 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Speech Recognition with Time-Depth Separable Convolutions
Apr 04, 2019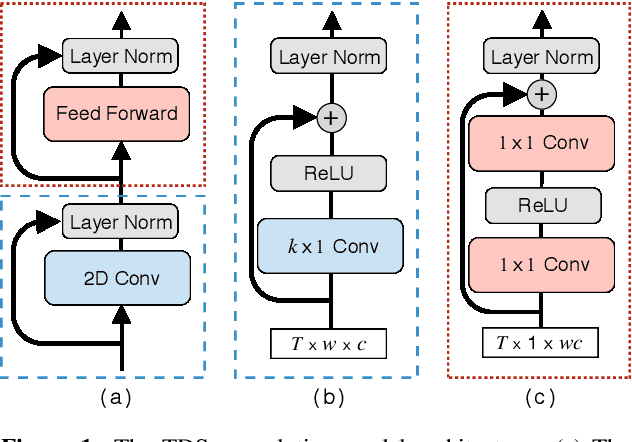
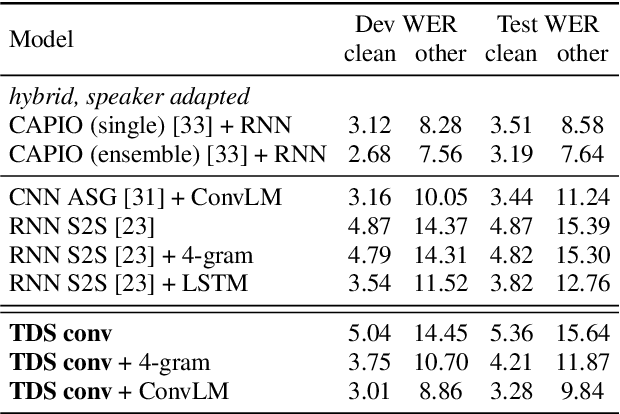
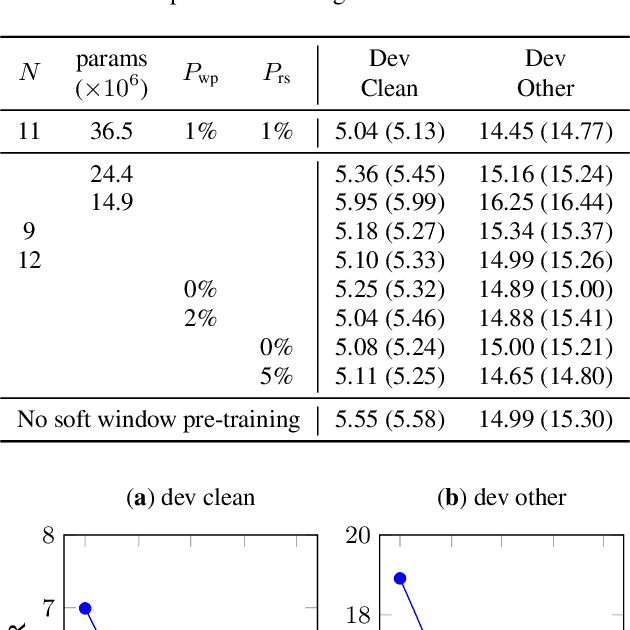
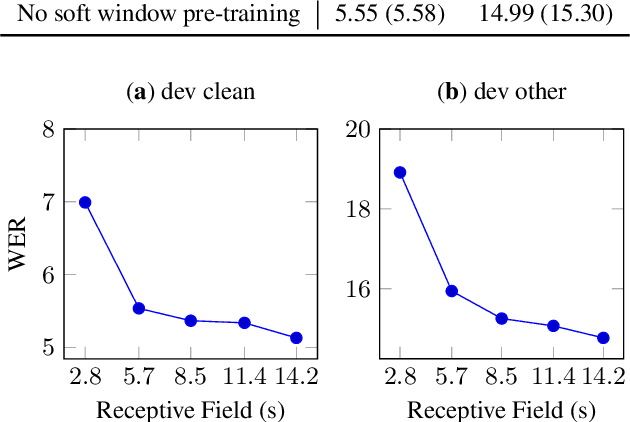
We propose a fully convolutional sequence-to-sequence encoder architecture with a simple and efficient decoder. Our model improves WER on LibriSpeech while being an order of magnitude more efficient than a strong RNN baseline. Key to our approach is a time-depth separable convolution block which dramatically reduces the number of parameters in the model while keeping the receptive field large. We also give a stable and efficient beam search inference procedure which allows us to effectively integrate a language model. Coupled with a convolutional language model, our time-depth separable convolution architecture improves by more than 22% relative WER over the best previously reported sequence-to-sequence results on the noisy LibriSpeech test set.
