 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIC: Text-Guided Image Colorization
Aug 04, 2022

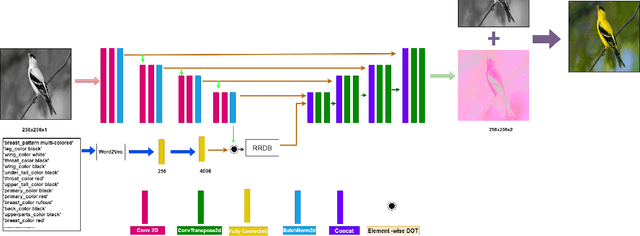
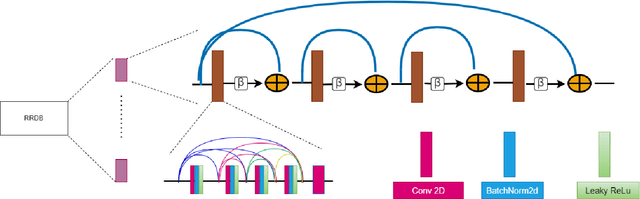
Image colorization is a well-known problem in computer vision. However, due to the ill-posed nature of the task, image colorization is inherently challenging. Though several attempts have been made by researchers to make the colorization pipeline automatic, these processes often produce unrealistic results due to a lack of conditioning. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To the best of our knowledge, this is one of the first attempts to incorporate textual conditioning in the colorization pipeline. To do so, we have proposed a novel deep network that takes two inputs (the grayscale image and the respective encoded text description) and tries to predict the relevant color gamut. As the respective textual descriptions contain color information of the objects present in the scene, the text encoding helps to improve the overall quality of the predicted colors. We have evaluated our proposed model using different metrics and found that it outperforms the state-of-the-art colorization algorithms both qualitatively and quantitatively.
TIPS: Text-Induced Pose Synthesis
Jul 24, 2022
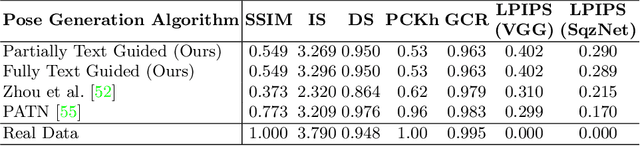
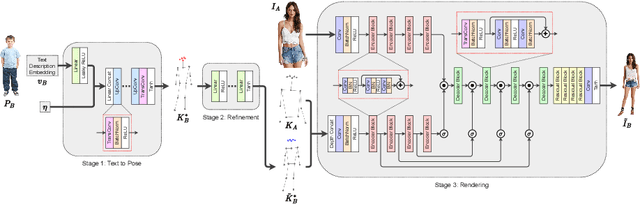
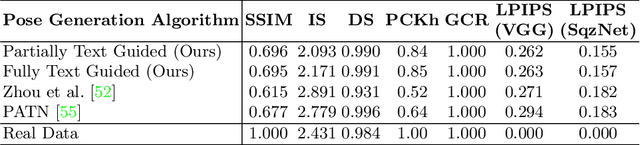
In computer vision, human pose synthesis and transfer deal with probabilistic image generation of a person in a previously unseen pose from an already available observation of that person. Though researchers have recently proposed several methods to achieve this task, most of these techniques derive the target pose directly from the desired target image on a specific dataset, making the underlying process challenging to apply in real-world scenarios as the generation of the target image is the actual aim. In this paper, we first present the shortcomings of current pose transfer algorithms and then propose a novel text-based pose transfer technique to address those issues. We divide the problem into three independent stages: (a) text to pose representation, (b) pose refinement, and (c) pose rendering. To the best of our knowledge, this is one of the first attempts to develop a text-based pose transfer framework where we also introduce a new dataset DF-PASS, by adding descriptive pose annotations for the images of the DeepFashion dataset. The proposed method generates promising results with significant qualitative and quantitative scores in our experiments.
