 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamson Tan
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021




Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
TraVLR: Now You See It, Now You Don't! Evaluating Cross-Modal Transfer of Visio-Linguistic Reasoning
Nov 21, 2021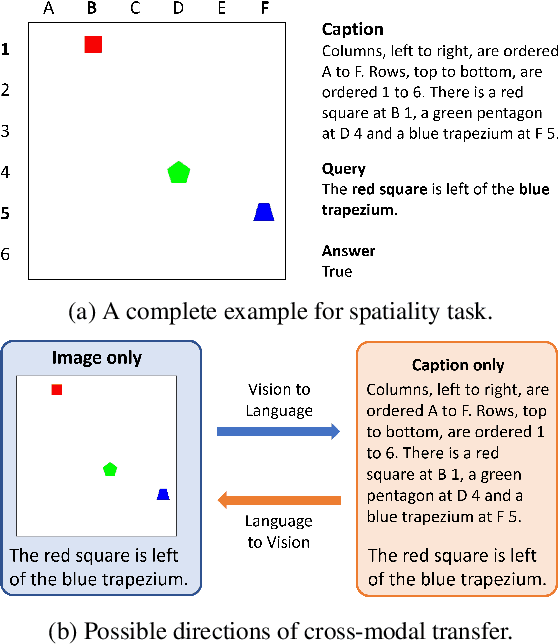

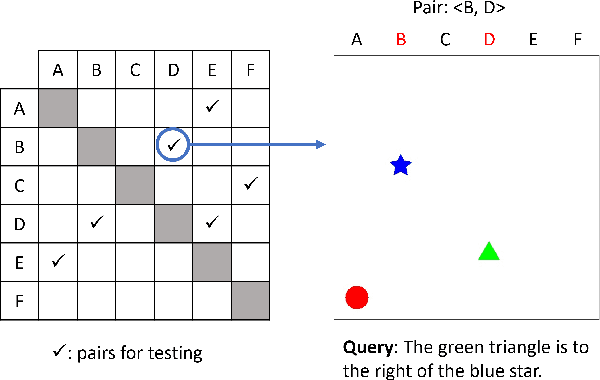
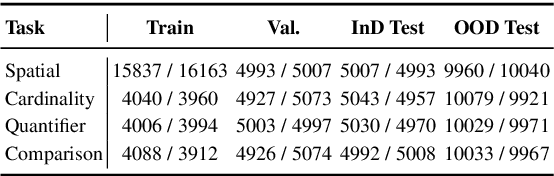
Numerous visio-linguistic (V+L) representation learning methods have been developed, yet existing datasets do not evaluate the extent to which they represent visual and linguistic concepts in a unified space. Inspired by the crosslingual transfer and psycholinguistics literature, we propose a novel evaluation setting for V+L models: zero-shot cross-modal transfer. Existing V+L benchmarks also often report global accuracy scores on the entire dataset, rendering it difficult to pinpoint the specific reasoning tasks that models fail and succeed at. To address this issue and enable the evaluation of cross-modal transfer, we present TraVLR, a synthetic dataset comprising four V+L reasoning tasks. Each example encodes the scene bimodally such that either modality can be dropped during training/testing with no loss of relevant information. TraVLR's training and testing distributions are also constrained along task-relevant dimensions, enabling the evaluation of out-of-distribution generalisation. We evaluate four state-of-the-art V+L models and find that although they perform well on the test set from the same modality, all models fail to transfer cross-modally and have limited success accommodating the addition or deletion of one modality. In alignment with prior work, we also find these models to require large amounts of data to learn simple spatial relationships. We release TraVLR as an open challenge for the research community.
