 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShlomo Dubnov
Multitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments
Jul 14, 2022
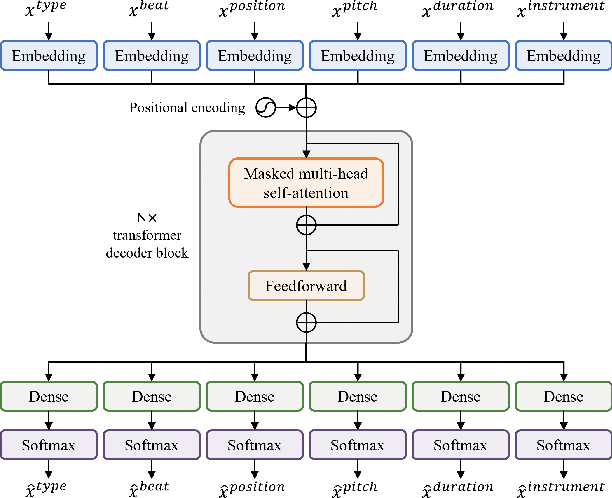
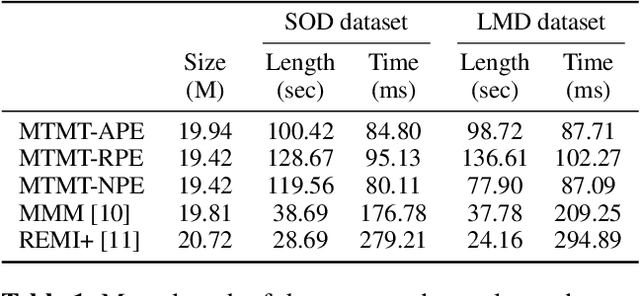
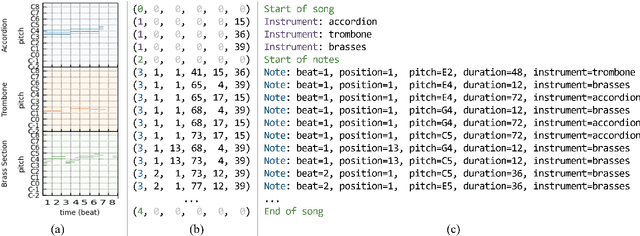
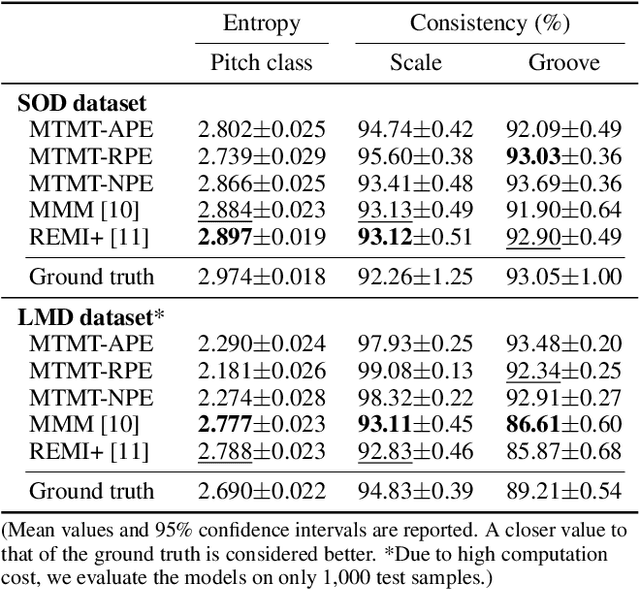
Existing approaches for generating multitrack music with transformer models have been limited to either a small set of instruments or short music segments. This is partly due to the memory requirements of the lengthy input sequences necessitated by existing representations for multitrack music. In this work, we propose a compact representation that allows a diverse set of instruments while keeping a short sequence length. Using our proposed representation, we present the Multitrack Music Transformer (MTMT) for learning long-term dependencies in multitrack music. In a subjective listening test, our proposed model achieves competitive quality on unconditioned generation against two baseline models. We also show that our proposed model can generate samples that are twice as long as those produced by the baseline models, and, further, can do so in half the inference time. Moreover, we propose a new measure for analyzing musical self-attentions and show that the trained model learns to pay less attention to notes that form a dissonant interval with the current note, yet attending more to notes that are 4N beats away from current. Finally, our findings provide a novel foundation for future work exploring longer-form multitrack music generation and improving self-attentions for music. All source code and audio samples can be found at https://salu133445.github.io/mtmt/ .
TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
Feb 02, 2022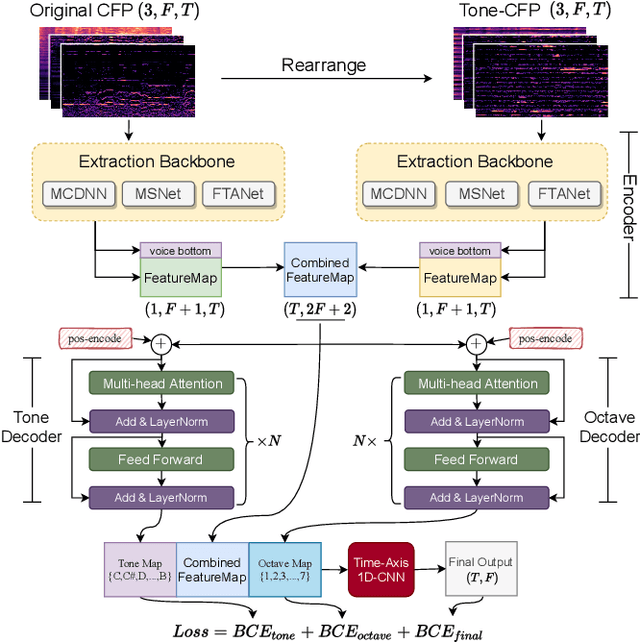
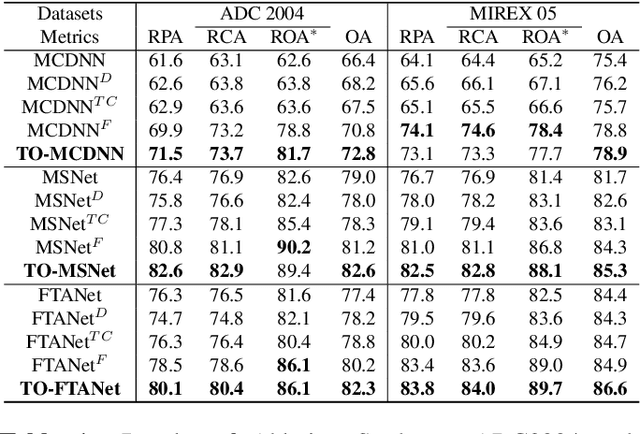
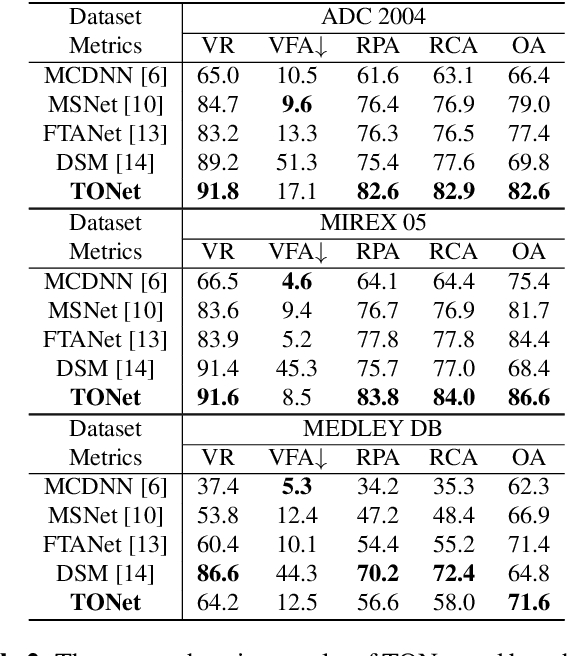
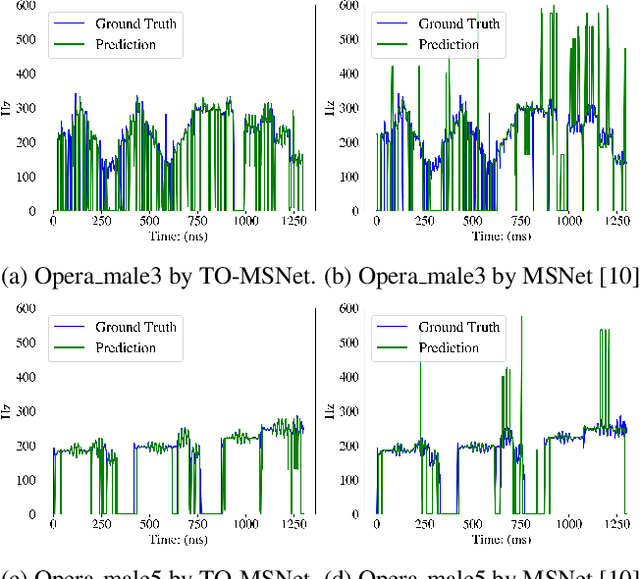
Singing melody extraction is an important problem in the field of music information retrieval. Existing methods typically rely on frequency-domain representations to estimate the sung frequencies. However, this design does not lead to human-level performance in the perception of melody information for both tone (pitch-class) and octave. In this paper, we propose TONet, a plug-and-play model that improves both tone and octave perceptions by leveraging a novel input representation and a novel network architecture. First, we present an improved input representation, the Tone-CFP, that explicitly groups harmonics via a rearrangement of frequency-bins. Second, we introduce an encoder-decoder architecture that is designed to obtain a salience feature map, a tone feature map, and an octave feature map. Third, we propose a tone-octave fusion mechanism to improve the final salience feature map. Experiments are done to verify the capability of TONet with various baseline backbone models. Our results show that tone-octave fusion with Tone-CFP can significantly improve the singing voice extraction performance across various datasets -- with substantial gains in octave and tone accuracy.
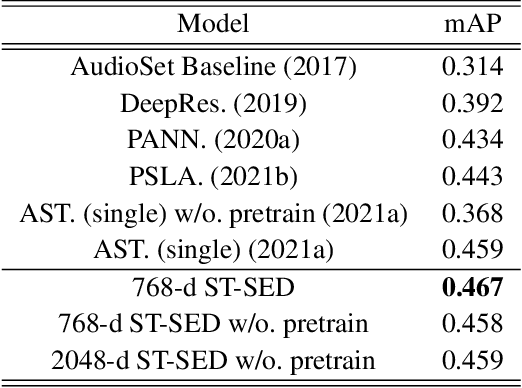
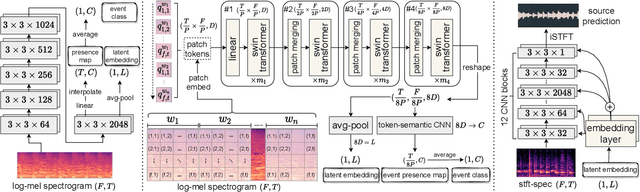
HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection
Feb 02, 2022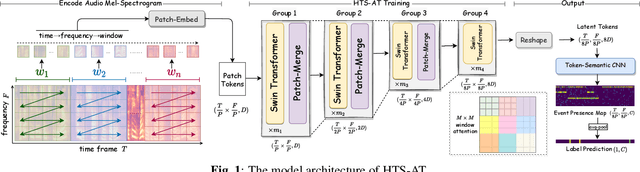
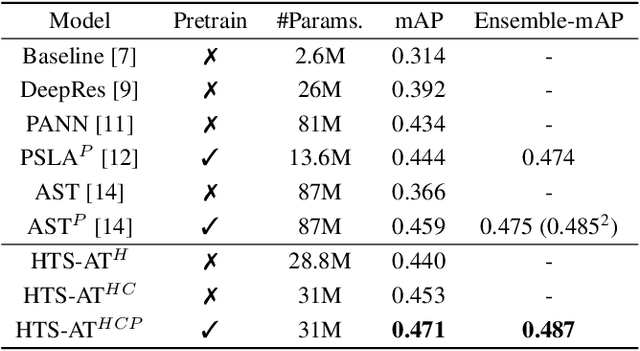
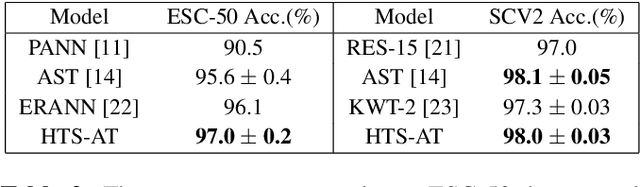

Audio classification is an important task of mapping audio samples into their corresponding labels. Recently, the transformer model with self-attention mechanisms has been adopted in this field. However, existing audio transformers require large GPU memories and long training time, meanwhile relying on pretrained vision models to achieve high performance, which limits the model's scalability in audio tasks. To combat these problems, we introduce HTS-AT: an audio transformer with a hierarchical structure to reduce the model size and training time. It is further combined with a token-semantic module to map final outputs into class featuremaps, thus enabling the model for the audio event detection (i.e. localization in time). We evaluate HTS-AT on three datasets of audio classification where it achieves new state-of-the-art (SOTA) results on AudioSet and ESC-50, and equals the SOTA on Speech Command V2. It also achieves better performance in event localization than the previous CNN-based models. Moreover, HTS-AT requires only 35% model parameters and 15% training time of the previous audio transformer. These results demonstrate the high performance and high efficiency of HTS-AT.
Zero-shot Audio Source Separation through Query-based Learning from Weakly-labeled Data
Jan 12, 2022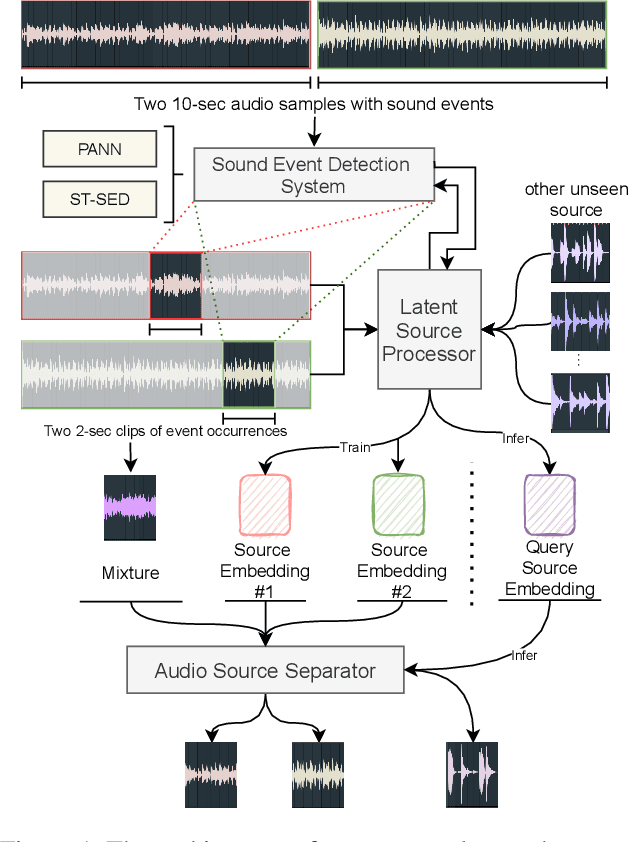
