 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeong Joon Oh
VideoMix: Rethinking Data Augmentation for Video Classification
Dec 07, 2020

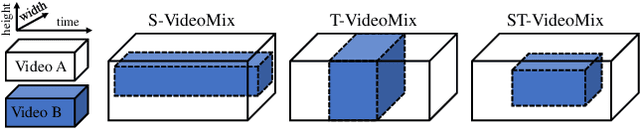
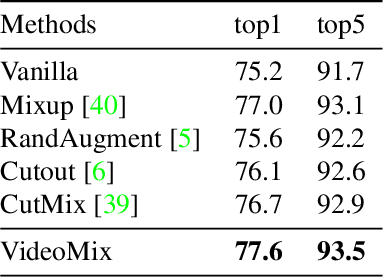
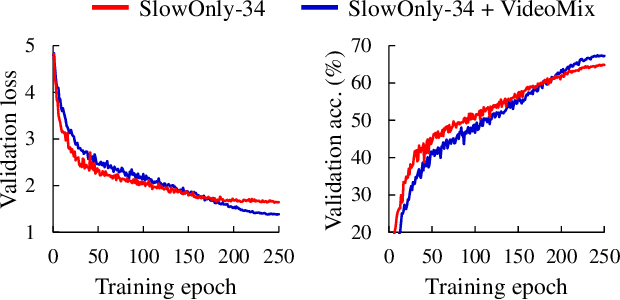
State-of-the-art video action classifiers often suffer from overfitting. They tend to be biased towards specific objects and scene cues, rather than the foreground action content, leading to sub-optimal generalization performances. Recent data augmentation strategies have been reported to address the overfitting problems in static image classifiers. Despite the effectiveness on the static image classifiers, data augmentation has rarely been studied for videos. For the first time in the field, we systematically analyze the efficacy of various data augmentation strategies on the video classification task. We then propose a powerful augmentation strategy VideoMix. VideoMix creates a new training video by inserting a video cuboid into another video. The ground truth labels are mixed proportionally to the number of voxels from each video. We show that VideoMix lets a model learn beyond the object and scene biases and extract more robust cues for action recognition. VideoMix consistently outperforms other augmentation baselines on Kinetics and the challenging Something-Something-V2 benchmarks. It also improves the weakly-supervised action localization performance on THUMOS'14. VideoMix pretrained models exhibit improved accuracies on the video detection task (AVA).
Evaluation for Weakly Supervised Object Localization: Protocol, Metrics, and Datasets
Jul 08, 2020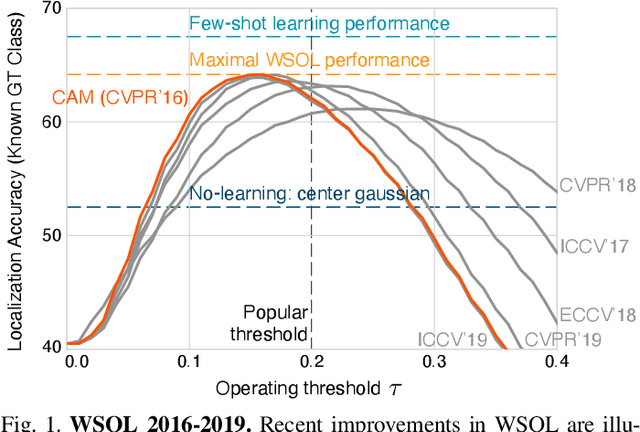



Weakly-supervised object localization (WSOL) has gained popularity over the last years for its promise to train localization models with only image-level labels. Since the seminal WSOL work of class activation mapping (CAM), the field has focused on how to expand the attention regions to cover objects more broadly and localize them better. However, these strategies rely on full localization supervision for validating hyperparameters and model selection, which is in principle prohibited under the WSOL setup. In this paper, we argue that WSOL task is ill-posed with only image-level labels, and propose a new evaluation protocol where full supervision is limited to only a small held-out set not overlapping with the test set. We observe that, under our protocol, the five most recent WSOL methods have not made a major improvement over the CAM baseline. Moreover, we report that existing WSOL methods have not reached the few-shot learning baseline, where the full-supervision at validation time is used for model training instead. Based on our findings, we discuss some future directions for WSOL.
