 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuhui Wang
IR-GAN: Image Manipulation with Linguistic Instruction by Increment Reasoning
Apr 02, 2022
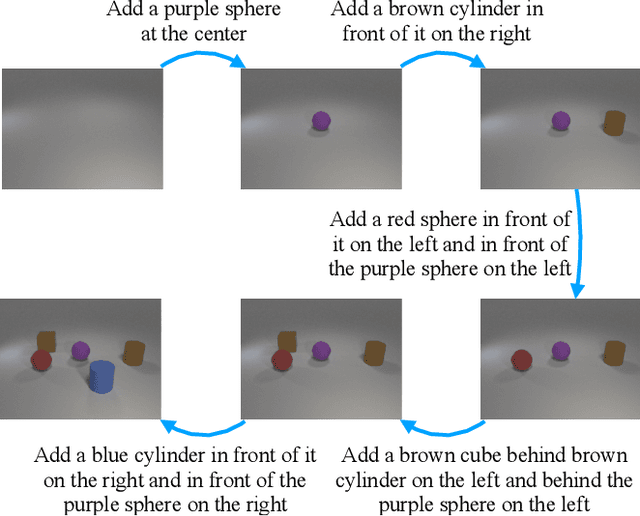
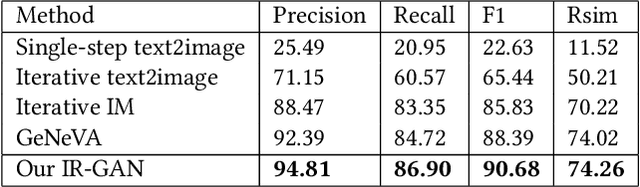
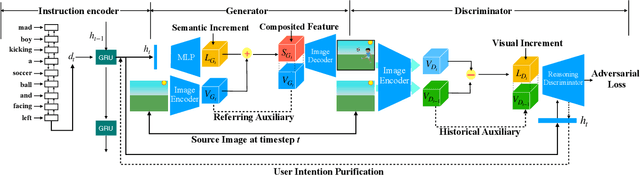
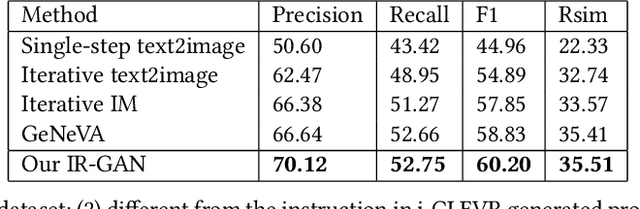
Conditional image generation is an active research topic including text2image and image translation. Recently image manipulation with linguistic instruction brings new challenges of multimodal conditional generation. However, traditional conditional image generation models mainly focus on generating high-quality and visually realistic images, and lack resolving the partial consistency between image and instruction. To address this issue, we propose an Increment Reasoning Generative Adversarial Network (IR-GAN), which aims to reason the consistency between visual increment in images and semantic increment in instructions. First, we introduce the word-level and instruction-level instruction encoders to learn user's intention from history-correlated instructions as semantic increment. Second, we embed the representation of semantic increment into that of source image for generating target image, where source image plays the role of referring auxiliary. Finally, we propose a reasoning discriminator to measure the consistency between visual increment and semantic increment, which purifies user's intention and guarantees the good logic of generated target image. Extensive experiments and visualization conducted on two datasets show the effectiveness of IR-GAN.
