 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTriage: Exploring the Effectiveness of Deep Learning for Bug Triaging
Jan 04, 2018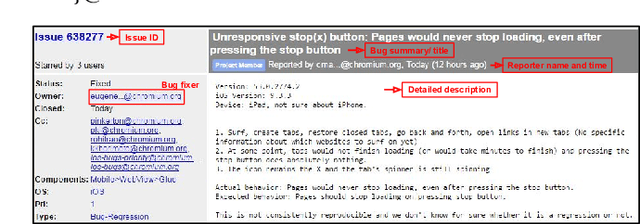
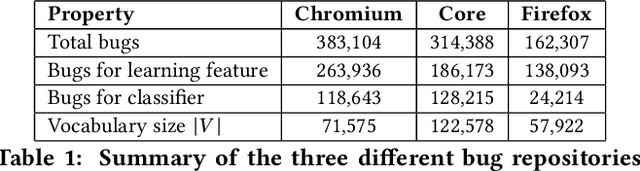

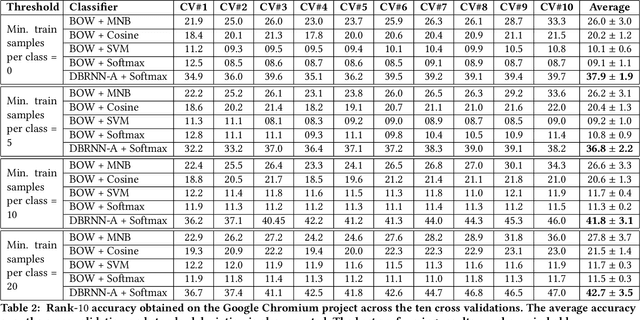
For a given software bug report, identifying an appropriate developer who could potentially fix the bug is the primary task of a bug triaging process. A bug title (summary) and a detailed description is present in most of the bug tracking systems. Automatic bug triaging algorithm can be formulated as a classification problem, with the bug title and description as the input, mapping it to one of the available developers (classes). The major challenge is that the bug description usually contains a combination of free unstructured text, code snippets, and stack trace making the input data noisy. The existing bag-of-words (BOW) feature models do not consider the syntactical and sequential word information available in the unstructured text. We propose a novel bug report representation algorithm using an attention based deep bidirectional recurrent neural network (DBRNN-A) model that learns a syntactic and semantic feature from long word sequences in an unsupervised manner. Instead of BOW features, the DBRNN-A based bug representation is then used for training the classifier. Using an attention mechanism enables the model to learn the context representation over a long word sequence, as in a bug report. To provide a large amount of data to learn the feature learning model, the unfixed bug reports (~70% bugs in an open source bug tracking system) are leveraged, which were completely ignored in the previous studies. Another contribution is to make this research reproducible by making the source code available and creating a public benchmark dataset of bug reports from three open source bug tracking system: Google Chromium (383,104 bug reports), Mozilla Core (314,388 bug reports), and Mozilla Firefox (162,307 bug reports). Experimentally we compare our approach with BOW model and machine learning approaches and observe that DBRNN-A provides a higher rank-10 average accuracy.
DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers
Nov 09, 2017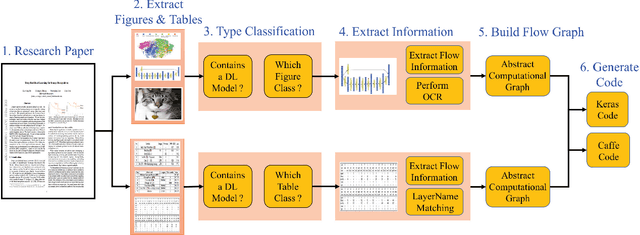
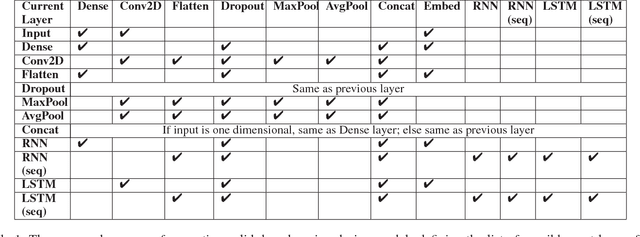

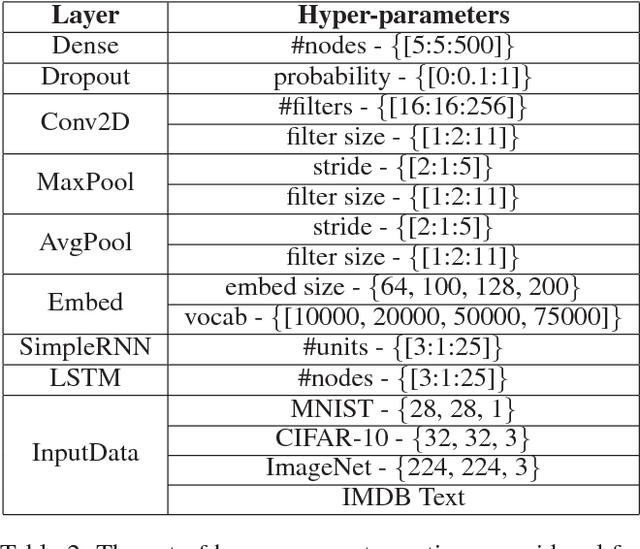
With an abundance of research papers in deep learning, reproducibility or adoption of the existing works becomes a challenge. This is due to the lack of open source implementations provided by the authors. Further, re-implementing research papers in a different library is a daunting task. To address these challenges, we propose a novel extensible approach, DLPaper2Code, to extract and understand deep learning design flow diagrams and tables available in a research paper and convert them to an abstract computational graph. The extracted computational graph is then converted into execution ready source code in both Keras and Caffe, in real-time. An arXiv-like website is created where the automatically generated designs is made publicly available for 5,000 research papers. The generated designs could be rated and edited using an intuitive drag-and-drop UI framework in a crowdsourced manner. To evaluate our approach, we create a simulated dataset with over 216,000 valid design visualizations using a manually defined grammar. Experiments on the simulated dataset show that the proposed framework provide more than $93\%$ accuracy in flow diagram content extraction.
Hi, how can I help you?: Automating enterprise IT support help desks
Nov 02, 2017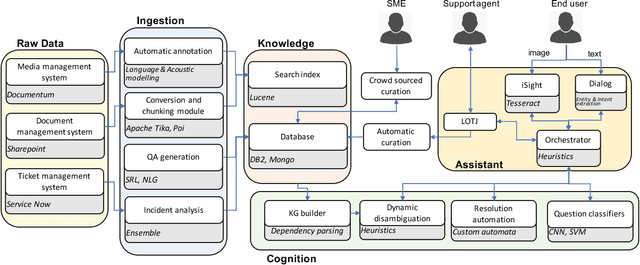
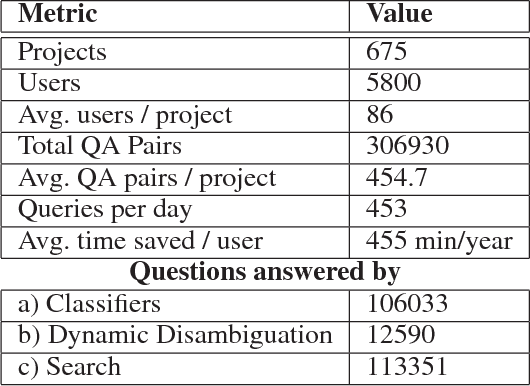
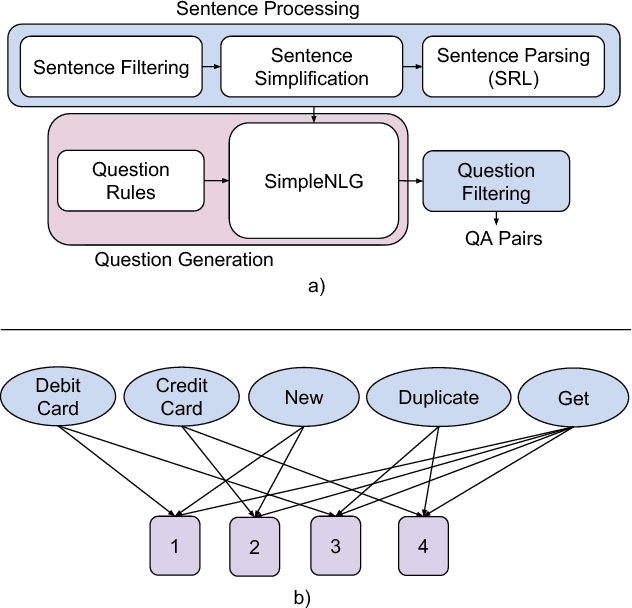
Question answering is one of the primary challenges of natural language understanding. In realizing such a system, providing complex long answers to questions is a challenging task as opposed to factoid answering as the former needs context disambiguation. The different methods explored in the literature can be broadly classified into three categories namely: 1) classification based, 2) knowledge graph based and 3) retrieval based. Individually, none of them address the need of an enterprise wide assistance system for an IT support and maintenance domain. In this domain the variance of answers is large