 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuicheng Yan
Value-Consistent Representation Learning for Data-Efficient Reinforcement Learning
Jun 25, 2022
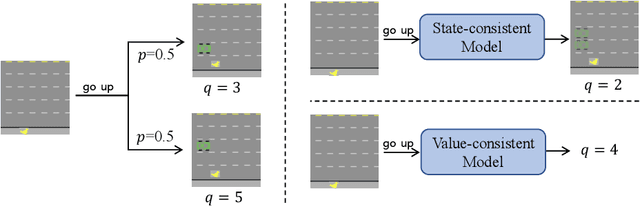

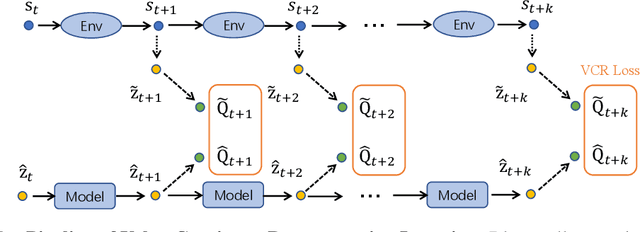

Deep reinforcement learning (RL) algorithms suffer severe performance degradation when the interaction data is scarce, which limits their real-world application. Recently, visual representation learning has been shown to be effective and promising for boosting sample efficiency in RL. These methods usually rely on contrastive learning and data augmentation to train a transition model for state prediction, which is different from how the model is used in RL--performing value-based planning. Accordingly, the learned model may not be able to align well with the environment and generate consistent value predictions, especially when the state transition is not deterministic. To address this issue, we propose a novel method, called value-consistent representation learning (VCR), to learn representations that are directly related to decision-making. More specifically, VCR trains a model to predict the future state (also referred to as the ''imagined state'') based on the current one and a sequence of actions. Instead of aligning this imagined state with a real state returned by the environment, VCR applies a $Q$-value head on both states and obtains two distributions of action values. Then a distance is computed and minimized to force the imagined state to produce a similar action value prediction as that by the real state. We develop two implementations of the above idea for the discrete and continuous action spaces respectively. We conduct experiments on Atari 100K and DeepMind Control Suite benchmarks to validate their effectiveness for improving sample efficiency. It has been demonstrated that our methods achieve new state-of-the-art performance for search-free RL algorithms.
EnvPool: A Highly Parallel Reinforcement Learning Environment Execution Engine
Jun 21, 2022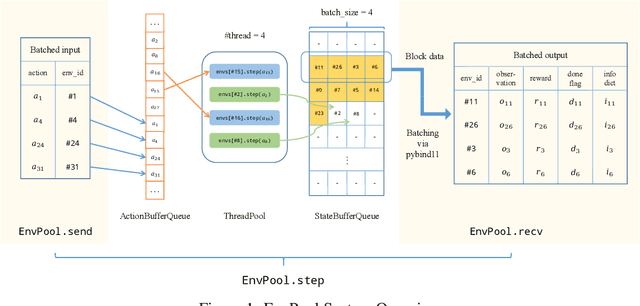
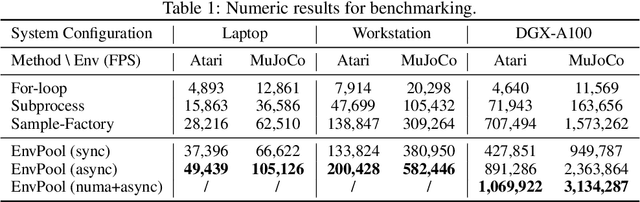
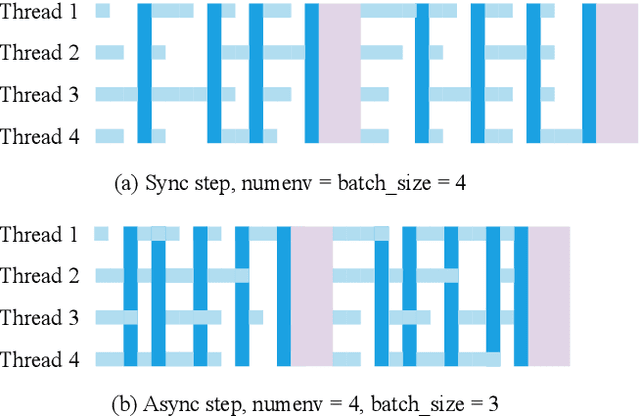
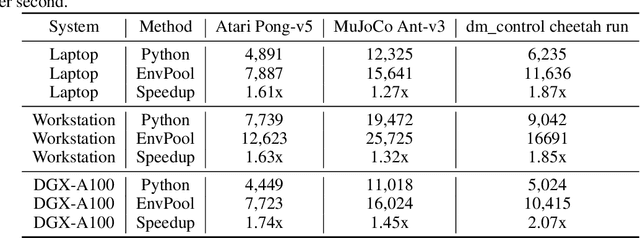