Scene Aware Person Image Generation through Global Contextual Conditioning
Jun 06, 2022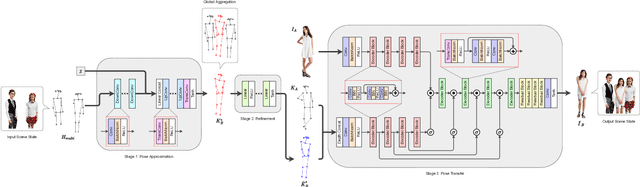
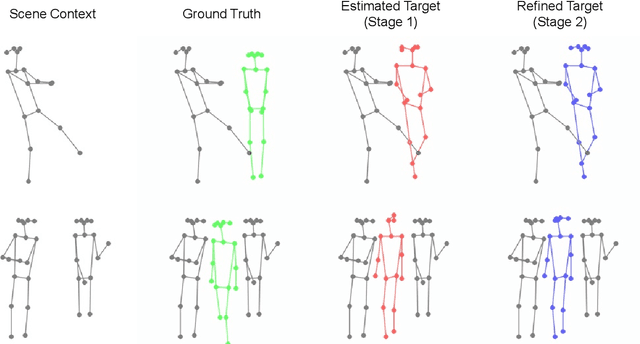


Person image generation is an intriguing yet challenging problem. However, this task becomes even more difficult under constrained situations. In this work, we propose a novel pipeline to generate and insert contextually relevant person images into an existing scene while preserving the global semantics. More specifically, we aim to insert a person such that the location, pose, and scale of the person being inserted blends in with the existing persons in the scene. Our method uses three individual networks in a sequential pipeline. At first, we predict the potential location and the skeletal structure of the new person by conditioning a Wasserstein Generative Adversarial Network (WGAN) on the existing human skeletons present in the scene. Next, the predicted skeleton is refined through a shallow linear network to achieve higher structural accuracy in the generated image. Finally, the target image is generated from the refined skeleton using another generative network conditioned on a given image of the target person. In our experiments, we achieve high-resolution photo-realistic generation results while preserving the general context of the scene. We conclude our paper with multiple qualitative and quantitative benchmarks on the results.
SWIS: Self-Supervised Representation Learning For Writer Independent Offline Signature Verification
Feb 26, 2022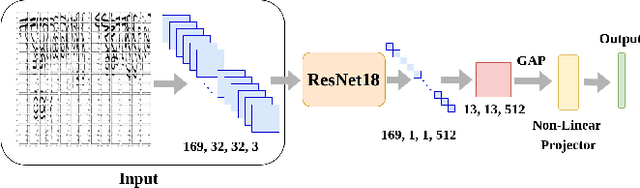

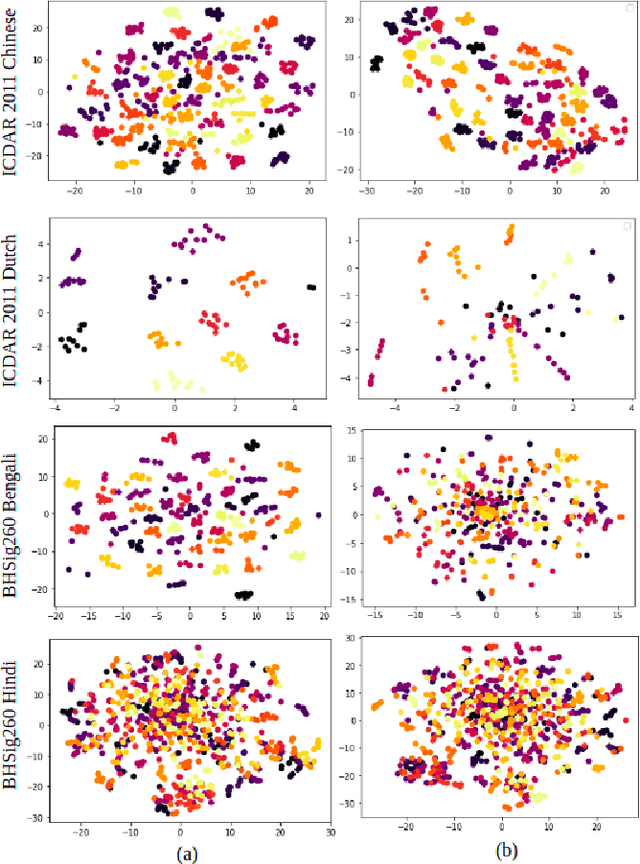
Writer independent offline signature verification is one of the most challenging tasks in pattern recognition as there is often a scarcity of training data. To handle such data scarcity problem, in this paper, we propose a novel self-supervised learning (SSL) framework for writer independent offline signature verification. To our knowledge, this is the first attempt to utilize self-supervised setting for the signature verification task. The objective of self-supervised representation learning from the signature images is achieved by minimizing the cross-covariance between two random variables belonging to different feature directions and ensuring a positive cross-covariance between the random variables denoting the same feature direction. This ensures that the features are decorrelated linearly and the redundant information is discarded. Through experimental results on different data sets, we obtained encouraging results.
