 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Generation Using Reinforcement Learning with External Rewards
Nov 26, 2019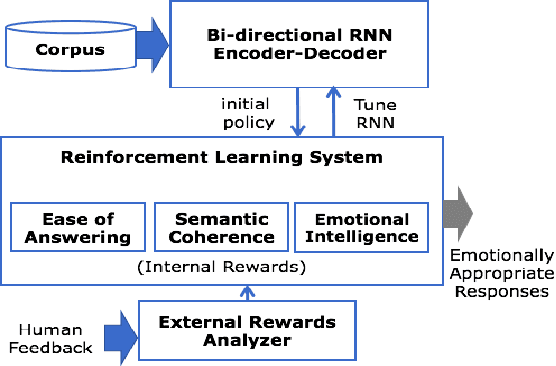


We propose an approach towards natural language generation using a bidirectional encoder-decoder which incorporates external rewards through reinforcement learning (RL). We use attention mechanism and maximum mutual information as an initial objective function using RL. Using a two-part training scheme, we train an external reward analyzer to predict the external rewards and then use the predicted rewards to maximize the expected rewards (both internal and external). We evaluate the system on two standard dialogue corpora - Cornell Movie Dialog Corpus and Yelp Restaurant Review Corpus. We report standard evaluation metrics including BLEU, ROUGE-L, and perplexity as well as human evaluation to validate our approach.
Emotional Neural Language Generation Grounded in Situational Contexts
Nov 25, 2019
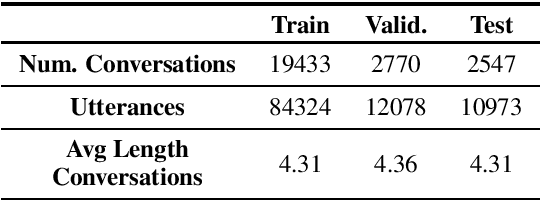
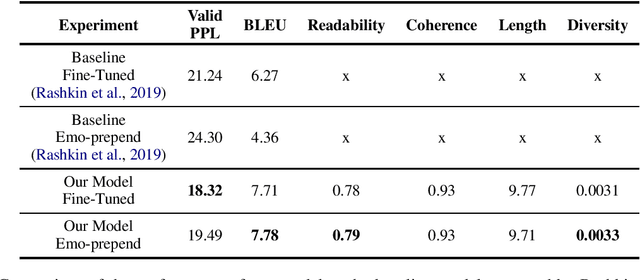
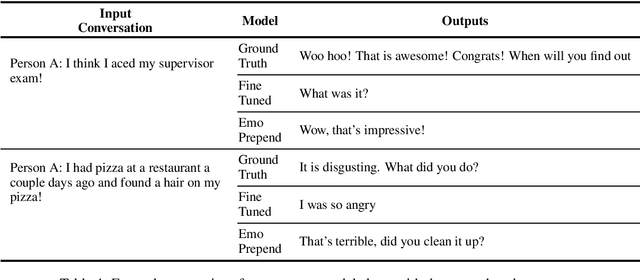
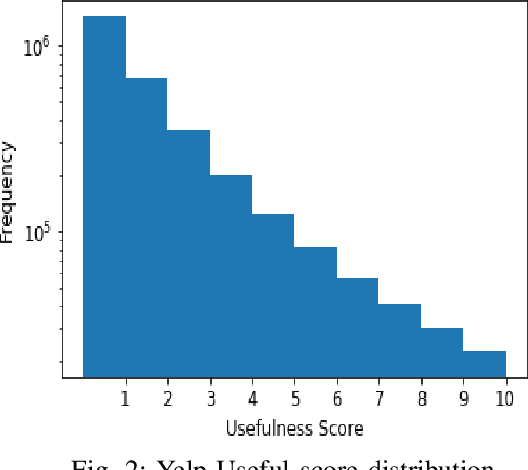
Emotional language generation is one of the keys to human-like artificial intelligence. Humans use different type of emotions depending on the situation of the conversation. Emotions also play an important role in mediating the engagement level with conversational partners. However, current conversational agents do not effectively account for emotional content in the language generation process. To address this problem, we develop a language modeling approach that generates affective content when the dialogue is situated in a given context. We use the recently released Empathetic-Dialogues corpus to build our models. Through detailed experiments, we find that our approach outperforms the state-of-the-art method on the perplexity metric by about 5 points and achieves a higher BLEU metric score.