Slowing Down the Weight Norm Increase in Momentum-based Optimizers
Jun 15, 2020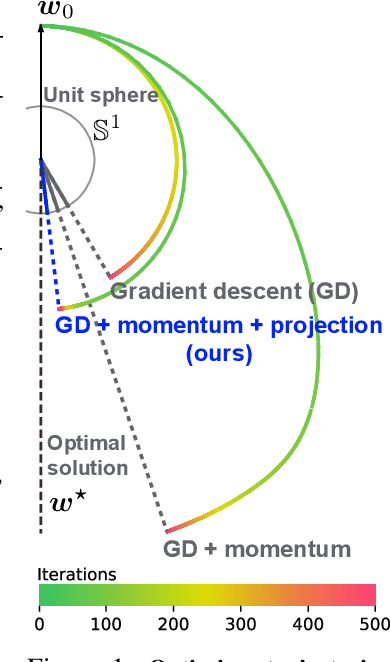

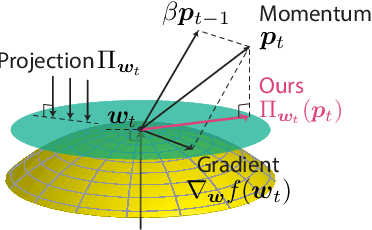
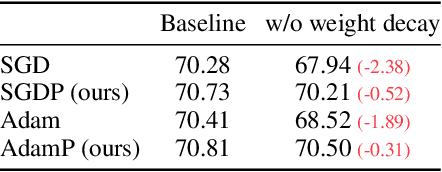
Normalization techniques, such as batch normalization (BN), have led to significant improvements in deep neural network performances. Prior studies have analyzed the benefits of the resulting scale invariance of the weights for the gradient descent (GD) optimizers: it leads to a stabilized training due to the auto-tuning of step sizes. However, we show that, combined with the momentum-based algorithms, the scale invariance tends to induce an excessive growth of the weight norms. This in turn overly suppresses the effective step sizes during training, potentially leading to sub-optimal performances in deep neural networks. We analyze this phenomenon both theoretically and empirically. We propose a simple and effective solution: at each iteration of momentum-based GD optimizers (e.g. SGD or Adam) applied on scale-invariant weights (e.g. Conv weights preceding a BN layer), we remove the radial component (i.e. parallel to the weight vector) from the update vector. Intuitively, this operation prevents the unnecessary update along the radial direction that only increases the weight norm without contributing to the loss minimization. We verify that the modified optimizers SGDP and AdamP successfully regularize the norm growth and improve the performance of a broad set of models. Our experiments cover tasks including image classification and retrieval, object detection, robustness benchmarks, and audio classification. Source code is available at https://github.com/clovaai/AdamP.
An Empirical Evaluation on Robustness and Uncertainty of Regularization Methods
Mar 09, 2020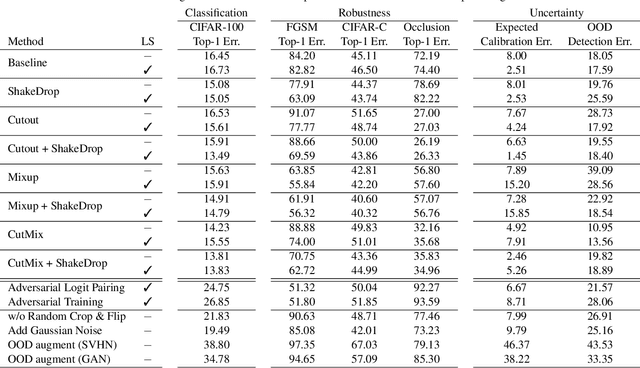
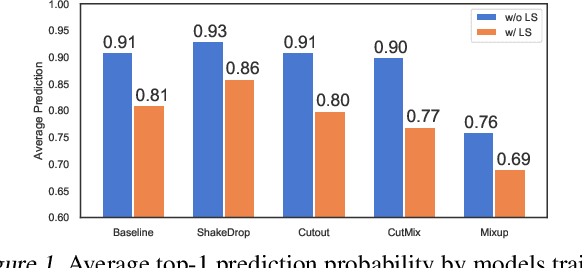

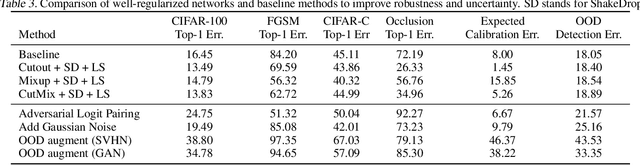