A Fully Differentiable Beam Search Decoder
Feb 16, 2019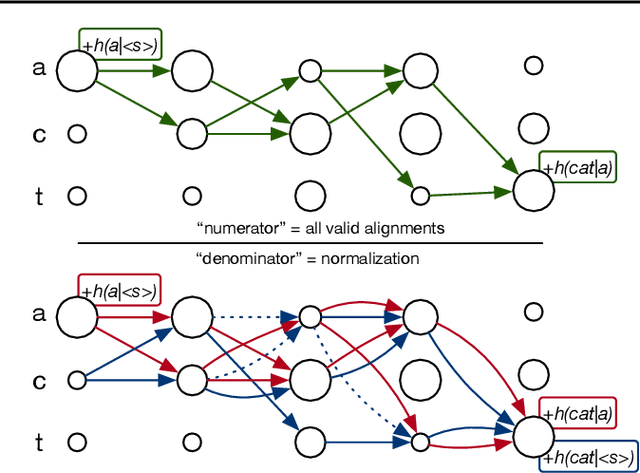
We introduce a new beam search decoder that is fully differentiable, making it possible to optimize at training time through the inference procedure. Our decoder allows us to combine models which operate at different granularities (e.g. acoustic and language models). It can be used when target sequences are not aligned to input sequences by considering all possible alignments between the two. We demonstrate our approach scales by applying it to speech recognition, jointly training acoustic and word-level language models. The system is end-to-end, with gradients flowing through the whole architecture from the word-level transcriptions. Recent research efforts have shown that deep neural networks with attention-based mechanisms are powerful enough to successfully train an acoustic model from the final transcription, while implicitly learning a language model. Instead, we show that it is possible to discriminatively train an acoustic model jointly with an explicit and possibly pre-trained language model.
wav2letter++: The Fastest Open-source Speech Recognition System
Dec 18, 2018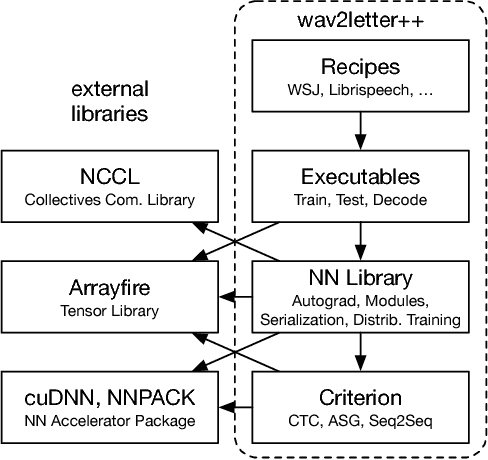
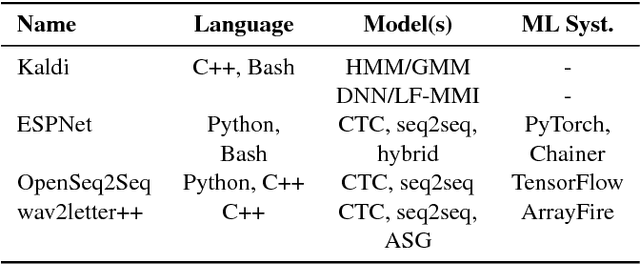

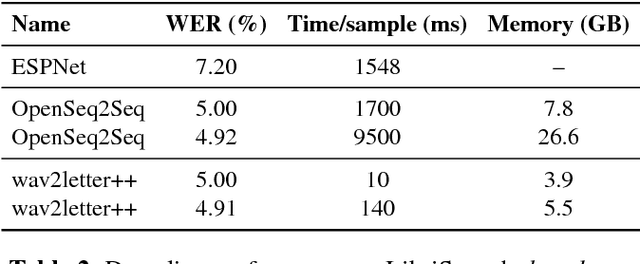
This paper introduces wav2letter++, the fastest open-source deep learning speech recognition framework. wav2letter++ is written entirely in C++, and uses the ArrayFire tensor library for maximum efficiency. Here we explain the architecture and design of the wav2letter++ system and compare it to other major open-source speech recognition systems. In some cases wav2letter++ is more than 2x faster than other optimized frameworks for training end-to-end neural networks for speech recognition. We also show that wav2letter++'s training times scale linearly to 64 GPUs, the highest we tested, for models with 100 million parameters. High-performance frameworks enable fast iteration, which is often a crucial factor in successful research and model tuning on new datasets and tasks.
