 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGANN: An Efficient Algorithm to Extract Rules from ANNs
Sep 25, 2010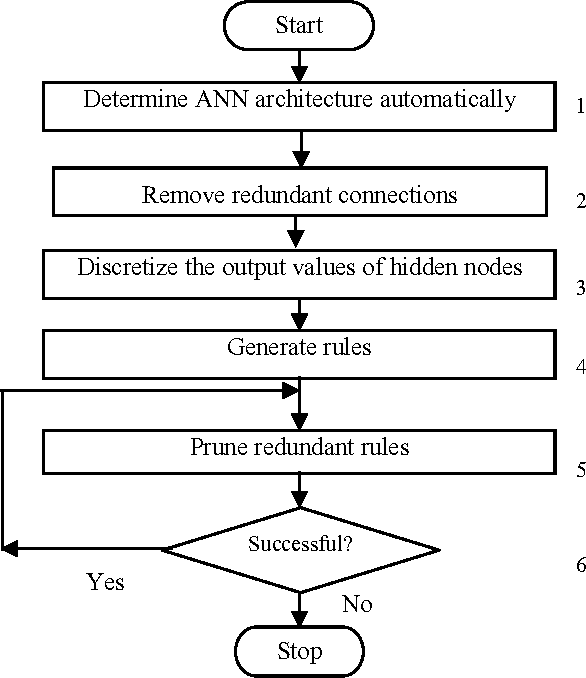
This paper describes an efficient rule generation algorithm, called rule generation from artificial neural networks (RGANN) to generate symbolic rules from ANNs. Classification rules are sought in many areas from automatic knowledge acquisition to data mining and ANN rule extraction. This is because classification rules possess some attractive features. They are explicit, understandable and verifiable by domain experts, and can be modified, extended and passed on as modular knowledge. A standard three-layer feedforward ANN is the basis of the algorithm. A four-phase training algorithm is proposed for backpropagation learning. Comparing them to the symbolic rules generated by other methods supports explicitness of the generated rules. Generated rules are comparable with other methods in terms of number of rules, average number of conditions for a rule, and predictive accuracy. Extensive experimental studies on several benchmarks classification problems, including breast cancer, wine, season, golf-playing, and lenses classification demonstrate the effectiveness of the proposed approach with good generalization ability.
* 12 Pages, International Journal
Optimal Bangla Keyboard Layout using Association Rule of Data Mining
Sep 23, 2010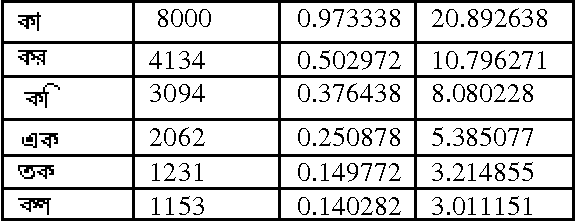
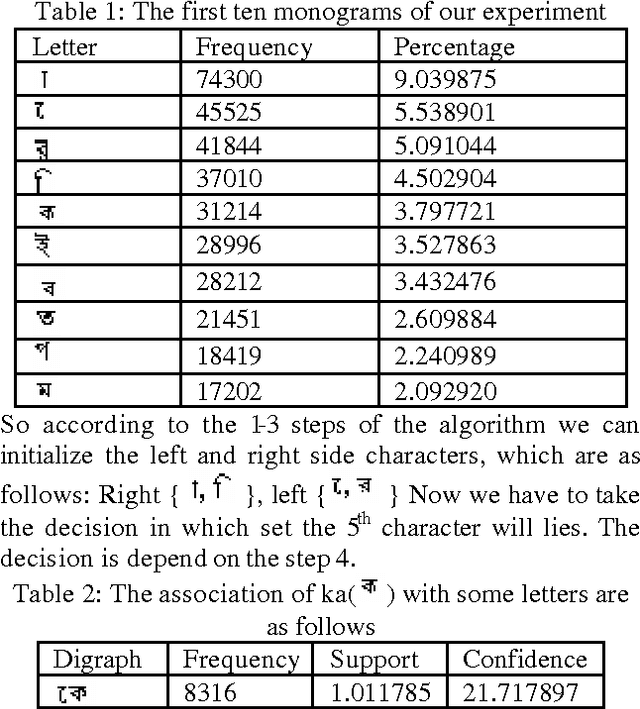

In this paper we present an optimal Bangla Keyboard Layout, which distributes the load equally on both hands so that maximizing the ease and minimizing the effort. Bangla alphabet has a large number of letters, for this it is difficult to type faster using Bangla keyboard. Our proposed keyboard will maximize the speed of operator as they can type with both hands parallel. Here we use the association rule of data mining to distribute the Bangla characters in the keyboard. First, we analyze the frequencies of data consisting of monograph, digraph and trigraph, which are derived from data wire-house, and then used association rule of data mining to distribute the Bangla characters in the layout. Finally, we propose a Bangla Keyboard Layout. Experimental results on several keyboard layout shows the effectiveness of the proposed approach with better performance.
