 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalman Khan
Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization
Nov 02, 2023
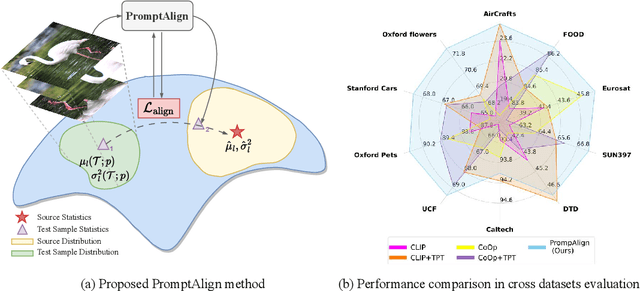

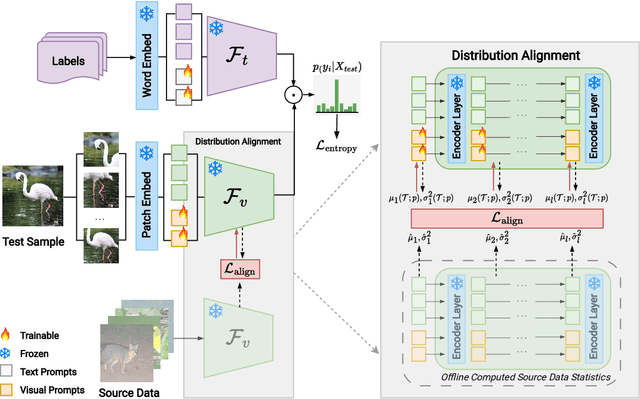
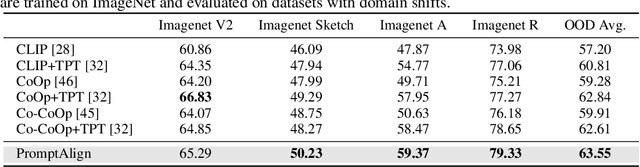
The promising zero-shot generalization of vision-language models such as CLIP has led to their adoption using prompt learning for numerous downstream tasks. Previous works have shown test-time prompt tuning using entropy minimization to adapt text prompts for unseen domains. While effective, this overlooks the key cause for performance degradation to unseen domains -- distribution shift. In this work, we explicitly handle this problem by aligning the out-of-distribution (OOD) test sample statistics to those of the source data using prompt tuning. We use a single test sample to adapt multi-modal prompts at test time by minimizing the feature distribution shift to bridge the gap in the test domain. Evaluating against the domain generalization benchmark, our method improves zero-shot top- 1 accuracy beyond existing prompt-learning techniques, with a 3.08% improvement over the baseline MaPLe. In cross-dataset generalization with unseen categories across 10 datasets, our method improves consistently across all datasets compared to the existing state-of-the-art. Our source code and models are available at https://jameelhassan.github.io/promptalign.
A Hybrid Graph Network for Complex Activity Detection in Video
Oct 30, 2023Interpretation and understanding of video presents a challenging computer vision task in numerous fields - e.g. autonomous driving and sports analytics. Existing approaches to interpreting the actions taking place within a video clip are based upon Temporal Action Localisation (TAL), which typically identifies short-term actions. The emerging field of Complex Activity Detection (CompAD) extends this analysis to long-term activities, with a deeper understanding obtained by modelling the internal structure of a complex activity taking place within the video. We address the CompAD problem using a hybrid graph neural network which combines attention applied to a graph encoding the local (short-term) dynamic scene with a temporal graph modelling the overall long-duration activity. Our approach is as follows: i) Firstly, we propose a novel feature extraction technique which, for each video snippet, generates spatiotemporal `tubes' for the active elements (`agents') in the (local) scene by detecting individual objects, tracking them and then extracting 3D features from all the agent tubes as well as the overall scene. ii) Next, we construct a local scene graph where each node (representing either an agent tube or the scene) is connected to all other nodes. Attention is then applied to this graph to obtain an overall representation of the local dynamic scene. iii) Finally, all local scene graph representations are interconnected via a temporal graph, to estimate the complex activity class together with its start and end time. The proposed framework outperforms all previous state-of-the-art methods on all three datasets including ActivityNet-1.3, Thumos-14, and ROAD.