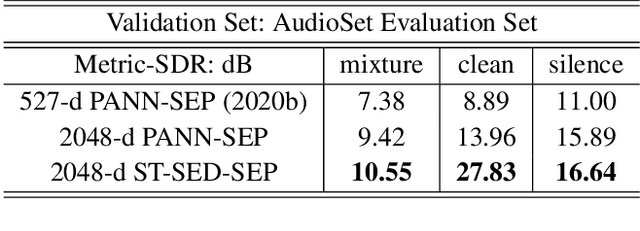
Deep learning techniques for separating audio into different sound sources face several challenges. Standard architectures require training separate models for different types of audio sources. Although some universal separators employ a single model to target multiple sources, they have difficulty generalizing to unseen sources. In this paper, we propose a three-component pipeline to train a universal audio source separator from a large, but weakly-labeled dataset: AudioSet. First, we propose a transformer-based sound event detection system for processing weakly-labeled training data. Second, we devise a query-based audio separation model that leverages this data for model training. Third, we design a latent embedding processor to encode queries that specify audio targets for separation, allowing for zero-shot generalization. Our approach uses a single model for source separation of multiple sound types, and relies solely on weakly-labeled data for training. In addition, the proposed audio separator can be used in a zero-shot setting, learning to separate types of audio sources that were never seen in training. To evaluate the separation performance, we test our model on MUSDB18, while training on the disjoint AudioSet. We further verify the zero-shot performance by conducting another experiment on audio source types that are held-out from training. The model achieves comparable Source-to-Distortion Ratio (SDR) performance to current supervised models in both cases.
