 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Read Me Now? Content Aware Rectification using Angle Supervision
Aug 05, 2020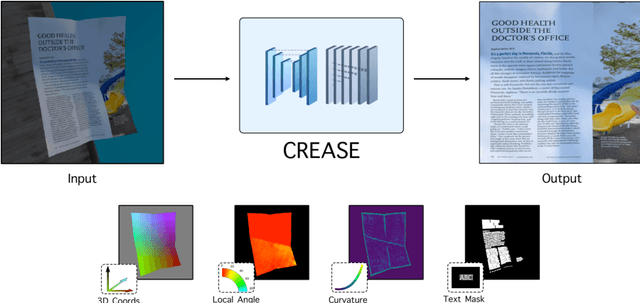

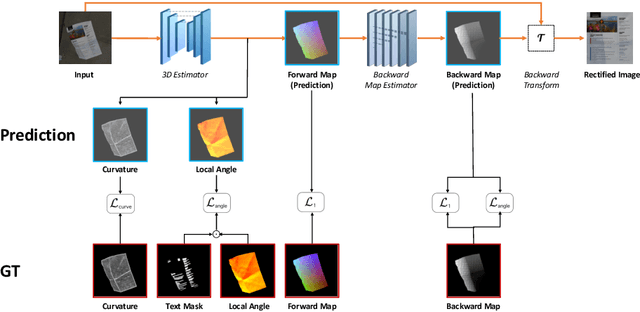

The ubiquity of smartphone cameras has led to more and more documents being captured by cameras rather than scanned. Unlike flatbed scanners, photographed documents are often folded and crumpled, resulting in large local variance in text structure. The problem of document rectification is fundamental to the Optical Character Recognition (OCR) process on documents, and its ability to overcome geometric distortions significantly affects recognition accuracy. Despite the great progress in recent OCR systems, most still rely on a pre-process that ensures the text lines are straight and axis aligned. Recent works have tackled the problem of rectifying document images taken in-the-wild using various supervision signals and alignment means. However, they focused on global features that can be extracted from the document's boundaries, ignoring various signals that could be obtained from the document's content. We present CREASE: Content Aware Rectification using Angle Supervision, the first learned method for document rectification that relies on the document's content, the location of the words and specifically their orientation, as hints to assist in the rectification process. We utilize a novel pixel-wise angle regression approach and a curvature estimation side-task for optimizing our rectification model. Our method surpasses previous approaches in terms of OCR accuracy, geometric error and visual similarity.
SCATTER: Selective Context Attentional Scene Text Recognizer
Mar 25, 2020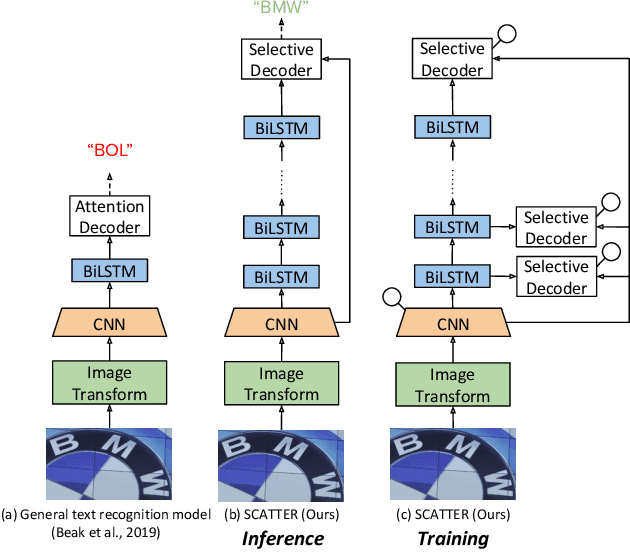
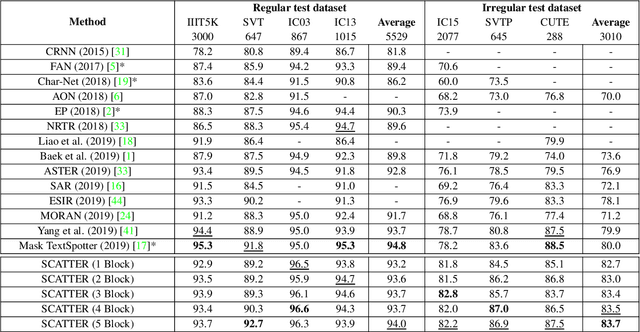
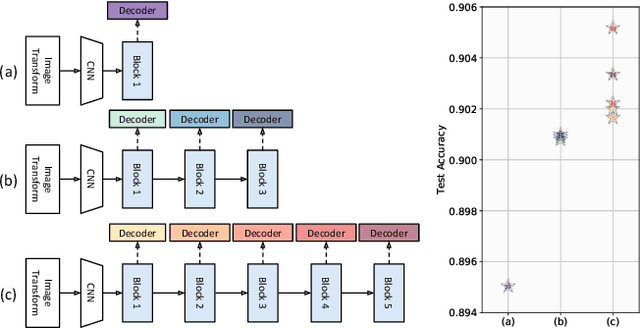
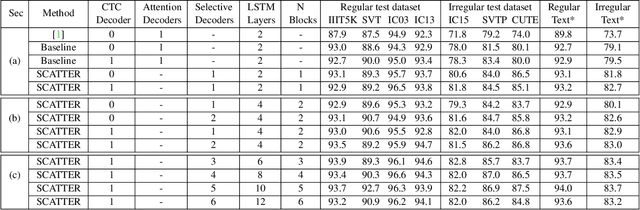
Scene Text Recognition (STR), the task of recognizing text against complex image backgrounds, is an active area of research. Current state-of-the-art (SOTA) methods still struggle to recognize text written in arbitrary shapes. In this paper, we introduce a novel architecture for STR, named Selective Context ATtentional Text Recognizer (SCATTER). SCATTER