There has been significant progress in developing reinforcement learning (RL) training systems. Past works such as IMPALA, Apex, Seed RL, Sample Factory, and others aim to improve the system's overall throughput. In this paper, we try to address a common bottleneck in the RL training system, i.e., parallel environment execution, which is often the slowest part of the whole system but receives little attention. With a curated design for paralleling RL environments, we have improved the RL environment simulation speed across different hardware setups, ranging from a laptop, and a modest workstation, to a high-end machine like NVIDIA DGX-A100. On a high-end machine, EnvPool achieves 1 million frames per second for the environment execution on Atari environments and 3 million frames per second on MuJoCo environments. When running on a laptop, the speed of EnvPool is 2.8 times of the Python subprocess. Moreover, great compatibility with existing RL training libraries has been demonstrated in the open-sourced community, including CleanRL, rl_games, DeepMind Acme, etc. Finally, EnvPool allows researchers to iterate their ideas at a much faster pace and has the great potential to become the de facto RL environment execution engine. Example runs show that it takes only 5 minutes to train Atari Pong and MuJoCo Ant, both on a laptop. EnvPool has already been open-sourced at https://github.com/sail-sg/envpool.
Towards Understanding Why Mask-Reconstruction Pretraining Helps in Downstream Tasks
Jun 14, 2022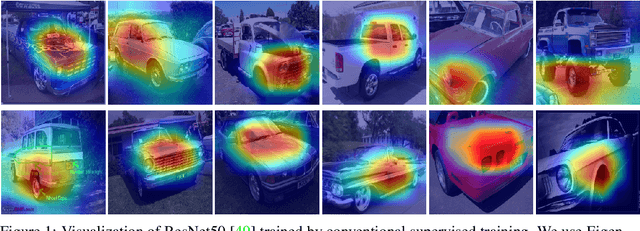

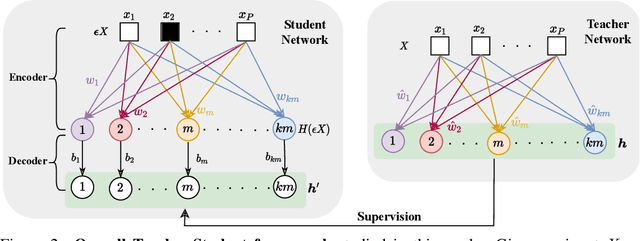
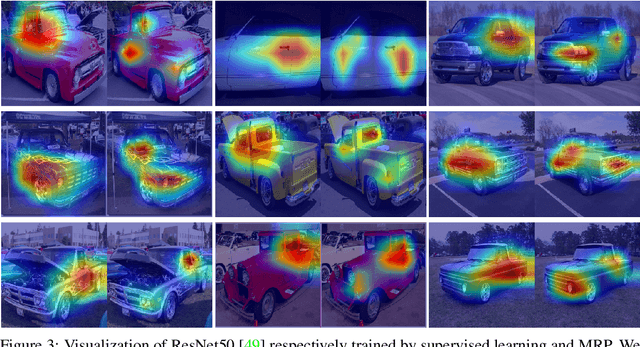
For unsupervised pretraining, mask-reconstruction pretraining (MRP) approaches randomly mask input patches and then reconstruct pixels or semantic features of these masked patches via an auto-encoder. Then for a downstream task, supervised fine-tuning the pretrained encoder remarkably surpasses the conventional supervised learning (SL) trained from scratch. However, it is still unclear 1) how MRP performs semantic learning in the pretraining phase and 2) why it helps in downstream tasks. To solve these problems, we theoretically