Towards Cross-Cultural Analysis using Music Information Dynamics
Nov 24, 2021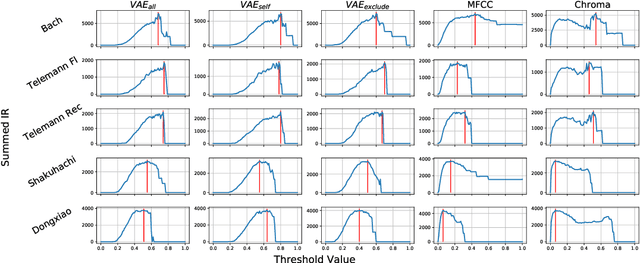
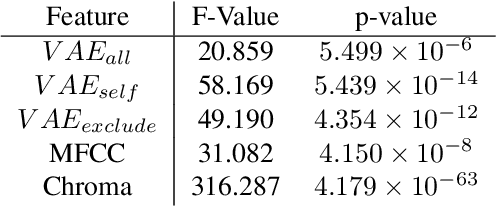
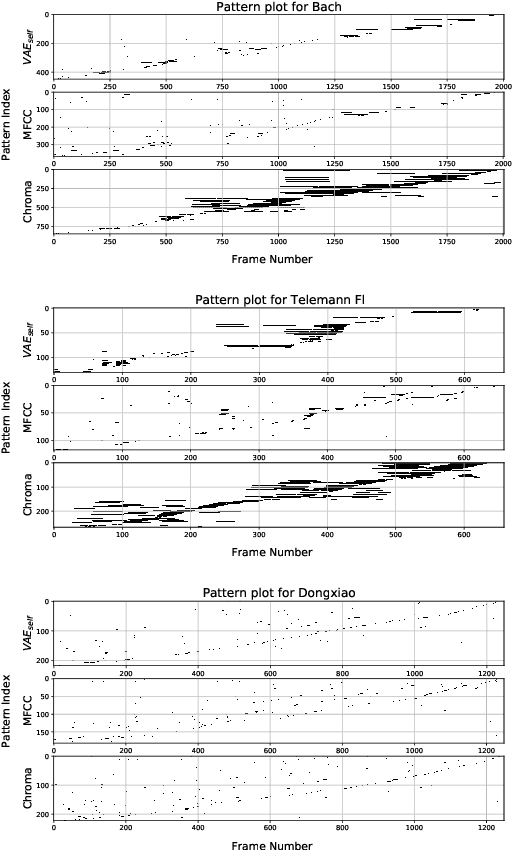
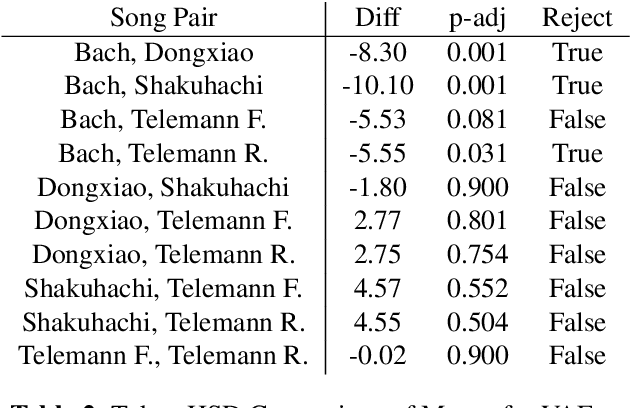
A music piece is both comprehended hierarchically, from sonic events to melodies, and sequentially, in the form of repetition and variation. Music from different cultures establish different aesthetics by having different style conventions on these two aspects. We propose a framework that could be used to quantitatively compare music from different cultures by looking at these two aspects. The framework is based on an Music Information Dynamics model, a Variable Markov Oracle (VMO), and is extended with a variational representation learning of audio. A variational autoencoder (VAE) is trained to map audio fragments into a latent representation. The latent representation is fed into a VMO. The VMO then learns a clustering of the latent representation via a threshold that maximizes the information rate of the quantized latent representation sequence. This threshold effectively controls the sensibility of the predictive step to acoustic changes, which determines the framework's ability to track repetitions on longer time scales. This approach allows characterization of the overall information contents of a musical signal at each level of acoustic sensibility. Our findings under this framework show that sensibility to subtle acoustic changes is