 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarvesting Creative Templates for Generating Stylistically Varied Restaurant Reviews
Sep 15, 2017
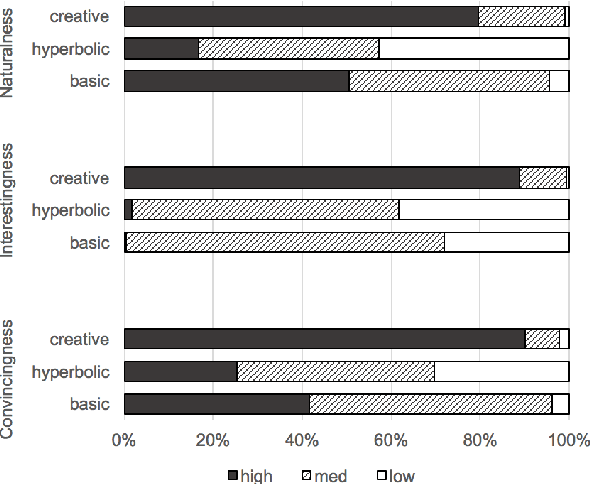
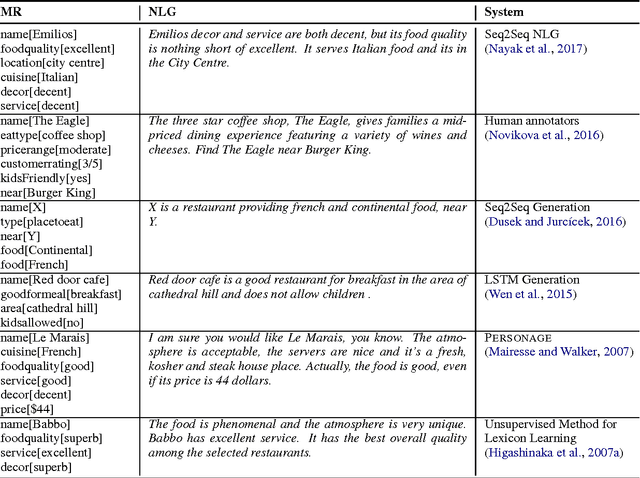
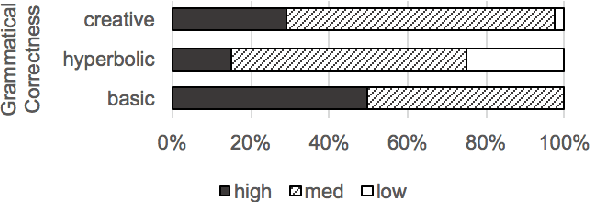
Many of the creative and figurative elements that make language exciting are lost in translation in current natural language generation engines. In this paper, we explore a method to harvest templates from positive and negative reviews in the restaurant domain, with the goal of vastly expanding the types of stylistic variation available to the natural language generator. We learn hyperbolic adjective patterns that are representative of the strongly-valenced expressive language commonly used in either positive or negative reviews. We then identify and delexicalize entities, and use heuristics to extract generation templates from review sentences. We evaluate the learned templates against more traditional review templates, using subjective measures of "convincingness", "interestingness", and "naturalness". Our results show that the learned templates score highly on these measures. Finally, we analyze the linguistic categories that characterize the learned positive and negative templates. We plan to use the learned templates to improve the conversational style of dialogue systems in the restaurant domain.