Despite apparent human-level performances of deep neural networks (DNN), they behave fundamentally differently from humans. They easily change predictions when small corruptions such as blur and noise are applied on the input (lack of robustness), and they often produce confident predictions on out-of-distribution samples (improper uncertainty measure). While a number of researches have aimed to address those issues, proposed solutions are typically expensive and complicated (e.g. Bayesian inference and adversarial training). Meanwhile, many simple and cheap regularization methods have been developed to enhance the generalization of classifiers. Such regularization methods have largely been overlooked as baselines for addressing the robustness and uncertainty issues, as they are not specifically designed for that. In this paper, we provide extensive empirical evaluations on the robustness and uncertainty estimates of image classifiers (CIFAR-100 and ImageNet) trained with state-of-the-art regularization methods. Furthermore, experimental results show that certain regularization methods can serve as strong baseline methods for robustness and uncertainty estimation of DNNs.
Reliable Fidelity and Diversity Metrics for Generative Models
Feb 23, 2020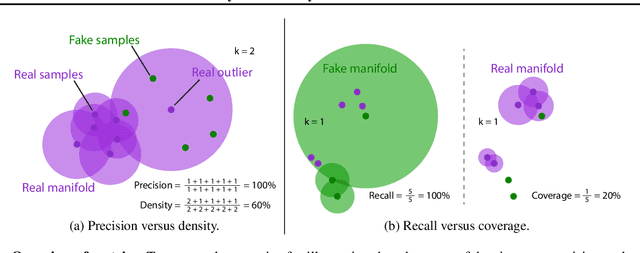
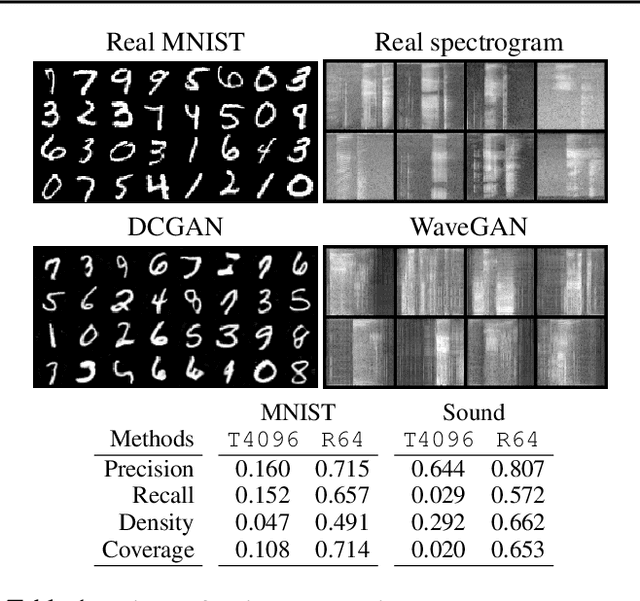
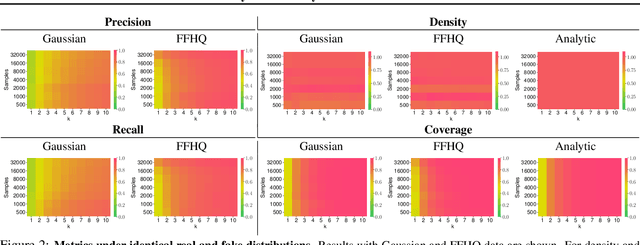
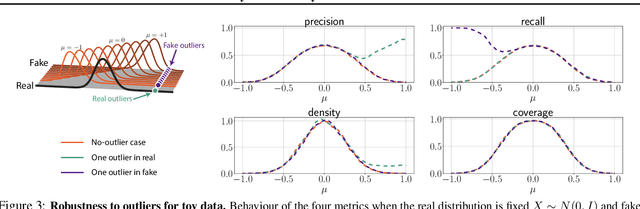
Devising indicative evaluation metrics for the image generation task remains an open problem. The most widely used metric for measuring the similarity between real and generated images has been the Fr\'echet Inception Distance (FID) score. Because it does not differentiate the fidelity and diversity aspects of the generated images, recent papers have introduced variants of precision and recall metrics to diagnose those properties separately. In this paper, we show that even the latest version of the precision and recall metrics are not reliable yet. For example, they fail to detect the match between two identical distributions, they are not robust against outliers, and the evaluation hyperparameters are selected arbitrarily. We propose density and coverage metrics that solve the above issues. We analytically and experimentally show that density and coverage provide more interpretable and reliable signals for practitioners than the existing metrics. Code: https://github.com/clovaai/generative-evaluation-prdc.