Fully Convolutional Speech Recognition
Dec 17, 2018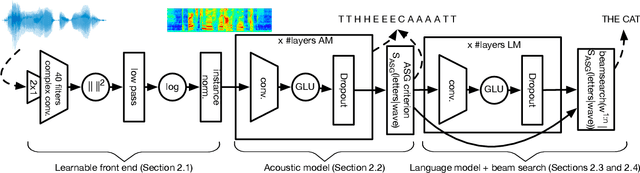

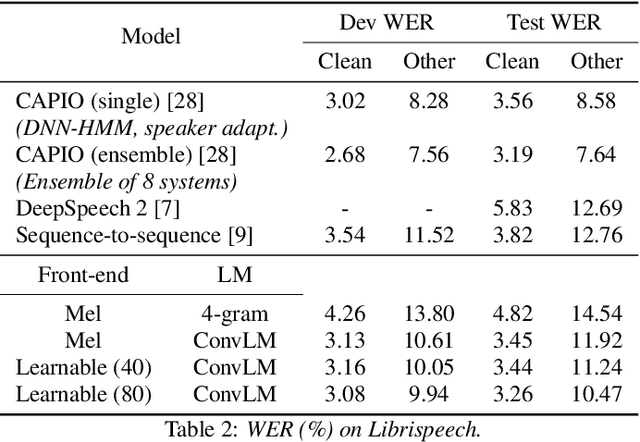
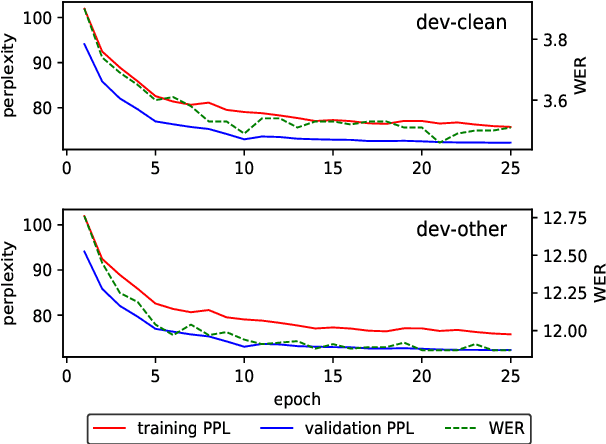
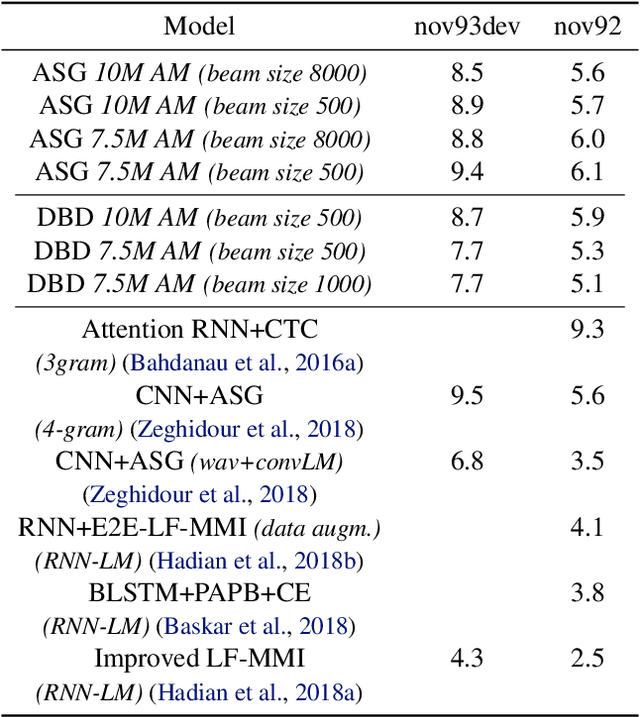
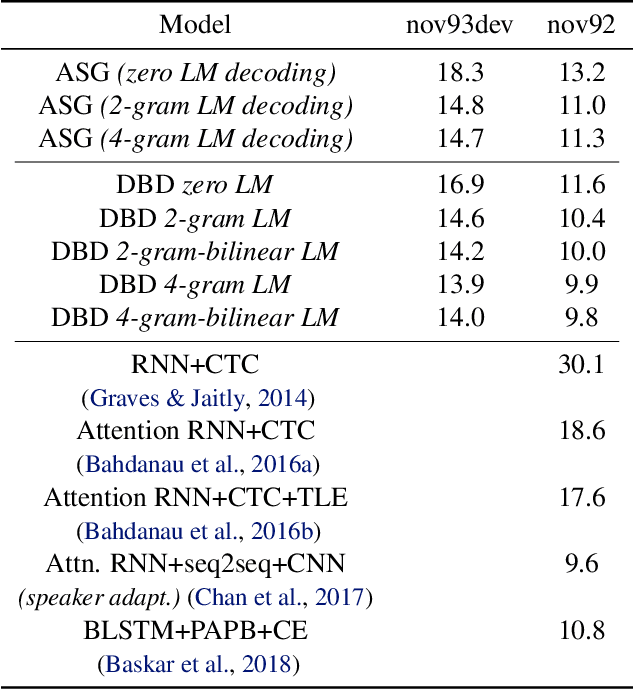
Current state-of-the-art speech recognition systems build on recurrent neural networks for acoustic and/or language modeling, and rely on feature extraction pipelines to extract mel-filterbanks or cepstral coefficients. In this paper we present an alternative approach based solely on convolutional neural networks, leveraging recent advances in acoustic models from the raw waveform and language modeling. This fully convolutional approach is trained end-to-end to predict characters from the raw waveform, removing the feature extraction step altogether. An external convolutional language model is used to decode words. On Wall Street Journal, our model matches the current state-of-the-art. On Librispeech, we report state-of-the-art performance among end-to-end models, including Deep Speech 2 trained with 12 times more acoustic data and significantly more linguistic data.
To Reverse the Gradient or Not: An Empirical Comparison of Adversarial and Multi-task Learning in Speech Recognition
Dec 13, 2018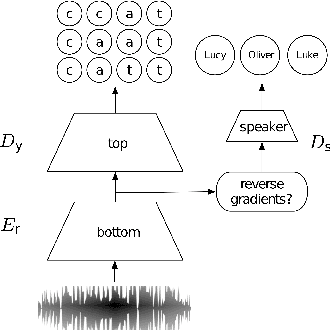
