 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamarth Bharadwaj
A deep learning approach to solar-irradiance forecasting in sky-videos
Jan 15, 2019

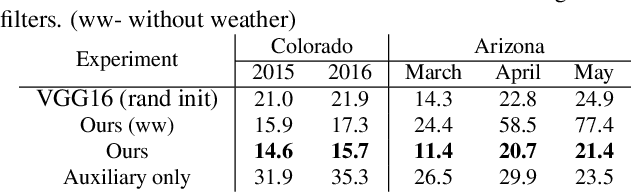
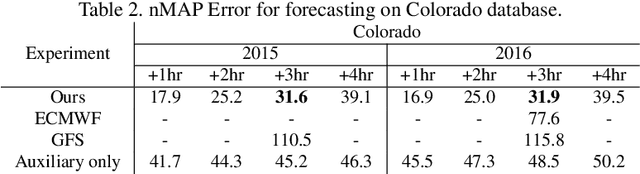
Ahead-of-time forecasting of incident solar-irradiance on a panel is indicative of expected energy yield and is essential for efficient grid distribution and planning. Traditionally, these forecasts are based on meteorological physics models whose parameters are tuned by coarse-grained radiometric tiles sensed from geo-satellites. This research presents a novel application of deep neural network approach to observe and estimate short-term weather effects from videos. Specifically, we use time-lapsed videos (sky-videos) obtained from upward facing wide-lensed cameras (sky-cameras) to directly estimate and forecast solar irradiance. We introduce and present results on two large publicly available datasets obtained from weather stations in two regions of North America using relatively inexpensive optical hardware. These datasets contain over a million images that span for 1 and 12 years respectively, the largest such collection to our knowledge. Compared to satellite based approaches, the proposed deep learning approach significantly reduces the normalized mean-absolute-percentage error for both nowcasting, i.e. prediction of the solar irradiance at the instance the frame is captured, as well as forecasting, ahead-of-time irradiance prediction for a duration for upto 4 hours.
Future semantic segmentation of time-lapsed videos with large temporal displacement
Dec 27, 2018

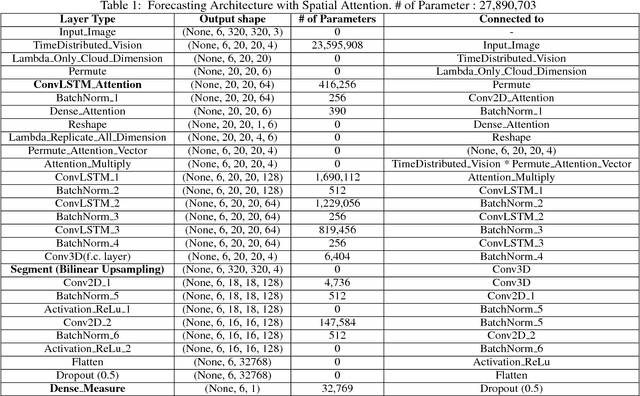
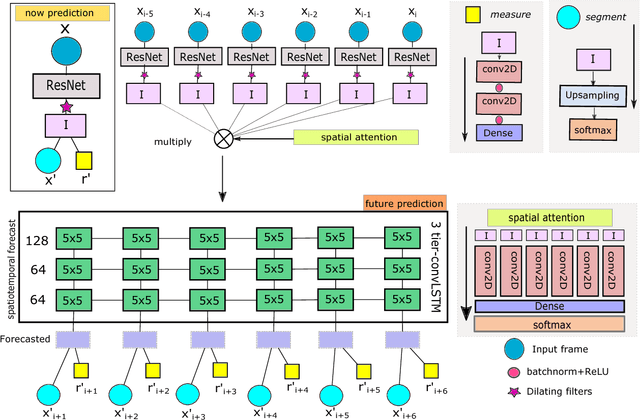
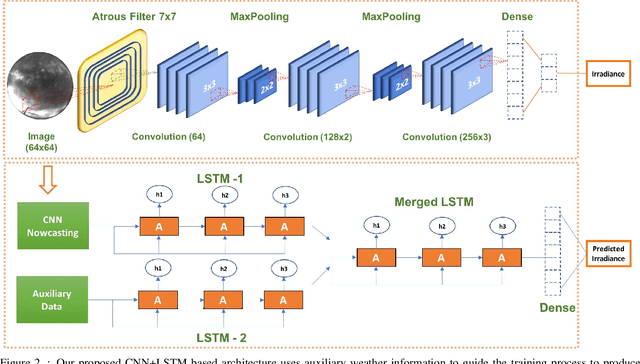
An important aspect of video understanding is the ability to predict the evolution of its content in the future. This paper presents a future frame semantic segmentation technique for predicting semantic masks of the current and future frames in a time-lapsed video. We specifically focus on time-lapsed videos with large temporal displacement to highlight the model's ability to capture large motions in time. We first introduce a unique semantic segmentation prediction dataset with over 120,000 time-lapsed sky-video frames and all corresponding semantic masks captured over a span of five years in North America region. The dataset has immense practical value for cloud cover analysis, which are treated as non-rigid objects of interest. %Here the model provides both semantic segmentation of cloud region and solar irradiance emitted from a region from the sky-videos. Next, our proposed recurrent network architecture departs from existing trend of using temporal convolutional networks (TCN) (or feed-forward networks), by explicitly learning an internal representations for the evolution of video content with time. Experimental evaluation shows an improvement of mean IoU over TCNs in the segmentation task by 10.8% for 10 mins (21% over 60 mins) ahead of time predictions. Further, our model simultaneously measures both the current and future solar irradiance from the same video frames with a normalized-MAE of 10.5% over two years. These results indicate that recurrent memory networks with attention mechanism are able to capture complex advective and diffused flow characteristic of dense fluids even with sparse temporal sampling and are more suitable for future frame prediction tasks for longer duration videos.