 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRonan Collobert
Phrase-based Image Captioning
Apr 09, 2015
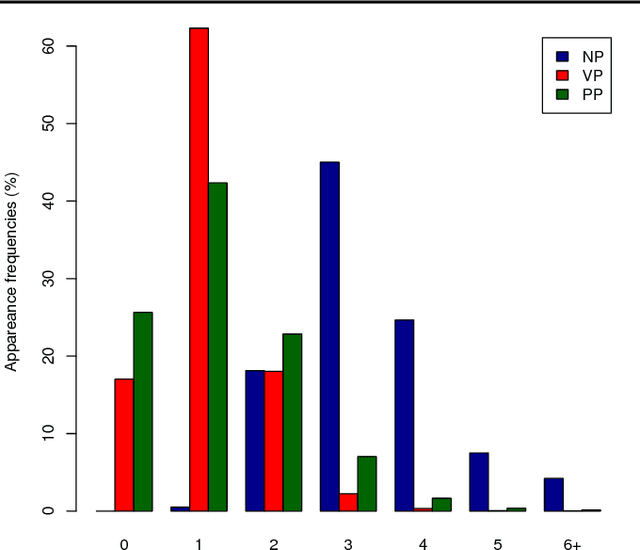
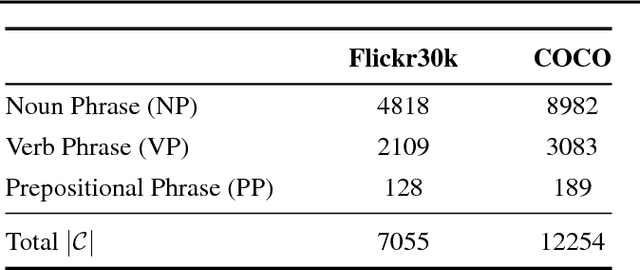
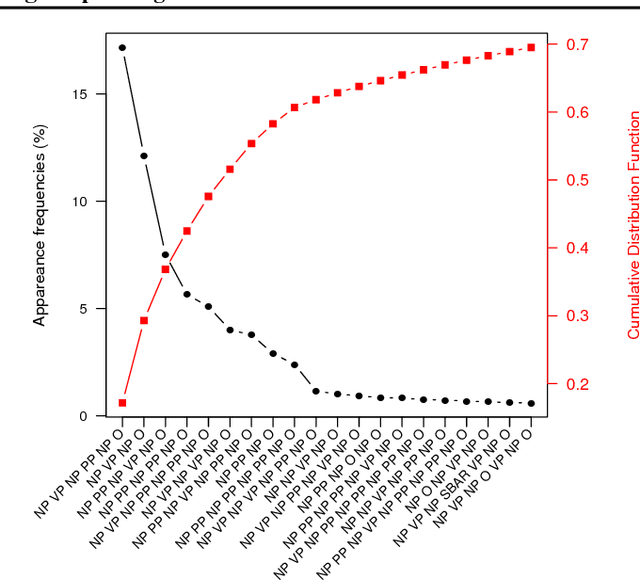
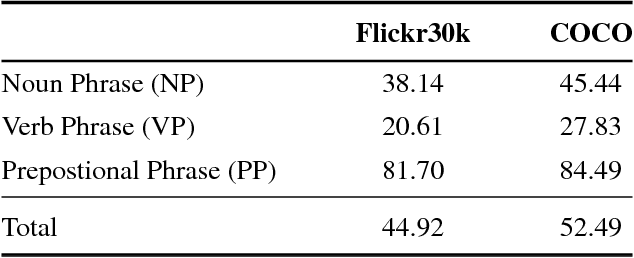
Generating a novel textual description of an image is an interesting problem that connects computer vision and natural language processing. In this paper, we present a simple model that is able to generate descriptive sentences given a sample image. This model has a strong focus on the syntax of the descriptions. We train a purely bilinear model that learns a metric between an image representation (generated from a previously trained Convolutional Neural Network) and phrases that are used to described them. The system is then able to infer phrases from a given image sample. Based on caption syntax statistics, we propose a simple language model that can produce relevant descriptions for a given test image using the phrases inferred. Our approach, which is considerably simpler than state-of-the-art models, achieves comparable results in two popular datasets for the task: Flickr30k and the recently proposed Microsoft COCO.