Videoprompter: an ensemble of foundational models for zero-shot video understanding
Oct 23, 2023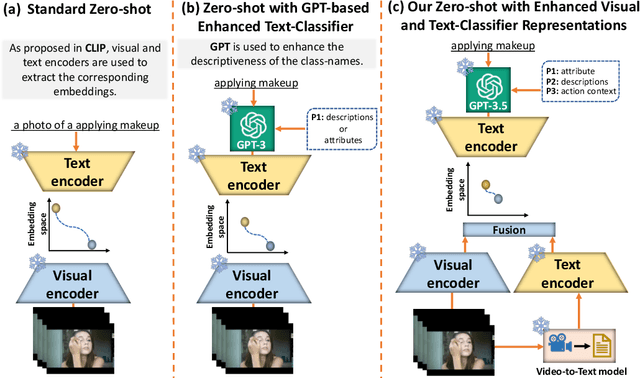


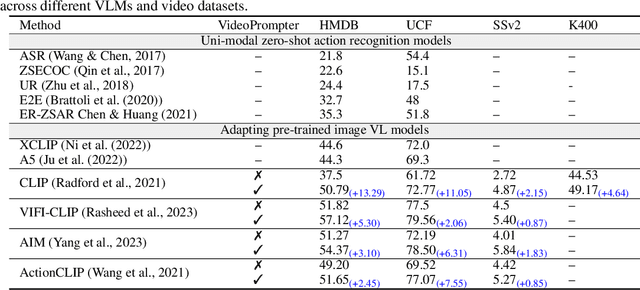
Vision-language models (VLMs) classify the query video by calculating a similarity score between the visual features and text-based class label representations. Recently, large language models (LLMs) have been used to enrich the text-based class labels by enhancing the descriptiveness of the class names. However, these improvements are restricted to the text-based classifier only, and the query visual features are not considered. In this paper, we propose a framework which combines pre-trained discriminative VLMs with pre-trained generative video-to-text and text-to-text models. We introduce two key modifications to the standard zero-shot setting. First, we propose language-guided visual feature enhancement and employ a video-to-text model to convert the query video to its descriptive form. The resulting descriptions contain vital visual cues of the query video, such as what objects are present and their spatio-temporal interactions. These descriptive cues provide additional semantic knowledge to VLMs to enhance their zeroshot performance. Second, we propose video-specific prompts to LLMs to generate more meaningful descriptions to enrich class label representations. Specifically, we introduce prompt techniques to create a Tree Hierarchy of Categories for class names, offering a higher-level action context for additional visual cues, We demonstrate the effectiveness of our approach in video understanding across three different zero-shot settings: 1) video action recognition, 2) video-to-text and textto-video retrieval, and 3) time-sensitive video tasks. Consistent improvements across multiple benchmarks and with various VLMs demonstrate the effectiveness of our proposed framework. Our code will be made publicly available.
LLM Blueprint: Enabling Text-to-Image Generation with Complex and Detailed Prompts
Oct 16, 2023Diffusion-based generative models have significantly advanced text-to-image generation but encounter challenges when processing lengthy and intricate text prompts describing complex scenes with multiple objects. While excelling in generating images from short, single-object descriptions, these models often struggle to faithfully capture all the nuanced details within longer and more elaborate textual inputs. In response, we present a novel approach leveraging Large Language Models (LLMs) to extract critical components from text prompts, including bounding box coordinates for foreground objects, detailed textual descriptions for individual objects, and a succinct background context. These components form the foundation of our layout-to-image generation model, which operates in two phases. The initial Global Scene Generation utilizes object layouts and background context to create an initial scene but often falls short in faithfully representing object characteristics as specified in the prompts. To address this limitation, we introduce an Iterative Refinement Scheme that iteratively evaluates and refines box-level content to align them with their textual descriptions, recomposing objects as needed to ensure consistency. Our evaluation on complex prompts featuring multiple objects demonstrates a substantial improvement in recall compared to baseline diffusion models. This is further validated by a user study, underscoring the efficacy of our approach in generating coherent and detailed scenes from intricate textual inputs.