* 3 Pages, International Conference
Text Classification using the Concept of Association Rule of Data Mining
Sep 23, 2010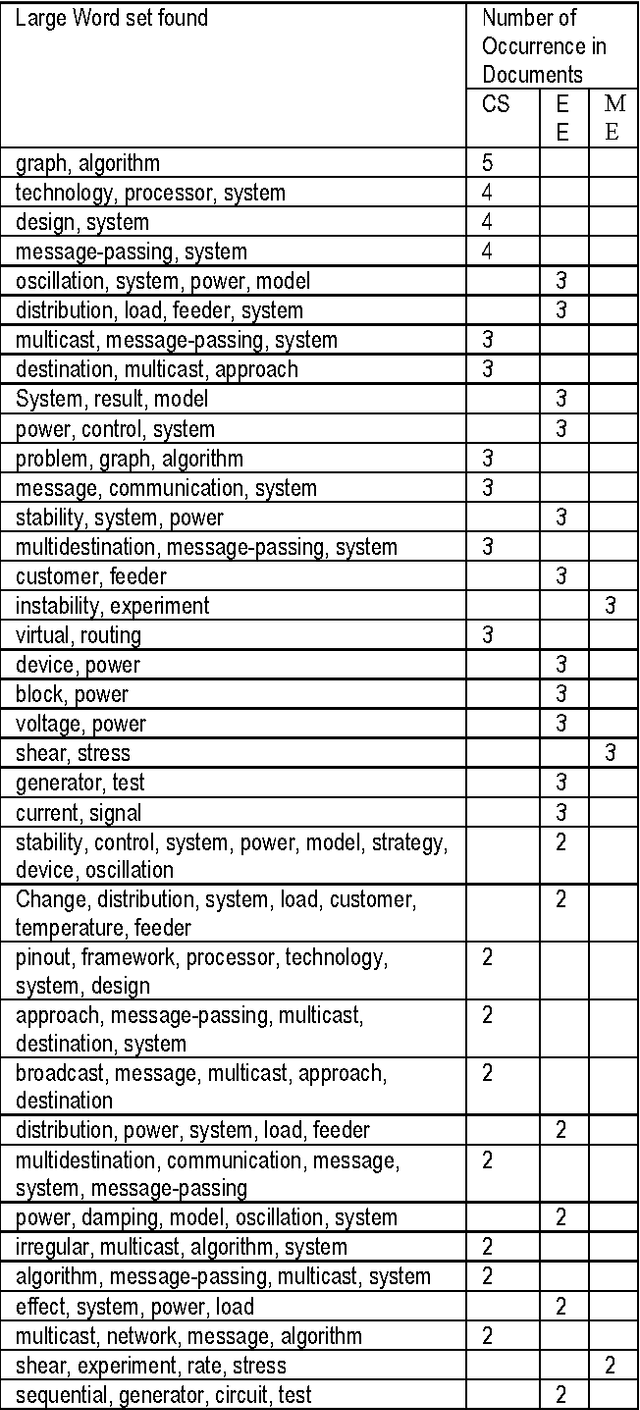
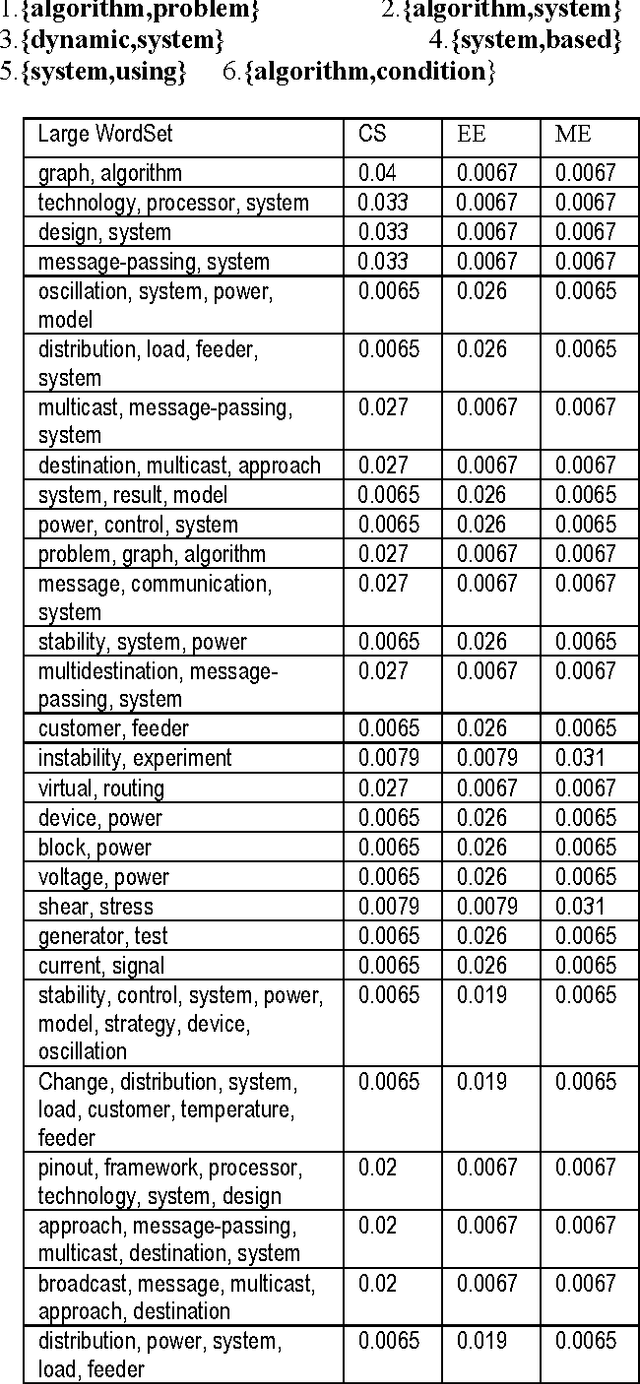
As the amount of online text increases, the demand for text classification to aid the analysis and management of text is increasing. Text is cheap, but information, in the form of knowing what classes a text belongs to, is expensive. Automatic classification of text can provide this information at low cost, but the classifiers themselves must be built with expensive human effort, or trained from texts which have themselves been manually classified. In this paper we will discuss a procedure of classifying text using the concept of association rule of data mining. Association rule mining technique has been used to derive feature set from pre-classified text documents. Naive Bayes classifier is then used on derived features for final classification.
