 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Cross-Modal Interactions in Multimodal Glioma Survival Prediction via InterSHAP: Evidence for Additive Signal Integration
Mar 31, 2026Multimodal deep learning for cancer prognosis is commonly assumed to benefit from synergistic cross-modal interactions, yet this assumption has not been directly tested in survival prediction settings. This work adapts InterSHAP, a Shapley interaction index-based metric, from classification to Cox proportional hazards models and applies it to quantify cross-modal interactions in glioma survival prediction. Using TCGA-GBM and TCGA-LGG data (n=575), we evaluate four fusion architectures combining whole-slide image (WSI) and RNA-seq features. Our central finding is an inverse relationship between predictive performance and measured interaction: architectures achieving superior discrimination (C-index 0.64$\to$0.82) exhibit equivalent or lower cross-modal interaction (4.8\%$\to$3.0\%). Variance decomposition reveals stable additive contributions across all architectures (WSI${\approx}$40\%, RNA${\approx}$55\%, Interaction${\approx}$4\%), indicating that performance gains arise from complementary signal aggregation rather than learned synergy. These findings provide a practical model auditing tool for comparing fusion strategies, reframe the role of architectural complexity in multimodal fusion, and have implications for privacy-preserving federated deployment.
Early Stopping Criteria for Training Generative Adversarial Networks in Biomedical Imaging
May 31, 2024Generative Adversarial Networks (GANs) have high computational costs to train their complex architectures. Throughout the training process, GANs' output is analyzed qualitatively based on the loss and synthetic images' diversity and quality. Based on this qualitative analysis, training is manually halted once the desired synthetic images are generated. By utilizing an early stopping criterion, the computational cost and dependence on manual oversight can be reduced yet impacted by training problems such as mode collapse, non-convergence, and instability. This is particularly prevalent in biomedical imagery, where training problems degrade the diversity and quality of synthetic images, and the high computational cost associated with training makes complex architectures increasingly inaccessible. This work proposes a novel early stopping criteria to quantitatively detect training problems, halt training, and reduce the computational costs associated with synthesizing biomedical images. Firstly, the range of generator and discriminator loss values is investigated to assess whether mode collapse, non-convergence, and instability occur sequentially, concurrently, or interchangeably throughout the training of GANs. Secondly, utilizing these occurrences in conjunction with the Mean Structural Similarity Index (MS-SSIM) and Fr\'echet Inception Distance (FID) scores of synthetic images forms the basis of the proposed early stopping criteria. This work helps identify the occurrence of training problems in GANs using low-resource computational cost and reduces training time to generate diversified and high-quality synthetic images.
InceptionCaps: A Performant Glaucoma Classification Model for Data-scarce Environment
Nov 24, 2023Glaucoma is an irreversible ocular disease and is the second leading cause of visual disability worldwide. Slow vision loss and the asymptomatic nature of the disease make its diagnosis challenging. Early detection is crucial for preventing irreversible blindness. Ophthalmologists primarily use retinal fundus images as a non-invasive screening method. Convolutional neural networks (CNN) have demonstrated high accuracy in the classification of medical images. Nevertheless, CNN's translation-invariant nature and inability to handle the part-whole relationship between objects make its direct application unsuitable for glaucomatous fundus image classification, as it requires a large number of labelled images for training. This work reviews existing state of the art models and proposes InceptionCaps, a novel capsule network (CapsNet) based deep learning model having pre-trained InceptionV3 as its convolution base, for automatic glaucoma classification. InceptionCaps achieved an accuracy of 0.956, specificity of 0.96, and AUC of 0.9556, which surpasses several state-of-the-art deep learning model performances on the RIM-ONE v2 dataset. The obtained result demonstrates the robustness of the proposed deep learning model.