Causally Estimating the Sensitivity of Neural NLP Models to Spurious Features
Oct 14, 2021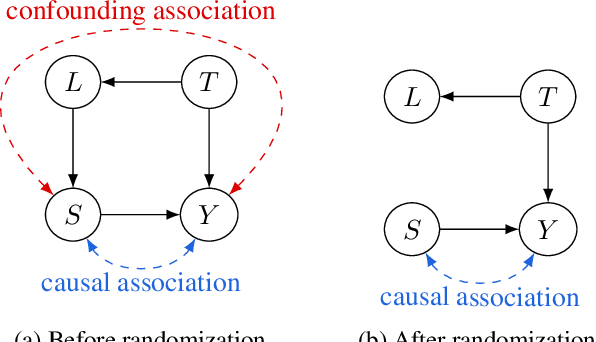
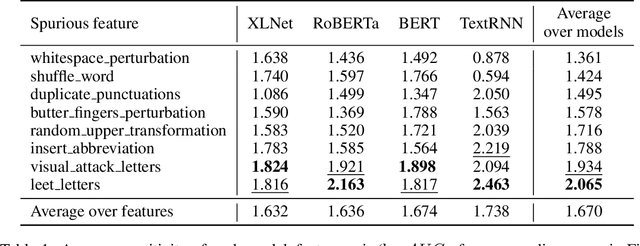
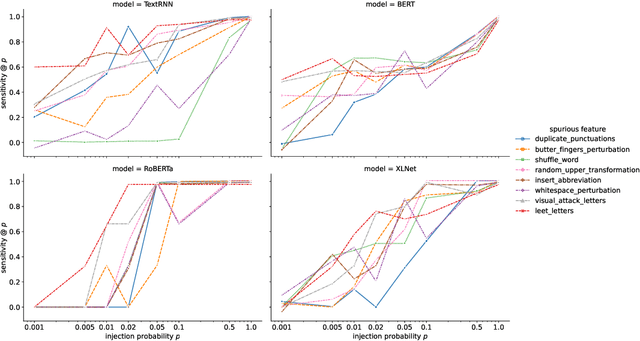
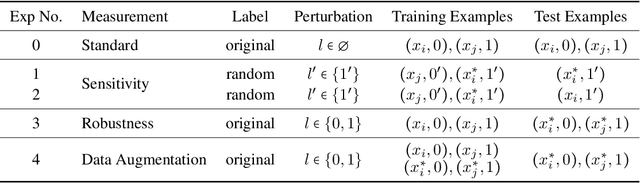
Recent work finds modern natural language processing (NLP) models relying on spurious features for prediction. Mitigating such effects is thus important. Despite this need, there is no quantitative measure to evaluate or compare the effects of different forms of spurious features in NLP. We address this gap in the literature by quantifying model sensitivity to spurious features with a causal estimand, dubbed CENT, which draws on the concept of average treatment effect from the causality literature. By conducting simulations with four prominent NLP models -- TextRNN, BERT, RoBERTa and XLNet -- we rank the models against their sensitivity to artificial injections of eight spurious features. We further hypothesize and validate that models that are more sensitive to a spurious feature will be less robust against perturbations with this feature during inference. Conversely, data augmentation with this feature improves robustness to similar perturbations. We find statistically significant inverse correlations between sensitivity and robustness, providing empirical support for our hypothesis.
Reliability Testing for Natural Language Processing Systems
Jun 01, 2021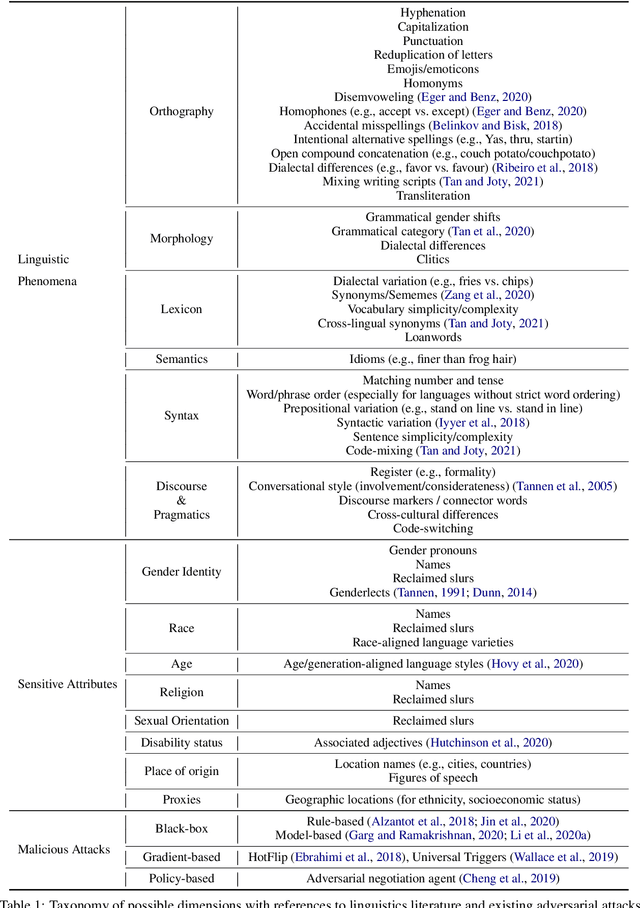
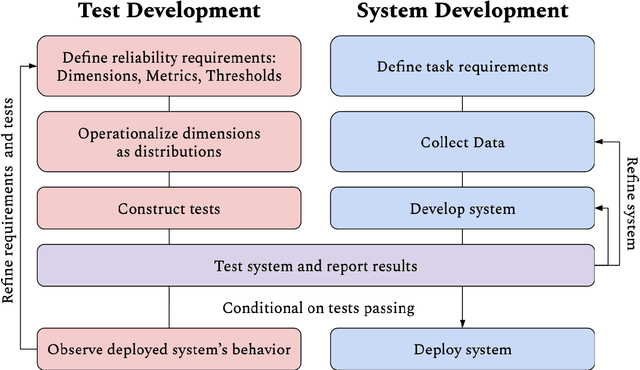