Attribute Group Editing for Reliable Few-shot Image Generation
Mar 16, 2022
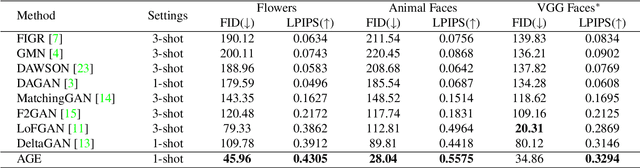
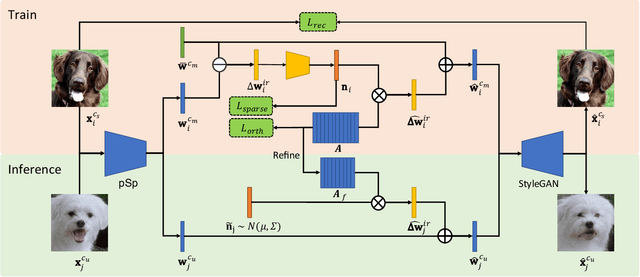
Few-shot image generation is a challenging task even using the state-of-the-art Generative Adversarial Networks (GANs). Due to the unstable GAN training process and the limited training data, the generated images are often of low quality and low diversity. In this work, we propose a new editing-based method, i.e., Attribute Group Editing (AGE), for few-shot image generation. The basic assumption is that any image is a collection of attributes and the editing direction for a specific attribute is shared across all categories. AGE examines the internal representation learned in GANs and identifies semantically meaningful directions. Specifically, the class embedding, i.e., the mean vector of the latent codes from a specific category, is used to represent the category-relevant attributes, and the category-irrelevant attributes are learned globally by Sparse Dictionary Learning on the difference between the sample embedding and the class embedding. Given a GAN well trained on seen categories, diverse images of unseen categories can be synthesized through editing category-irrelevant attributes while keeping category-relevant attributes unchanged. Without re-training the GAN, AGE is capable of not only producing more realistic and diverse images for downstream visual applications with limited data but achieving controllable image editing with interpretable category-irrelevant directions.
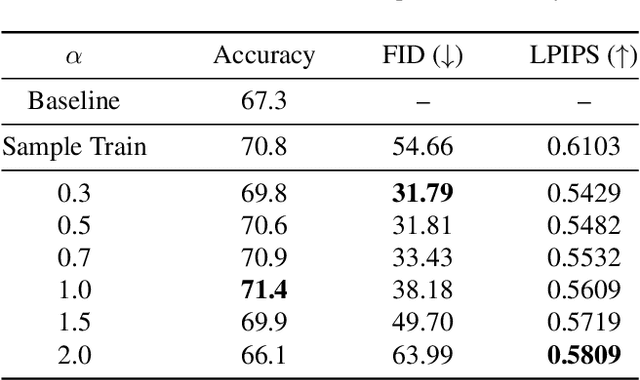
General Greedy De-bias Learning
Dec 21, 2021
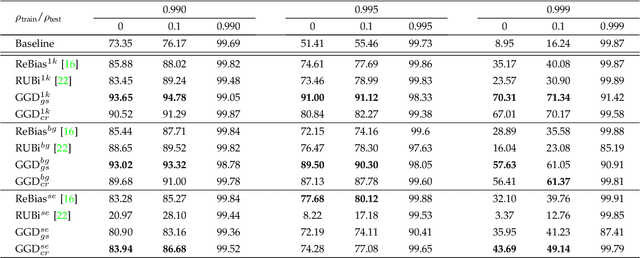
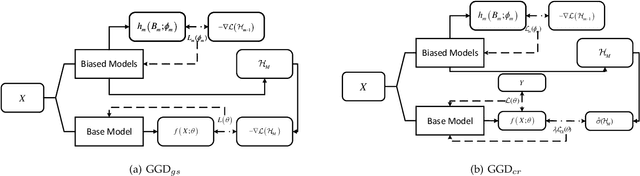
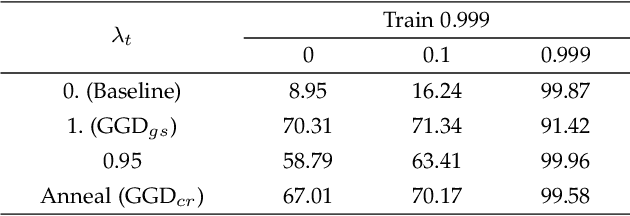
Neural networks often make predictions relying on the spurious correlations from the datasets rather than the intrinsic properties of the task of interest, facing sharp degradation on out-of-distribution (OOD) test data. Existing de-bias learning frameworks try to capture specific dataset bias by bias annotations, they fail to handle complicated OOD scenarios. Others implicitly identify the dataset bias by the special design on the low capability biased model or the loss, but they degrade when the training and testing data are from the same distribution. In this paper, we propose a General Greedy De-bias learning framework (GGD), which greedily trains the biased models and the base model like gradient descent in functional space. It encourages the base model to focus on examples that are hard to solve with biased models, thus remaining robust against spurious correlations in the test stage. GGD largely improves models' OOD generalization ability on various tasks, but sometimes over-estimates the bias level and degrades on the in-distribution test. We further re-analyze the ensemble process of GGD and introduce the Curriculum Regularization into GGD inspired by curriculum learning, which achieves a good trade-off between in-distribution and out-of-distribution performance. Extensive experiments on image classification, adversarial question answering, and visual question answering demonstrate the effectiveness of our method. GGD can learn a more robust base model under the settings of both task-specific biased models with prior knowledge and self-ensemble biased model without prior knowledge.