Adaptive Input-image Normalization for Solving Mode Collapse Problem in GAN-based X-ray Images
Sep 21, 2023Biomedical image datasets can be imbalanced due to the rarity of targeted diseases. Generative Adversarial Networks play a key role in addressing this imbalance by enabling the generation of synthetic images to augment datasets. It is important to generate synthetic images that incorporate a diverse range of features to accurately represent the distribution of features present in the training imagery. Furthermore, the absence of diverse features in synthetic images can degrade the performance of machine learning classifiers. The mode collapse problem impacts Generative Adversarial Networks' capacity to generate diversified images. Mode collapse comes in two varieties: intra-class and inter-class. In this paper, both varieties of the mode collapse problem are investigated, and their subsequent impact on the diversity of synthetic X-ray images is evaluated. This work contributes an empirical demonstration of the benefits of integrating the adaptive input-image normalization with the Deep Convolutional GAN and Auxiliary Classifier GAN to alleviate the mode collapse problems. Synthetically generated images are utilized for data augmentation and training a Vision Transformer model. The classification performance of the model is evaluated using accuracy, recall, and precision scores. Results demonstrate that the DCGAN and the ACGAN with adaptive input-image normalization outperform the DCGAN and ACGAN with un-normalized X-ray images as evidenced by the superior diversity scores and classification scores.