* 8 Pages, International Conference
A hybrid learning algorithm for text classification
Sep 23, 2010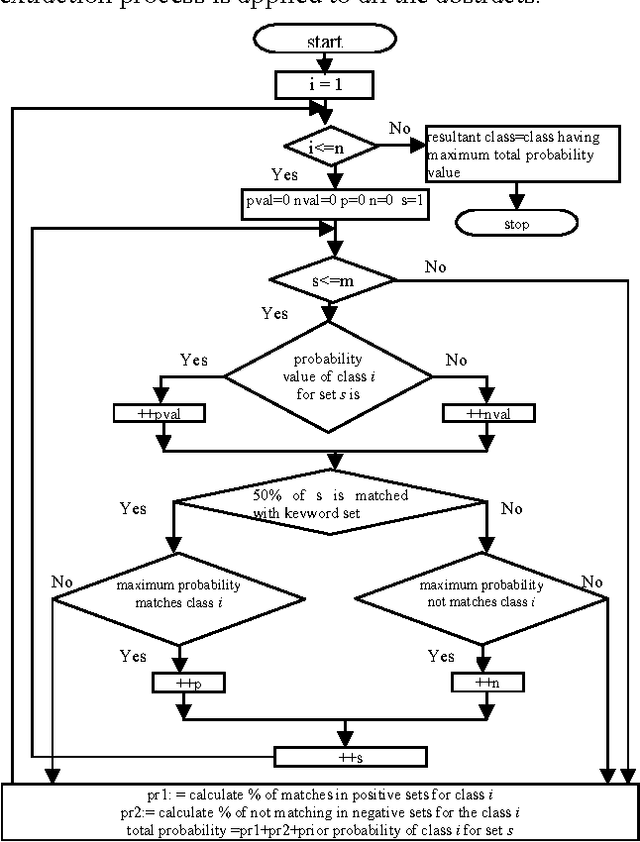
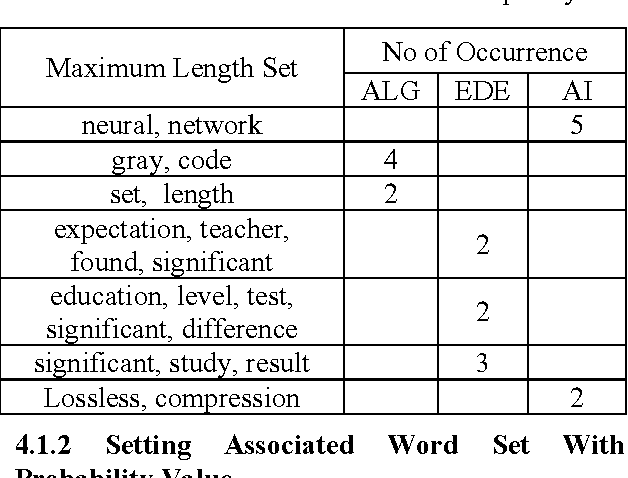
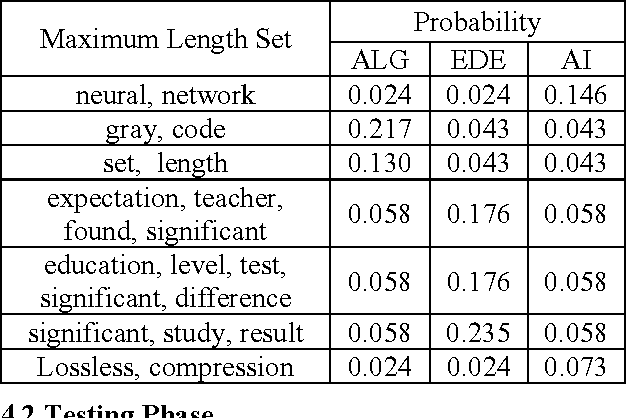
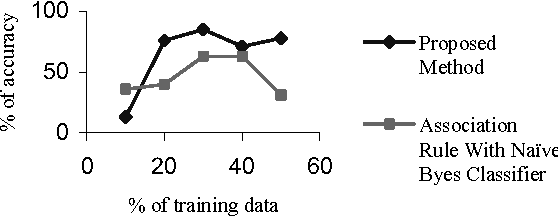
Text classification is the process of classifying documents into predefined categories based on their content. Existing supervised learning algorithms to automatically classify text need sufficient documents to learn accurately. This paper presents a new algorithm for text classification that requires fewer documents for training. Instead of using words, word relation i.e association rules from these words is used to derive feature set from preclassified text documents. The concept of Naive Bayes classifier is then used on derived features and finally only a single concept of Genetic Algorithm has been added for final classification. Experimental results show that the classifier build this way is more accurate than the existing text classification systems.