show that on an auto-encoder of a two/one-layered convolution encoder/decoder, MRP can capture all discriminative semantics in the pretraining dataset, and accordingly show its provable improvement over SL on the classification downstream task. Specifically, we assume that pretraining dataset contains multi-view samples of ratio $1-\mu$ and single-view samples of ratio $\mu$, where multi/single-view samples has multiple/single discriminative semantics. Then for pretraining, we prove that 1) the convolution kernels of the MRP encoder captures all discriminative semantics in the pretraining data; and 2) a convolution kernel captures at most one semantic. Accordingly, in the downstream supervised fine-tuning, most semantics would be captured and different semantics would not be fused together. This helps the downstream fine-tuned network to easily establish the relation between kernels and semantic class labels. In this way, the fine-tuned encoder in MRP provably achieves zero test error with high probability for both multi-view and single-view test data. In contrast, as proved by~[3], conventional SL can only obtain a test accuracy between around $0.5\mu$ for single-view test data. These results together explain the benefits of MRP in downstream tasks. Experimental results testify to multi-view data assumptions and our theoretical implications.
Inception Transformer
May 26, 2022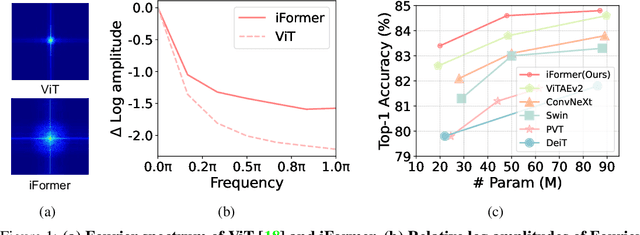
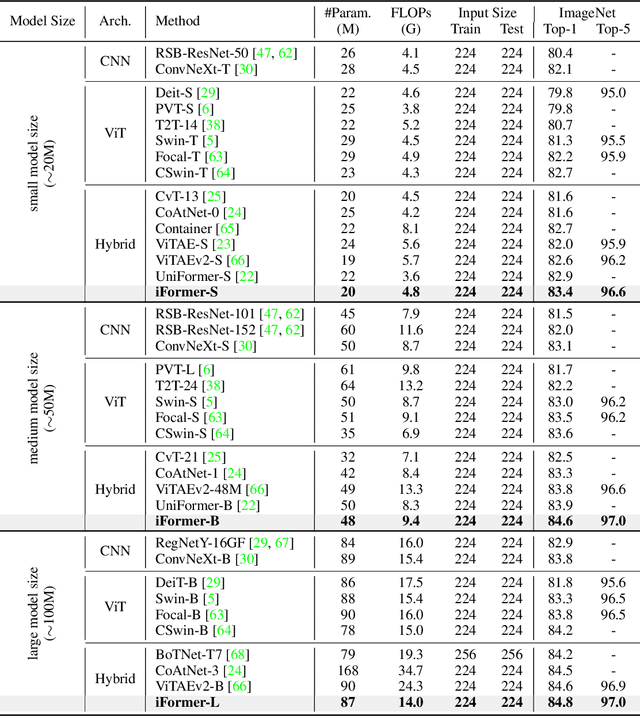
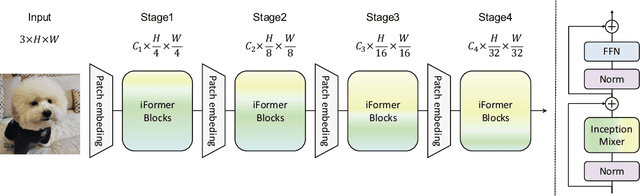
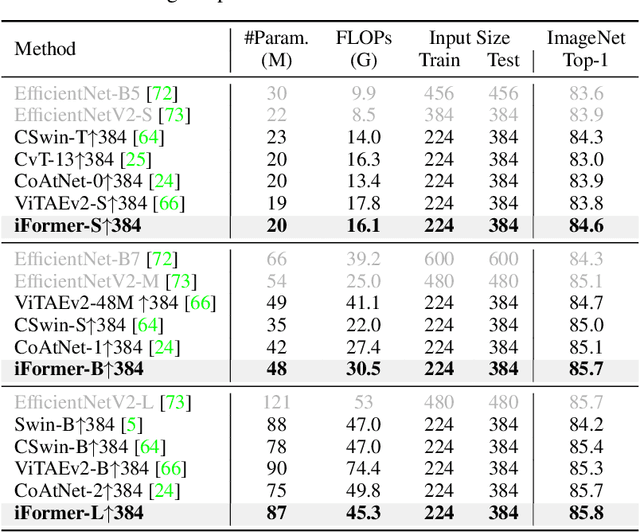
Recent studies show that Transformer has strong capability of building long-range dependencies, yet is incompetent in capturing high frequencies that predominantly convey local information. To tackle this issue, we present a novel and general-purpose Inception Transformer, or iFormer for short, that effectively learns comprehensive features with both high- and low-frequency information in visual data. Specifically, we design an Inception mixer to explicitly graft the advantages of convolution and max-pooling for capturing the high-frequency information to Transformers. Different from recent hybrid frameworks, the