 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShujian Huang
Helping the Weak Makes You Strong: Simple Multi-Task Learning Improves Non-Autoregressive Translators
Nov 11, 2022
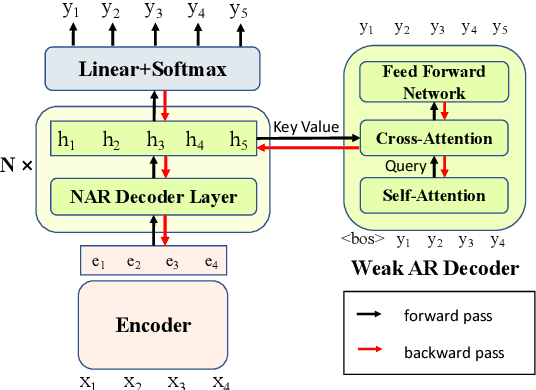
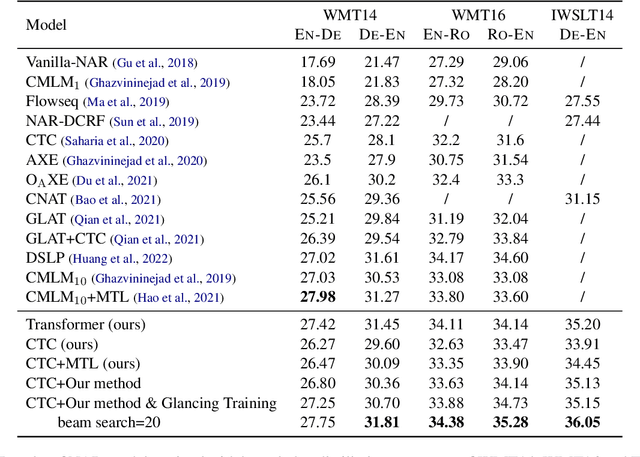
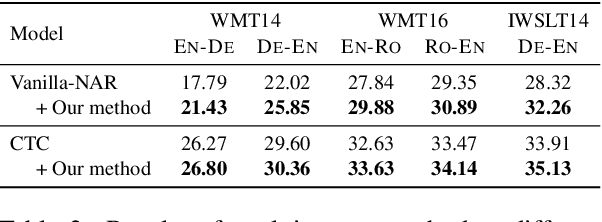
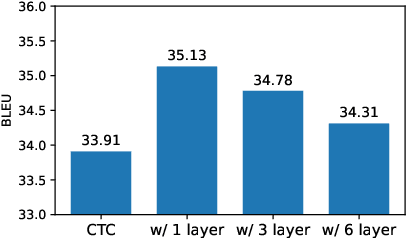
Recently, non-autoregressive (NAR) neural machine translation models have received increasing attention due to their efficient parallel decoding. However, the probabilistic framework of NAR models necessitates conditional independence assumption on target sequences, falling short of characterizing human language data. This drawback results in less informative learning signals for NAR models under conventional MLE training, thereby yielding unsatisfactory accuracy compared to their autoregressive (AR) counterparts. In this paper, we propose a simple and model-agnostic multi-task learning framework to provide more informative learning signals. During training stage, we introduce a set of sufficiently weak AR decoders that solely rely on the information provided by NAR decoder to make prediction, forcing the NAR decoder to become stronger or else it will be unable to support its weak AR partners. Experiments on WMT and IWSLT datasets show that our approach can consistently improve accuracy of multiple NAR baselines without adding any additional decoding overhead.
