 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time 2D/3D Registration via CNN Regression
Apr 25, 2016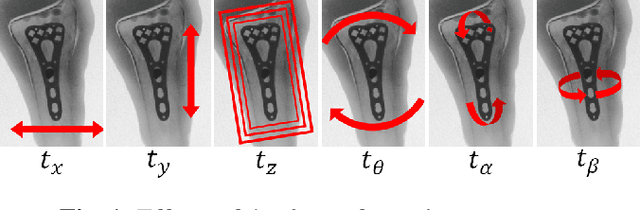
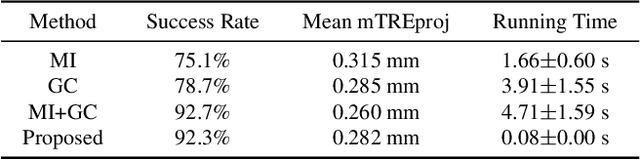
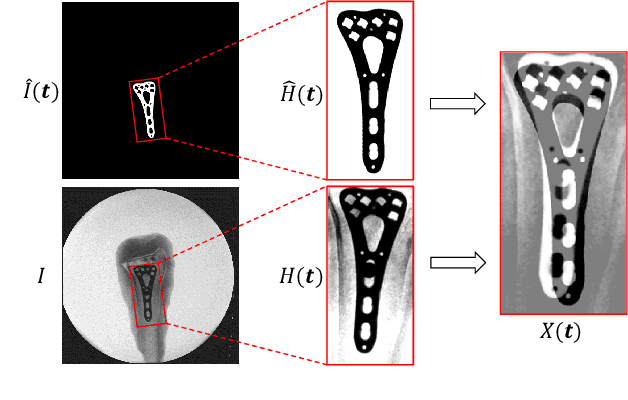
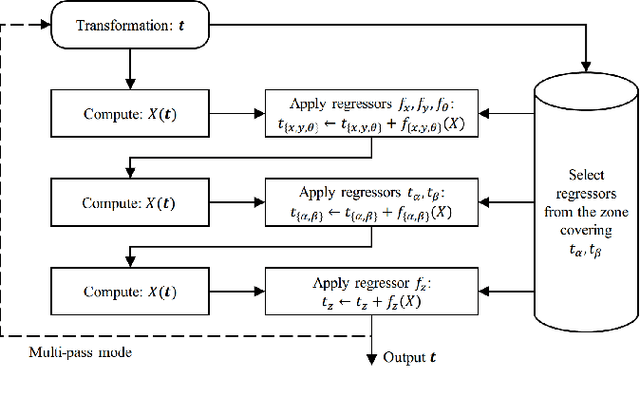
In this paper, we present a Convolutional Neural Network (CNN) regression approach for real-time 2-D/3-D registration. Different from optimization-based methods, which iteratively optimize the transformation parameters over a scalar-valued metric function representing the quality of the registration, the proposed method exploits the information embedded in the appearances of the Digitally Reconstructed Radiograph and X-ray images, and employs CNN regressors to directly estimate the transformation parameters. The CNN regressors are trained for local zones and applied in a hierarchical manner to break down the complex regression task into simpler sub-tasks that can be learned separately. Our experiment results demonstrate the advantage of the proposed method in computational efficiency with negligible degradation of registration accuracy compared to intensity-based methods.