Multi-scale Attention Guided Pose Transfer
Feb 14, 2022Pose transfer refers to the probabilistic image generation of a person with a previously unseen novel pose from another image of that person having a different pose. Due to potential academic and commercial applications, this problem is extensively studied in recent years. Among the various approaches to the problem, attention guided progressive generation is shown to produce state-of-the-art results in most cases. In this paper, we present an improved network architecture for pose transfer by introducing attention links at every resolution level of the encoder and decoder. By utilizing such dense multi-scale attention guided approach, we are able to achieve significant improvement over the existing methods both visually and analytically. We conclude our findings with extensive qualitative and quantitative comparisons against several existing methods on the DeepFashion dataset.
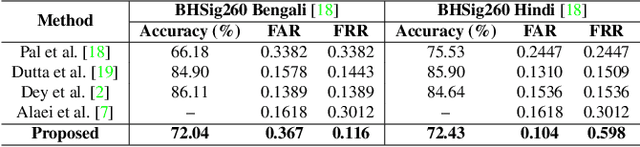
SURDS: Self-Supervised Attention-guided Reconstruction and Dual Triplet Loss for Writer Independent Offline Signature Verification
Jan 25, 2022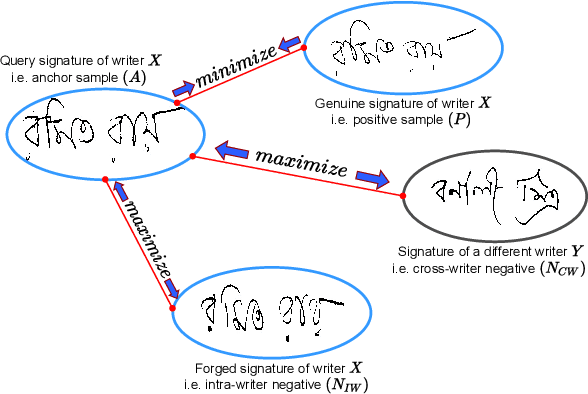

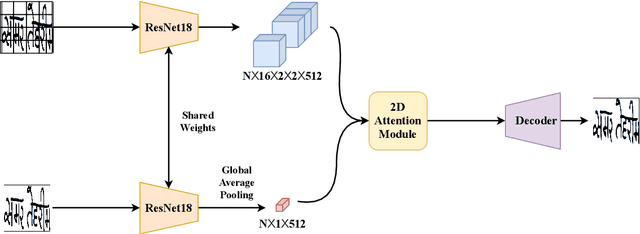
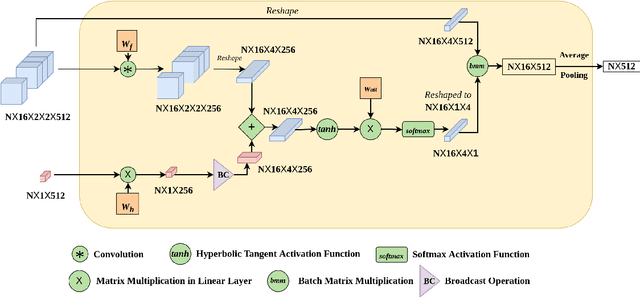
Offline Signature Verification (OSV) is a fundamental biometric task across various forensic, commercial and legal applications. The underlying task at hand is to carefully model fine-grained features of the signatures to distinguish between genuine and forged ones, which differ only in minute deformities. This makes OSV more challenging compared to other verification problems. In this work, we propose a two-stage deep learning framework that leverages self-supervised representation learning as well as metric learning for writer-independent OSV. First, we train an image reconstruction network using an encoder-decoder architecture that is augmented by a 2D spatial attention mechanism using signature image patches. Next, the trained encoder backbone is fine-tuned with a projector head using a supervised metric learning framework, whose objective is to optimize a novel dual triplet loss by sampling negative samples from both within the same writer class as well as from other writers. The intuition behind this is to ensure that a signature sample lies closer to its positive counterpart