Towards Best Experiment Design for Evaluating Dialogue System Output
Sep 23, 2019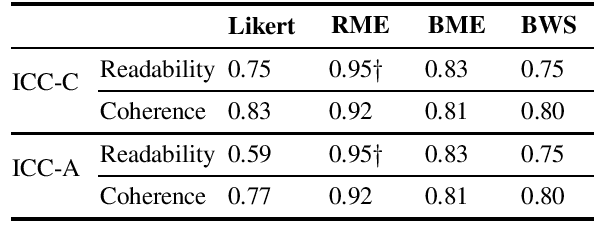
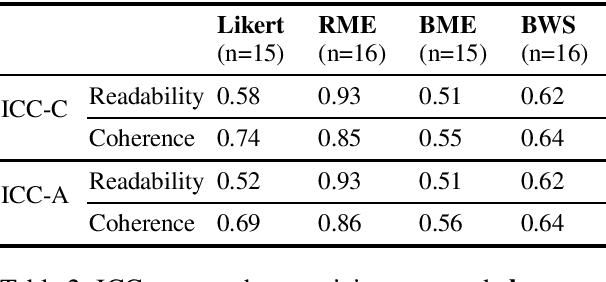
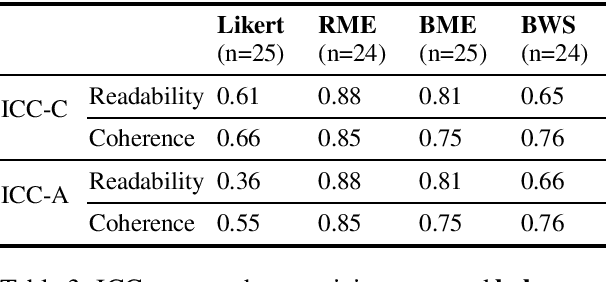
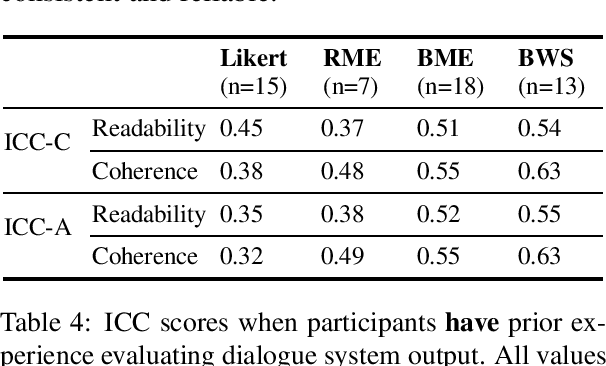
To overcome the limitations of automated metrics (e.g. BLEU, METEOR) for evaluating dialogue systems, researchers typically use human judgments to provide convergent evidence. While it has been demonstrated that human judgments can suffer from the inconsistency of ratings, extant research has also found that the design of the evaluation task affects the consistency and quality of human judgments. We conduct a between-subjects study to understand the impact of four experiment conditions on human ratings of dialogue system output. In addition to discrete and continuous scale ratings, we also experiment with a novel application of Best-Worst scaling to dialogue evaluation. Through our systematic study with 40 crowdsourced workers in each task, we find that using continuous scales achieves more consistent ratings than Likert scale or ranking-based experiment design. Additionally, we find that factors such as time taken to complete the task and no prior experience of participating in similar studies of rating dialogue system output positively impact consistency and agreement amongst raters
I Stand With You: Using Emojis to Study Solidarity in Crisis Events
Jul 19, 2019
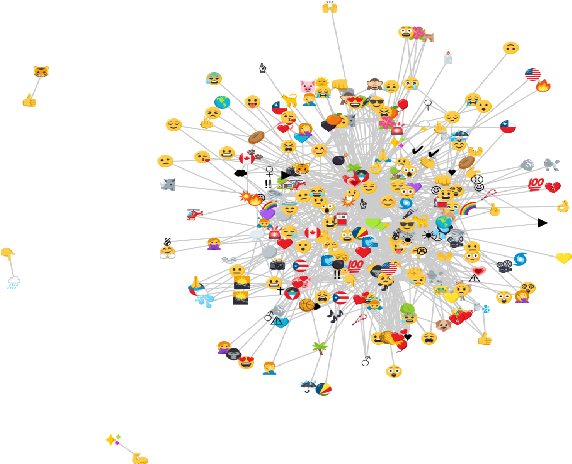
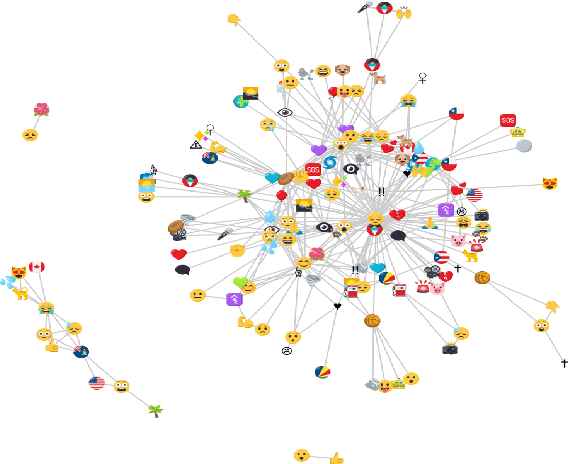
We study how emojis are used to express solidarity in social media in the context of two major crisis events - a natural disaster, Hurricane Irma in 2017 and terrorist attacks that occurred on November 2015 in Paris. Using annotated corpora, we first train a recurrent neural network model to classify expressions of solidarity in text. Next, we use these expressions of solidarity to characterize human behavior in online social networks, through the temporal and geospatial diffusion of emojis. Our analysis reveals that emojis are a powerful indicator of sociolinguistic behaviors (solidarity) that are exhibited on social media as the crisis events unfold.