Assessing Intra-class Diversity and Quality of Synthetically Generated Images in a Biomedical and Non-biomedical Setting
Jul 23, 2023In biomedical image analysis, data imbalance is common across several imaging modalities. Data augmentation is one of the key solutions in addressing this limitation. Generative Adversarial Networks (GANs) are increasingly being relied upon for data augmentation tasks. Biomedical image features are sensitive to evaluating the efficacy of synthetic images. These features can have a significant impact on metric scores when evaluating synthetic images across different biomedical imaging modalities. Synthetically generated images can be evaluated by comparing the diversity and quality of real images. Multi-scale Structural Similarity Index Measure and Cosine Distance are used to evaluate intra-class diversity, while Frechet Inception Distance is used to evaluate the quality of synthetic images. Assessing these metrics for biomedical and non-biomedical imaging is important to investigate an informed strategy in evaluating the diversity and quality of synthetic images. In this work, an empirical assessment of these metrics is conducted for the Deep Convolutional GAN in a biomedical and non-biomedical setting. The diversity and quality of synthetic images are evaluated using different sample sizes. This research intends to investigate the variance in diversity and quality across biomedical and non-biomedical imaging modalities. Results demonstrate that the metrics scores for diversity and quality vary significantly across biomedical-to-biomedical and biomedical-to-non-biomedical imaging modalities.