Rehabilitation of Count-based Models for Word Vector Representations
Apr 08, 2015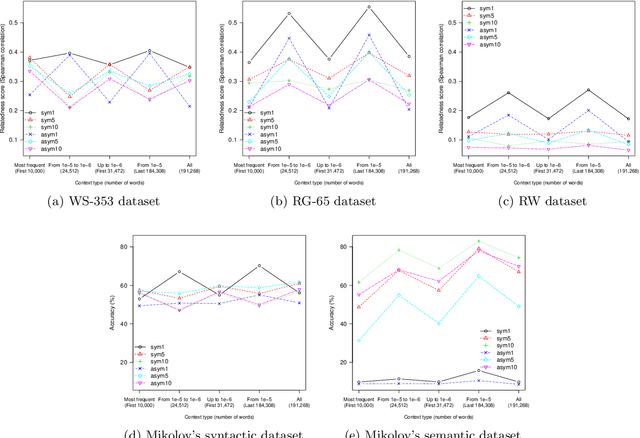
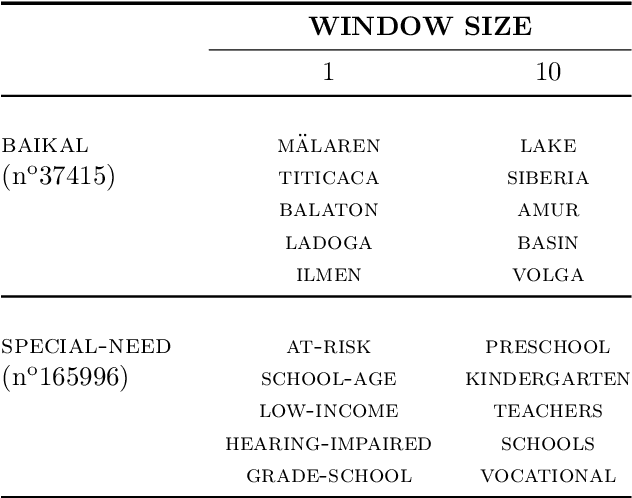
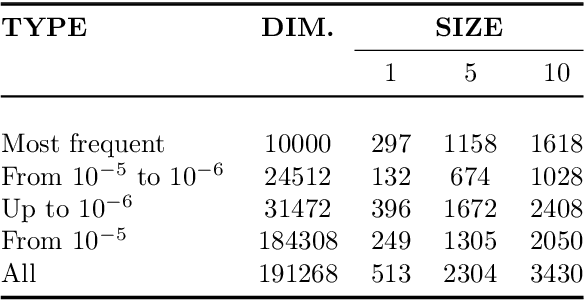
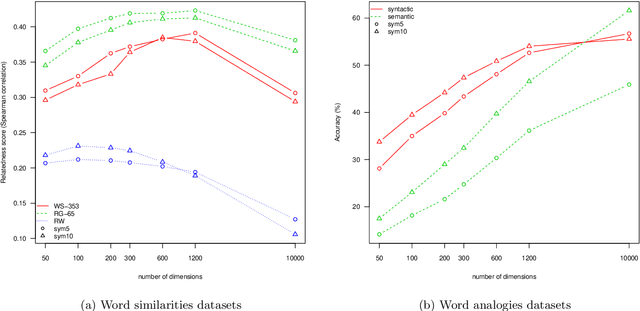
Recent works on word representations mostly rely on predictive models. Distributed word representations (aka word embeddings) are trained to optimally predict the contexts in which the corresponding words tend to appear. Such models have succeeded in capturing word similarties as well as semantic and syntactic regularities. Instead, we aim at reviving interest in a model based on counts. We present a systematic study of the use of the Hellinger distance to extract semantic representations from the word co-occurence statistics of large text corpora. We show that this distance gives good performance on word similarity and analogy tasks, with a proper type and size of context, and a dimensionality reduction based on a stochastic low-rank approximation. Besides being both simple and intuitive, this method also provides an encoding function which can be used to infer unseen words or phrases. This becomes a clear advantage compared to predictive models which must train these new words.