Sentence-level Prompts Benefit Composed Image Retrieval
Oct 09, 2023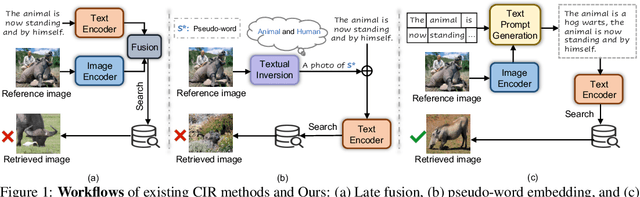
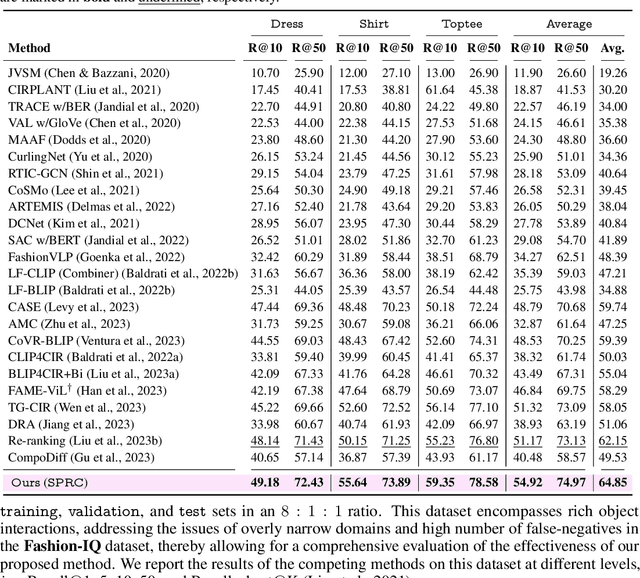
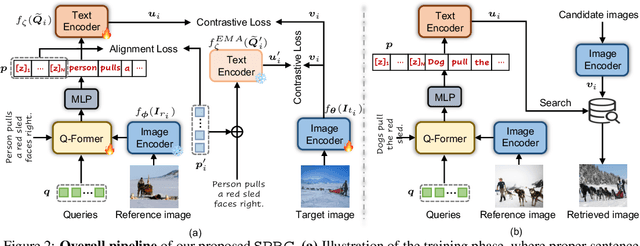
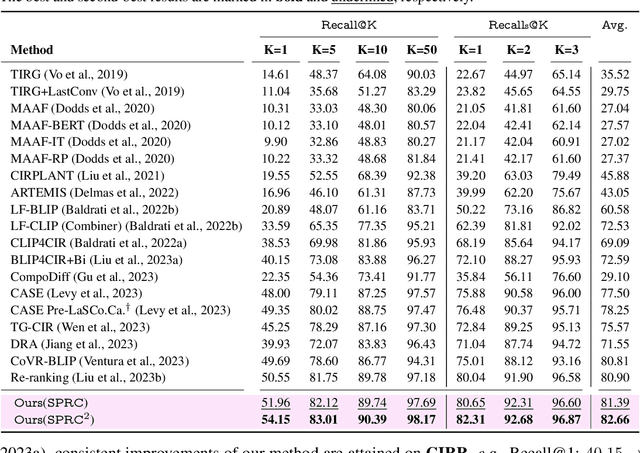
Composed image retrieval (CIR) is the task of retrieving specific images by using a query that involves both a reference image and a relative caption. Most existing CIR models adopt the late-fusion strategy to combine visual and language features. Besides, several approaches have also been suggested to generate a pseudo-word token from the reference image, which is further integrated into the relative caption for CIR. However, these pseudo-word-based prompting methods have limitations when target image encompasses complex changes on reference image, e.g., object removal and attribute modification. In this work, we demonstrate that learning an appropriate sentence-level prompt for the relative caption (SPRC) is sufficient for achieving effective composed image retrieval. Instead of relying on pseudo-word-based prompts, we propose to leverage pretrained V-L models, e.g., BLIP-2, to generate sentence-level prompts. By concatenating the learned sentence-level prompt with the relative caption, one can readily use existing text-based image retrieval models to enhance CIR performance. Furthermore, we introduce both image-text contrastive loss and text prompt alignment loss to enforce the learning of suitable sentence-level prompts. Experiments show that our proposed method performs favorably against the state-of-the-art CIR methods on the Fashion-IQ and CIRR datasets. The source code and pretrained model are publicly available at https://github.com/chunmeifeng/SPRC
3D Indoor Instance Segmentation in an Open-World