A Self-attention Guided Multi-scale Gradient GAN for Diversified X-ray Image Synthesis
Oct 09, 2022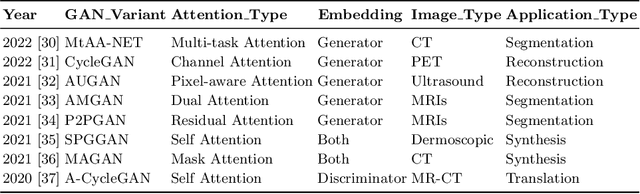
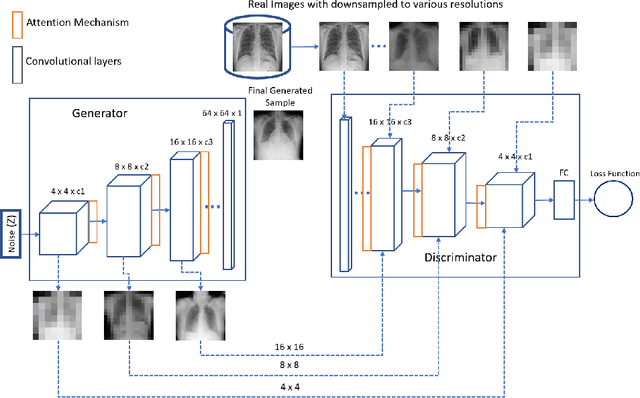
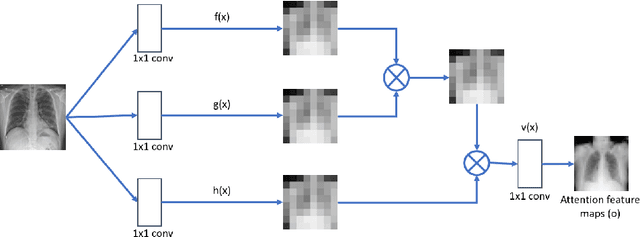
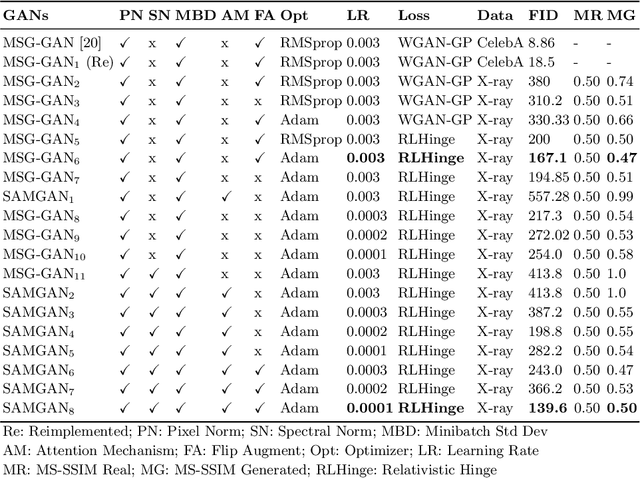
Imbalanced image datasets are commonly available in the domain of biomedical image analysis. Biomedical images contain diversified features that are significant in predicting targeted diseases. Generative Adversarial Networks (GANs) are utilized to address the data limitation problem via the generation of synthetic images. Training challenges such as mode collapse, non-convergence, and instability degrade a GAN's performance in synthesizing diversified and high-quality images. In this work, SAMGAN, an attention-guided multi-scale gradient GAN architecture is proposed to model the relationship between long-range dependencies of biomedical image features and improves the training performance using a flow of multi-scale gradients at multiple resolutions in the layers of generator and discriminator models. The intent is to reduce the impact of mode collapse and stabilize the training of GAN using an attention mechanism with multi-scale gradient learning for diversified X-ray image synthesis. Multi-scale Structural Similarity Index Measure (MS-SSIM) and Frechet Inception Distance (FID) are used to identify the occurrence of mode collapse and evaluate the diversity of synthetic images generated. The proposed architecture is compared with the multi-scale gradient GAN (MSG-GAN) to assess the diversity of generated synthetic images. Results indicate that the SAMGAN outperforms MSG-GAN in synthesizing diversified images as evidenced by the MS-SSIM and FID scores.