higher for East-Asian musical traditions, while the Western works exhibit longer motivic structures at higher thresholds of differences in the latent space. This suggests that a profile of information contents, analyzed as a function of the level of acoustic detail can serve as a possible cultural characteristic.
Comparison and Analysis of Deep Audio Embeddings for Music Emotion Recognition
Apr 13, 2021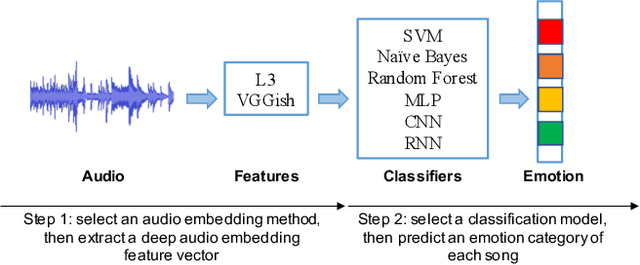
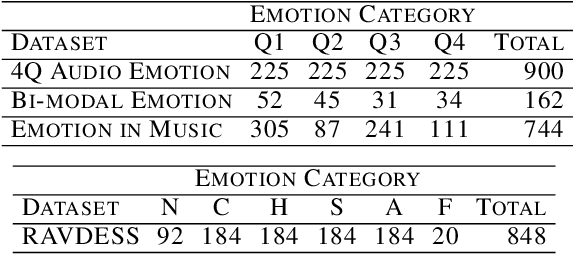
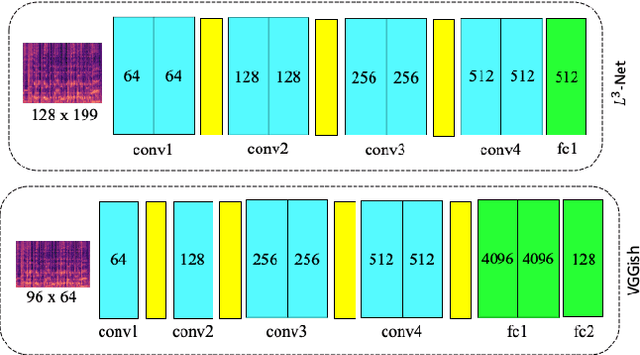
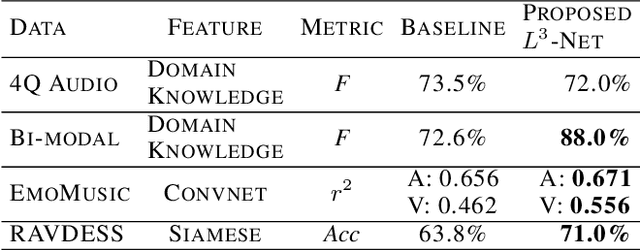
Emotion is a complicated notion present in music that is hard to capture even with fine-tuned feature engineering. In this paper, we investigate the utility of state-of-the-art pre-trained deep audio embedding methods to be used in the Music Emotion Recognition (MER) task. Deep audio embedding methods allow us to efficiently capture the high dimensional features into a compact representation. We implement several multi-class classifiers with deep audio embeddings to predict emotion semantics in music. We investigate the effectiveness of L3-Net and VGGish deep audio embedding methods for music emotion inference over four music datasets. The experiments with several classifiers on the task show that the deep audio embedding solutions can improve the performances of the previous baseline MER models. We conclude that deep audio embeddings represent musical emotion semantics for the MER task without expert human engineering.