Sep 25, 2023Existing 3D instance segmentation methods typically assume that all semantic classes to be segmented would be available during training and only seen categories are segmented at inference. We argue that such a closed-world assumption is restrictive and explore for the first time 3D indoor instance segmentation in an open-world setting, where the model is allowed to distinguish a set of known classes as well as identify an unknown object as unknown and then later incrementally learning the semantic category of the unknown when the corresponding category labels are available. To this end, we introduce an open-world 3D indoor instance segmentation method, where an auto-labeling scheme is employed to produce pseudo-labels during training and induce separation to separate known and unknown category labels. We further improve the pseudo-labels quality at inference by adjusting the unknown class probability based on the objectness score distribution. We also introduce carefully curated open-world splits leveraging realistic scenarios based on inherent object distribution, region-based indoor scene exploration and randomness aspect of open-world classes. Extensive experiments reveal the efficacy of the proposed contributions leading to promising open-world 3D instance segmentation performance.
Multi-grained Temporal Prototype Learning for Few-shot Video Object Segmentation
Sep 20, 2023
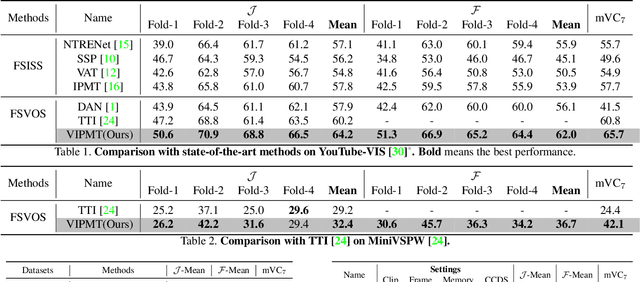
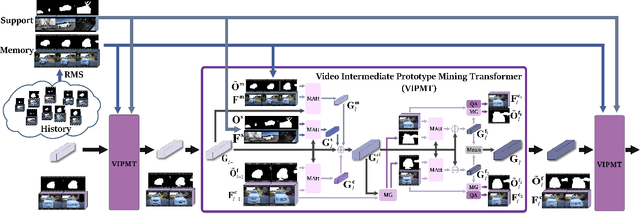
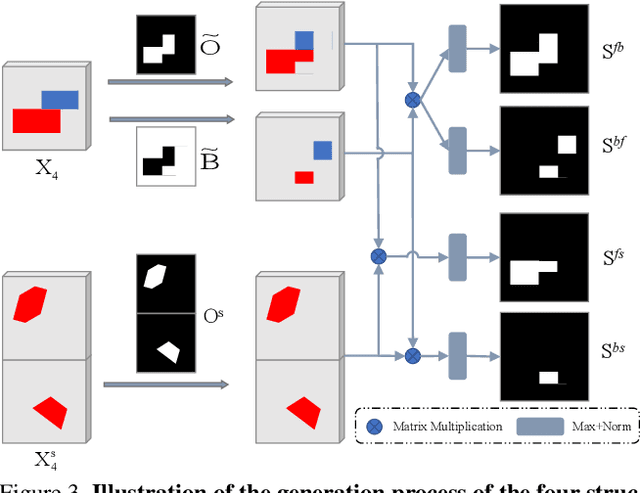
Few-Shot Video Object Segmentation (FSVOS) aims to segment objects in a query video with the same category defined by a few annotated support images. However, this task was seldom explored. In this work, based on IPMT, a state-of-the-art few-shot image segmentation method that combines external support guidance information with adaptive query guidance cues, we propose to leverage multi-grained temporal guidance information for handling the temporal correlation nature of video data. We decompose the query video information into a clip prototype and a memory prototype for capturing local and long-term internal temporal guidance, respectively. Frame prototypes are further used for each frame independently to handle fine-grained adaptive guidance and enable