compared to negative samples from both intra-writer and cross-writer sets. This results in robust discriminative learning of the embedding space. To the best of our knowledge, this is the first work of using self-supervised learning frameworks for OSV. The proposed two-stage framework has been evaluated on two publicly available offline signature datasets and compared with various state-of-the-art methods. It is noted that the proposed method provided promising results outperforming several existing pieces of work.
MIO : Mutual Information Optimization using Self-Supervised Binary Contrastive Learning
Nov 24, 2021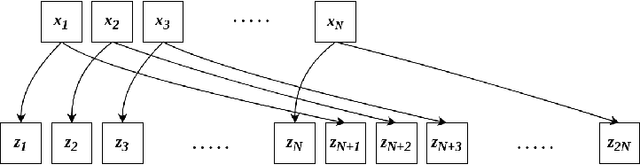
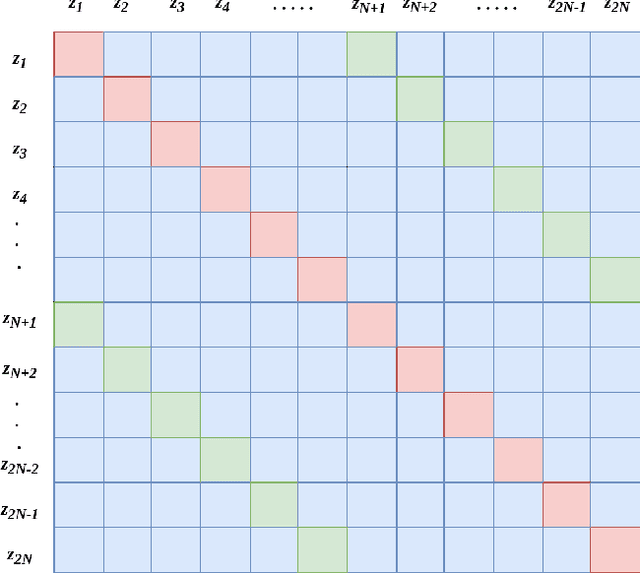
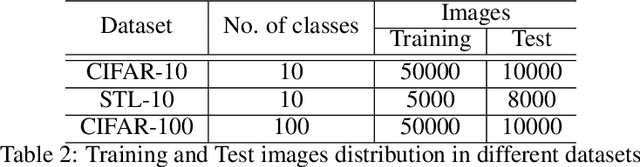
Self-supervised contrastive learning is one of the domains which has progressed rapidly over the last few years. Most of the state-of-the-art self-supervised algorithms use a large number of negative samples, momentum updates, specific architectural modifications, or extensive training to learn good representations. Such arrangements make the overall training process complex and challenging to realize analytically. In this paper, we propose a mutual information optimization based loss function for contrastive learning where we model contrastive learning into a binary classification problem to predict if a pair is positive or not. This formulation not only helps us to track the problem mathematically but also helps us to outperform existing algorithms. Unlike the existing methods that only maximize the mutual information in a positive pair, the proposed loss function optimizes the mutual information in both positive and negative pairs. We also present a mathematical expression for the parameter gradients flowing into the projector and the displacement of the feature vectors in the feature space. This helps us to get a mathematical insight into the working principle of contrastive learning. An additive $L_2$ regularizer is also used to prevent diverging of the feature vectors and to improve performance. The proposed method outperforms the state-of-the-art algorithms on benchmark datasets like STL-10, CIFAR-10, CIFAR-100. After only 250 epochs of pre-training, the proposed model achieves the best accuracy of 85.44\%, 60.75\%, 56.81\% on CIFAR-10, STL-10, CIFAR-100 datasets, respectively.