* AAAI Workshop on Affective Content Analysis 2021 Camera Ready Version
Bias-Free FedGAN
Mar 17, 2021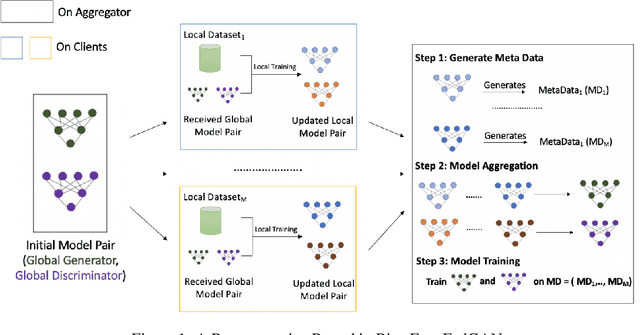

Federated Generative Adversarial Network (FedGAN) is a communication-efficient approach to train a GAN across distributed clients without clients having to share their sensitive training data. In this paper, we experimentally show that FedGAN generates biased data points under non-independent-and-identically-distributed (non-iid) settings. Also, we propose Bias-Free FedGAN, an approach to generate bias-free synthetic datasets using FedGAN. Bias-Free FedGAN has the same communication cost as that of FedGAN. Experimental results on image datasets (MNIST and FashionMNIST) validate our claims.
WaveGuard: Understanding and Mitigating Audio Adversarial Examples
Mar 04, 2021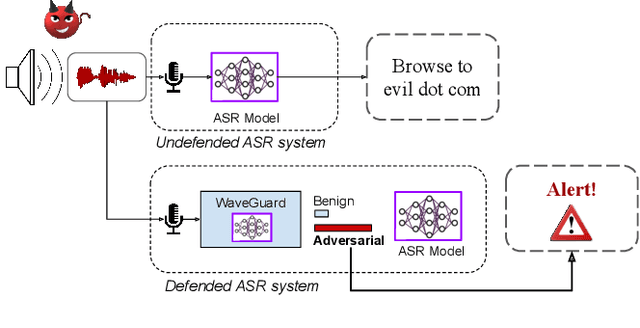

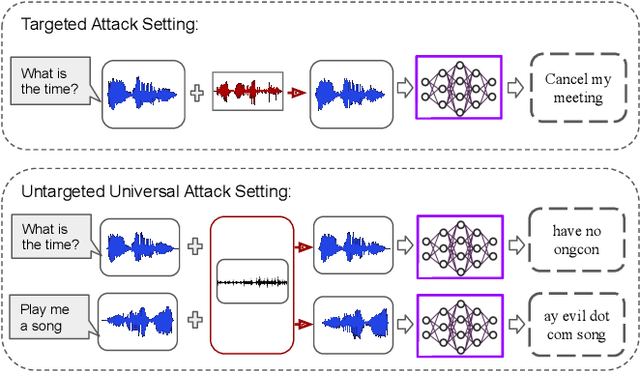
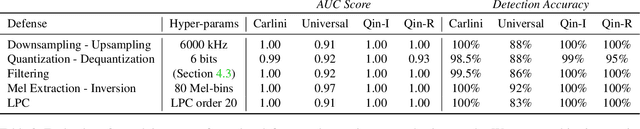
There has been a recent surge in adversarial attacks on deep learning based automatic speech recognition (ASR) systems. These attacks pose new challenges to deep learning security and have raised significant concerns in deploying ASR systems in safety-critical applications. In this work, we introduce WaveGuard: a framework for detecting adversarial inputs that are crafted to attack ASR systems. Our framework incorporates audio transformation functions and analyses the ASR transcriptions of the original and transformed audio to detect adversarial inputs. We demonstrate that our defense framework is able to reliably detect adversarial examples constructed by four recent audio adversarial attacks, with a variety of audio transformation functions. With careful regard for best practices in defense evaluations, we analyze our proposed defense and its strength to withstand adaptive and robust attacks in the audio domain. We empirically demonstrate that audio transformations that recover audio from perceptually informed representations can lead to a strong defense that is robust against an adaptive adversary even in a complete white-box setting. Furthermore, WaveGuard can be used out-of-the box and integrated directly with any ASR model to efficiently detect audio adversarial examples, without the need for model retraining.