Hierarchical Modular Network for Video Captioning
Nov 25, 2021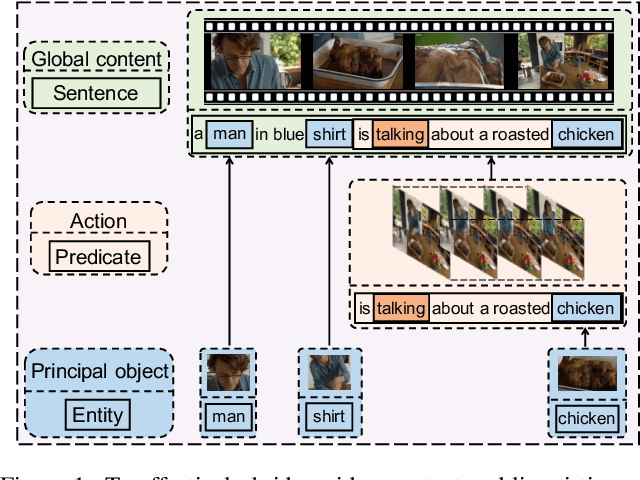
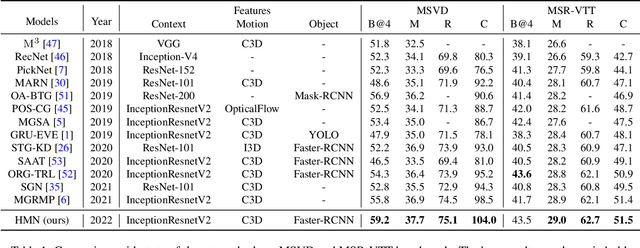
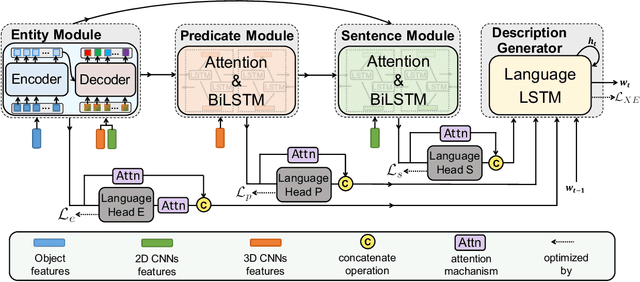
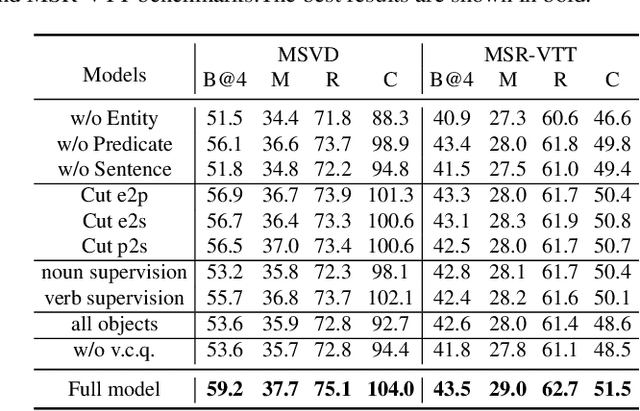
Video captioning aims to generate natural language descriptions according to the content, where representation learning plays a crucial role. Existing methods are mainly developed within the supervised learning framework via word-by-word comparison of the generated caption against the ground-truth text without fully exploiting linguistic semantics. In this work, we propose a hierarchical modular network to bridge video representations and linguistic semantics from three levels before generating captions. In particular, the hierarchy is composed of: (I) Entity level, which highlights objects that are most likely to be mentioned in captions. (II) Predicate level, which learns the actions conditioned on highlighted objects and is supervised by the predicate in captions. (III) Sentence level, which learns the global semantic representation and is supervised by the whole caption. Each level is implemented by one module. Extensive experimental results show that the proposed method performs favorably against the state-of-the-art models on the two widely-used benchmarks: MSVD 104.0% and MSR-VTT 51.5% in CIDEr score.