Inception mixer brings greater efficiency through a channel splitting mechanism to adopt parallel convolution/max-pooling path and self-attention path as high- and low-frequency mixers, while having the flexibility to model discriminative information scattered within a wide frequency range. Considering that bottom layers play more roles in capturing high-frequency details while top layers more in modeling low-frequency global information, we further introduce a frequency ramp structure, i.e. gradually decreasing the dimensions fed to the high-frequency mixer and increasing those to the low-frequency mixer, which can effectively trade-off high- and low-frequency components across different layers. We benchmark the iFormer on a series of vision tasks, and showcase that it achieves impressive performance on image classification, COCO detection and ADE20K segmentation. For example, our iFormer-S hits the top-1 accuracy of 83.4% on ImageNet-1K, much higher than DeiT-S by 3.6%, and even slightly better than much bigger model Swin-B (83.3%) with only 1/4 parameters and 1/3 FLOPs. Code and models will be released at https://github.com/sail-sg/iFormer.
$O(N^2)$ Universal Antisymmetry in Fermionic Neural Networks
May 26, 2022
Fermionic neural network (FermiNet) is a recently proposed wavefunction Ansatz, which is used in variational Monte Carlo (VMC) methods to solve the many-electron Schr\"odinger equation. FermiNet proposes permutation-equivariant architectures, on which a Slater determinant is applied to induce antisymmetry. FermiNet is proved to have universal approximation capability with a single determinant, namely, it suffices to represent any antisymmetric function given sufficient parameters. However, the asymptotic computational bottleneck comes from the Slater determinant, which scales with $O(N^3)$ for $N$ electrons. In this paper, we substitute the Slater determinant with a pairwise antisymmetry construction, which is easy to implement and can reduce the computational cost to $O(N^2)$. Furthermore, we formally prove that the pairwise construction built upon permutation-equivariant architectures can universally represent any antisymmetric function.