Evaluating Weakly Supervised Object Localization Methods Right
Jan 21, 2020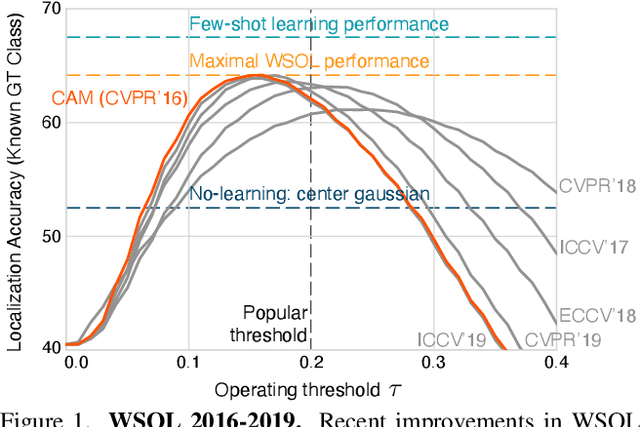


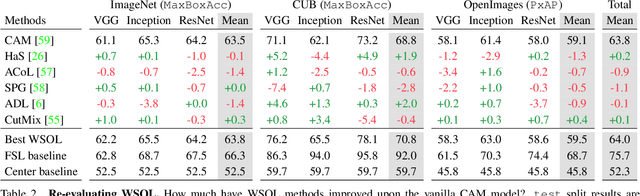
Weakly-supervised object localization (WSOL) has gained popularity over the last years for its promise to train localization models with only image-level labels. Since the seminal WSOL work of class activation mapping (CAM), the field has focused on how to expand the attention regions to cover objects more broadly and localize them better. However, these strategies rely on full localization supervision to validate hyperparameters and for model selection, which is in principle prohibited under the WSOL setup. In this paper, we argue that WSOL task is ill-posed with only image-level labels, and propose a new evaluation protocol where full supervision is limited to only a small held-out set not overlapping with the test set. We observe that, under our protocol, the five most recent WSOL methods have not made a major improvement over the CAM baseline. Moreover, we report that existing WSOL methods have not reached the few-shot learning baseline, where the full-supervision at validation time is used for model training instead. Based on our findings, we discuss some future directions for WSOL.