Questions of fairness, robustness, and transparency are paramount to address before deploying NLP systems. Central to these concerns is the question of reliability: Can NLP systems reliably treat different demographics fairly and function correctly in diverse and noisy environments? To address this, we argue for the need for reliability testing and contextualize it among existing work on improving accountability. We show how adversarial attacks can be reframed for this goal, via a framework for developing reliability tests. We argue that reliability testing -- with an emphasis on interdisciplinary collaboration -- will enable rigorous and targeted testing, and aid in the enactment and enforcement of industry standards.
Code-Mixing on Sesame Street: Dawn of the Adversarial Polyglots
Mar 17, 2021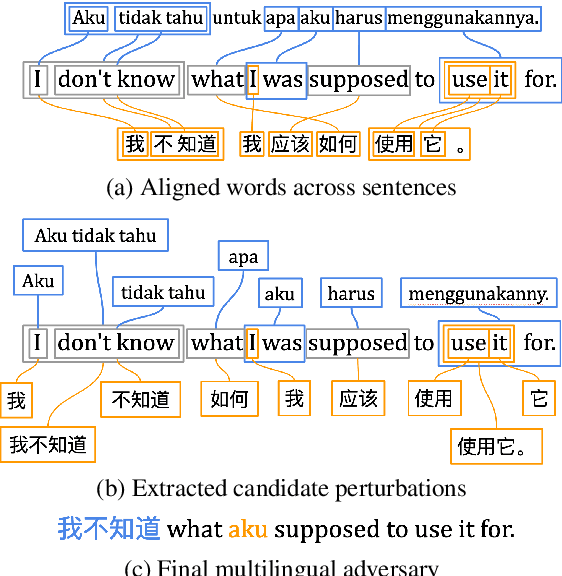

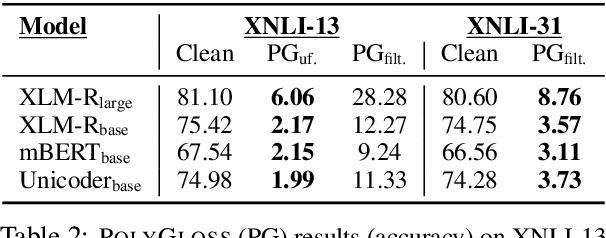
Multilingual models have demonstrated impressive cross-lingual transfer performance. However, test sets like XNLI are monolingual at the example level. In multilingual communities, it is common for polyglots to code-mix when conversing with each other. Inspired by this phenomenon, we present two strong black-box adversarial attacks (one word-level, one phrase-level) for multilingual models that push their ability to handle code-mixed sentences to the limit. The former uses bilingual dictionaries to propose perturbations and translations of the clean example for sense disambiguation. The latter directly aligns the clean example with its translations before extracting phrases as perturbations. Our phrase-level attack has a success rate of 89.75% against XLM-R-large, bringing its average accuracy of 79.85 down to 8.18 on XNLI. Finally, we propose an efficient adversarial training scheme that trains in the same number of steps as the original model and show that it improves model accuracy.