What Knowledge Is Needed? Towards Explainable Memory for kNN-MT Domain Adaptation
Nov 08, 2022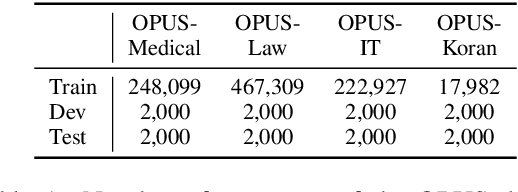
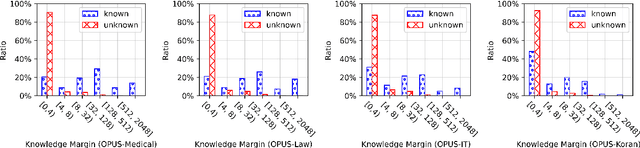
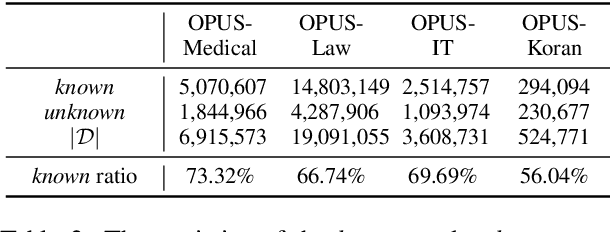
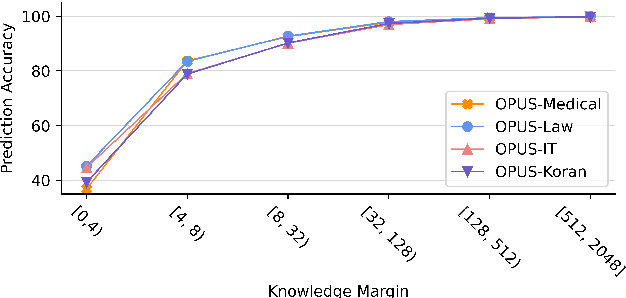
kNN-MT presents a new paradigm for domain adaptation by building an external datastore, which usually saves all target language token occurrences in the parallel corpus. As a result, the constructed datastore is usually large and possibly redundant. In this paper, we investigate the interpretability issue of this approach: what knowledge does the NMT model need? We propose the notion of local correctness (LAC) as a new angle, which describes the potential translation correctness for a single entry and for a given neighborhood. Empirical study shows that our investigation successfully finds the conditions where the NMT model could easily fail and need related knowledge. Experiments on six diverse target domains and two language-pairs show that pruning according to local correctness brings a light and more explainable memory for kNN-MT domain adaptation.
Probing Cross-modal Semantics Alignment Capability from the Textual Perspective
Oct 18, 2022

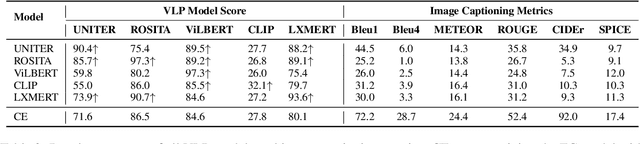
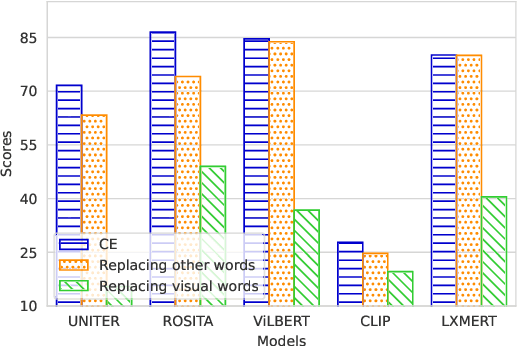
In recent years, vision and language pre-training (VLP) models have advanced the state-of-the-art results in a variety of cross-modal downstream tasks. Aligning cross-modal semantics is claimed to be one of the essential capabilities of VLP models. However, it still remains unclear about the inner working mechanism of alignment in VLP models. In this paper, we propose a new probing method that is based on image captioning to first empirically study the cross-modal semantics alignment of VLP models. Our probing method is built upon the fact that given an image-caption pair, the VLP models will give a score, indicating how well two modalities are aligned; maximizing such scores will generate sentences that VLP models believe are of good alignment. Analyzing these sentences thus will reveal in what way different modalities are aligned and how well these alignments are in VLP models. We apply our probing method to five popular VLP models, including UNITER, ROSITA, ViLBERT, CLIP, and LXMERT, and provide a comprehensive analysis of the generated captions guided by these models. Our results show that VLP models (1) focus more on just aligning objects with visual words, while neglecting global semantics; (2) prefer fixed sentence patterns, thus ignoring more important textual information including fluency and grammar; and (3) deem the captions with more visual words are better aligned with images. These findings indicate that VLP models still have weaknesses in cross-modal semantics alignment and we hope this work will draw researchers' attention to such problems when designing a new VLP model.