ClusterQ: Semantic Feature Distribution Alignment for Data-Free Quantization
Apr 30, 2022
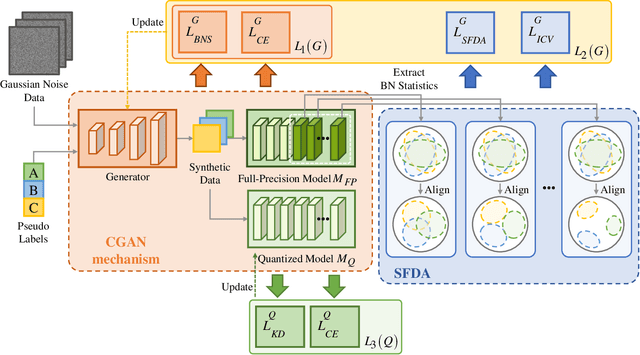
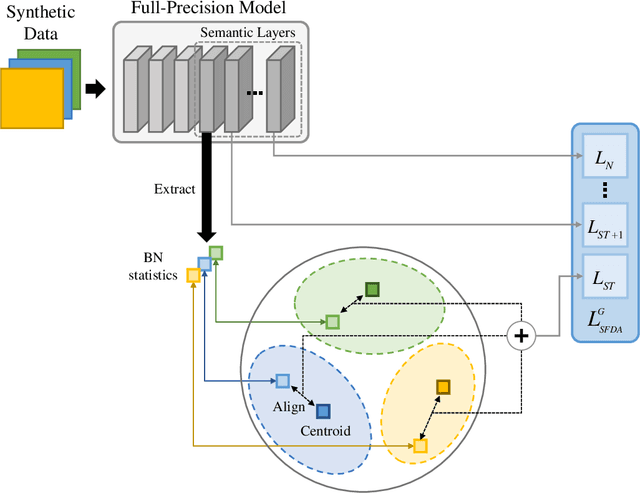
Network quantization has emerged as a promising method for model compression and inference acceleration. However, tradtional quantization methods (such as quantization aware training and post training quantization) require original data for the fine-tuning or calibration of quantized model, which makes them inapplicable to the cases that original data are not accessed due to privacy or security. This gives birth to the data-free quantization with synthetic data generation. While current DFQ methods still suffer from severe performance degradation when quantizing a model into lower bit, caused by the low inter-class separability of semantic features. To this end, we propose a new and effective data-free quantization method termed ClusterQ, which utilizes the semantic feature distribution alignment for synthetic data generation. To obtain high inter-class separability of semantic features, we cluster and align the feature distribution statistics to imitate the distribution of real data, so that the performance degradation is alleviated. Moreover, we incorporate the intra-class variance to solve class-wise mode collapse. We also employ the exponential moving average to update the centroid of each cluster for further feature distribution improvement. Extensive experiments across various deep models (e.g., ResNet-18 and MobileNet-V2) over the ImageNet dataset demonstrate that our ClusterQ obtains state-of-the-art performance.
Improving Vision Transformers by Revisiting High-frequency Components
Apr 03, 2022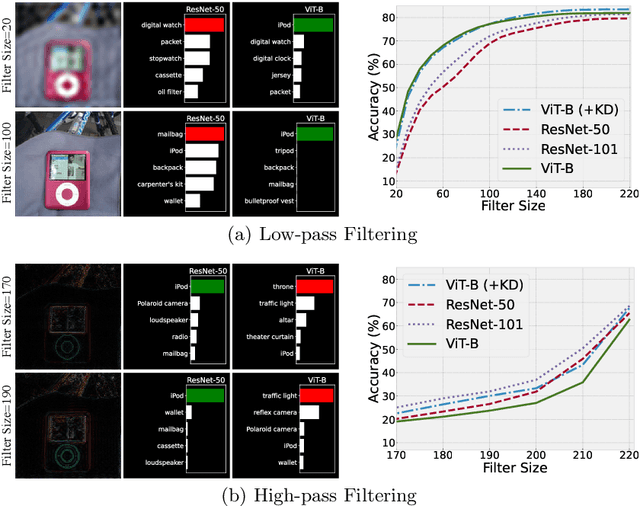

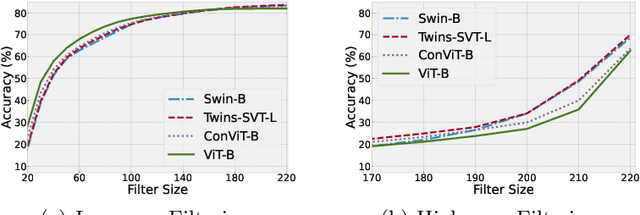
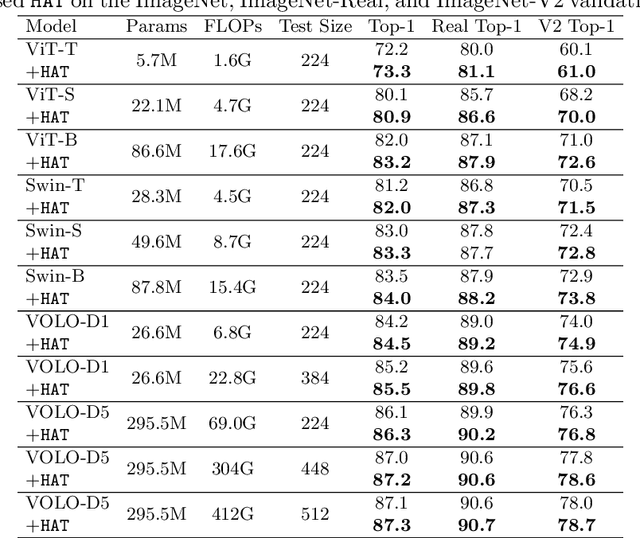
The transformer models have shown promising effectiveness in dealing with various vision tasks. However, compared with training Convolutional Neural Network (CNN) models, training Vision Transformer (ViT) models is more difficult and relies on the large-scale training set. To explain this observation we make a hypothesis that ViT models are less effective in capturing the high-frequency components of images than CNN models, and verify it by a frequency analysis. Inspired by this finding, we first investigate the effects of existing techniques for improving ViT models from a new frequency perspective, and find that the success of some techniques (e.g., RandAugment) can be attributed to the better usage of the high-frequency