 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Image Rotation for Open Set Domain Adaptation
Jul 24, 2020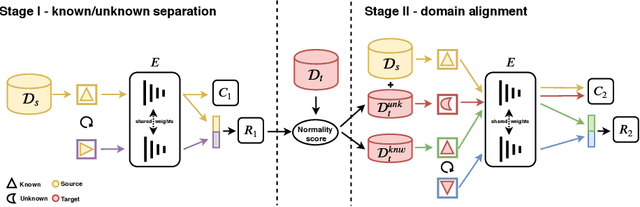
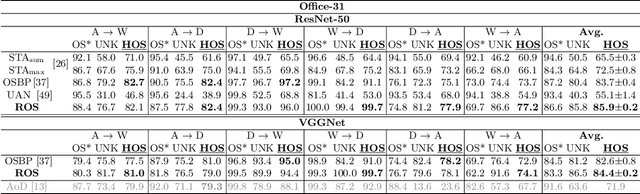
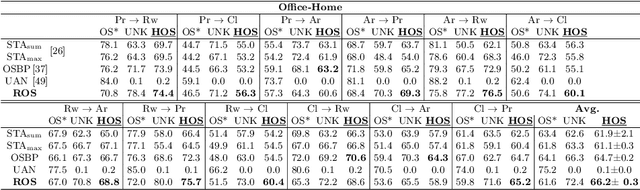

Open Set Domain Adaptation (OSDA) bridges the domain gap between a labeled source domain and an unlabeled target domain, while also rejecting target classes that are not present in the source. To avoid negative transfer, OSDA can be tackled by first separating the known/unknown target samples and then aligning known target samples with the source data. We propose a novel method to addresses both these problems using the self-supervised task of rotation recognition. Moreover, we assess the performance with a new open set metric that properly balances the contribution of recognizing the known classes and rejecting the unknown samples. Comparative experiments with existing OSDA methods on the standard Office-31 and Office-Home benchmarks show that: (i) our method outperforms its competitors, (ii) reproducibility for this field is a crucial issue to tackle, (iii) our metric provides a reliable tool to allow fair open set evaluation.
One-Shot Unsupervised Cross-Domain Detection
May 23, 2020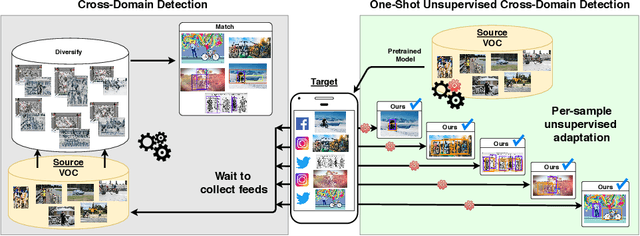
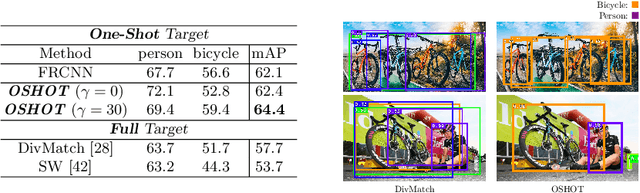
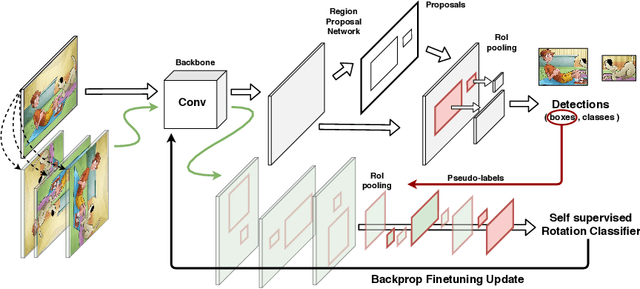
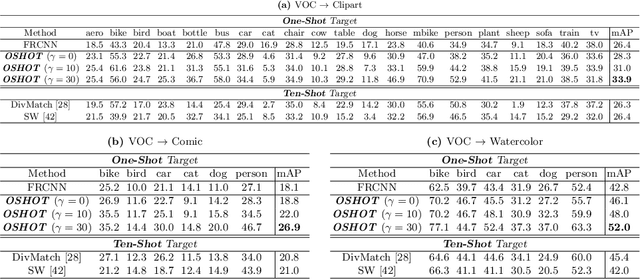
Despite impressive progress in object detection over the last years, it is still an open challenge to reliably detect objects across visual domains. Although the topic has attracted attention recently, current approaches all rely on the ability to access a sizable amount of target data for use at training time. This is a heavy assumption, as often it is not possible to anticipate the domain where a detector will be used, nor to access it in