Cross-modal Adversarial Reprogramming
Feb 15, 2021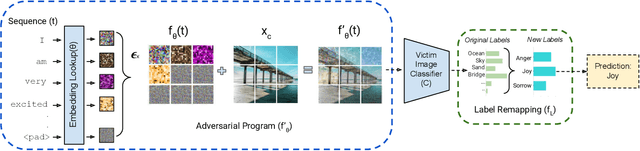
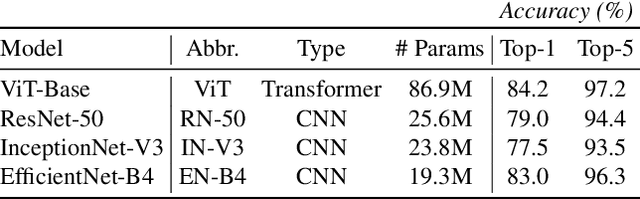
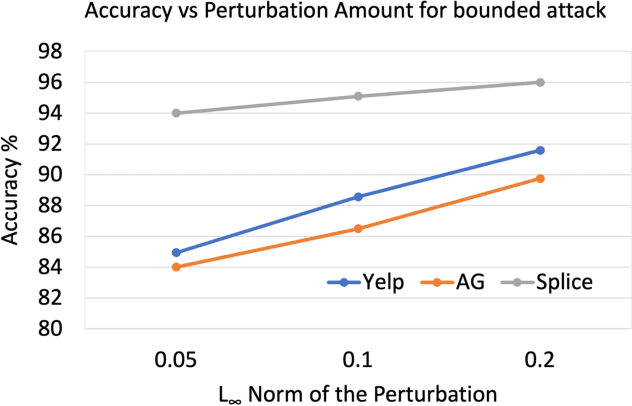
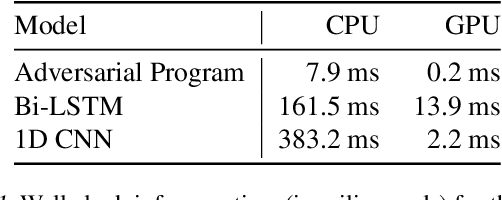
With the abundance of large-scale deep learning models, it has become possible to repurpose pre-trained networks for new tasks. Recent works on adversarial reprogramming have shown that it is possible to repurpose neural networks for alternate tasks without modifying the network architecture or parameters. However these works only consider original and target tasks within the same data domain. In this work, we broaden the scope of adversarial reprogramming beyond the data modality of the original task. We analyze the feasibility of adversarially repurposing image classification neural networks for Natural Language Processing (NLP) and other sequence classification tasks. We design an efficient adversarial program that maps a sequence of discrete tokens into an image which can be classified to the desired class by an image classification model. We demonstrate that by using highly efficient adversarial programs, we can reprogram image classifiers to achieve competitive performance on a variety of text and sequence classification benchmarks without retraining the network.