Zero-shot Domain Adaptation for Neural Machine Translation with Retrieved Phrase-level Prompts
Sep 23, 2022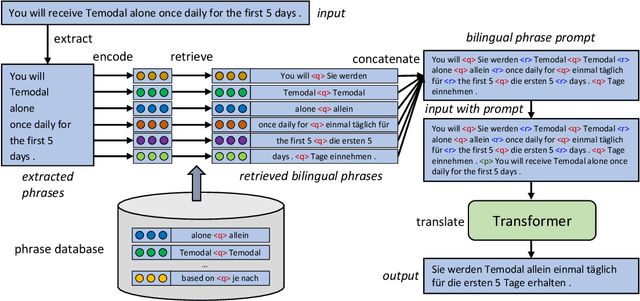

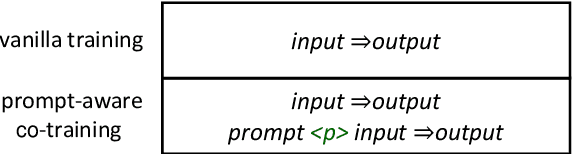

Domain adaptation is an important challenge for neural machine translation. However, the traditional fine-tuning solution requires multiple extra training and yields a high cost. In this paper, we propose a non-tuning paradigm, resolving domain adaptation with a prompt-based method. Specifically, we construct a bilingual phrase-level database and retrieve relevant pairs from it as a prompt for the input sentences. By utilizing Retrieved Phrase-level Prompts (RePP), we effectively boost the translation quality. Experiments show that our method improves domain-specific machine translation for 6.2 BLEU scores and improves translation constraints for 11.5% accuracy without additional training.
A Numerical Reasoning Question Answering System with Fine-grained Retriever and the Ensemble of Multiple Generators for FinQA
Jun 17, 2022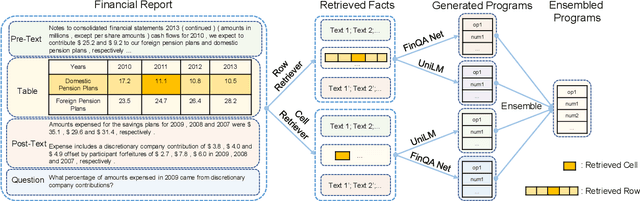
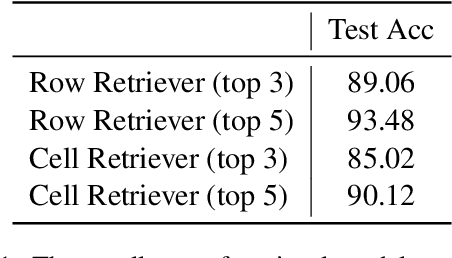
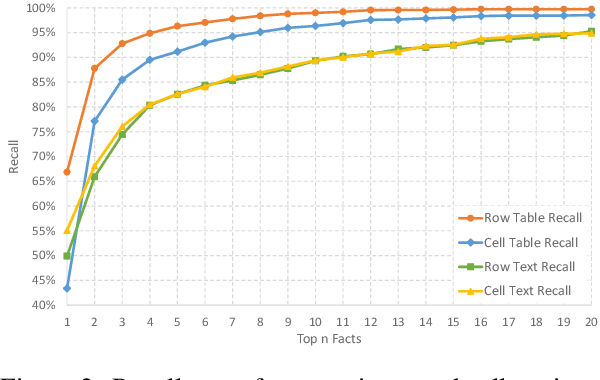
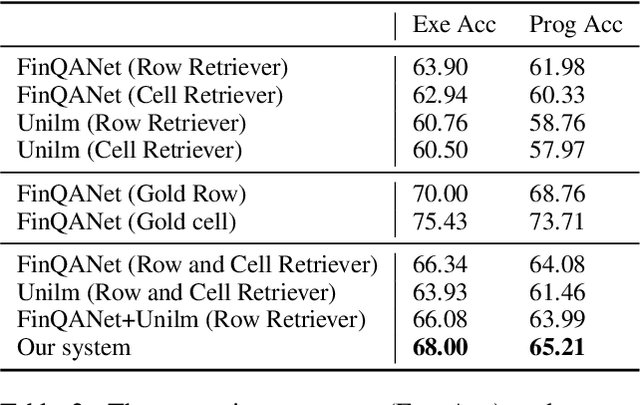
The numerical reasoning in the financial domain -- performing quantitative analysis and summarizing the information from financial reports -- can greatly increase business efficiency and reduce costs of billions of dollars. Here, we propose a numerical reasoning question answering system to answer numerical reasoning questions among financial text and table data sources, consisting of a retriever module, a generator module, and an ensemble module. Specifically, in the retriever module, in addition to retrieving the whole row data, we innovatively design a cell retriever that retrieves the gold cells to avoid bringing unrelated and similar cells in the same row to the inputs of the generator module. In the generator module, we utilize multiple generators to produce programs, which are operation steps to answer the question. Finally, in the ensemble module, we integrate multiple programs to choose the best program as the output of our system. In the final private test set in FinQA Competition, our system obtains 69.79 execution accuracy.