bidirectional clip-frame prototype communication. To reduce the influence of noisy memory, we propose to leverage the structural similarity relation among different predicted regions and the support for selecting reliable memory frames. Furthermore, a new segmentation loss is also proposed to enhance the category discriminability of the learned prototypes. Experimental results demonstrate that our proposed video IPMT model significantly outperforms previous models on two benchmark datasets. Code is available at https://github.com/nankepan/VIPMT.
Unsupervised Landmark Discovery Using Consistency Guided Bottleneck
Sep 19, 2023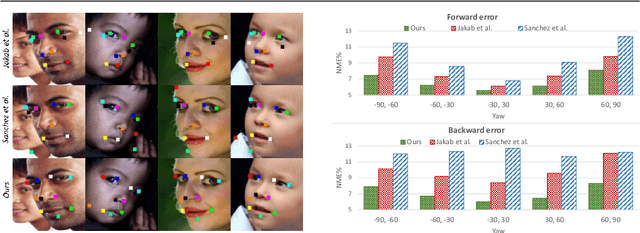
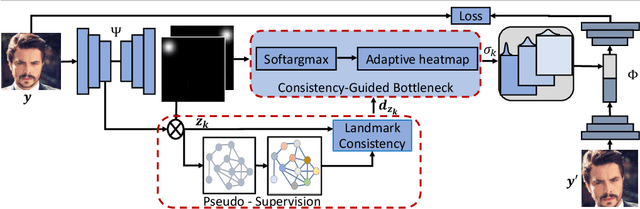
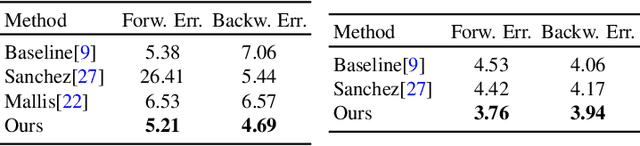
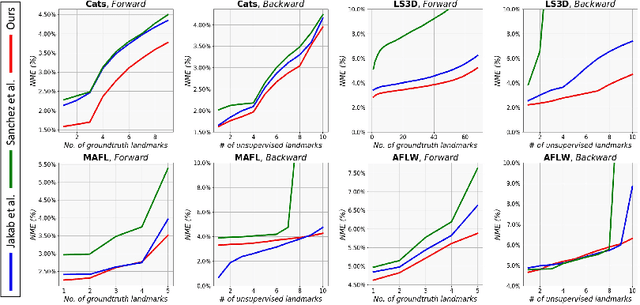
We study a challenging problem of unsupervised discovery of object landmarks. Many recent methods rely on bottlenecks to generate 2D Gaussian heatmaps however, these are limited in generating informed heatmaps while training, presumably due to the lack of effective structural cues. Also, it is assumed that all predicted landmarks are semantically relevant despite having no ground truth supervision. In the current work, we introduce a consistency-guided bottleneck in an image reconstruction-based pipeline that leverages landmark consistency, a measure of compatibility score with the pseudo-ground truth to generate adaptive heatmaps. We propose obtaining pseudo-supervision via forming landmark correspondence across images. The consistency then modulates the uncertainty of the discovered landmarks in the generation of adaptive heatmaps which rank consistent landmarks above their noisy counterparts, providing effective structural information for improved robustness. Evaluations on five diverse datasets including MAFL, AFLW, LS3D, Cats, and Shoes demonstrate excellent performance of the proposed approach compared to the existing state-of-the-art methods. Our code is publicly available at https://github.com/MamonaAwan/CGB_ULD.