Attention W-Net: Improved Skip Connections for better Representations
Oct 17, 2021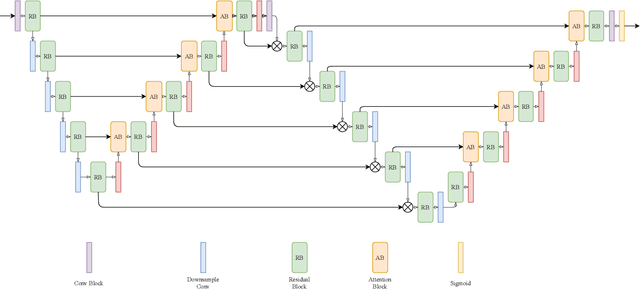

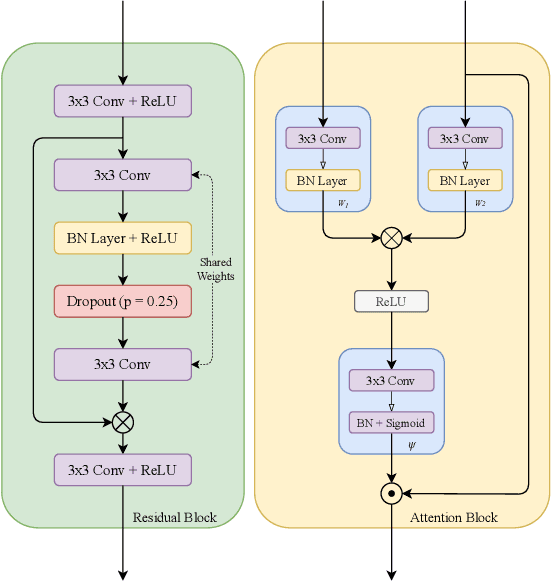
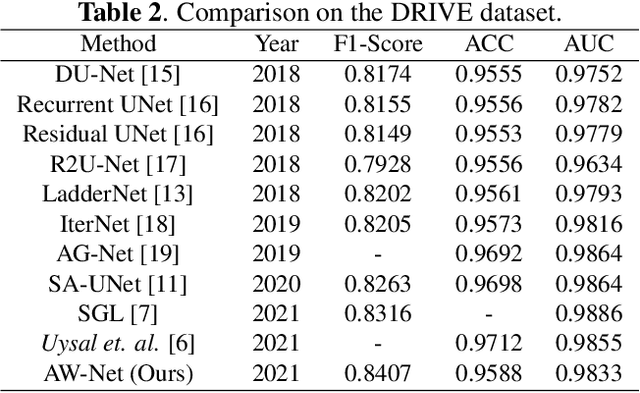
Segmentation of macro and microvascular structures in fundoscopic retinal images plays a crucial role in detection of multiple retinal and systemic diseases, yet it is a difficult problem to solve. Most deep learning approaches for this task involve an autoencoder based architecture, but they face several issues such as lack of enough parameters, overfitting when there are enough parameters and incompatibility between internal feature-spaces. Due to such issues, these techniques are hence not able to extract the best semantic information from the limited data present for such tasks. We propose Attention W-Net, a new U-Net based architecture for retinal vessel segmentation to address these problems. In this architecture with a LadderNet backbone, we have two main contributions: Attention Block and regularisation measures. Our Attention Block uses decoder features to attend over the encoder features from skip-connections during upsampling, resulting in higher compatibility when the encoder and decoder features are added. Our regularisation measures include image augmentation and modifications to the ResNet Block used, which prevent overfitting. With these additions, we observe an AUC and F1-Score of 0.8407 and 0.9833 - a sizeable improvement over its LadderNet backbone as well as competitive performance among the contemporary state-of-the-art methods.