components. Then, to compensate for this insufficient ability of ViT models, we propose HAT, which directly augments high-frequency components of images via adversarial training. We show that HAT can consistently boost the performance of various ViT models (e.g., +1.2% for ViT-B, +0.5% for Swin-B), and especially enhance the advanced model VOLO-D5 to 87.3% that only uses ImageNet-1K data, and the superiority can also be maintained on out-of-distribution data and transferred to downstream tasks.
Mugs: A Multi-Granular Self-Supervised Learning Framework
Mar 27, 2022
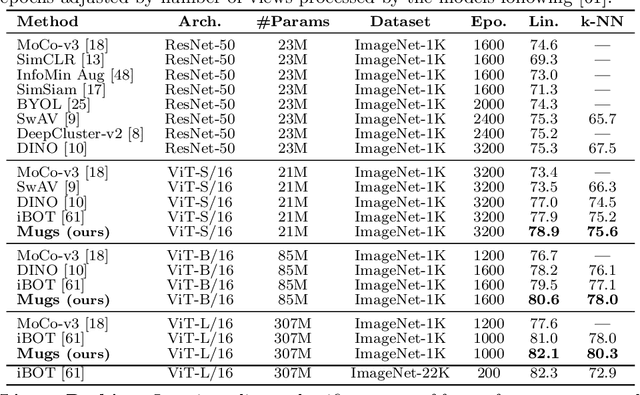
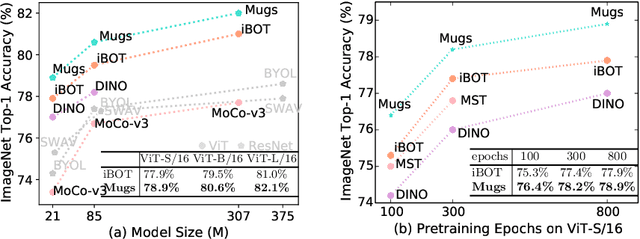
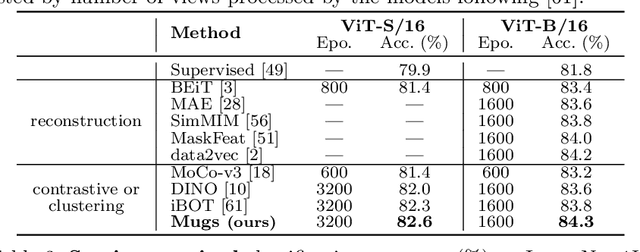
In self-supervised learning, multi-granular features are heavily desired though rarely investigated, as different downstream tasks (e.g., general and fine-grained classification) often require different or multi-granular features, e.g.~fine- or coarse-grained one or their mixture. In this work, for the first time, we propose an effective MUlti-Granular Self-supervised learning (Mugs) framework to explicitly learn multi-granular visual features. Mugs has three complementary granular supervisions: 1) an instance discrimination supervision (IDS), 2) a novel local-group discrimination supervision (LGDS), and 3) a group discrimination supervision (GDS). IDS distinguishes different instances to learn instance-level fine-grained features. LGDS aggregates features of an image and its neighbors into a local-group feature, and pulls local-group features from different crops of the same image together and push them away for others. It provides complementary instance supervision to IDS via an extra alignment on local neighbors, and scatters different local-groups separately to increase discriminability. Accordingly, it helps learn high-level fine-grained features at a local-group level. Finally, to prevent similar local-groups from being scattered randomly or far away, GDS brings similar samples close and thus pulls similar local-groups together, capturing coarse-grained features at a (semantic) group level. Consequently, Mugs can capture three granular features that often enjoy higher generality on diverse downstream tasks over single-granular features, e.g.~instance-level fine-grained features in contrastive learning. By only pretraining on ImageNet-1K, Mugs sets new SoTA linear probing accuracy 82.1$\%$ on ImageNet-1K and improves previous SoTA by $1.1\%$. It also surpasses SoTAs on other tasks, e.g. transfer learning, detection and segmentation.