Towards Realistic Zero-Shot Classification via Self Structural Semantic Alignment
Aug 24, 2023
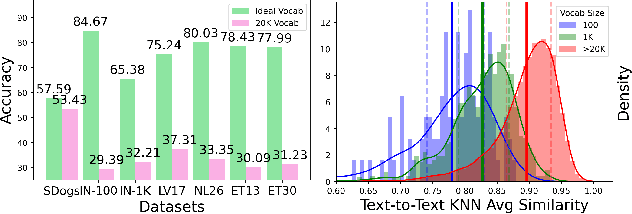
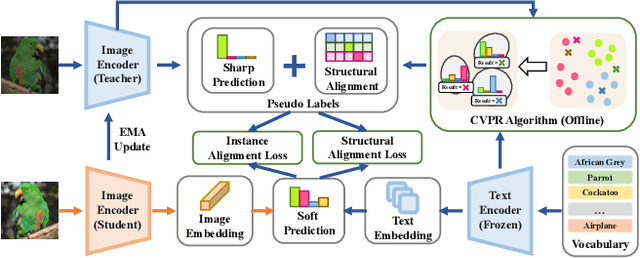
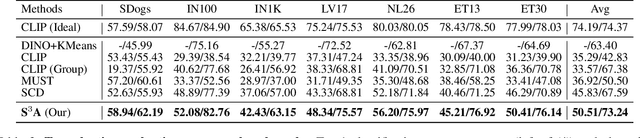
Large-scale pre-trained Vision Language Models (VLMs) have proven effective for zero-shot classification. Despite the success, most traditional VLMs-based methods are restricted by the assumption of partial source supervision or ideal vocabularies, which rarely satisfy the open-world scenario. In this paper, we aim at a more challenging setting, Realistic Zero-Shot Classification, which assumes no annotation but instead a broad vocabulary. To address this challenge, we propose the Self Structural Semantic Alignment (S^3A) framework, which extracts the structural semantic information from unlabeled data while simultaneously self-learning. Our S^3A framework adopts a unique Cluster-Vote-Prompt-Realign (CVPR) algorithm, which iteratively groups unlabeled data to derive structural semantics for pseudo-supervision. Our CVPR process includes iterative clustering on images, voting within each cluster to identify initial class candidates from the vocabulary, generating discriminative prompts with large language models to discern confusing candidates, and realigning images and the vocabulary as structural semantic alignment. Finally, we propose to self-learn the CLIP image encoder with both individual and structural semantic alignment through a teacher-student learning strategy. Our comprehensive experiments across various generic and fine-grained benchmarks demonstrate that the S^3A method offers substantial improvements over existing VLMs-based approaches, achieving a more than 15% accuracy improvement over CLIP on average. Our codes, models, and prompts are publicly released at https://github.com/sheng-eatamath/S3A.