On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
Oct 10, 2019
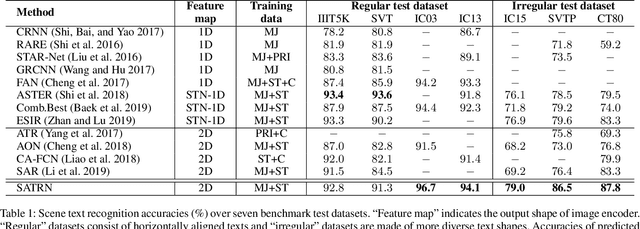
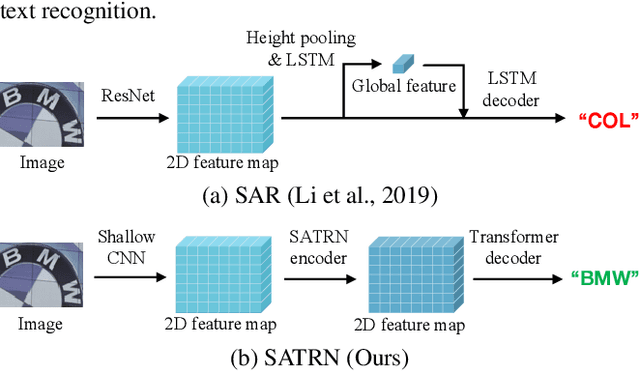
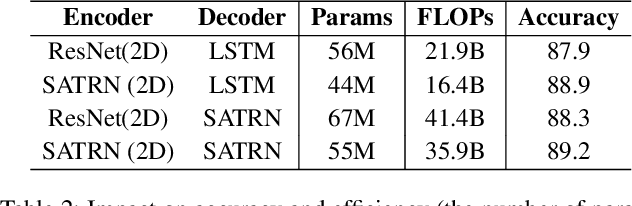
Scene text recognition (STR) is the task of recognizing character sequences in natural scenes. While there have been great advances in STR methods, current methods still fail to recognize texts in arbitrary shapes, such as heavily curved or rotated texts, which are abundant in daily life (e.g. restaurant signs, product labels, company logos, etc). This paper introduces a novel architecture to recognizing texts of arbitrary shapes, named Self-Attention Text Recognition Network (SATRN), which is inspired by the Transformer. SATRN utilizes the self-attention mechanism to describe two-dimensional (2D) spatial dependencies of characters in a scene text image. Exploiting the full-graph propagation of self-attention, SATRN can recognize texts with arbitrary arrangements and large inter-character spacing. As a result, SATRN outperforms existing STR models by a large margin of 5.7 pp on average in "irregular text" benchmarks. We provide empirical analyses that illustrate the inner mechanisms and the extent to which the model is applicable (e.g. rotated and multi-line text). We will open-source the code.
Learning De-biased Representations with Biased Representations
Oct 07, 2019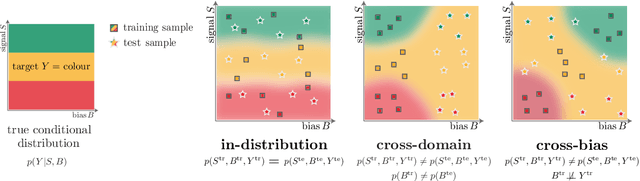
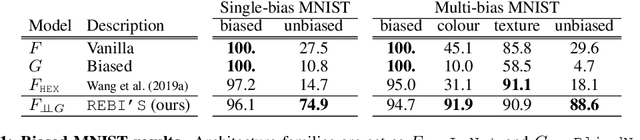
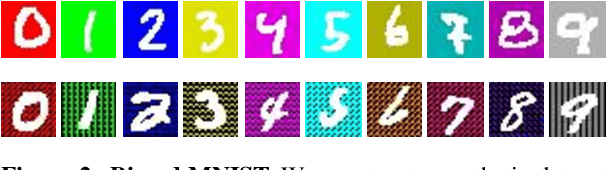
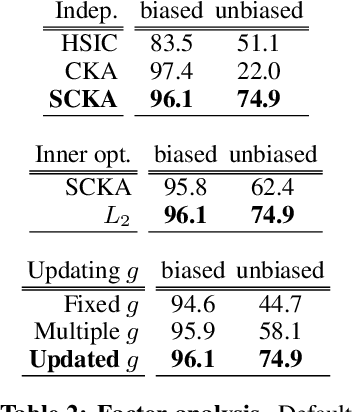
Many machine learning algorithms are trained and evaluated by splitting data from a single source into training and test sets. While such focus on in-distribution learning scenarios has led interesting advances, it has not been able to tell if models are relying on dataset biases as shortcuts for successful prediction (e.g., using snow cues for recognising snowmobiles). Such biased models fail to generalise when the bias shifts to a different class. The cross-bias generalisation problem has been addressed by de-biasing training data through augmentation or re-sampling, which are often prohibitive due to the data collection cost (e.g., collecting images of a snowmobile on a desert) and the difficulty of quantifying or expressing biases in the first place. In this work, we propose a novel framework to train a de-biased representation by encouraging it to be different from a set of representations that are biased by design. This tactic is feasible in many scenarios where it is much easier to define a set of biased representations than to define and quantify bias. Our experiments and analyses show that our method discourages models from taking bias shortcuts, resulting in improved performances on de-biased test data.