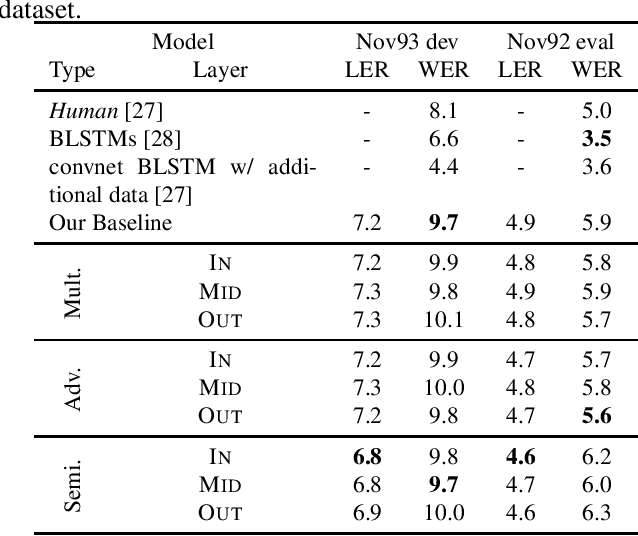
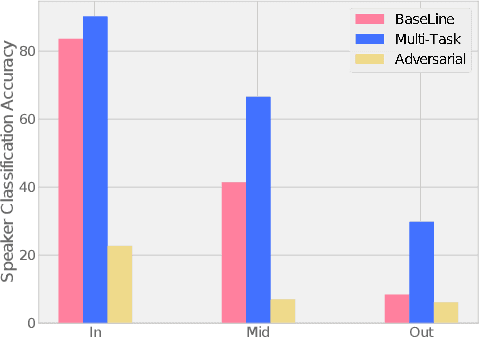
Transcribed datasets typically contain speaker identity for each instance in the data. We investigate two ways to incorporate this information during training: Multi-Task Learning and Adversarial Learning. In multi-task learning, the goal is speaker prediction; we expect a performance improvement with this joint training if the two tasks of speech recognition and speaker recognition share a common set of underlying features. In contrast, adversarial learning is a means to learn representations invariant to the speaker. We then expect better performance if this learnt invariance helps generalizing to new speakers. While the two approaches seem natural in the context of speech recognition, they are incompatible because they correspond to opposite gradients back-propagated to the model. In order to better understand the effect of these approaches in terms of error rates, we compare both strategies in controlled settings. Moreover, we explore the use of additional untranscribed data in a semi-supervised, adversarial learning manner to improve error rates. Our results show that deep models trained on big datasets already develop invariant representations to speakers without any auxiliary loss. When considering adversarial learning and multi-task learning, the impact on the acoustic model seems minor. However, models trained in a semi-supervised manner can improve error-rates.