Are you serious?: Rhetorical Questions and Sarcasm in Social Media Dialog
Sep 15, 2017
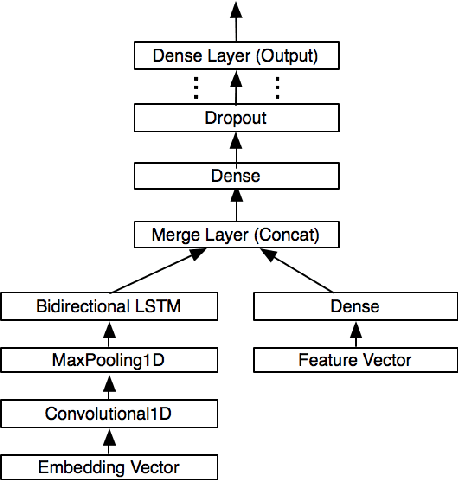

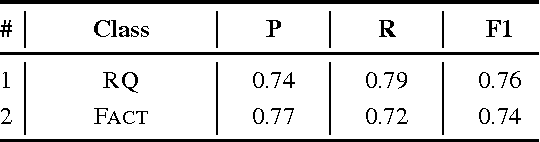
Effective models of social dialog must understand a broad range of rhetorical and figurative devices. Rhetorical questions (RQs) are a type of figurative language whose aim is to achieve a pragmatic goal, such as structuring an argument, being persuasive, emphasizing a point, or being ironic. While there are computational models for other forms of figurative language, rhetorical questions have received little attention to date. We expand a small dataset from previous work, presenting a corpus of 10,270 RQs from debate forums and Twitter that represent different discourse functions. We show that we can clearly distinguish between RQs and sincere questions (0.76 F1). We then show that RQs can be used both sarcastically and non-sarcastically, observing that non-sarcastic (other) uses of RQs are frequently argumentative in forums, and persuasive in tweets. We present experiments to distinguish between these uses of RQs using SVM and LSTM models that represent linguistic features and post-level context, achieving results as high as 0.76 F1 for "sarcastic" and 0.77 F1 for "other" in forums, and 0.83 F1 for both "sarcastic" and "other" in tweets. We supplement our quantitative experiments with an in-depth characterization of the linguistic variation in RQs.
And That's A Fact: Distinguishing Factual and Emotional Argumentation in Online Dialogue
Sep 15, 2017
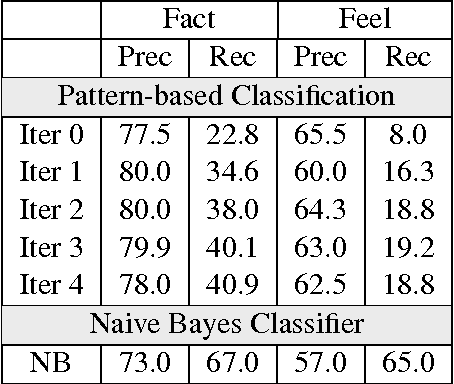
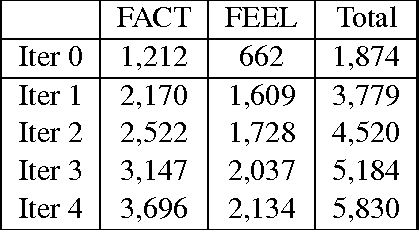

We investigate the characteristics of factual and emotional argumentation styles observed in online debates. Using an annotated set of "factual" and "feeling" debate forum posts, we extract patterns that are highly correlated with factual and emotional arguments, and then apply a bootstrapping methodology to find new patterns in a larger pool of unannotated forum posts. This process automatically produces a large set of patterns representing linguistic expressions that are highly correlated with factual and emotional language. Finally, we analyze the most discriminating patterns to better understand the defining characteristics of factual and emotional arguments.
Data-Driven Dialogue Systems for Social Agents
Sep 10, 2017In order to build dialogue systems to tackle the ambitious task of holding social conversations, we argue that we need a data driven approach that includes insight into human conversational chit chat, and which incorporates different natural language processing modules. Our strategy is to analyze and index large corpora of social media data, including Twitter conversations, online debates, dialogues between friends, and blog posts, and then to couple this data retrieval with modules that perform tasks such as sentiment and style analysis, topic modeling, and summarization. We aim for personal assistants that can learn more nuanced human language, and to grow from task-oriented agents to more personable social bots.