advance for data acquisition. Consider for instance the task of monitoring image feeds from social media: as every image is created and uploaded by a different user it belongs to a different target domain that is impossible to foresee during training. This paper addresses this setting, presenting an object detection algorithm able to perform unsupervised adaption across domains by using only one target sample, seen at test time. We achieve this by introducing a multi-task architecture that one-shot adapts to any incoming sample by iteratively solving a self-supervised task on it. We further enhance this auxiliary adaptation with cross-task pseudo-labeling. A thorough benchmark analysis against the most recent cross-domain detection methods and a detailed ablation study show the advantage of our method, which sets the state-of-the-art in the defined one-shot scenario.
Learning to Generalize One Sample at a Time with Self-Supervision
Oct 11, 2019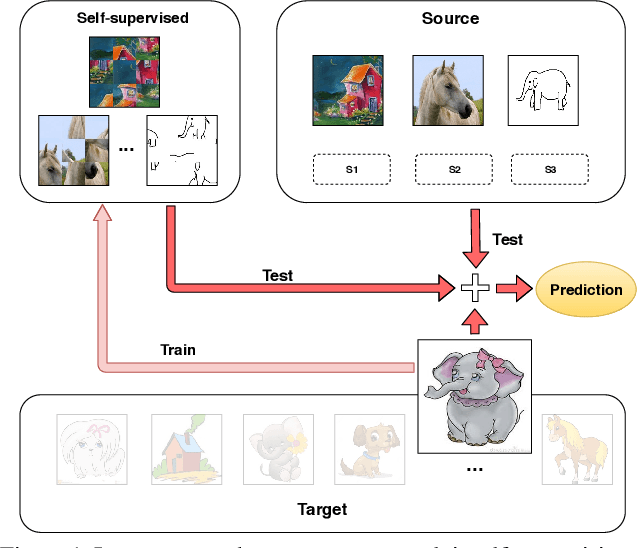
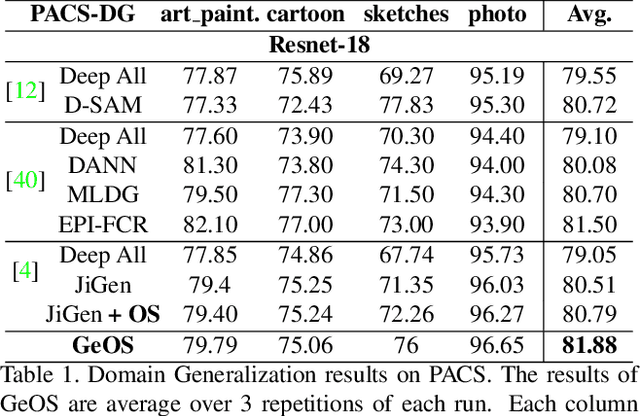
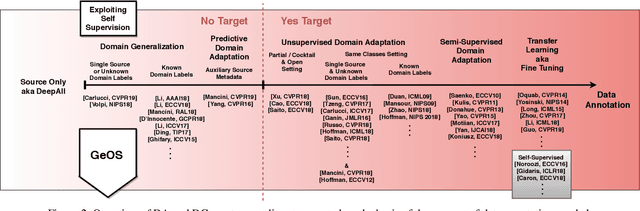
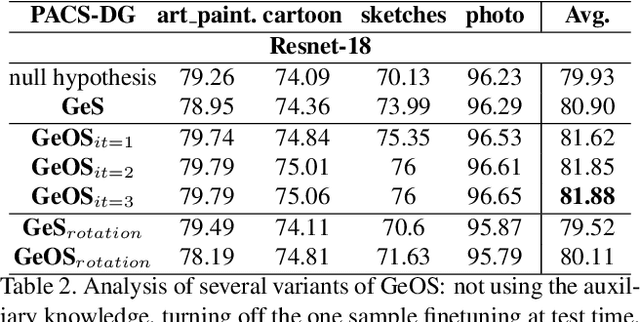
Although deep networks have significantly increased the performance of visual recognition methods, it is still challenging to achieve the robustness across visual domains that is necessary for real-world applications. To tackle this issue, research on domain adaptation and generalization has flourished over the last decade. An important aspect to consider when assessing the work done in the literature so far is the amount of data annotation necessary for training each approach, both at the source and target level. In this paper we argue that the data annotation overload should be minimal, as it is costly. Hence, we propose to use self-supervised learning to achieve domain generalization and adaptation. We consider