 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolution Neural Networks for diagnosing colon and lung cancer histopathological images
Sep 08, 2020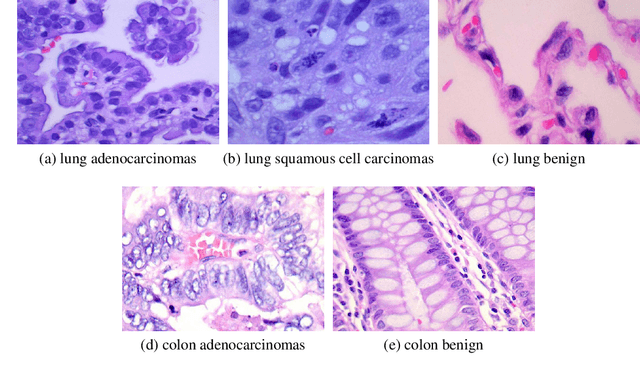
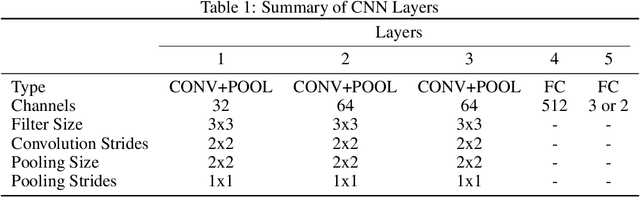
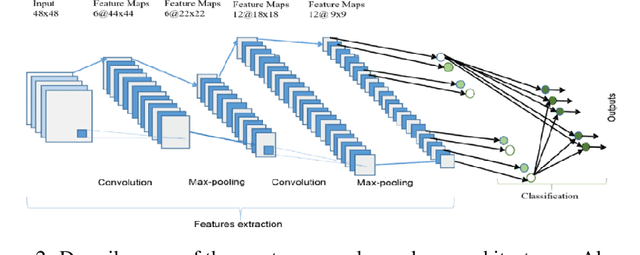
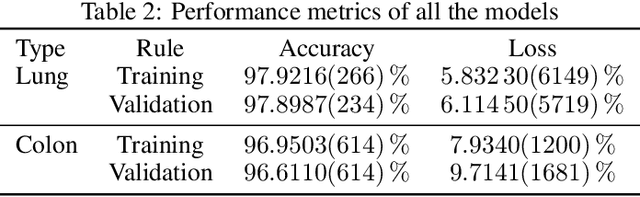
Lung and Colon cancer are one of the leading causes of mortality and morbidity in adults. Histopathological diagnosis is one of the key components to discern cancer type. The aim of the present research is to propose a computer aided diagnosis system for diagnosing squamous cell carcinomas and adenocarcinomas of lung as well as adenocarcinomas of colon using convolutional neural networks by evaluating the digital pathology images for these cancers. Hereby, rendering artificial intelligence as useful technology in the near future. A total of 2500 digital images were acquired from LC25000 dataset containing 5000 images for each class. A shallow neural network architecture was used classify the histopathological slides into squamous cell carcinomas, adenocarcinomas and benign for the lung. Similar model was used to classify adenocarcinomas and benign for colon. The diagnostic accuracy of more than 97% and 96% was recorded for lung and colon respectively.