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Nov 23, 2021
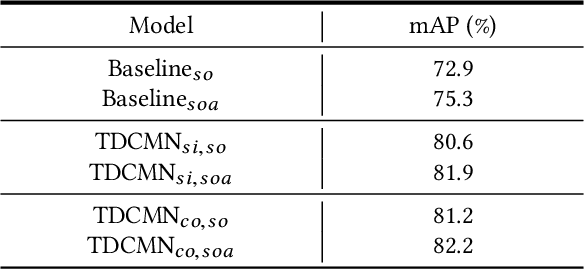
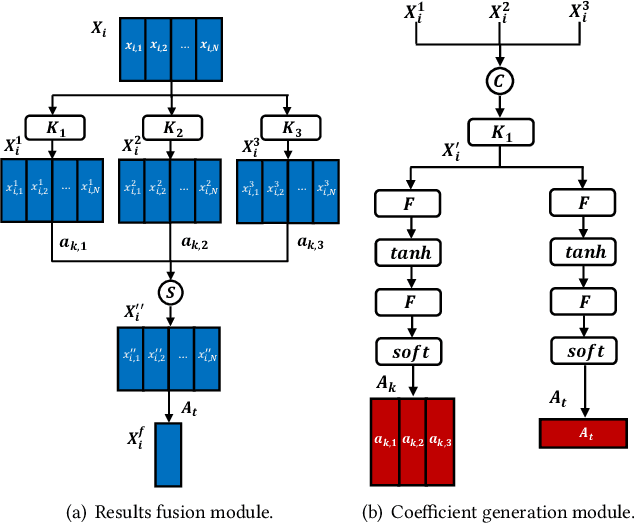
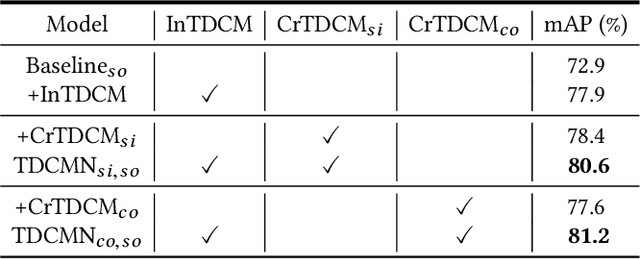
Event analysis in untrimmed videos has attracted increasing attention due to the application of cutting-edge techniques such as CNN. As a well studied property for CNN-based models, the receptive field is a measurement for measuring the spatial range covered by a single feature response, which is crucial in improving the image categorization accuracy. In video domain, video event semantics are actually described by complex interaction among different concepts, while their behaviors vary drastically from one video to another, leading to the difficulty in concept-based analytics for accurate event categorization. To model the concept behavior, we study temporal concept receptive field of concept-based event representation, which encodes the temporal occurrence pattern of different mid-level concepts. Accordingly, we introduce temporal dynamic convolution (TDC) to give stronger flexibility to concept-based event analytics. TDC can adjust the temporal concept receptive field size dynamically according to different inputs. Notably, a set of coefficients are learned to fuse the results of multiple convolutions with different kernel widths that provide various temporal concept receptive field sizes. Different coefficients can generate appropriate and accurate temporal concept receptive field size according to input videos and highlight crucial concepts. Based on TDC, we propose the temporal dynamic concept modeling network (TDCMN) to learn an accurate and complete concept representation for efficient untrimmed video analysis. Experiment results on FCVID and ActivityNet show that TDCMN demonstrates adaptive event recognition ability conditioned on different inputs, and improve the event recognition performance of Concept-based methods by a large margin. Code is available at https://github.com/qzhb/TDCMN.