End-to-End Speech Recognition From the Raw Waveform
Jun 21, 2018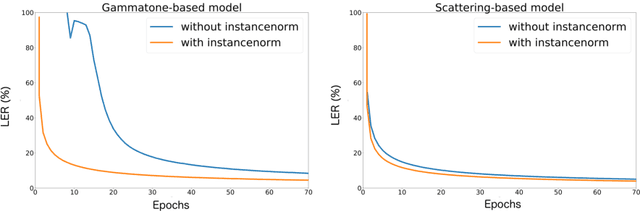
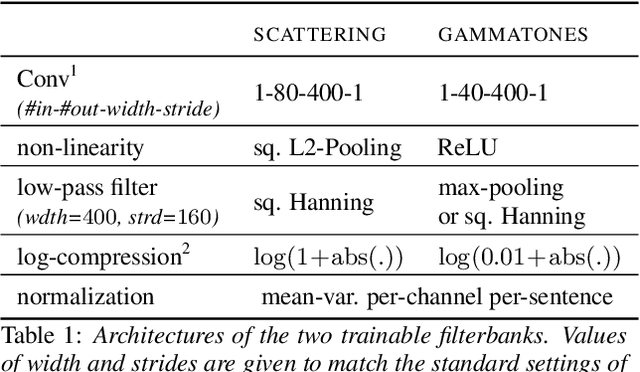
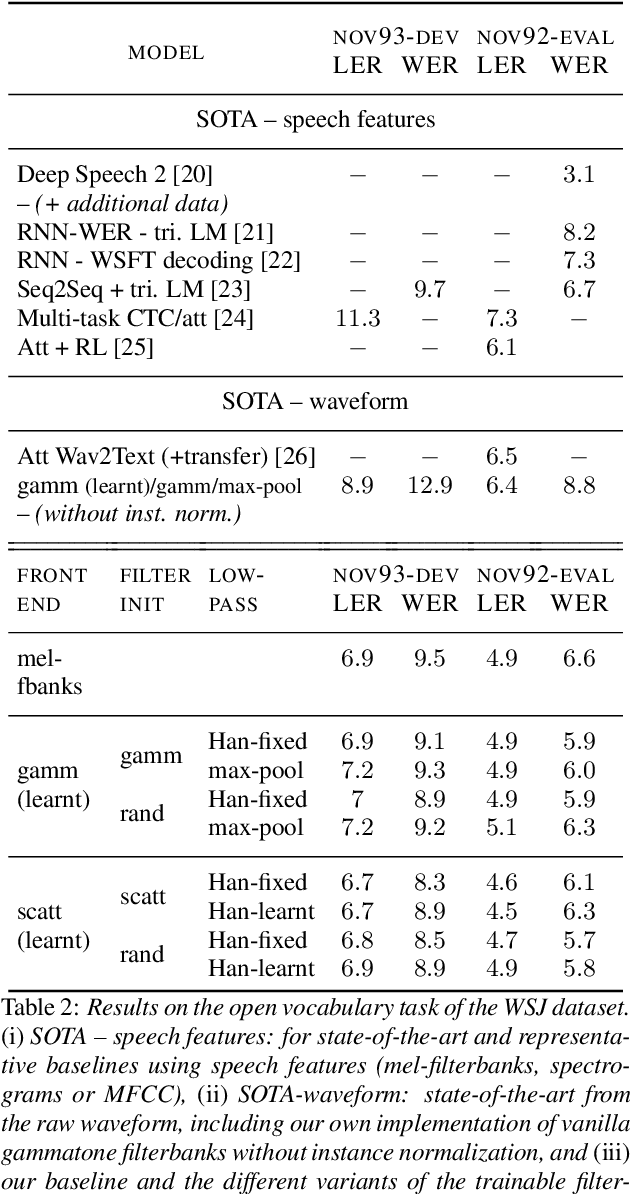
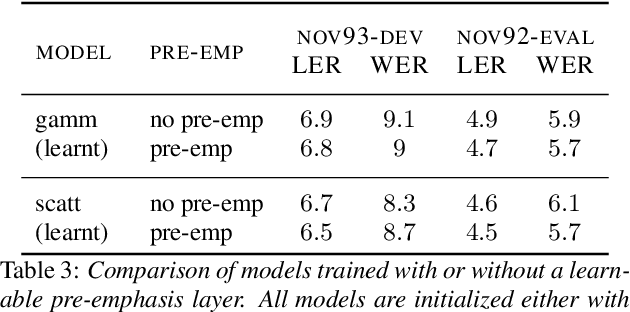
State-of-the-art speech recognition systems rely on fixed, hand-crafted features such as mel-filterbanks to preprocess the waveform before the training pipeline. In this paper, we study end-to-end systems trained directly from the raw waveform, building on two alternatives for trainable replacements of mel-filterbanks that use a convolutional architecture. The first one is inspired by gammatone filterbanks (Hoshen et al., 2015; Sainath et al, 2015), and the second one by the scattering transform (Zeghidour et al., 2017). We propose two modifications to these architectures and systematically compare them to mel-filterbanks, on the Wall Street Journal dataset. The first modification is the addition of an instance normalization layer, which greatly improves on the gammatone-based trainable filterbanks and speeds up the training of the scattering-based filterbanks. The second one relates to the low-pass filter