LSTM vs. GRU vs. Bidirectional RNN for script generation
Aug 12, 2019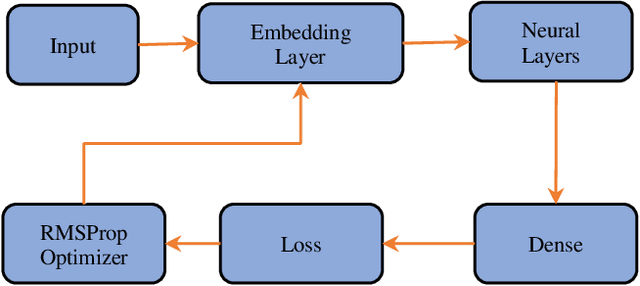
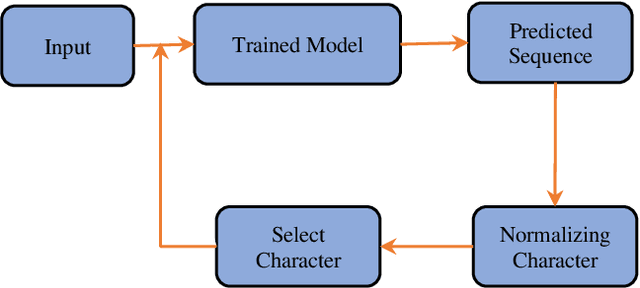
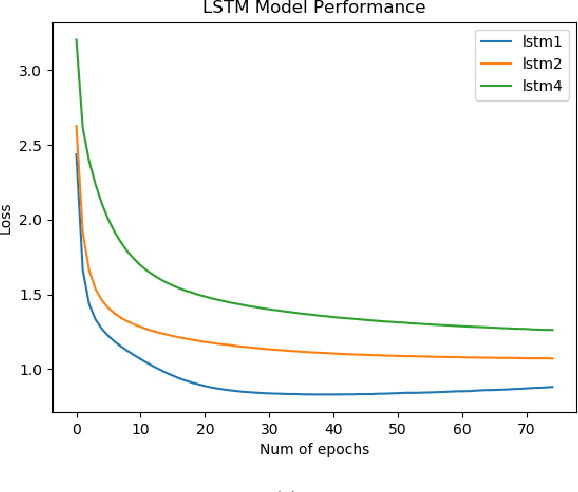
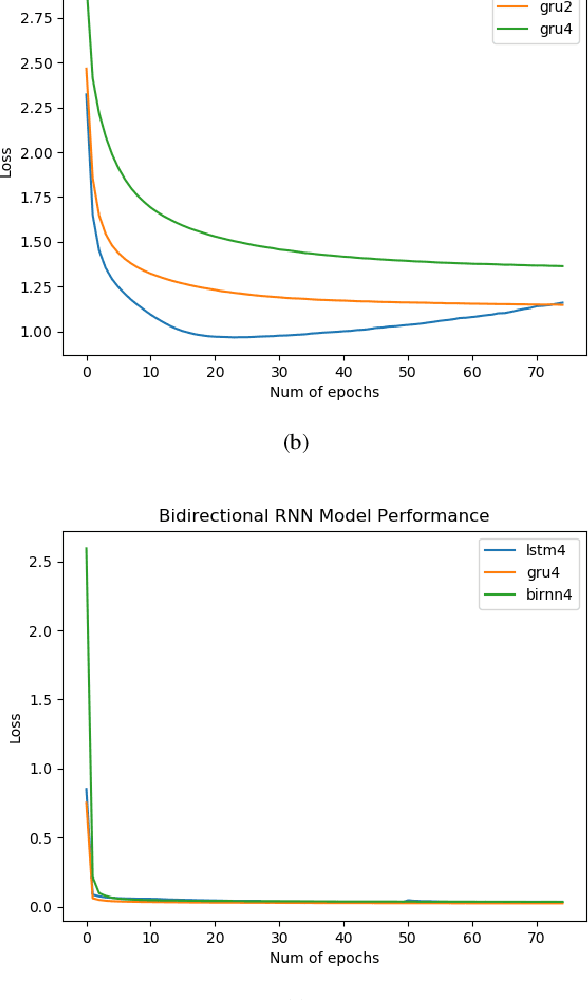
Scripts are an important part of any TV series. They narrate movements, actions and expressions of characters. In this paper, a case study is presented on how different sequence to sequence deep learning models perform in the task of generating new conversations between characters as well as new scenarios on the basis of a script (previous conversations). A comprehensive comparison between these models, namely, LSTM, GRU and Bidirectional RNN is presented. All the models are designed to learn the sequence of recurring characters from the input sequence. Each input sequence will contain, say "n" characters, and the corresponding targets will contain the same number of characters, except, they will be shifted one character to the right. In this manner, input and output sequences are generated and used to train the models. A closer analysis of explored models performance and efficiency is delineated with the help of graph plots and generated texts by taking some input string. These graphs describe both, intraneural performance and interneural model performance for each model.