* 4 pages, International Conference
Medical diagnosis using neural network
Sep 23, 2010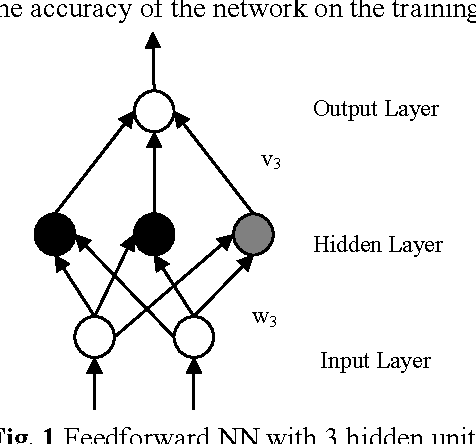
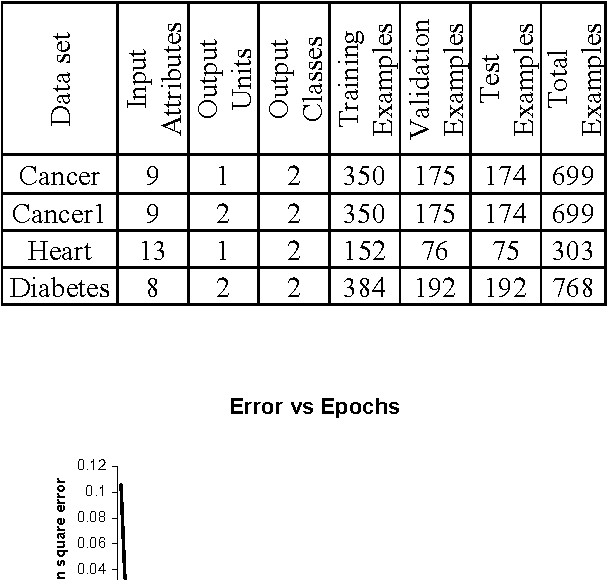
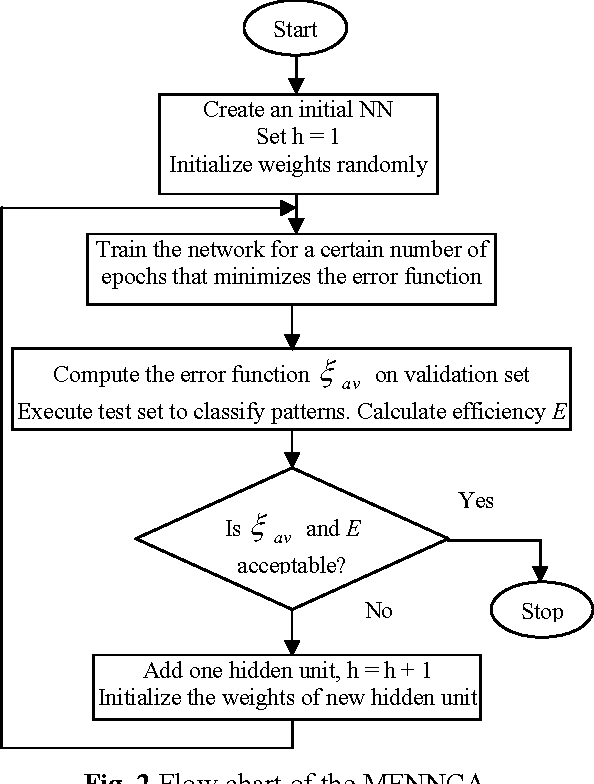
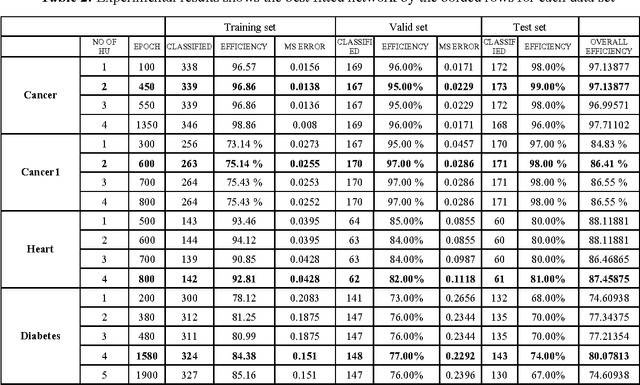
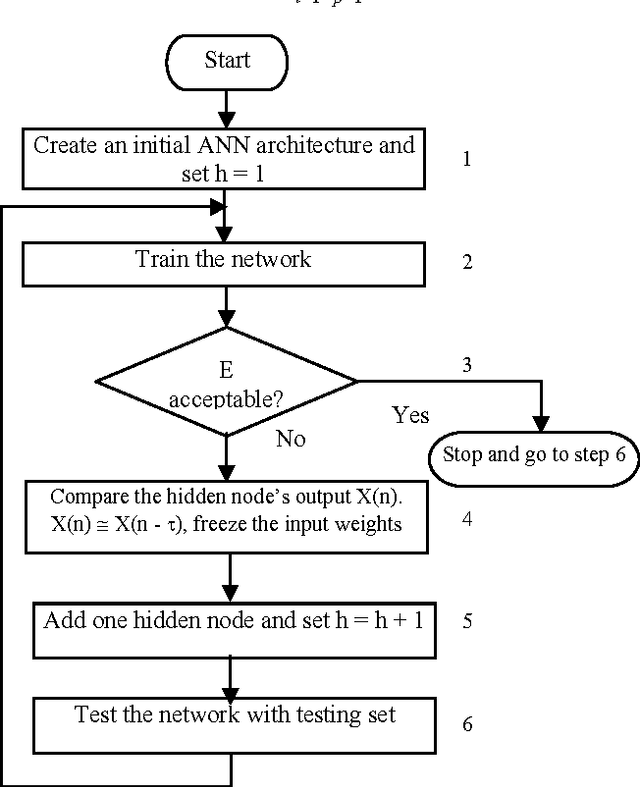
This research is to search for alternatives to the resolution of complex medical diagnosis where human knowledge should be apprehended in a general fashion. Successful application examples show that human diagnostic capabilities are significantly worse than the neural diagnostic system. This paper describes a modified feedforward neural network constructive algorithm (MFNNCA), a new algorithm for medical diagnosis. The new constructive algorithm with backpropagation; offer an approach for the incremental construction of near-minimal neural network architectures for pattern classification. The algorithm starts with minimal number of hidden units in the single hidden