Self-Regulated Learning for Egocentric Video Activity Anticipation
Nov 23, 2021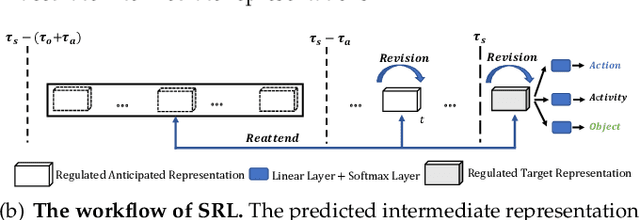
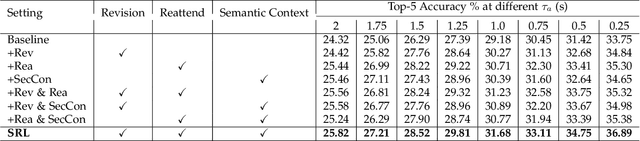
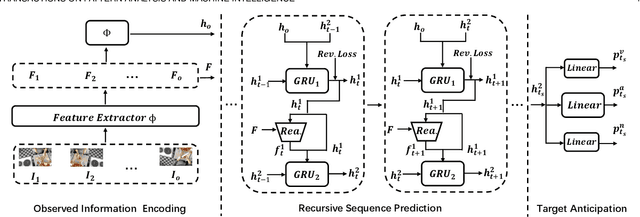
Future activity anticipation is a challenging problem in egocentric vision. As a standard future activity anticipation paradigm, recursive sequence prediction suffers from the accumulation of errors. To address this problem, we propose a simple and effective Self-Regulated Learning framework, which aims to regulate the intermediate representation consecutively to produce representation that (a) emphasizes the novel information in the frame of the current time-stamp in contrast to previously observed content, and (b) reflects its correlation with previously observed frames. The former is achieved by minimizing a contrastive loss, and the latter can be achieved by a dynamic reweighing mechanism to attend to informative frames in the observed content with a similarity comparison between feature of the current frame and observed frames. The learned final video representation can be further enhanced by multi-task learning which performs joint feature learning on the target activity labels and the automatically detected action and object class tokens. SRL sharply outperforms existing state-of-the-art in most cases on two egocentric video datasets and two third-person video datasets. Its effectiveness is also verified by the experimental fact that the action and object concepts that support the activity semantics can be accurately identified.
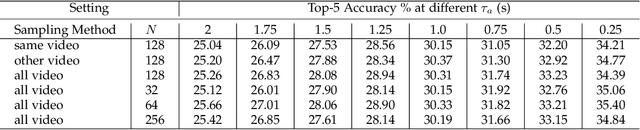
DVCFlow: Modeling Information Flow Towards Human-like Video Captioning
Nov 19, 2021
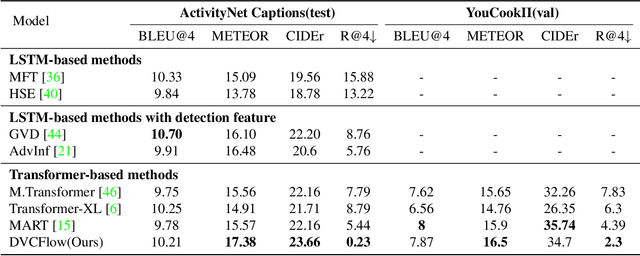
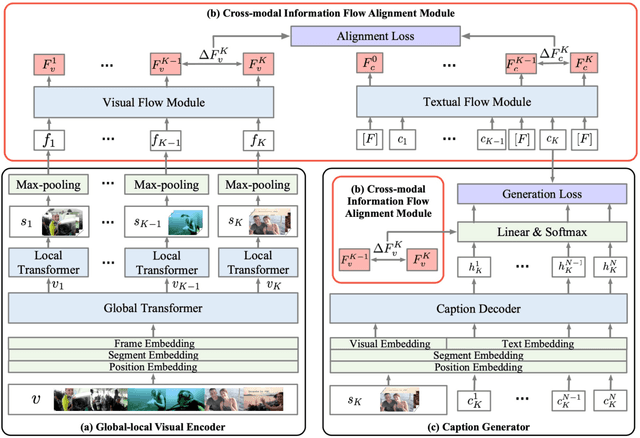
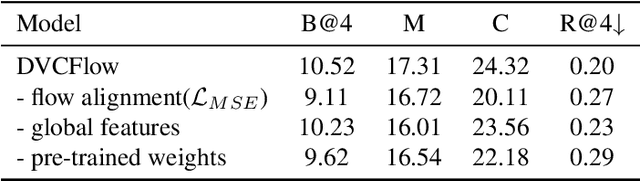
Dense video captioning (DVC) aims to generate multi-sentence descriptions to elucidate the multiple events in the video, which is challenging and demands visual consistency, discoursal coherence, and linguistic diversity. Existing methods mainly generate captions from individual video segments, lacking adaptation to the global visual context and progressive alignment between the fast-evolved visual content and textual descriptions, which results in redundant and spliced descriptions. In this paper, we introduce the concept of information flow to model the progressive information changing across video sequence and captions. By designing a Cross-modal Information Flow Alignment mechanism, the visual and textual information flows are captured and aligned, which endows the captioning process with richer context and dynamics on event/topic evolution. Based on the Cross-modal Information Flow Alignment module, we further put forward DVCFlow framework, which consists of a Global-local Visual Encoder to capture both global features and local features for each video segment, and a pre-trained Caption Generator to produce captions. Extensive experiments on the popular ActivityNet Captions and YouCookII datasets demonstrate that our method significantly outperforms competitive baselines, and generates more human-like text according to subject and objective tests.