used in these approaches. These modifications consistently improve performances for both approaches, and remove the need for a careful initialization in scattering-based trainable filterbanks. In particular, we show a consistent improvement in word error rate of the trainable filterbanks relatively to comparable mel-filterbanks. It is the first time end-to-end models trained from the raw signal significantly outperform mel-filterbanks on a large vocabulary task under clean recording conditions.
Letter-Based Speech Recognition with Gated ConvNets
Dec 22, 2017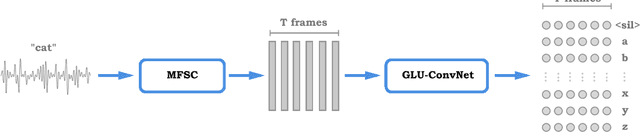

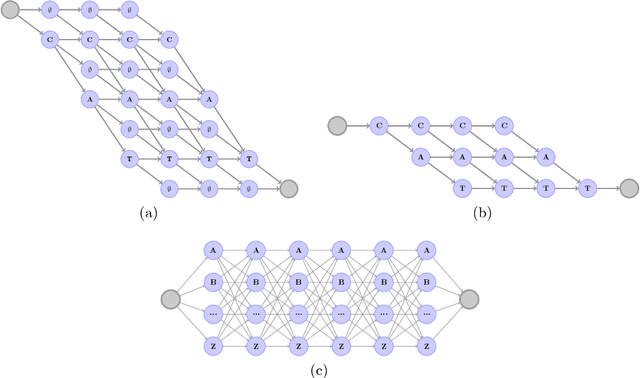

In this paper we introduce a new speech recognition system, leveraging a simple letter-based ConvNet acoustic model. The acoustic model requires -- only audio transcription for training -- no alignment annotations, nor any forced alignment step is needed. At inference, our decoder takes only a word list and a language model, and is fed with letter scores from the -- acoustic model -- no phonetic word lexicon is needed. Key ingredients for the acoustic model are Gated Linear Units and high dropout. We show near state-of-the-art results in word error rate on the LibriSpeech corpus using log-mel filterbanks, both on the "clean" and "other" configurations.