layer; additional units are added to the hidden layer one at a time to improve the accuracy of the network and to get an optimal size of a neural network. The MFNNCA was tested on several benchmarking classification problems including the cancer, heart disease and diabetes. Experimental results show that the MFNNCA can produce optimal neural network architecture with good generalization ability.
* 4 pages, International Conference
Extraction of Symbolic Rules from Artificial Neural Networks
Sep 23, 2010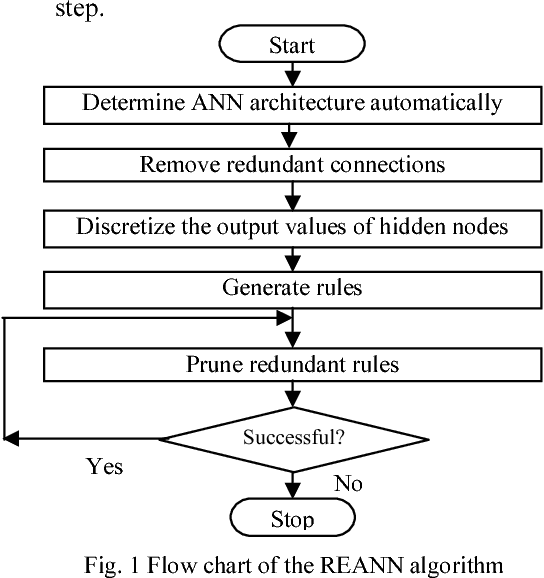
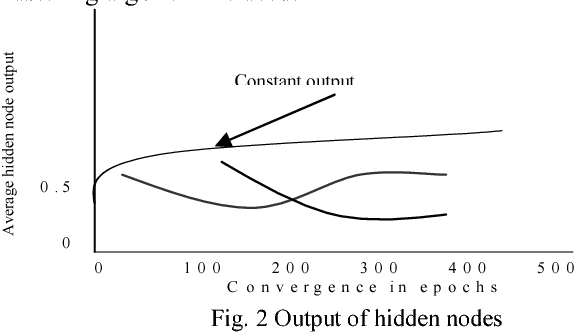
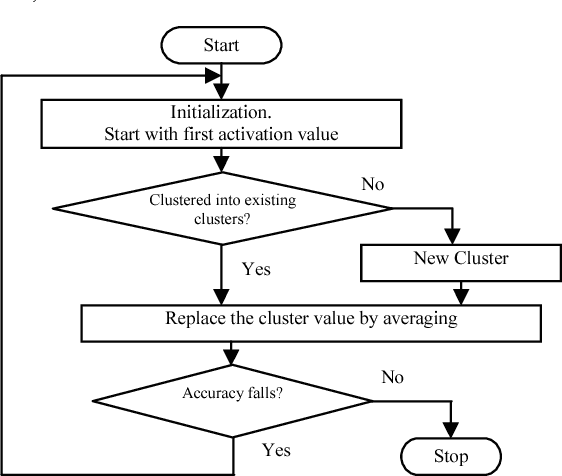
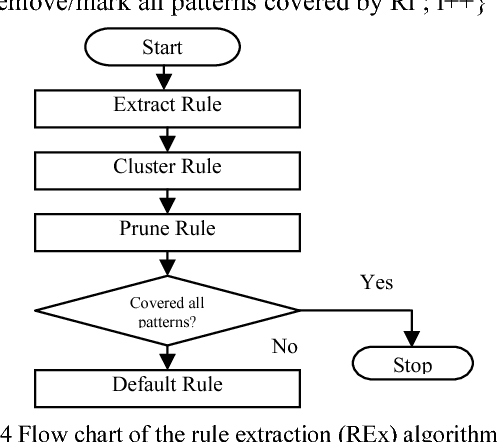
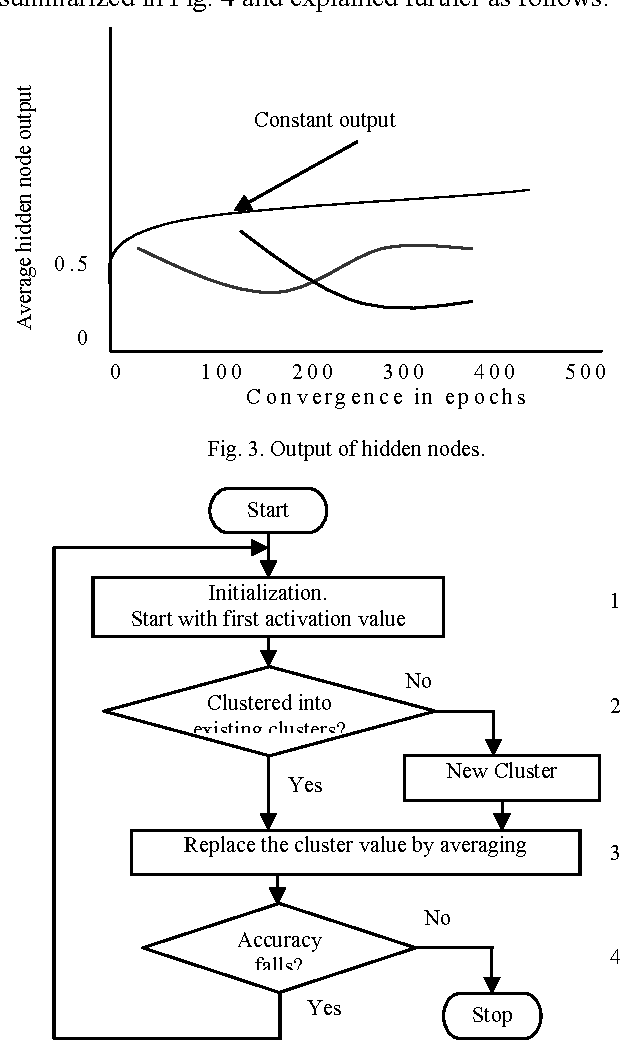
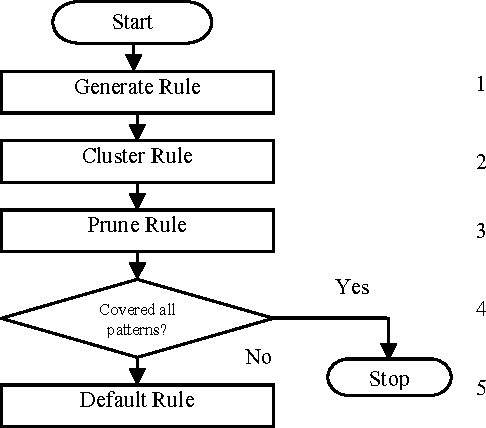
Although backpropagation ANNs generally predict better than decision trees do for pattern classification problems, they are often regarded as black boxes, i.e., their predictions cannot be explained as those of decision trees. In many applications, it is desirable to extract knowledge from trained ANNs for the users to gain a better understanding of how the networks solve the problems. A new rule extraction algorithm, called rule extraction from artificial neural networks (REANN) is proposed and implemented to extract symbolic rules from ANNs. A standard three-layer feedforward ANN is the basis of the algorithm. A four-phase training algorithm is proposed for backpropagation learning. Explicitness of the extracted rules is supported by comparing them to the symbolic rules generated by other methods. Extracted rules are comparable with other methods in terms of number of rules, average number of conditions for a rule, and predictive accuracy. Extensive experimental studies on several benchmarks classification problems, such as breast cancer, iris, diabetes, and season classification problems, demonstrate the effectiveness of the proposed approach with good generalization ability.
