. Our direct analysis also leads to tighter bounds comparing to Zhang et al. [2017] and shows the explicit dependence of the hitting time on different factors, including dimensionality, smoothness, noise strength, and step size effects. Under suitable conditions, we show that the hitting time of SGLD to first-order stationary points can be dimension-independent. Moreover, we apply our analysis to study several important online estimation problems in machine learning, including linear regression, matrix factorization, and online PCA.
On Exact Computation with an Infinitely Wide Neural Net
Apr 26, 2019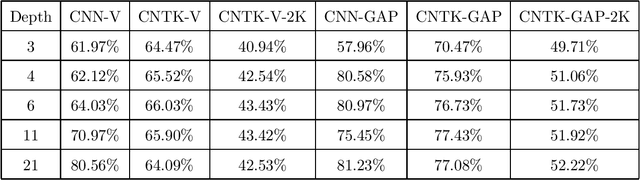
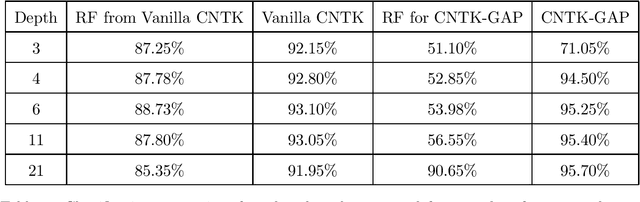
How well does a classic deep net architecture like AlexNet or VGG19 classify on a standard dataset such as CIFAR-10 when its "width" --- namely, number of channels in convolutional layers, and number of nodes in fully-connected internal layers --- is allowed to increase to infinity? Such questions have come to the forefront in the quest to theoretically understand deep learning and its mysteries about optimization and generalization. They also connect deep learning to notions such as Gaussian processes and kernels. A recent paper [Jacot et al., 2018] introduced the Neural Tangent Kernel (NTK) which captures the behavior of fully-connected deep nets in the infinite width limit trained by gradient descent; this object was implicit in some other recent papers. A subsequent paper [Lee et al., 2019] gave heuristic Monte Carlo methods to estimate the NTK and its extension, Convolutional Neural Tangent Kernel (CNTK) and used this to try to understand the limiting behavior on datasets like CIFAR-10. The current paper gives the first efficient exact algorithm (based upon dynamic programming) for computing CNTK as well as an efficient GPU implementation of this algorithm. This results in a significant new benchmark for performance of a pure kernel-based method on CIFAR-10, being 10% higher than the methods reported in [Novak et al., 2019], and only 5% lower than the performance of the corresponding finite deep net architecture (once batch normalization etc. are turned off). We give the first non-asymptotic proof showing that a fully-trained sufficiently wide net is indeed equivalent to the kernel regression predictor using NTK. Our experiments also demonstrate that earlier Monte Carlo approximation can degrade the performance significantly, thus highlighting the power of our exact kernel computation, which we have applied even to the full CIFAR-10 dataset and 20-layer nets.
Global Convergence of Adaptive Gradient Methods for An Over-parameterized Neural Network
Feb 19, 2019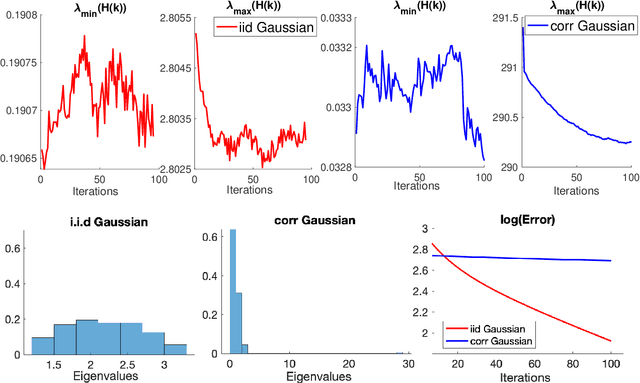

Adaptive gradient methods like AdaGrad are widely used in optimizing neural networks. Yet, existing convergence guarantees for adaptive gradient methods require either convexity or smoothness, and, in the smooth setting, only guarantee convergence to a stationary point. We propose an adaptive gradient method and show that for two-layer over-parameterized neural networks -- if the width is sufficiently large (polynomially) -- then the proposed method converges \emph{to the global minimum} in polynomial time, and convergence is robust, \emph{ without the need to fine-tune hyper-parameters such as the step-size schedule and with the level of over-parametrization independent of the training error}. Our analysis indicates in particular that over-parametrization is crucial for the harnessing the full potential of adaptive gradient methods in the setting of neural networks.