Analyzing the Intensity of Complaints on Social Media
Apr 20, 2022
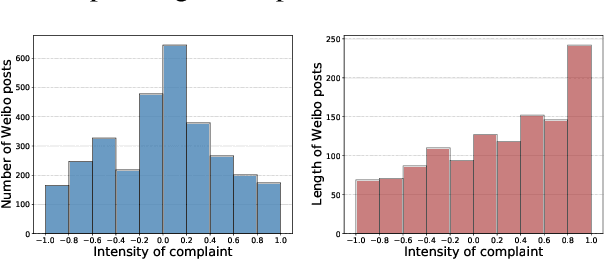

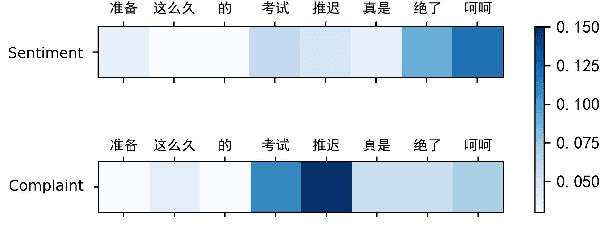
Complaining is a speech act that expresses a negative inconsistency between reality and human expectations. While prior studies mostly focus on identifying the existence or the type of complaints, in this work, we present the first study in computational linguistics of measuring the intensity of complaints from text. Analyzing complaints from such perspective is particularly useful, as complaints of certain degrees may cause severe consequences for companies or organizations. We create the first Chinese dataset containing 3,103 posts about complaints from Weibo, a popular Chinese social media platform. These posts are then annotated with complaints intensity scores using Best-Worst Scaling (BWS) method. We show that complaints intensity can be accurately estimated by computational models with the best mean square error achieving 0.11. Furthermore, we conduct a comprehensive linguistic analysis around complaints, including the connections between complaints and sentiment, and a cross-lingual comparison for complaints expressions used by Chinese and English speakers. We finally show that our complaints intensity scores can be incorporated for better estimating the popularity of posts on social media.
$\textit{latent}$-GLAT: Glancing at Latent Variables for Parallel Text Generation
Apr 05, 2022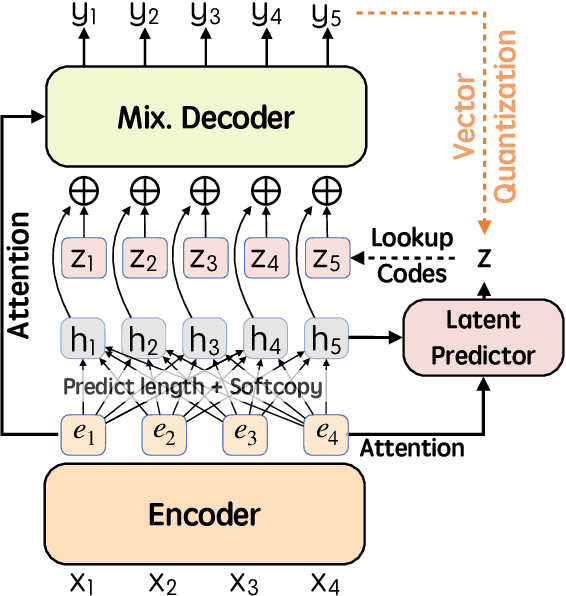
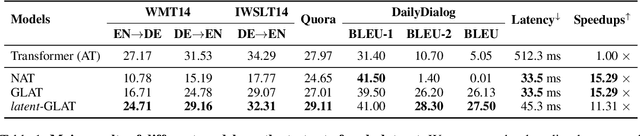
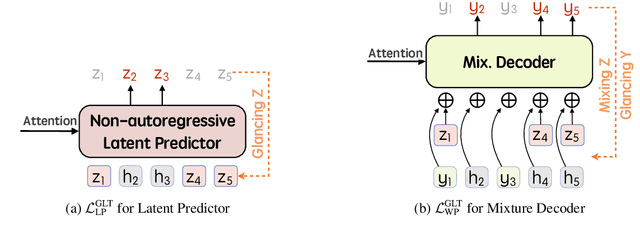
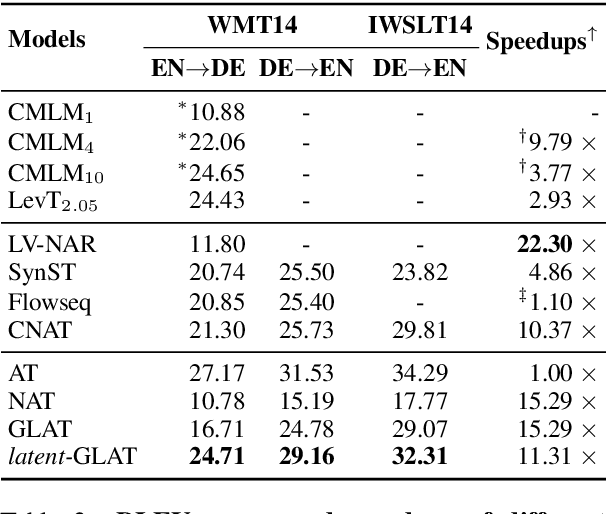