learning regularities from non annotated data as an auxiliary task, and cast the problem within an Auxiliary Learning principled framework. Moreover, we suggest to further exploit the ability to learn about visual domains from non annotated images by learning from target data while testing, as data are presented to the algorithm one sample at a time. Results on three different scenarios confirm the value of our approach.
Tackling Partial Domain Adaptation with Self-Supervision
Jun 12, 2019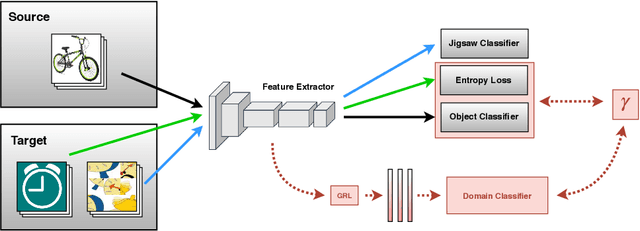
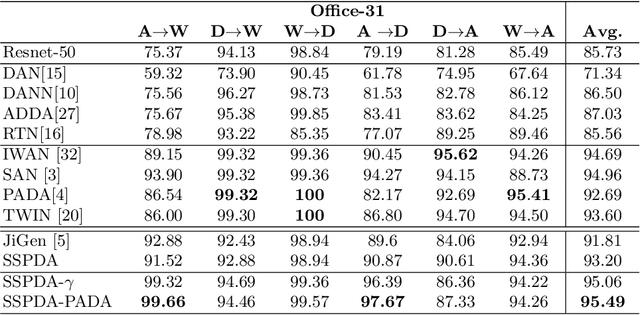
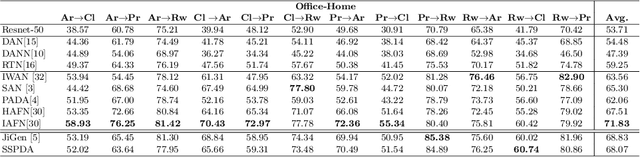
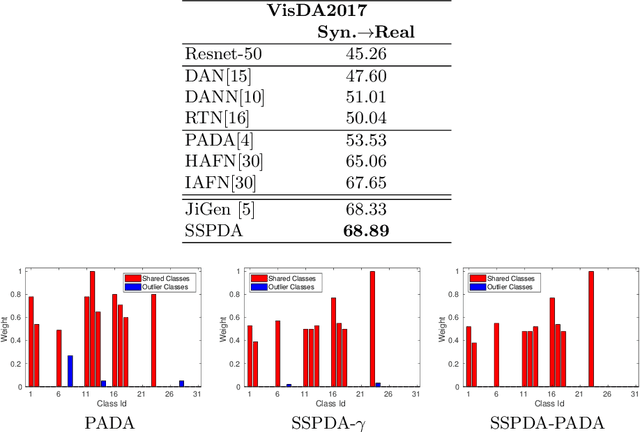
Domain adaptation approaches have shown promising results in reducing the marginal distribution difference among visual domains. They allow to train reliable models that work over datasets of different nature (photos, paintings etc), but they still struggle when the domains do not share an identical label space. In the partial domain adaptation setting, where the target covers only a subset of the source classes, it is challenging to reduce the domain gap without incurring in negative transfer. Many solutions just keep the standard domain adaptation techniques by adding heuristic sample weighting strategies. In this work we show how the self-supervisory signal obtained from the spatial co-location of patches can be used to define a side task that supports adaptation regardless of the exact label sharing condition across domains. We build over a recent work that introduced a jigsaw puzzle task for domain generalization: we describe how to reformulate this approach for partial domain adaptation and we show how it boosts existing adaptive solutions when combined with them. The obtained experimental results on three datasets supports the effectiveness of our approach.