A Survey of Natural Language Generation Techniques with a Focus on Dialogue Systems - Past, Present and Future Directions
Jun 02, 2019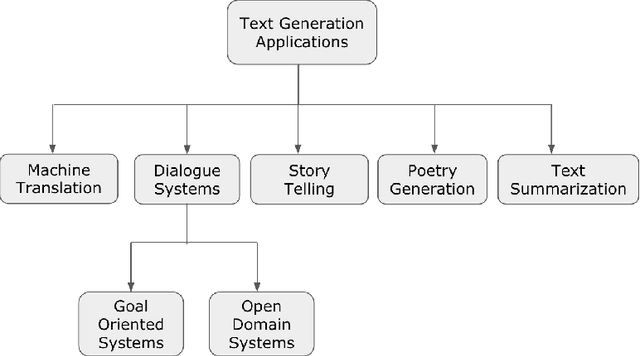
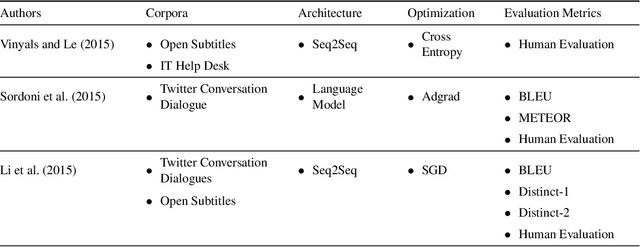
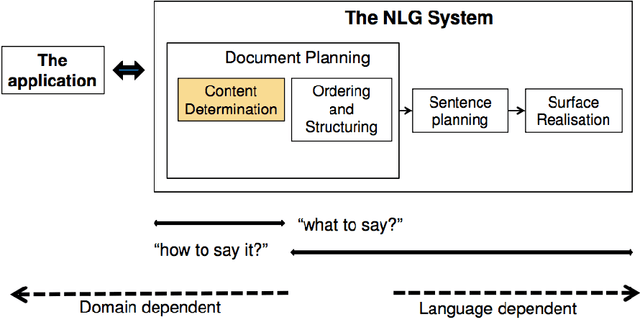
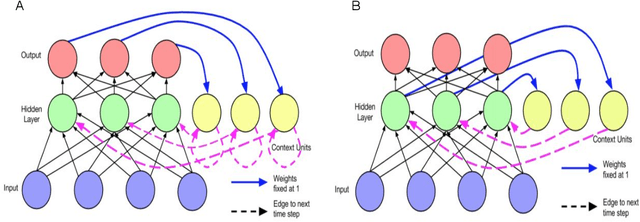
One of the hardest problems in the area of Natural Language Processing and Artificial Intelligence is automatically generating language that is coherent and understandable to humans. Teaching machines how to converse as humans do falls under the broad umbrella of Natural Language Generation. Recent years have seen unprecedented growth in the number of research articles published on this subject in conferences and journals both by academic and industry researchers. There have also been several workshops organized alongside top-tier NLP conferences dedicated specifically to this problem. All this activity makes it hard to clearly define the state of the field and reason about its future directions. In this work, we provide an overview of this important and thriving area, covering traditional approaches, statistical approaches and also approaches that use deep neural networks. We provide a comprehensive review towards building open domain dialogue systems, an important application of natural language generation. We find that, predominantly, the approaches for building dialogue systems use seq2seq or language models architecture. Notably, we identify three important areas of further research towards building more effective dialogue systems: 1) incorporating larger context, including conversation context and world knowledge; 2) adding personae or personality in the NLG system; and 3) overcoming dull and generic responses that affect the quality of system-produced responses. We provide pointers on how to tackle these open problems through the use of cognitive architectures that mimic human language understanding and generation capabilities.