utilizes a stacked block architecture with intermediate supervision during training, that paves the way to successfully train a deep BiLSTM encoder, thus improving the encoding of contextual dependencies. Decoding is done using a two-step 1D attention mechanism. The first attention step re-weights visual features from a CNN backbone together with contextual features computed by a BiLSTM layer. The second attention step, similar to previous papers, treats the features as a sequence and attends to the intra-sequence relationships. Experiments show that the proposed approach surpasses SOTA performance on irregular text recognition benchmarks by 3.7\% on average.
ScrabbleGAN: Semi-Supervised Varying Length Handwritten Text Generation
Mar 23, 2020
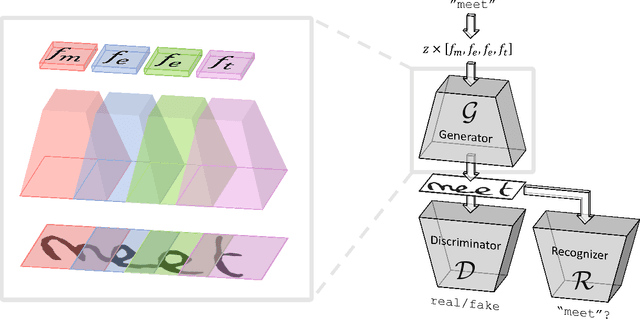
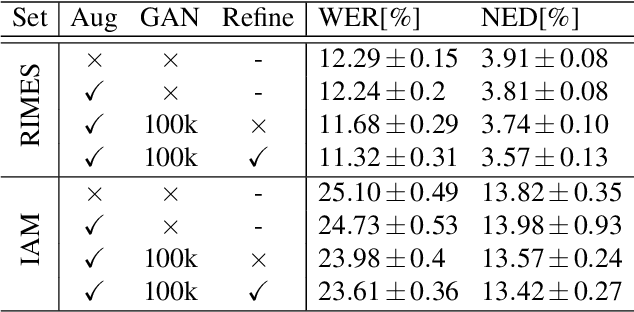

Optical character recognition (OCR) systems performance have improved significantly in the deep learning era. This is especially true for handwritten text recognition (HTR), where each author has a unique style, unlike printed text, where the variation is smaller by design. That said, deep learning based HTR is limited, as in every other task, by the number of training examples. Gathering data is a challenging and costly task, and even more so, the labeling task that follows, of which we focus here. One possible approach to reduce the burden of data annotation is semi-supervised learning. Semi supervised methods use, in addition to labeled data, some unlabeled samples to improve performance, compared to fully supervised ones. Consequently, such methods may adapt to unseen images during test time. We present ScrabbleGAN, a semi-supervised approach to synthesize handwritten text images that are versatile both in style and lexicon. ScrabbleGAN relies on a novel generative model which can generate images of words with an arbitrary length. We show how to operate our approach in a semi-supervised manner, enjoying the aforementioned benefits such as performance boost over state of the art supervised HTR. Furthermore, our generator can manipulate the resulting text style. This allows us to change, for instance, whether the text is cursive, or how thin is the pen stroke.