Evaluating Generatively Synthesized Diabetic Retinopathy Imagery
Aug 10, 2022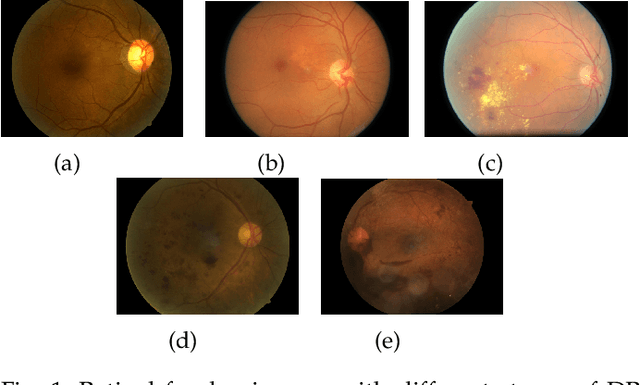
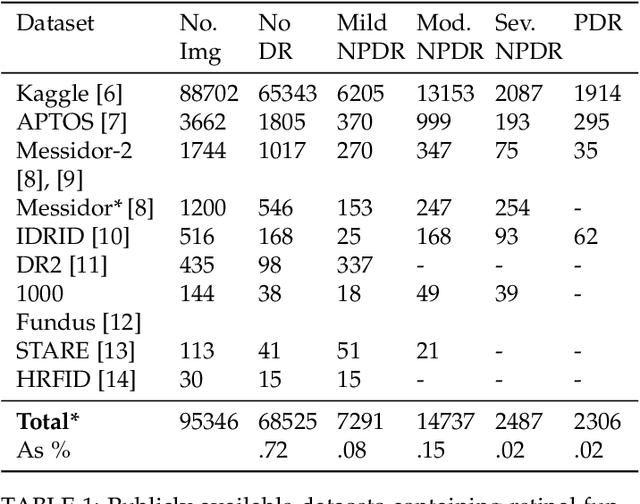
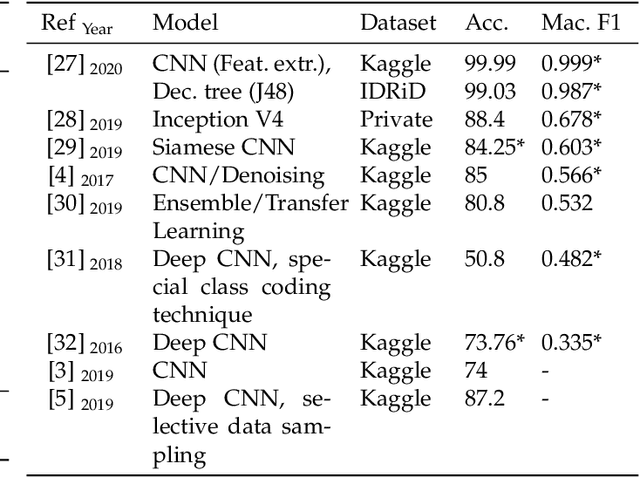
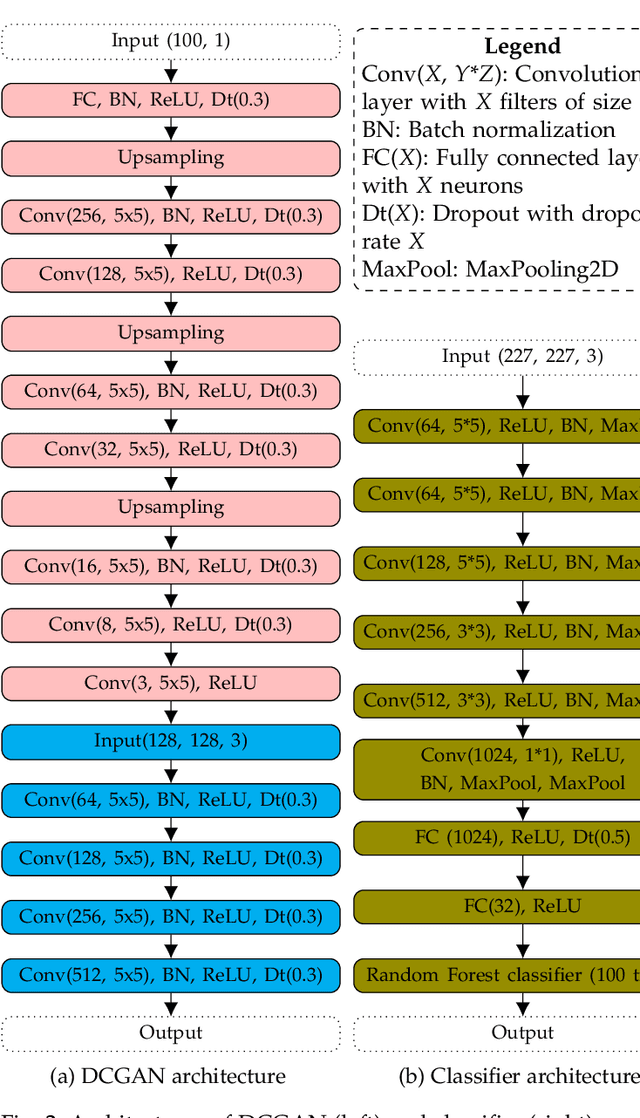
Publicly available data for the training of diabetic retinopathy classifiers is unbalanced. Generative adversarial networks can successfully synthesize retinal fundus imagery. In order for synthetic imagery to be of benefit, images need to be of high quality and diverse. Presently, several evaluation metrics are used to evaluate the quality and diversity of imagery synthesized from generative adversarial networks. This work contributes, the first of its kind, empirical assessment for the suitability of evaluation metrics used in the literature for the evaluation of generative adversarial networks for generating retinal fundus images in the context of diabetic retinopathy. Frechet Inception Distance, Peak Signal-to-Noise Ratio and Cosine Distance's capacity to assess the quality and diversity of synthetic proliferative diabetic retionpathy imagery is investigated. A quantitative analysis is performed to enable an improved methodology for selecting the synthetic imagery to be used for augmenting a classifier's training dataset. Results indicate that Frechet Inception Distance is suitable for evaluating the diversity of synthetic imagery, and for identifying if the imagery