* 7 Pages, WASET Transactions
An Algorithm to Extract Rules from Artificial Neural Networks for Medical Diagnosis Problems
Sep 23, 2010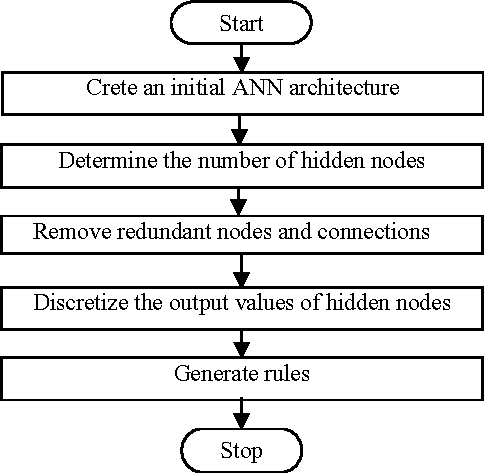
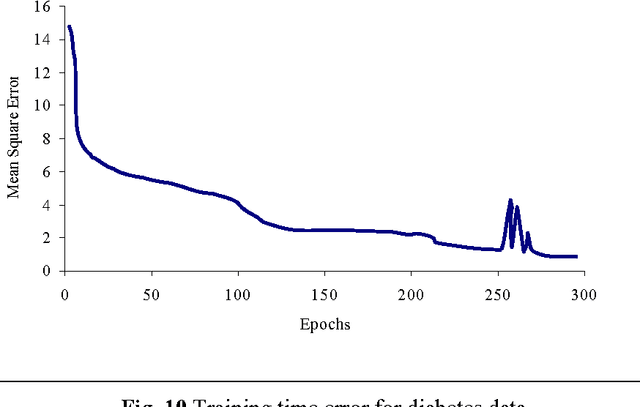
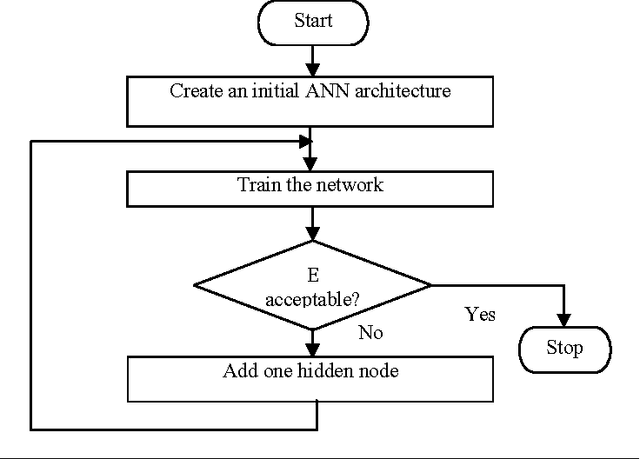
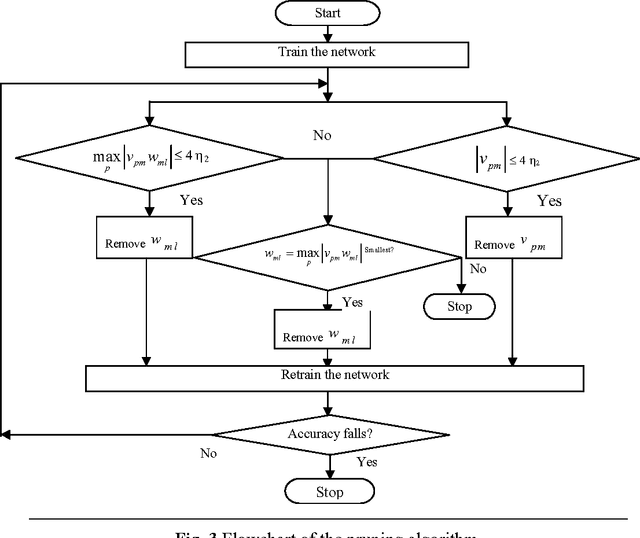
Artificial neural networks (ANNs) have been successfully applied to solve a variety of classification and function approximation problems. Although ANNs can generally predict better than decision trees for pattern classification problems, ANNs are often regarded as black boxes since their predictions cannot be explained clearly like those of decision trees. This paper presents a new algorithm, called rule extraction from ANNs (REANN), to extract rules from trained ANNs for medical diagnosis problems. A standard three-layer feedforward ANN with four-phase training is the basis of the proposed algorithm. In the first phase, the number of hidden nodes in ANNs is determined automatically by a constructive algorithm. In the second phase, irrelevant connections and input nodes are removed from trained ANNs without sacrificing the predictive accuracy of ANNs. The continuous activation values of the hidden nodes are discretized by using an efficient heuristic clustering algorithm in the third phase. Finally, rules are extracted from compact ANNs by examining the discretized activation values of the hidden nodes. Extensive experimental studies on three benchmark classification problems, i.e. breast cancer, diabetes and lenses, demonstrate that REANN can generate high quality rules from ANNs, which are comparable with other methods in terms of number of rules, average number of conditions for a rule, and predictive accuracy.