* A. Gelbukh (Ed.), Springer International Publishing Switzerland
End-to-end Phoneme Sequence Recognition using Convolutional Neural Networks
Dec 07, 2013



Most phoneme recognition state-of-the-art systems rely on a classical neural network classifiers, fed with highly tuned features, such as MFCC or PLP features. Recent advances in ``deep learning'' approaches questioned such systems, but while some attempts were made with simpler features such as spectrograms, state-of-the-art systems still rely on MFCCs. This might be viewed as a kind of failure from deep learning approaches, which are often claimed to have the ability to train with raw signals, alleviating the need of hand-crafted features. In this paper, we investigate a convolutional neural network approach for raw speech signals. While convolutional architectures got tremendous success in computer vision or text processing, they seem to have been let down in the past recent years in the speech processing field. We show that it is possible to learn an end-to-end phoneme sequence classifier system directly from raw signal, with similar performance on the TIMIT and WSJ datasets than existing systems based on MFCC, questioning the need of complex hand-crafted features on large datasets.
Recurrent Convolutional Neural Networks for Scene Parsing
Jun 12, 2013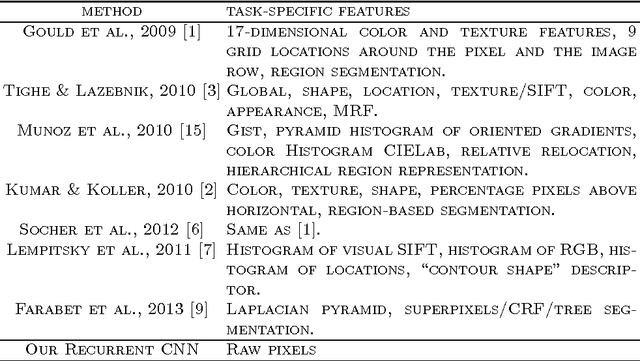
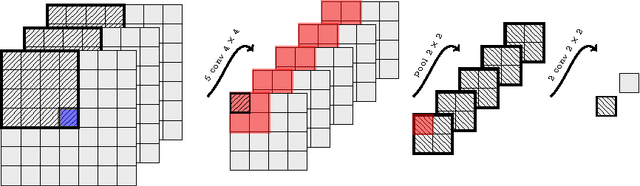

Scene parsing is a technique that consist on giving a label to all pixels in an image according to the class they belong to. To ensure a good visual coherence and a high class accuracy, it is essential for a scene parser to capture image long range dependencies. In a feed-forward architecture, this can be simply achieved by considering a sufficiently large input context patch, around each pixel to be labeled. We propose an approach consisting of a recurrent convolutional neural network which allows us to consider a large input context, while limiting the capacity of the model. Contrary to most standard approaches, our method does not rely on any segmentation methods, nor any task-specific features. The system is trained in an end-to-end manner over raw pixels, and models complex spatial dependencies with low inference cost. As the context size increases with the built-in recurrence, the system identifies and corrects its own errors. Our approach yields state-of-the-art performance on both the Stanford Background Dataset and the SIFT Flow Dataset, while remaining very fast at test time.