Recently, parallel text generation has received widespread attention due to its success in generation efficiency. Although many advanced techniques are proposed to improve its generation quality, they still need the help of an autoregressive model for training to overcome the one-to-many multi-modal phenomenon in the dataset, limiting their applications. In this paper, we propose $\textit{latent}$-GLAT, which employs the discrete latent variables to capture word categorical information and invoke an advanced curriculum learning technique, alleviating the multi-modality problem. Experiment results show that our method outperforms strong baselines without the help of an autoregressive model, which further broadens the application scenarios of the parallel decoding paradigm.
Non-Parametric Online Learning from Human Feedback for Neural Machine Translation
Sep 23, 2021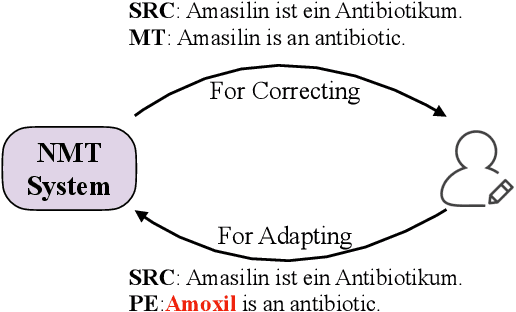
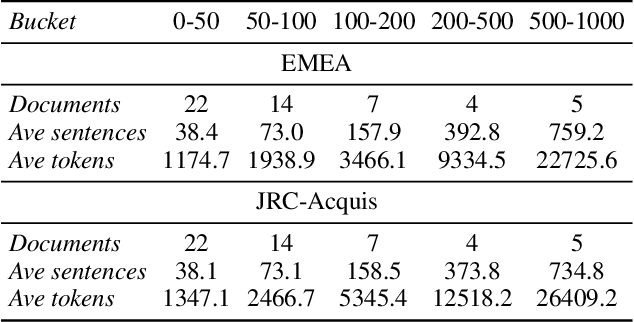
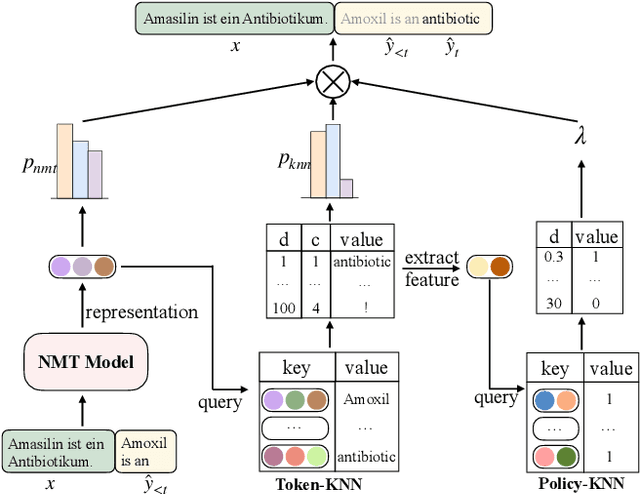
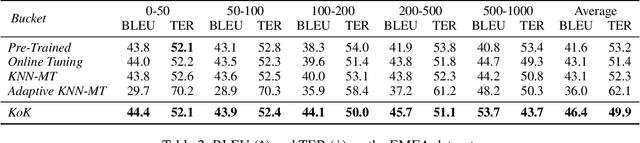
We study the problem of online learning with human feedback in the human-in-the-loop machine translation, in which the human translators revise the machine-generated translations and then the corrected translations are used to improve the neural machine translation (NMT) system. However, previous methods require online model updating or additional translation memory networks to achieve high-quality performance, making them inflexible and inefficient in practice. In this paper, we propose a novel non-parametric online learning method without changing the model structure. This approach