Domain Generalization by Solving Jigsaw Puzzles
Apr 14, 2019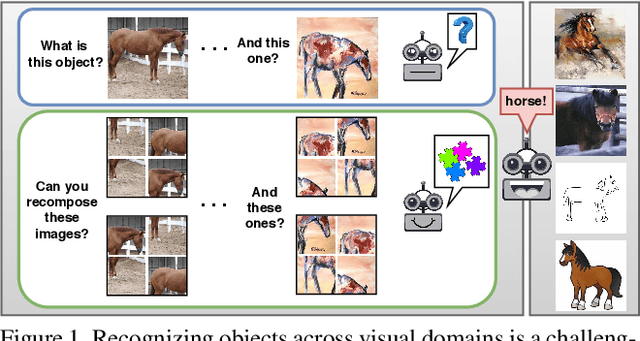
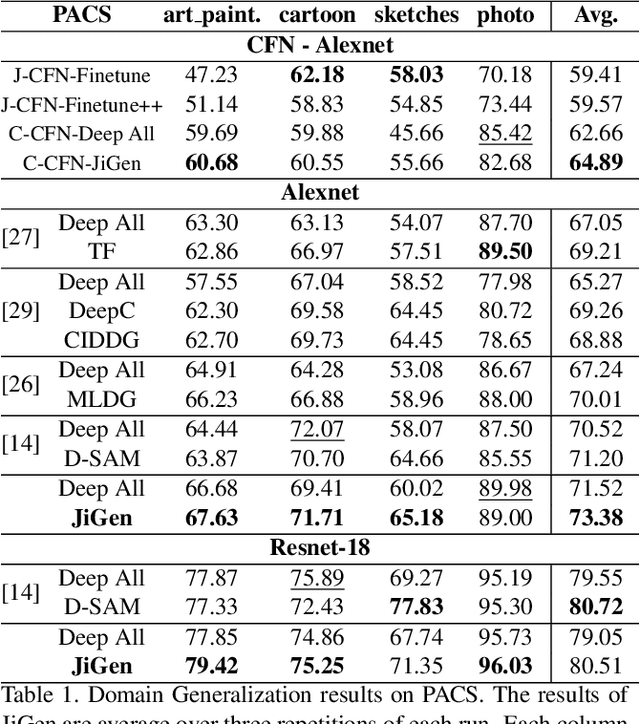
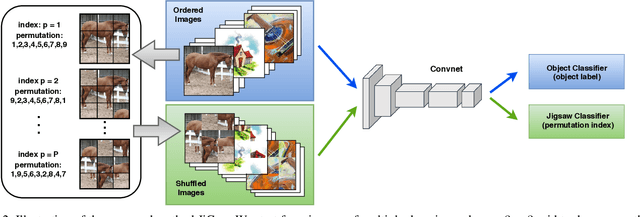
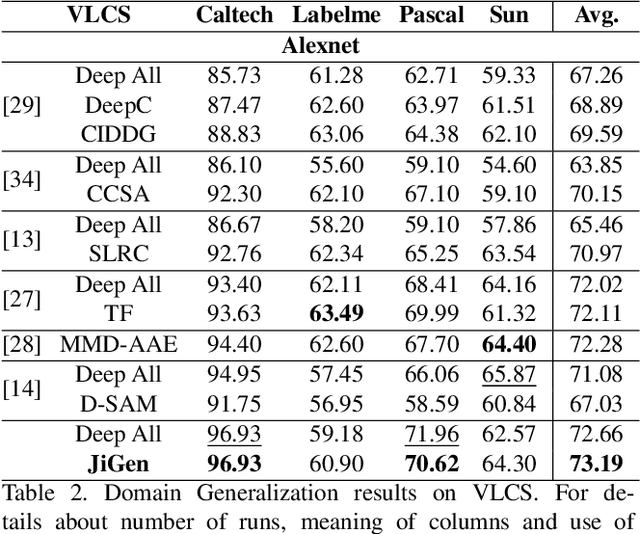
Human adaptability relies crucially on the ability to learn and merge knowledge both from supervised and unsupervised learning: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the task of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals how to solve a jigsaw puzzle on the same images. This secondary task helps the network to learn the concepts of spatial correlation while acting as a regularizer for the classification task. Multiple experiments on the PACS, VLCS, Office-Home and digits datasets confirm our intuition and show that this simple method outperforms previous domain generalization and adaptation solutions. An ablation study further illustrates the inner workings of our approach.
Multimodal Deep Domain Adaptation
Jul 31, 2018


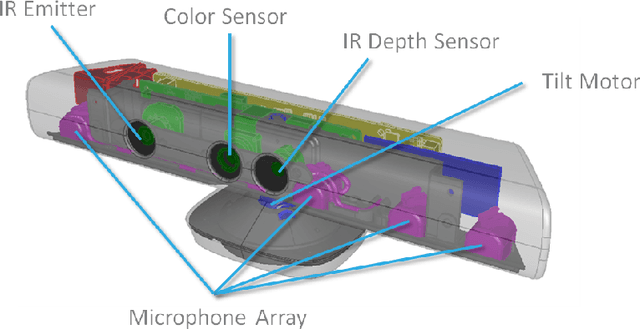
Typically a classifier trained on a given dataset (source domain) does not performs well if it is tested on data acquired in a different setting (target domain). This is the problem that domain adaptation (DA) tries to overcome and, while it is a well explored topic in computer vision, it is largely ignored in robotic vision where usually visual classification methods are trained and tested in the same domain. Robots should be able to deal with unknown environments, recognize objects and use them in the correct way, so it is important to explore the domain adaptation scenario also in this context. The goal of the project is to define a benchmark and a protocol for multi-modal domain adaptation that is valuable for the robot vision community. With this purpose some of the state-of-the-art DA methods are selected: Deep Adaptation Network (DAN), Domain Adversarial Training of Neural Network (DANN), Automatic Domain Alignment Layers (AutoDIAL) and Adversarial Discriminative Domain Adaptation (ADDA). Evaluations have been done using different data types: RGB only, depth only and RGB-D over the following datasets, designed for the robotic community: RGB-D Object Dataset (ROD), Web Object Dataset (WOD), Autonomous Robot Indoor Dataset (ARID), Big Berkeley Instance Recognition Dataset (BigBIRD) and Active Vision Dataset. Although progresses have been made on the formulation of effective adaptation algorithms and more realistic object datasets are available, the results obtained show that, training a sufficiently good object classifier, especially in the domain adaptation scenario, is still an unsolved problem. Also the best way to combine depth with RGB informations to improve the performance is a point that needs to be investigated more.