Self-Promoted Supervision for Few-Shot Transformer
Mar 14, 2022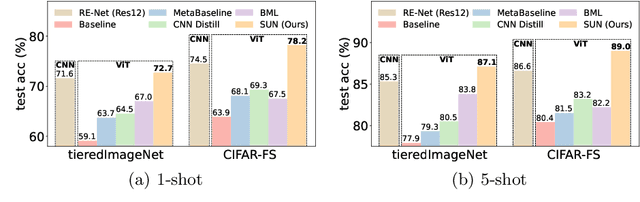
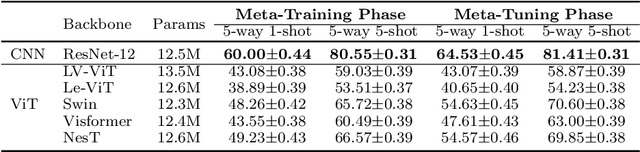
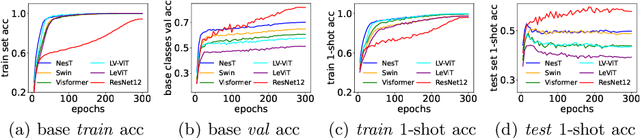
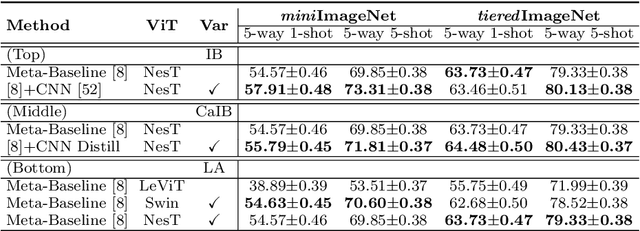
The few-shot learning ability of vision transformers (ViTs) is rarely investigated though heavily desired. In this work, we empirically find that with the same few-shot learning frameworks, e.g., Meta-Baseline, replacing the widely used CNN feature extractor with a ViT model often severely impairs few-shot classification performance. Moreover, our empirical study shows that in the absence of inductive bias, ViTs often learn the dependencies among input tokens slowly under few-shot learning regime where only a few labeled training data are available, which largely contributes to the above performance degradation. To alleviate this issue, for the first time, we propose a simple yet effective few-shot training framework for ViTs, namely Self-promoted sUpervisioN (SUN). Specifically, besides the conventional global supervision for global semantic learning, SUN further pretrains the ViT on the few-shot learning dataset and then uses it to generate individual location-specific supervision for guiding each patch token. This location-specific supervision tells the ViT which patch tokens are similar or dissimilar and thus accelerates token dependency learning. Moreover, it models the local semantics in each patch token to improve the object grounding and recognition capability which helps learn generalizable patterns. To improve the quality of location-specific supervision, we further propose two techniques:~1) background patch filtration to filtrate background patches out and assign them into an extra background class; and 2) spatial-consistent augmentation to introduce sufficient diversity for data augmentation while keeping the accuracy of the generated local supervisions. Experimental results show that SUN using ViTs significantly surpasses other few-shot learning frameworks with ViTs and is the first one that achieves higher performance than those CNN state-of-the-arts.