ranging from factoid to structured operating procedures; the knowledge is present across heterogeneous data sources like application specific documentation, ticket management systems and any single technique for a general purpose assistance is unable to scale for such a landscape. To address this, we have built a cognitive platform with capabilities adopted for this domain. Further, we have built a general purpose question answering system leveraging the platform that can be instantiated for multiple products, technologies in the support domain. The system uses a novel hybrid answering model that orchestrates across a deep learning classifier, a knowledge graph based context disambiguation module and a sophisticated bag-of-words search system. This orchestration performs context switching for a provided question and also does a smooth hand-off of the question to a human expert if none of the automated techniques can provide a confident answer. This system has been deployed across 675 internal enterprise IT support and maintenance projects.
mAnI: Movie Amalgamation using Neural Imitation
Aug 16, 2017
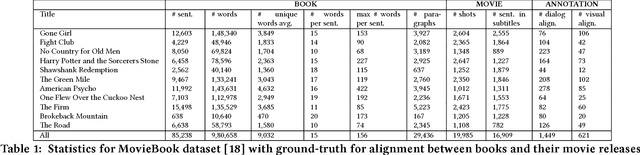

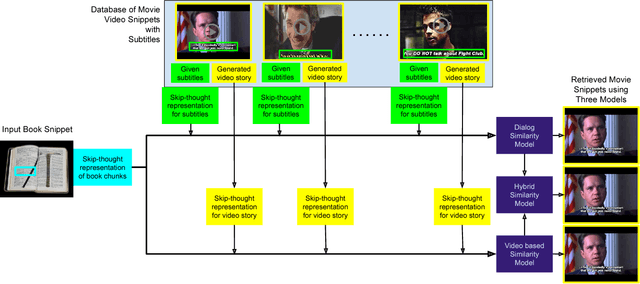
Cross-modal data retrieval has been the basis of various creative tasks performed by Artificial Intelligence (AI). One such highly challenging task for AI is to convert a book into its corresponding movie, which most of the creative film makers do as of today. In this research, we take the first step towards it by visualizing the content of a book using its corresponding movie visuals. Given a set of sentences from a book or even a fan-fiction written in the same universe, we employ deep learning models to visualize the input by stitching together relevant frames from the movie. We studied and compared three different types of setting to match the book with the movie content: (i) Dialog model: using only the dialog from the movie, (ii) Visual model: using only the visual content from the movie, and (iii) Hybrid model: using the dialog and the visual content from the movie. Experiments on the publicly available MovieBook dataset shows the effectiveness of the proposed models.