Semi-Autoregressive Image Captioning
Oct 13, 2021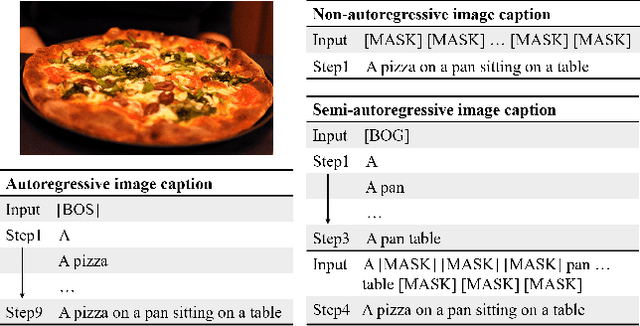
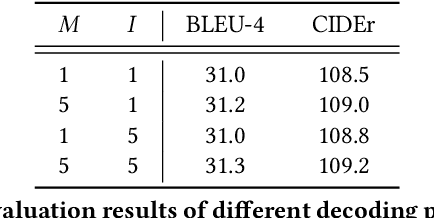
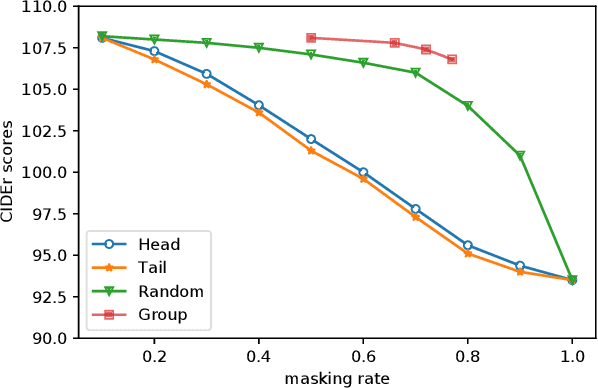
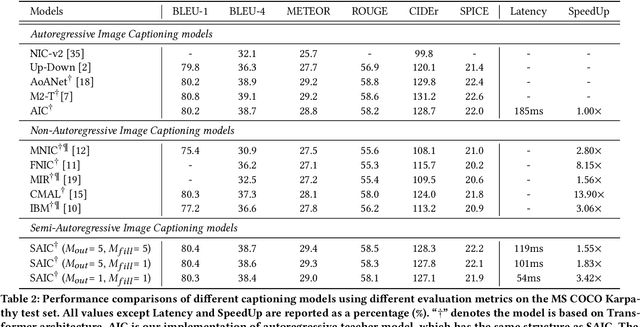
Current state-of-the-art approaches for image captioning typically adopt an autoregressive manner, i.e., generating descriptions word by word, which suffers from slow decoding issue and becomes a bottleneck in real-time applications. Non-autoregressive image captioning with continuous iterative refinement, which eliminates the sequential dependence in a sentence generation, can achieve comparable performance to the autoregressive counterparts with a considerable acceleration. Nevertheless, based on a well-designed experiment, we empirically proved that iteration times can be effectively reduced when providing sufficient prior knowledge for the language decoder. Towards that end, we propose a novel two-stage framework, referred to as Semi-Autoregressive Image Captioning (SAIC), to make a better trade-off between performance and speed. The proposed SAIC model maintains autoregressive property in global but relieves it in local. Specifically, SAIC model first jumpily generates an intermittent sequence in an autoregressive manner, that is, it predicts the first word in every word group in order. Then, with the help of the partially deterministic prior information and image features, SAIC model non-autoregressively fills all the skipped words with one iteration. Experimental results on the MS COCO benchmark demonstrate that our SAIC model outperforms the preceding non-autoregressive image captioning models while obtaining a competitive inference speedup. Code is available at https://github.com/feizc/SAIC.