Word Emdeddings through Hellinger PCA
Jan 04, 2017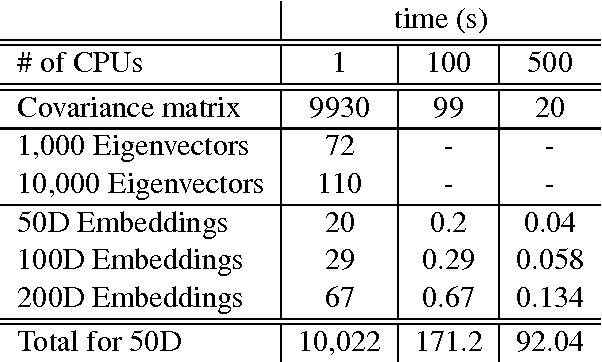
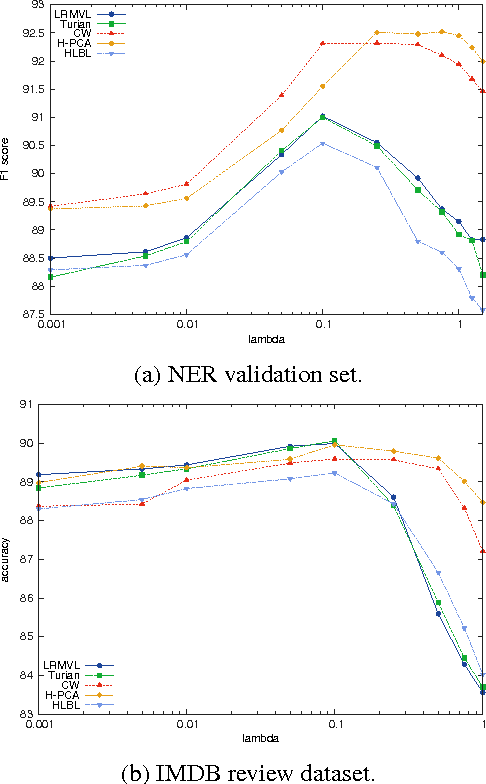

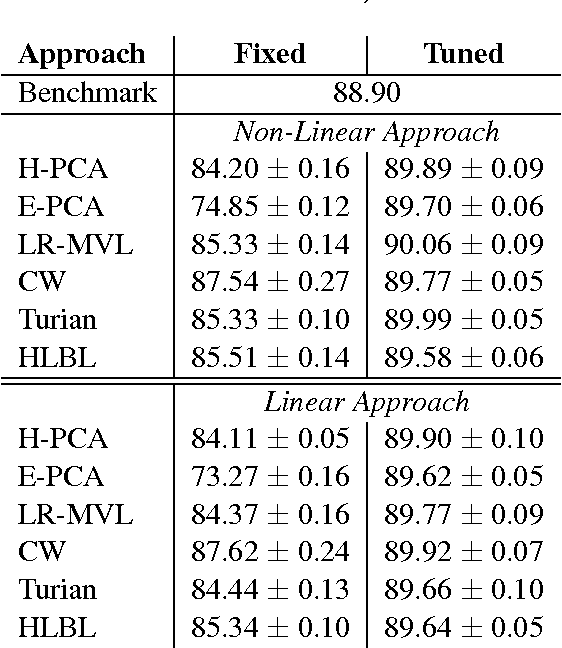
Word embeddings resulting from neural language models have been shown to be successful for a large variety of NLP tasks. However, such architecture might be difficult to train and time-consuming. Instead, we propose to drastically simplify the word embeddings computation through a Hellinger PCA of the word co-occurence matrix. We compare those new word embeddings with some well-known embeddings on NER and movie review tasks and show that we can reach similar or even better performance. Although deep learning is not really necessary for generating good word embeddings, we show that it can provide an easy way to adapt embeddings to specific tasks.