Robustness Gym: Unifying the NLP Evaluation Landscape
Jan 13, 2021Despite impressive performance on standard benchmarks, deep neural networks are often brittle when deployed in real-world systems. Consequently, recent research has focused on testing the robustness of such models, resulting in a diverse set of evaluation methodologies ranging from adversarial attacks to rule-based data transformations. In this work, we identify challenges with evaluating NLP systems and propose a solution in the form of Robustness Gym (RG), a simple and extensible evaluation toolkit that unifies 4 standard evaluation paradigms: subpopulations, transformations, evaluation sets, and adversarial attacks. By providing a common platform for evaluation, Robustness Gym enables practitioners to compare results from all 4 evaluation paradigms with just a few clicks, and to easily develop and share novel evaluation methods using a built-in set of abstractions. To validate Robustness Gym's utility to practitioners, we conducted a real-world case study with a sentiment-modeling team, revealing performance degradations of 18%+. To verify that Robustness Gym can aid novel research analyses, we perform the first study of state-of-the-art commercial and academic named entity linking (NEL) systems, as well as a fine-grained analysis of state-of-the-art summarization models. For NEL, commercial systems struggle to link rare entities and lag their academic counterparts by 10%+, while state-of-the-art summarization models struggle on examples that require abstraction and distillation, degrading by 9%+. Robustness Gym can be found at https://robustnessgym.com/
It's Morphin' Time! Combating Linguistic Discrimination with Inflectional Perturbations
May 09, 2020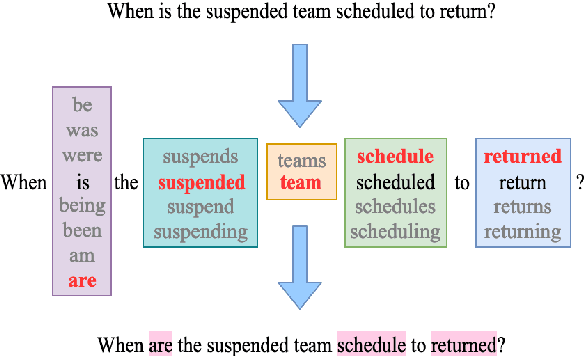

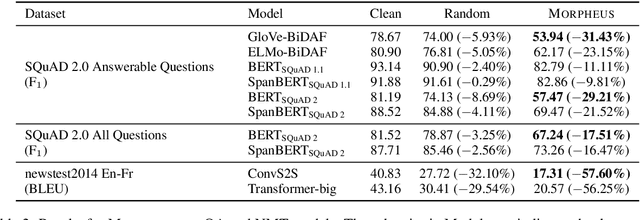
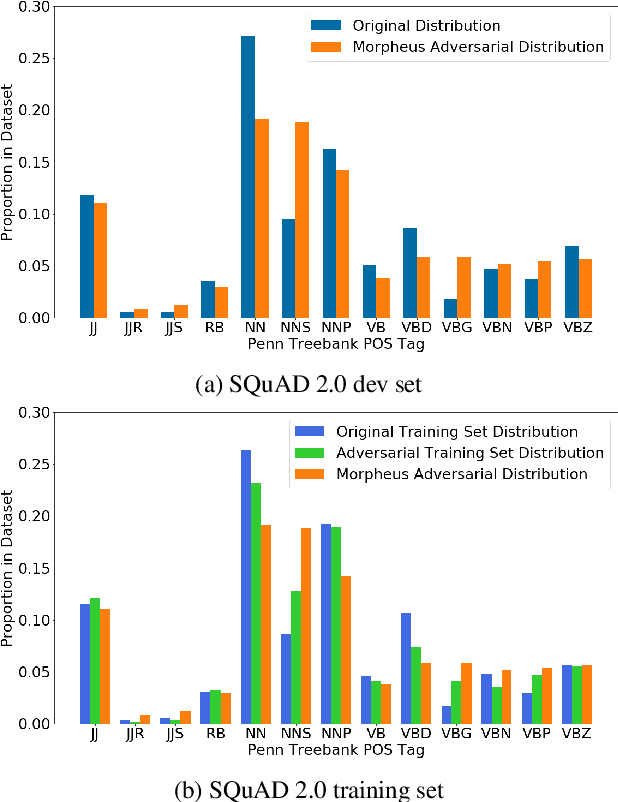
Training on only perfect Standard English corpora predisposes pre-trained neural networks to discriminate against minorities from non-standard linguistic backgrounds (e.g., African American Vernacular English, Colloquial Singapore English, etc.). We perturb the inflectional morphology of words to craft plausible and semantically similar adversarial examples that expose these biases in popular NLP models, e.g., BERT and Transformer, and show that adversarially fine-tuning them for a single epoch significantly improves robustness without sacrificing performance on clean data.