* 19 Pages, Internatiomal Journal
A Constructive Algorithm for Feedforward Neural Networks for Medical Diagnostic Reasoning
Sep 23, 2010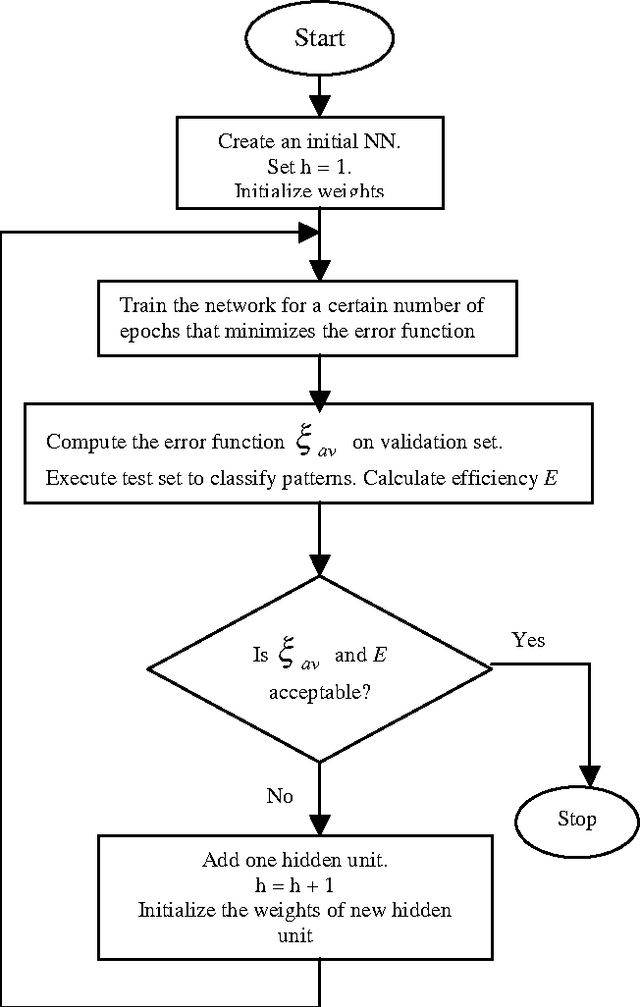
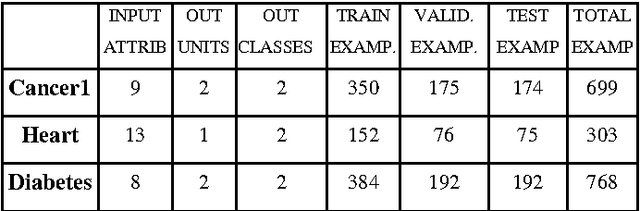
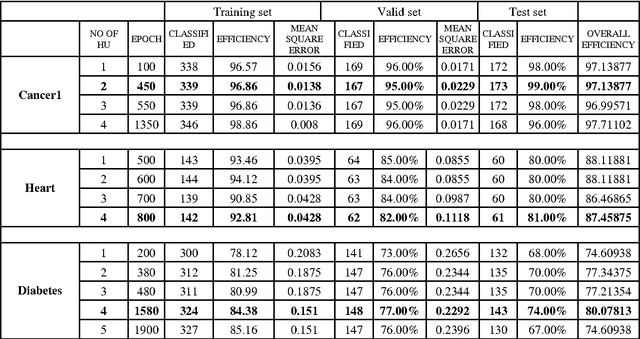
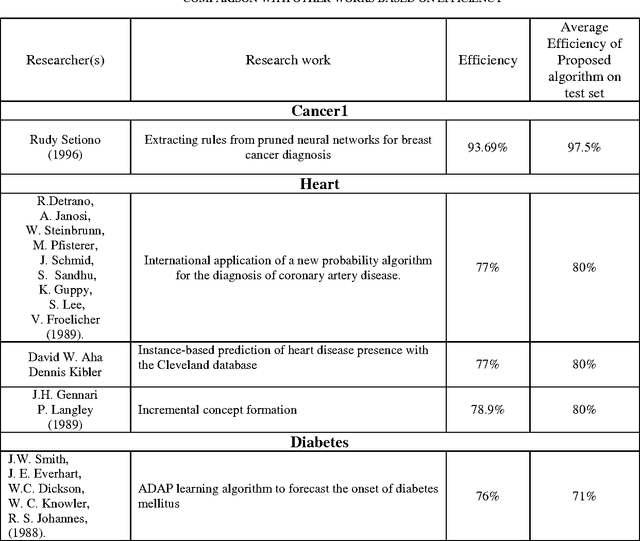
This research is to search for alternatives to the resolution of complex medical diagnosis where human knowledge should be apprehended in a general fashion. Successful application examples show that human diagnostic capabilities are significantly worse than the neural diagnostic system. Our research describes a constructive neural network algorithm with backpropagation; offer an approach for the incremental construction of nearminimal neural network architectures for pattern classification. The algorithm starts with minimal number of hidden units in the single hidden layer; additional units are added to the hidden layer one at a time to improve the accuracy of the network and to get an optimal size of a neural network. Our algorithm was tested on several benchmarking classification problems including Cancer1, Heart, and Diabetes with good generalization ability.
* 4 Pages, International Symposium