introduces two k-nearest-neighbor (KNN) modules: one module memorizes the human feedback, which is the correct sentences provided by human translators, while the other balances the usage of the history human feedback and original NMT models adaptively. Experiments conducted on EMEA and JRC-Acquis benchmarks demonstrate that our proposed method obtains substantial improvements on translation accuracy and achieves better adaptation performance with less repeating human correction operations.
Learning Kernel-Smoothed Machine Translation with Retrieved Examples
Sep 21, 2021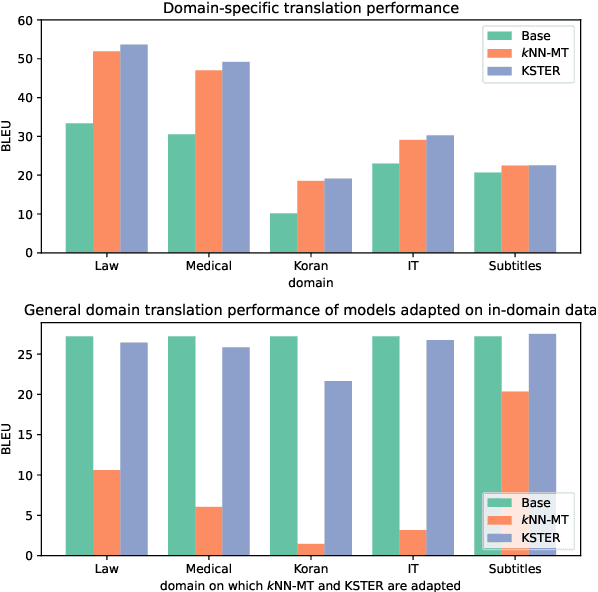
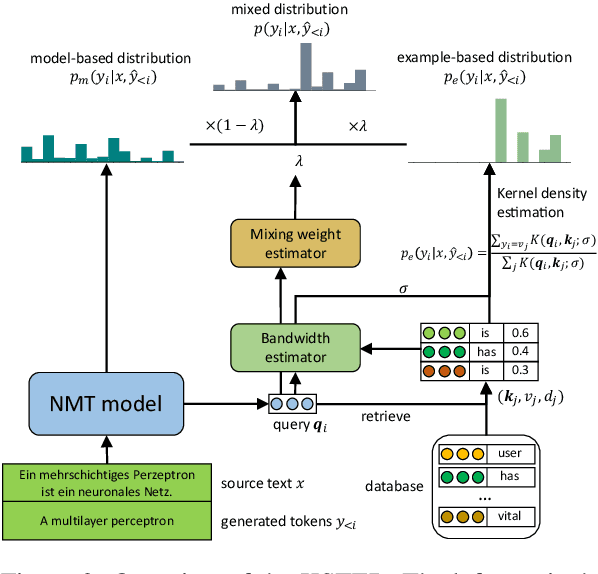

How to effectively adapt neural machine translation (NMT) models according to emerging cases without retraining? Despite the great success of neural machine translation, updating the deployed models online remains a challenge. Existing non-parametric approaches that retrieve similar examples from a database to guide the translation process are promising but are prone to overfit the retrieved examples. However, non-parametric methods are prone to overfit the retrieved examples. In this work, we propose to learn Kernel-Smoothed Translation with Example Retrieval (KSTER), an effective approach to adapt neural machine translation models online. Experiments on domain adaptation and multi-domain machine translation datasets show that even without expensive retraining, KSTER is able to achieve improvement of 1.1 to 1.5 BLEU scores over the best existing online adaptation methods. The code and trained models are released at https://github.com/jiangqn/KSTER.