Estimating Phoneme Class Conditional Probabilities from Raw Speech Signal using Convolutional Neural Networks
Jun 12, 2013

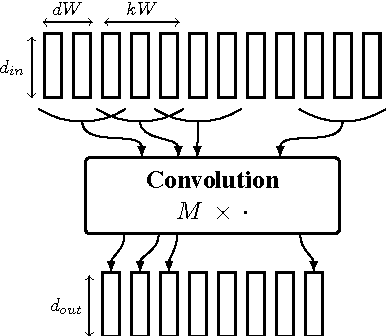
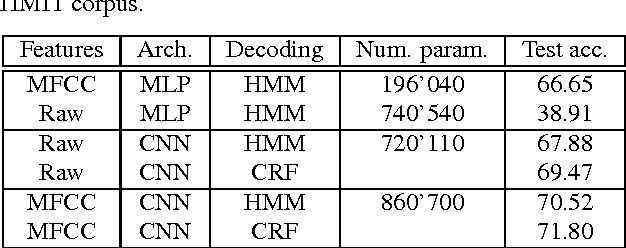
In hybrid hidden Markov model/artificial neural networks (HMM/ANN) automatic speech recognition (ASR) system, the phoneme class conditional probabilities are estimated by first extracting acoustic features from the speech signal based on prior knowledge such as, speech perception or/and speech production knowledge, and, then modeling the acoustic features with an ANN. Recent advances in machine learning techniques, more specifically in the field of image processing and text processing, have shown that such divide and conquer strategy (i.e., separating feature extraction and modeling steps) may not be necessary. Motivated from these studies, in the framework of convolutional neural networks (CNNs), this paper investigates a novel approach, where the input to the ANN is raw speech signal and the output is phoneme class conditional probability estimates. On TIMIT phoneme recognition task, we study different ANN architectures to show the benefit of CNNs and compare the proposed approach against conventional approach where, spectral-based feature MFCC is extracted and modeled by a multilayer perceptron. Our studies show that the proposed approach can yield comparable or better phoneme recognition performance when compared to the conventional approach. It indicates that CNNs can learn features relevant for phoneme classification automatically from the raw speech signal.
Natural Language Processing (almost) from Scratch
Mar 02, 2011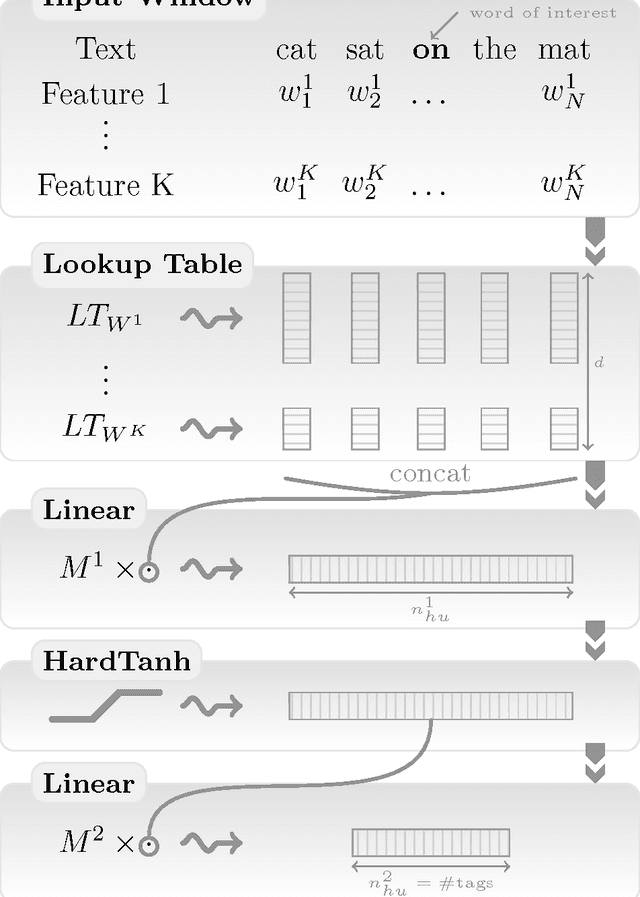

We propose a unified neural network architecture and learning algorithm that can be applied to various natural language processing tasks including: part-of-speech tagging, chunking, named entity recognition, and semantic role labeling. This versatility is achieved by trying to avoid task-specific engineering and therefore disregarding a lot of prior knowledge. Instead of exploiting man-made input features carefully optimized for each task, our system learns internal representations on the basis of vast amounts of mostly unlabeled training data. This work is then used as a basis for building a freely available tagging system with good performance and minimal computational requirements.