Acceleration via Symplectic Discretization of High-Resolution Differential Equations
Feb 11, 2019We study first-order optimization methods obtained by discretizing ordinary differential equations (ODEs) corresponding to Nesterov's accelerated gradient methods (NAGs) and Polyak's heavy-ball method. We consider three discretization schemes: an explicit Euler scheme, an implicit Euler scheme, and a symplectic scheme. We show that the optimization algorithm generated by applying the symplectic scheme to a high-resolution ODE proposed by Shi et al. [2018] achieves an accelerated rate for minimizing smooth strongly convex functions. On the other hand, the resulting algorithm either fails to achieve acceleration or is impractical when the scheme is implicit, the ODE is low-resolution, or the scheme is explicit.
Width Provably Matters in Optimization for Deep Linear Neural Networks
Jan 26, 2019We prove that for an $L$-layer fully-connected linear neural network, if the width of every hidden layer is $\tilde\Omega (L \cdot r \cdot d_{\mathrm{out}} \cdot \kappa^3 )$, where $r$ and $\kappa$ are the rank and the condition number of the input data, and $d_{\mathrm{out}}$ is the output dimension, then gradient descent with Gaussian random initialization converges to a global minimum at a linear rate. The number of iterations to find an $\epsilon$-suboptimal solution is $O(\kappa \log(\frac{1}{\epsilon}))$. Our polynomial upper bound on the total running time for wide deep linear networks and the $\exp\left(\Omega\left(L\right)\right)$ lower bound for narrow deep linear neural networks [Shamir, 2018] together demonstrate that wide layers are necessary for optimizing deep models.
Provably efficient RL with Rich Observations via Latent State Decoding
Jan 25, 2019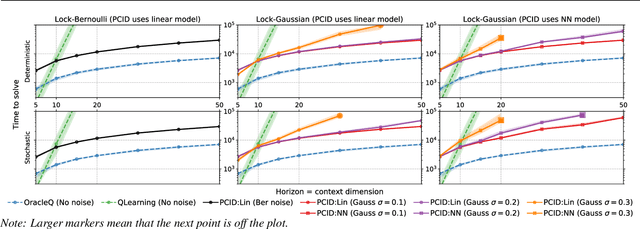
We study the exploration problem in episodic MDPs with rich observations generated from a small number of latent states. Under certain identifiability assumptions, we demonstrate how to estimate a mapping from the observations to latent states inductively through a sequence of regression and clustering steps---where previously decoded latent states provide labels for later regression problems---and use it to construct good exploration policies. We provide finite-sample guarantees on the quality of the learned state decoding function and exploration policies, and complement our theory with an empirical evaluation on a class of hard exploration problems. Our method exponentially improves over $Q$-learning with na\"ive exploration, even when $Q$-learning has cheating access to latent states.
Fine-Grained Analysis of Optimization and Generalization for Overparameterized Two-Layer Neural Networks
Jan 24, 2019
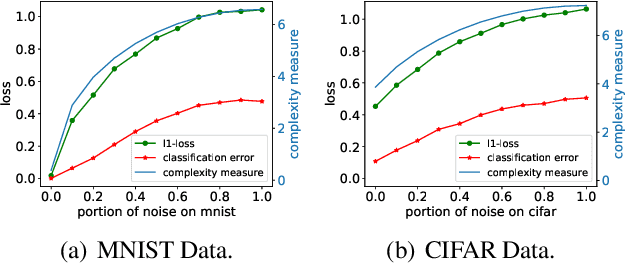
Recent works have cast some light on the mystery of why deep nets fit any data and generalize despite being very overparametrized. This paper analyzes training and generalization for a simple 2-layer ReLU net with random initialization, and provides the following improvements over recent works: (i) Using a tighter characterization of training speed than recent papers, an explanation for why training a neural net with random labels leads to slower training, as originally observed in [Zhang et al. ICLR'17]. (ii) Generalization bound independent of network size, using a data-dependent complexity measure. Our measure distinguishes clearly between random labels and true labels on MNIST and CIFAR, as shown by experiments. Moreover, recent papers require sample complexity to increase (slowly) with the size, while our sample complexity is completely independent of the network size. (iii) Learnability of a broad class of smooth functions by 2-layer ReLU nets trained via gradient descent. The key idea is to track dynamics of training and generalization via properties of a related kernel.