Bayesian Time-of-Flight for Realtime Shape, Illumination and Albedo
Jul 22, 2015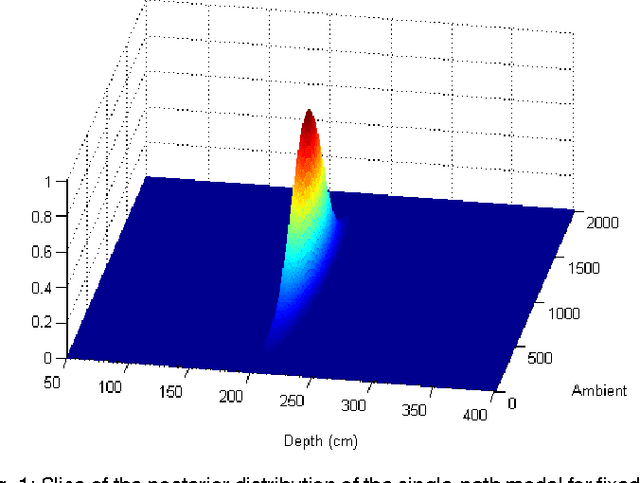
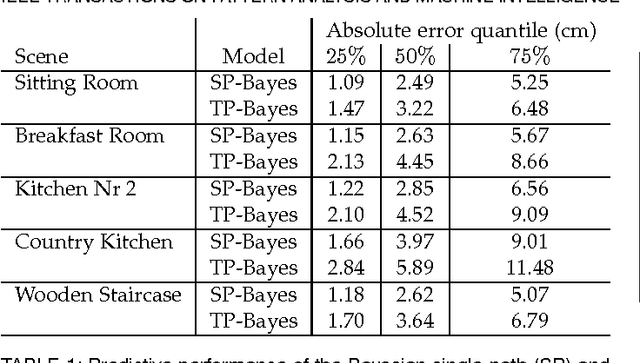
We propose a computational model for shape, illumination and albedo inference in a pulsed time-of-flight (TOF) camera. In contrast to TOF cameras based on phase modulation, our camera enables general exposure profiles. This results in added flexibility and requires novel computational approaches. To address this challenge we propose a generative probabilistic model that accurately relates latent imaging conditions to observed camera responses. While principled, realtime inference in the model turns out to be infeasible, and we propose to employ efficient non-parametric regression trees to approximate the model outputs. As a result we are able to provide, for each pixel, at video frame rate, estimates and uncertainty for depth, effective albedo, and ambient light intensity. These results we present are state-of-the-art in depth imaging. The flexibility of our approach allows us to easily enrich our generative model. We demonstrate that by extending the original single-path model to a two-path model, capable of describing some multipath effects. The new model is seamlessly integrated in the system at no additional computational cost. Our work also addresses the important question of optimal exposure design in pulsed TOF systems. Finally, for benchmark purposes and to obtain realistic empirical priors of multipath and insights into this phenomena, we propose a physically accurate simulation of multipath phenomena.