Non-Parametric Unsupervised Domain Adaptation for Neural Machine Translation
Sep 14, 2021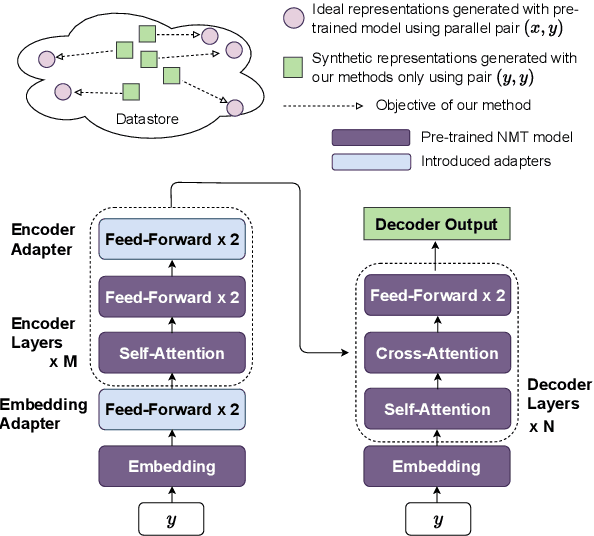
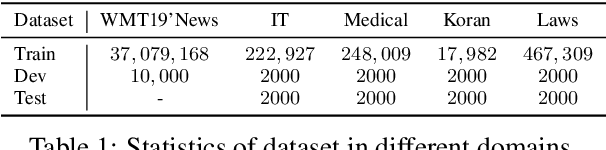
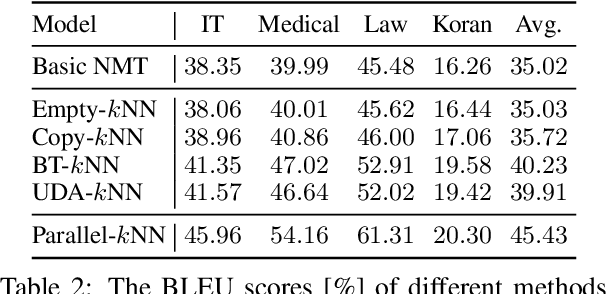
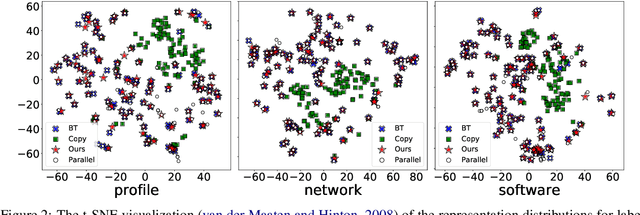
Recently, $k$NN-MT has shown the promising capability of directly incorporating the pre-trained neural machine translation (NMT) model with domain-specific token-level $k$-nearest-neighbor ($k$NN) retrieval to achieve domain adaptation without retraining. Despite being conceptually attractive, it heavily relies on high-quality in-domain parallel corpora, limiting its capability on unsupervised domain adaptation, where in-domain parallel corpora are scarce or nonexistent. In this paper, we propose a novel framework that directly uses in-domain monolingual sentences in the target language to construct an effective datastore for $k$-nearest-neighbor retrieval. To this end, we first introduce an autoencoder task based on the target language, and then insert lightweight adapters into the original NMT model to map the token-level representation of this task to the ideal representation of translation task. Experiments on multi-domain datasets demonstrate that our proposed approach significantly improves the translation accuracy with target-side monolingual data, while achieving comparable performance with back-translation.