LoOp: Looking for Optimal Hard Negative Embeddings for Deep Metric Learning
Aug 20, 2021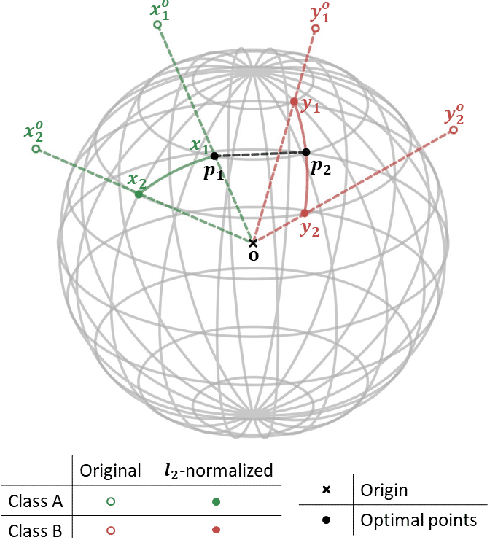

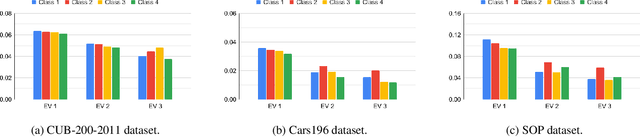
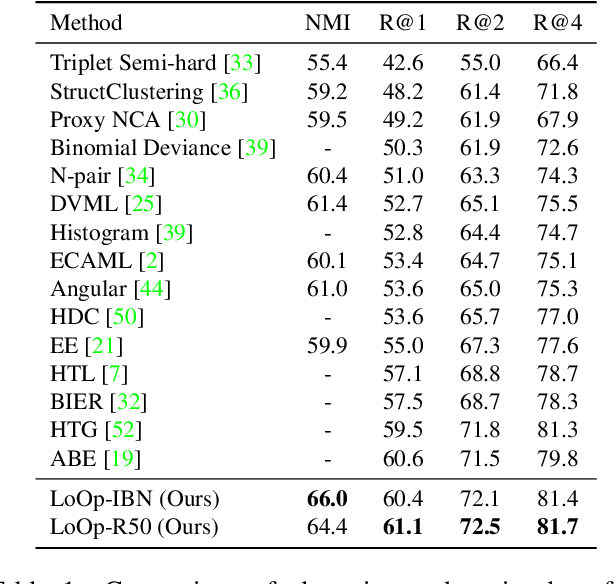
Deep metric learning has been effectively used to learn distance metrics for different visual tasks like image retrieval, clustering, etc. In order to aid the training process, existing methods either use a hard mining strategy to extract the most informative samples or seek to generate hard synthetics using an additional network. Such approaches face different challenges and can lead to biased embeddings in the former case, and (i) harder optimization (ii) slower training speed (iii) higher model complexity in the latter case. In order to overcome these challenges, we propose a novel approach that looks for optimal hard negatives (LoOp) in the embedding space, taking full advantage of each tuple by calculating the minimum distance between a pair of positives and a pair of negatives. Unlike mining-based methods, our approach considers the entire space between pairs of embeddings to calculate the optimal hard negatives. Extensive experiments combining our approach and representative metric learning losses reveal a significant boost in performance on three benchmark datasets.