* 9 pages, 5 tables
Wav2Letter: an End-to-End ConvNet-based Speech Recognition System
Sep 13, 2016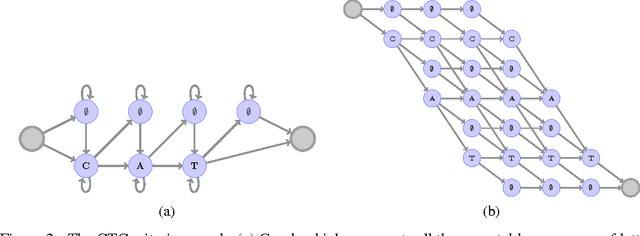
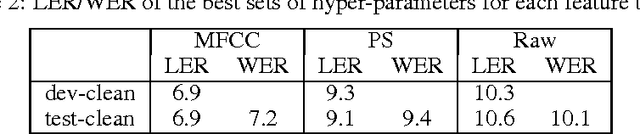
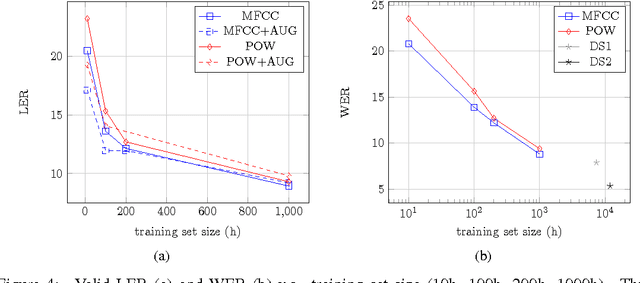
This paper presents a simple end-to-end model for speech recognition, combining a convolutional network based acoustic model and a graph decoding. It is trained to output letters, with transcribed speech, without the need for force alignment of phonemes. We introduce an automatic segmentation criterion for training from sequence annotation without alignment that is on par with CTC while being simpler. We show competitive results in word error rate on the Librispeech corpus with MFCC features, and promising results from raw waveform.
Learning to Refine Object Segments
Jul 26, 2016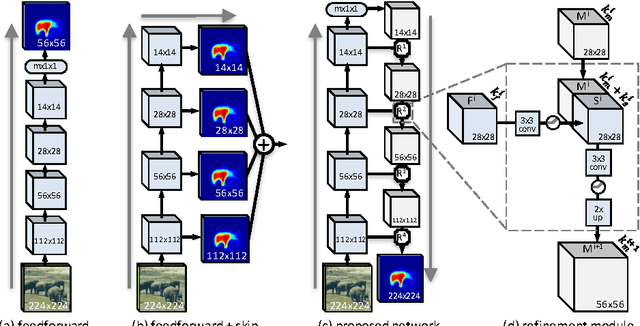
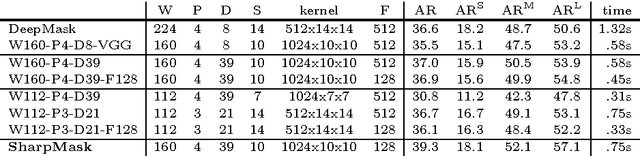

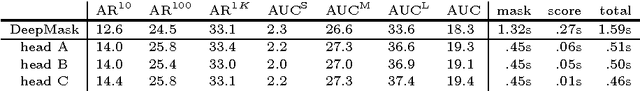
Object segmentation requires both object-level information and low-level pixel data. This presents a challenge for feedforward networks: lower layers in convolutional nets capture rich spatial information, while upper layers encode object-level knowledge but are invariant to factors such as pose and appearance. In this work we propose to augment feedforward nets for object segmentation with a novel top-down refinement approach. The resulting bottom-up/top-down architecture is capable of efficiently generating high-fidelity object masks. Similarly to skip connections, our approach leverages features at all layers of the net. Unlike skip connections, our approach does not attempt to output independent predictions at each layer. Instead, we first output a coarse `mask encoding' in a feedforward pass, then refine this mask encoding in a top-down pass utilizing features at successively lower layers. The approach is simple, fast, and effective. Building on the recent DeepMask network for generating object proposals, we show accuracy improvements of 10-20% in average recall for various setups. Additionally, by optimizing the overall network architecture, our approach, which we call SharpMask, is 50% faster than the original DeepMask network (under .8s per image).