has features corresponding to its class label. Peak Signal-to-Noise Ratio is suitable for indicating if the synthetic imagery has valid diabetic retinopathy lesions and if its features correspond to its class label. These results demonstrate the importance of performing such empirical evaluation, especially in the context of biomedical domains where utilisation in applied setting is intended.
Variance in Classifying Affective State via Electrocardiogram and Photoplethysmography
Jul 06, 2022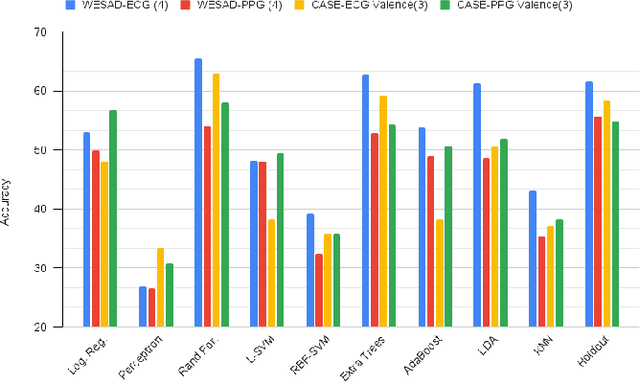
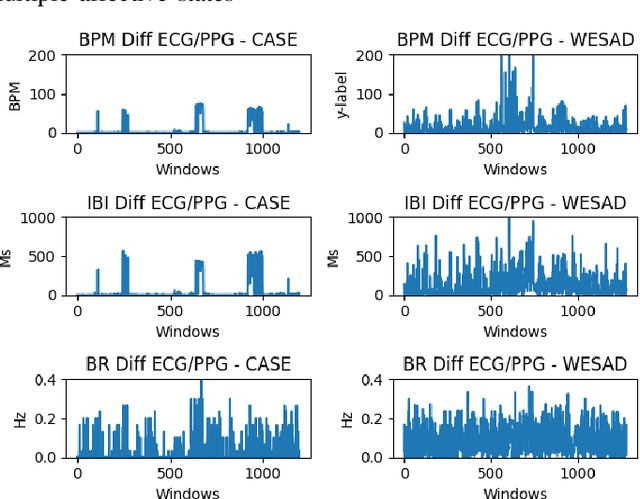
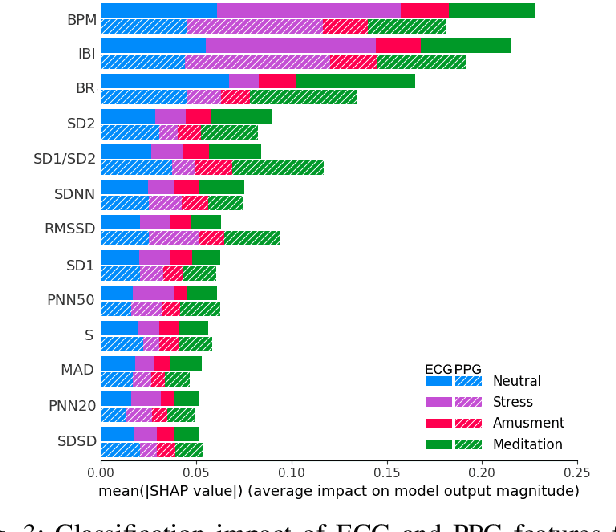
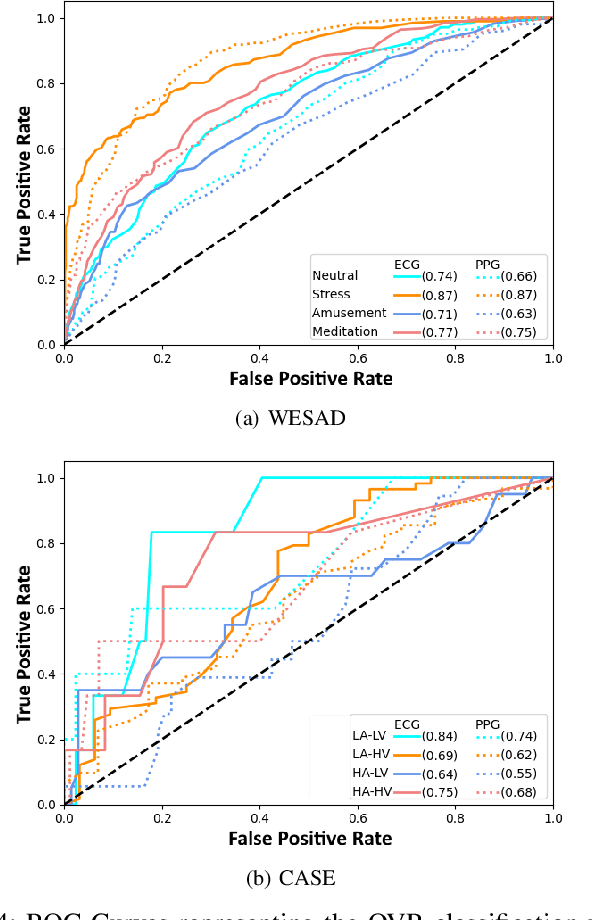
Advances in wearable technology have significantly increased the sensitivity and accuracy of devices for recording physiological signals. Commercial off-the-shelf wearable devices can gather large quantities of physiological data un-obtrusively. This enables momentary assessments of human physiology, which provide valuable insights into an individual's health and psychological state. Leveraging these insights provides significant benefits for human-to-computer interaction and personalised healthcare. This work contributes an analysis of variance occurring in features representative of affective states extracted from electrocardiograms and photoplethysmography; subsequently identifies the cardiac measures most descriptive of affective states from both signals and provides insights into signal and emotion-specific cardiac measures; finally baseline performance for automated affective state detection from physiological signals is established.