PLSM: A Parallelized Liquid State Machine for Unintentional Action Detection
May 06, 2021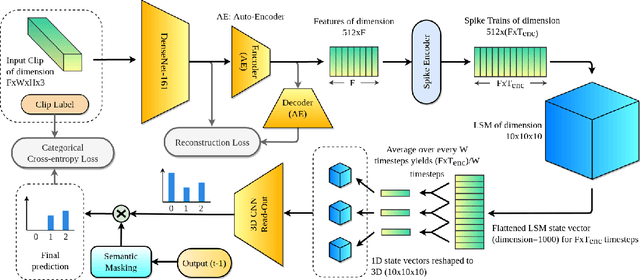
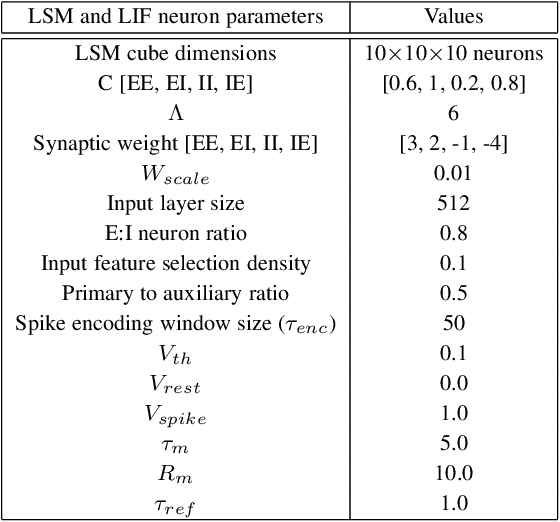
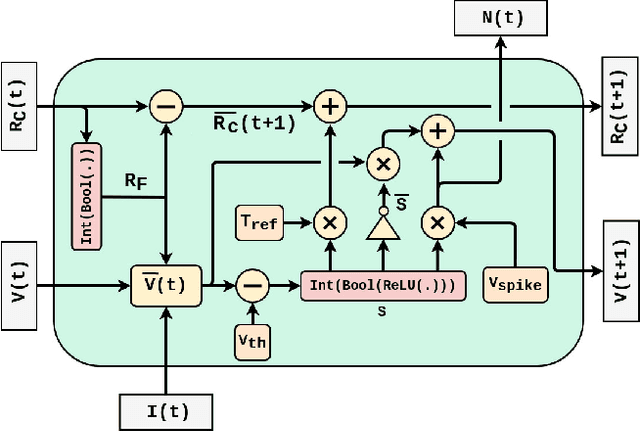
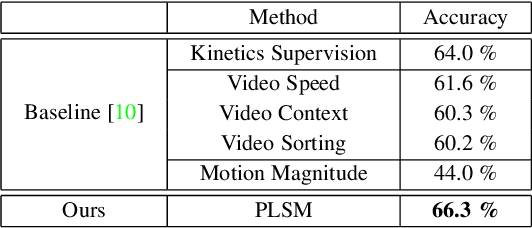
Reservoir Computing (RC) offers a viable option to deploy AI algorithms on low-end embedded system platforms. Liquid State Machine (LSM) is a bio-inspired RC model that mimics the cortical microcircuits and uses spiking neural networks (SNN) that can be directly realized on neuromorphic hardware. In this paper, we present a novel Parallelized LSM (PLSM) architecture that incorporates spatio-temporal read-out layer and semantic constraints on model output. To the best of our knowledge, such a formulation has been done for the first time in literature, and it offers a computationally lighter alternative to traditional deep-learning models. Additionally, we also present a comprehensive algorithm for the implementation of parallelizable SNNs and LSMs that are GPU-compatible. We implement the PLSM model to classify unintentional/accidental video clips, using the Oops dataset. From the experimental results on detecting unintentional action in video, it can be observed that our proposed model outperforms a self-supervised model and a fully supervised traditional deep learning model. All the implemented codes can be found at our repository https://github.com/anonymoussentience2020/Parallelized_LSM_for_Unintentional_Action_Recognition.