Diverse Data Augmentation with Diffusions for Effective Test-time Prompt Tuning
Aug 17, 2023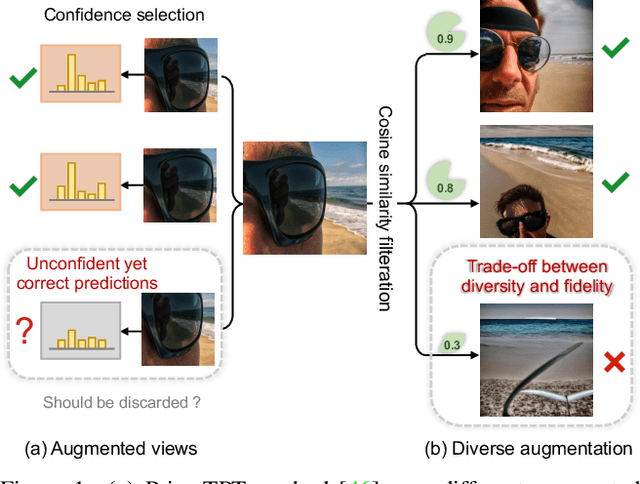
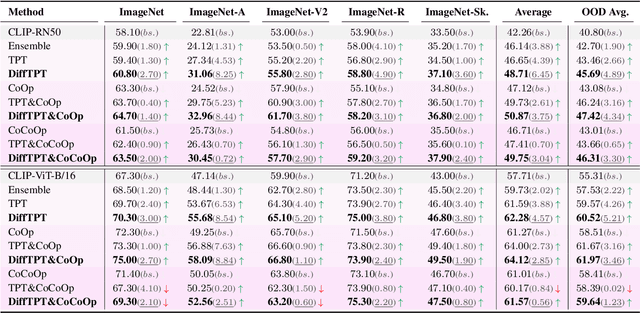
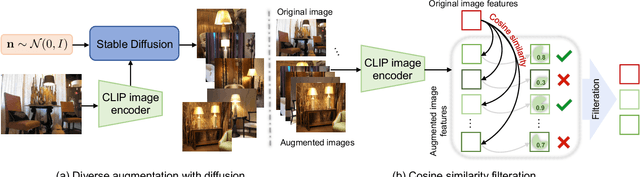
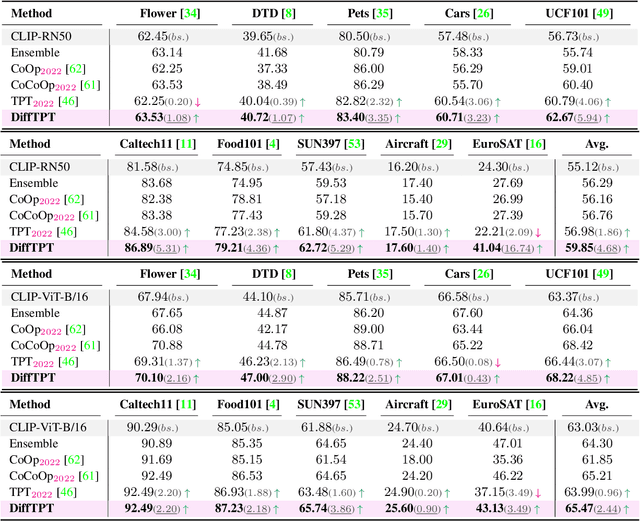
Benefiting from prompt tuning, recent years have witnessed the promising performance of pre-trained vision-language models, e.g., CLIP, on versatile downstream tasks. In this paper, we focus on a particular setting of learning adaptive prompts on the fly for each test sample from an unseen new domain, which is known as test-time prompt tuning (TPT). Existing TPT methods typically rely on data augmentation and confidence selection. However, conventional data augmentation techniques, e.g., random resized crops, suffers from the lack of data diversity, while entropy-based confidence selection alone is not sufficient to guarantee prediction fidelity. To address these issues, we propose a novel TPT method, named DiffTPT, which leverages pre-trained diffusion models to generate diverse and informative new data. Specifically, we incorporate augmented data by both conventional method and pre-trained stable diffusion to exploit their respective merits, improving the models ability to adapt to unknown new test data. Moreover, to ensure the prediction fidelity of generated data, we introduce a cosine similarity-based filtration technique to select the generated data with higher similarity to the single test sample. Our experiments on test datasets with distribution shifts and unseen categories demonstrate that DiffTPT improves the zero-shot accuracy by an average of 5.13\% compared to the state-of-the-art TPT method. Our code and models will be publicly released.