Greedy Gradient Ensemble for Robust Visual Question Answering
Aug 23, 2021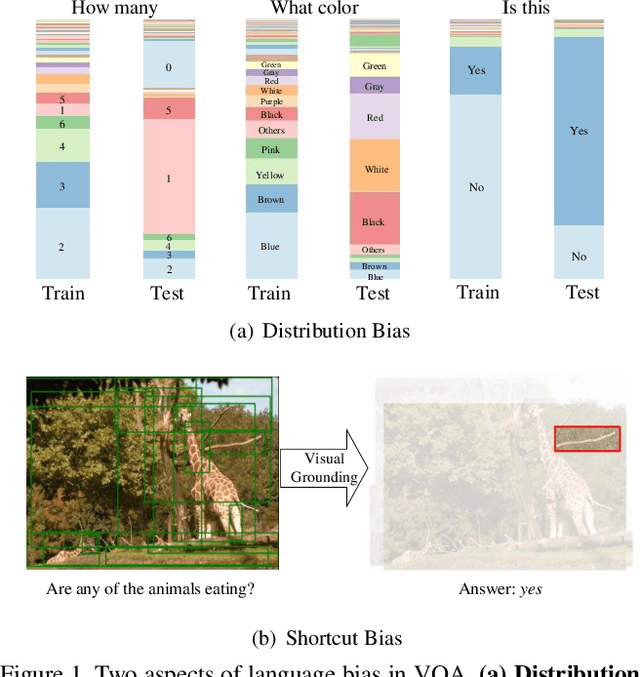
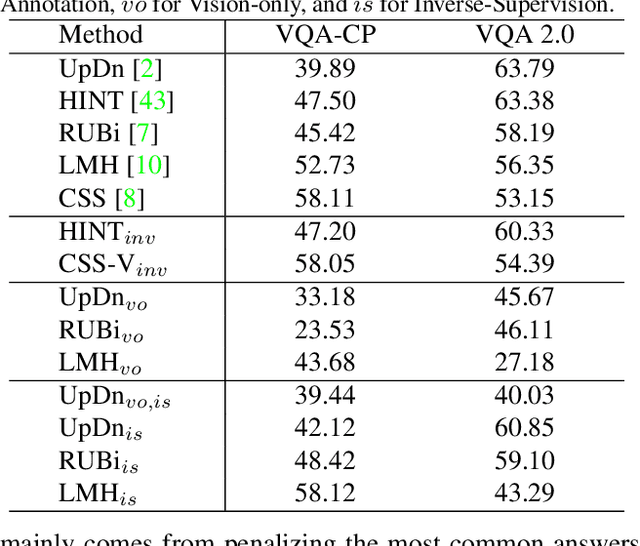
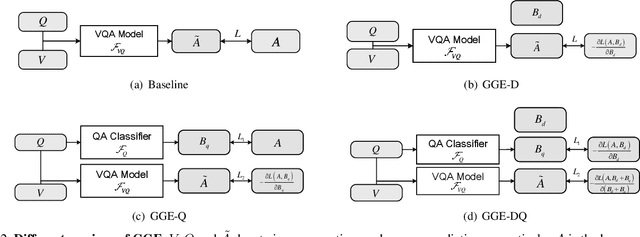
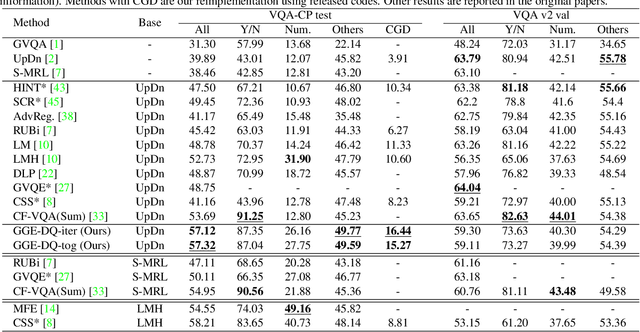
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.