LSTM Based Music Generation System
Aug 02, 2019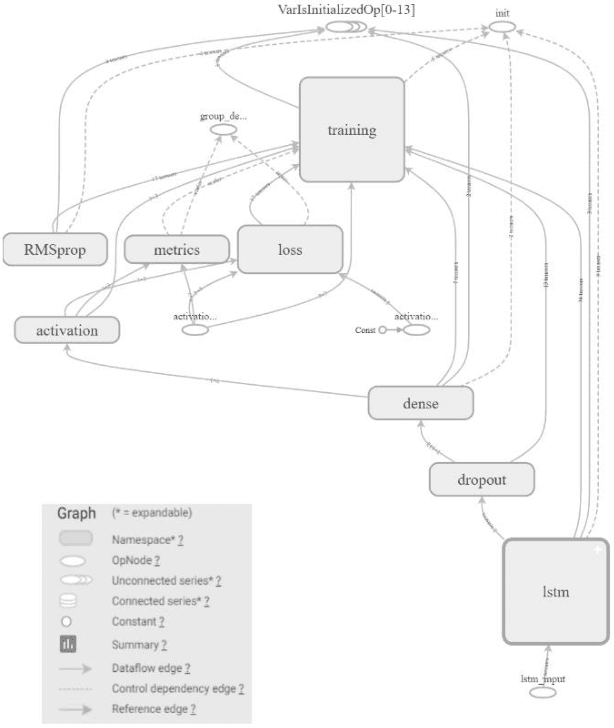
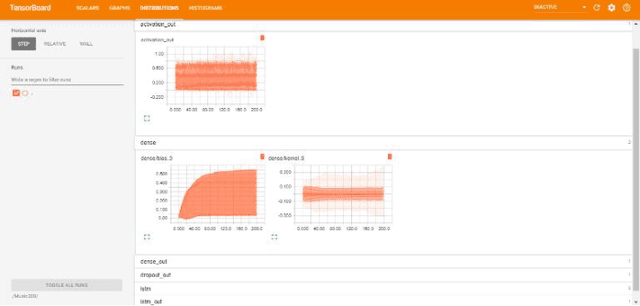
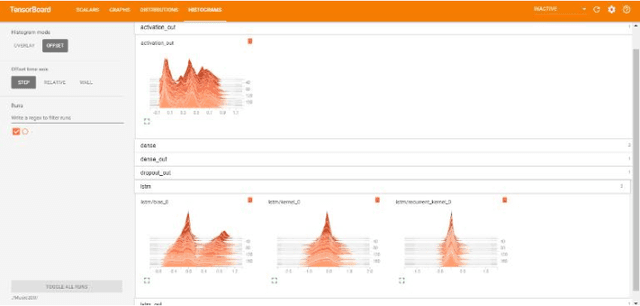
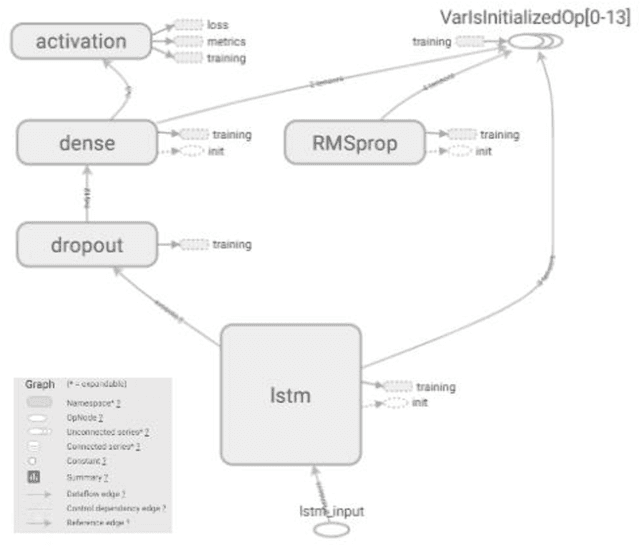
Traditionally, music was treated as an analogue signal and was generated manually. In recent years, music is conspicuous to technology which can generate a suite of music automatically without any human intervention. To accomplish this task, we need to overcome some technical challenges which are discussed descriptively in this paper. A brief introduction about music and its components is provided in the paper along with the citation and analysis of related work accomplished by different authors in this domain. Main objective of this paper is to propose an algorithm which can be used to generate musical notes using Recurrent Neural Networks (RNN), principally Long Short-Term Memory (LSTM) networks. A model is designed to execute this algorithm where data is represented with the help of musical instrument digital interface (MIDI) file format for easier access and better understanding. Preprocessing of data before feeding it into the model, revealing methods to read, process and prepare MIDI files for input are also discussed. The model used in this paper is used to learn the sequences of polyphonic musical notes over a single-layered LSTM network. The model must have the potential to recall past details of a musical sequence and its structure for better learning. Description of layered architecture used in LSTM model and its intertwining connections to develop a neural network is presented in this work. This paper imparts a peek view of distributions of weights and biases in every layer of the model along with a precise representation of losses and accuracy at each step and batches. When the model was thoroughly analyzed, it produced stellar results in composing new melodies.
* 6 pages, 11 figures