Mind Your Inflections! Improving NLP for Non-Standard English with Base-Inflection Encoding
Apr 30, 2020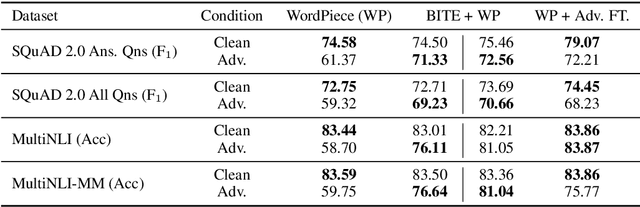
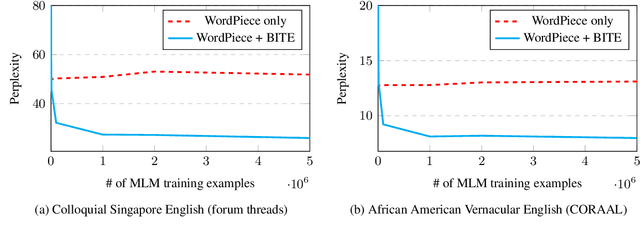
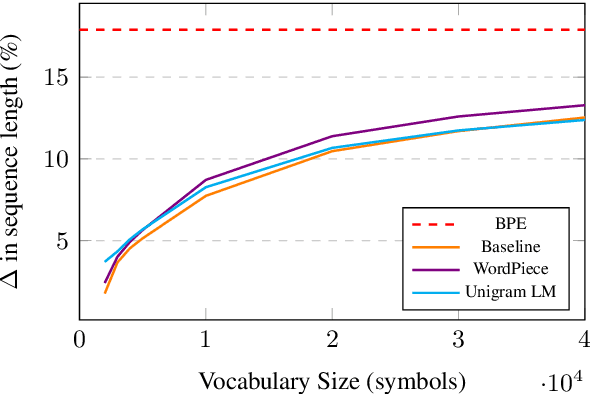
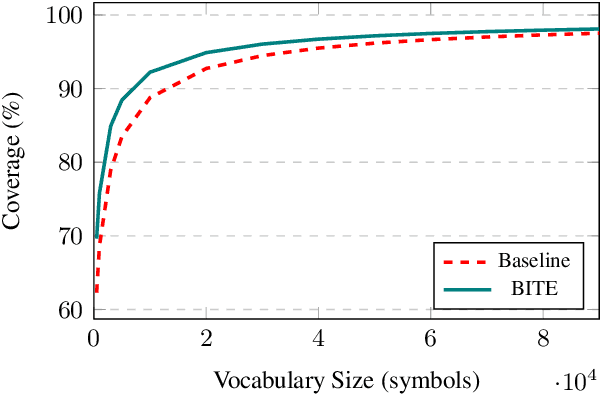
Morphological inflection is a process of word formation where base words are modified to express different grammatical categories such as tense, case, voice, person, or number. World Englishes, such as Colloquial Singapore English (CSE) and African American Vernacular English (AAVE), differ from Standard English dialects in inflection use. Although comprehension by human readers is usually unimpaired by non-standard inflection use, NLP systems are not so robust. We introduce a new Base-Inflection Encoding of English text that is achieved by combining linguistic and statistical techniques. Fine-tuning pre-trained NLP models for downstream tasks under this novel encoding achieves robustness to non-standard inflection use while maintaining performance on Standard English examples. Models using this encoding also generalize better to non-standard dialects without explicit training. We suggest metrics to evaluate tokenizers and extensive model-independent analyses demonstrate the efficacy of the encoding when used together with data-driven subword tokenizers.