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
May 13, 2019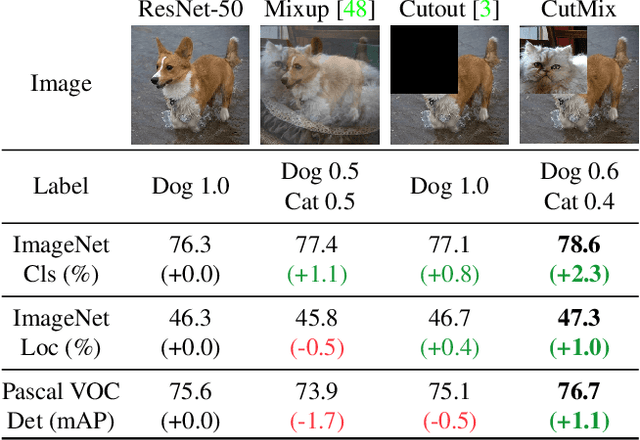


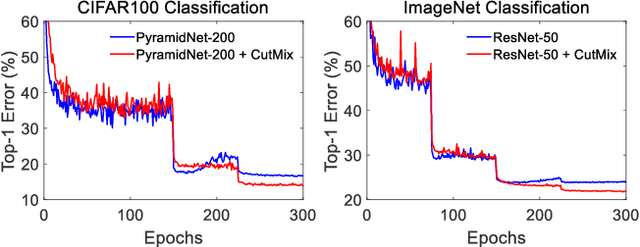
Regional dropout strategies have been proposed to enhance the performance of convolutional neural network classifiers. They have proved to be effective for guiding the model to attend on less discriminative parts of objects (\eg leg as opposed to head of a person), thereby letting the network generalize better and have better object localization capabilities. On the other hand, current methods for regional dropout removes informative pixels on training images by overlaying a patch of either black pixels or random noise. {Such removal is not desirable because it leads to information loss and inefficiency during training.} We therefore propose the CutMix augmentation strategy: patches are cut and pasted among training images where the ground truth labels are also mixed proportionally to the area of the patches. By making efficient use of training pixels and \mbox{retaining} the regularization effect of regional dropout, CutMix consistently outperforms the state-of-the-art augmentation strategies on CIFAR and ImageNet classification tasks, as well as on the ImageNet weakly-supervised localization task. Moreover, unlike previous augmentation methods, our CutMix-trained ImageNet classifier, when used as a pretrained model, results in consistent performance gains in Pascal detection and MS-COCO image captioning benchmarks. We also show that CutMix improves the model robustness against input corruptions and its out-of-distribution detection performances.
What is wrong with scene text recognition model comparisons? dataset and model analysis
Apr 03, 2019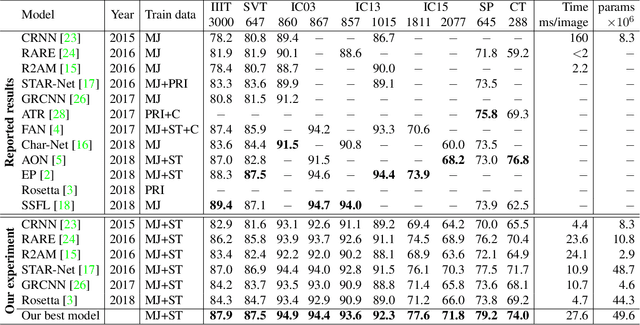



Many new proposals for scene text recognition (STR) models have been introduced in recent years. While each claim to have pushed the boundary of the technology, a holistic and fair comparison has been largely missing in the field due to the inconsistent choices of training and evaluation datasets. This paper addresses this difficulty with three major contributions. First, we examine the inconsistencies of training and evaluation datasets, and the performance gap results from inconsistencies. Second, we introduce a unified four-stage STR framework that most existing STR models fit into. Using this framework allows for the extensive evaluation of previously proposed STR modules and the discovery of previously unexplored module combinations. Third, we analyze the module-wise contributions to performance in terms of accuracy, speed, and memory demand, under one consistent set of training and evaluation datasets. Such analyses clean up the hindrance on the current comparisons to understand the performance gain of the existing modules.