Addressing the Intra-class Mode Collapse Problem using Adaptive Input Image Normalization in GAN-based X-ray Images
Jan 25, 2022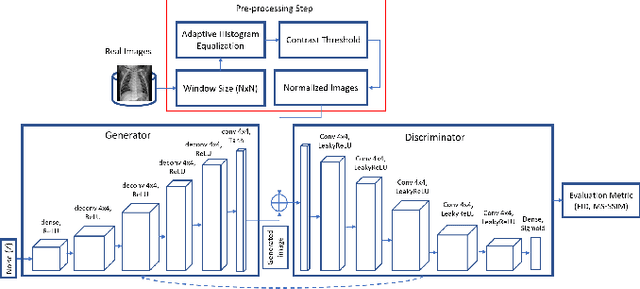
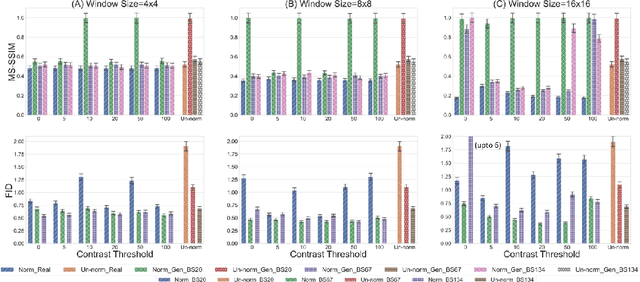
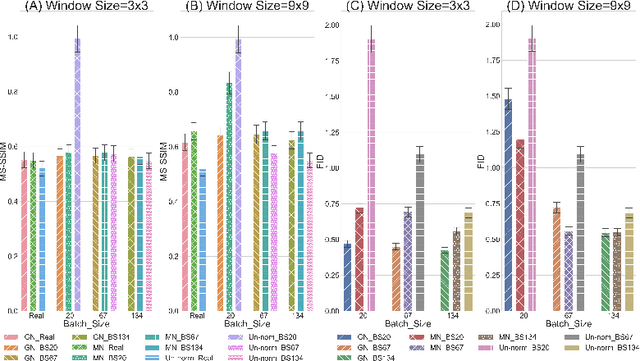
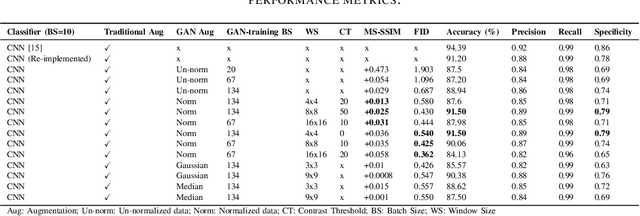
Biomedical image datasets can be imbalanced due to the rarity of targeted diseases. Generative Adversarial Networks play a key role in addressing this imbalance by enabling the generation of synthetic images to augment and balance datasets. It is important to generate synthetic images that incorporate a diverse range of features such that they accurately represent the distribution of features present in the training imagery. Furthermore, the absence of diverse features in synthetic images can degrade the performance of machine learning classifiers. The mode collapse problem can impact a Generative Adversarial Network's capacity to generate diversified images. The mode collapse comes in two varieties; intra-class and inter-class. In this paper, the intra-class mode collapse problem is investigated, and its subsequent impact on the diversity of synthetic X-ray images is evaluated. This work contributes an empirical demonstration of the benefits of integrating the adaptive input-image normalization for the Deep Convolutional GAN to alleviate the intra-class mode collapse problem. Results demonstrate that the DCGAN with adaptive input-image normalization outperforms DCGAN with un-normalized X-ray images as evident by the superior diversity scores.
A Survey on Training Challenges in Generative Adversarial Networks for Biomedical Image Analysis
Jan 19, 2022In biomedical image analysis, the applicability of deep learning methods is directly impacted by the quantity of image data available. This is due to deep learning models requiring large image datasets to provide high-level performance. Generative Adversarial Networks (GANs) have been widely utilized to address data limitations through the generation of synthetic biomedical images. GANs consist of two models. The generator, a model that learns how to produce synthetic images based on the feedback it receives. The discriminator, a model that classifies an image as synthetic or real and provides feedback to the generator. Throughout the training process, a GAN can experience several technical challenges that impede the generation of suitable synthetic imagery. First, the mode collapse problem whereby the generator either produces an identical image or produces a uniform image from distinct input features. Second, the non-convergence problem whereby the gradient descent optimizer fails to reach a Nash equilibrium. Thirdly, the vanishing gradient problem whereby unstable training behavior occurs due to the discriminator achieving optimal classification performance resulting in no meaningful feedback being provided to the generator. These problems result in the production of synthetic imagery that is blurry, unrealistic, and less diverse. To date, there has been no survey article outlining the impact of these technical challenges in the context of the biomedical imagery domain. This work presents a review and taxonomy based on solutions to the training problems of GANs in the biomedical imaging domain. This survey highlights important challenges and outlines future research directions about the training of GANs in the domain of biomedical imagery.