 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoland Siegwart
Fast and Compute-efficient Sampling-based Local Exploration Planning via Distribution Learning
Feb 28, 2022

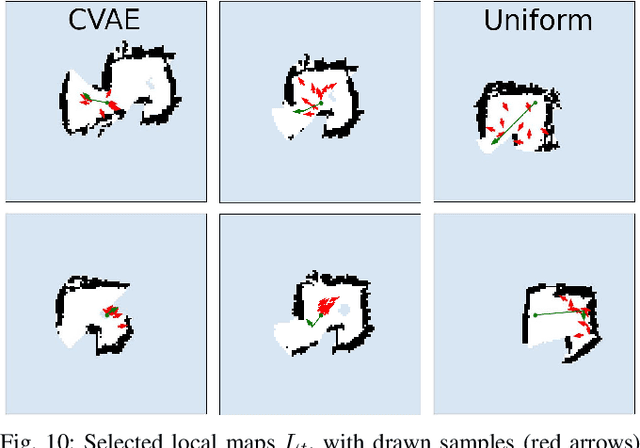
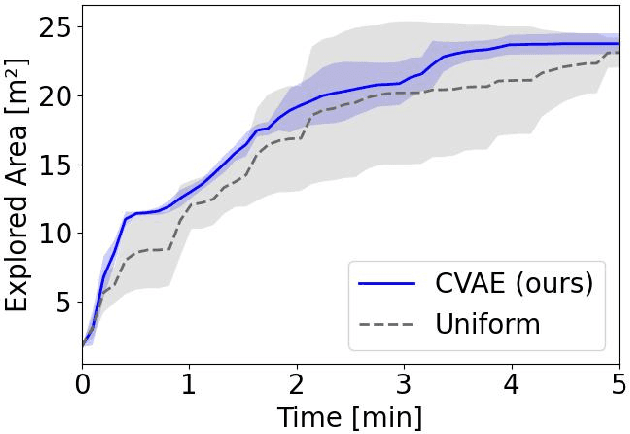
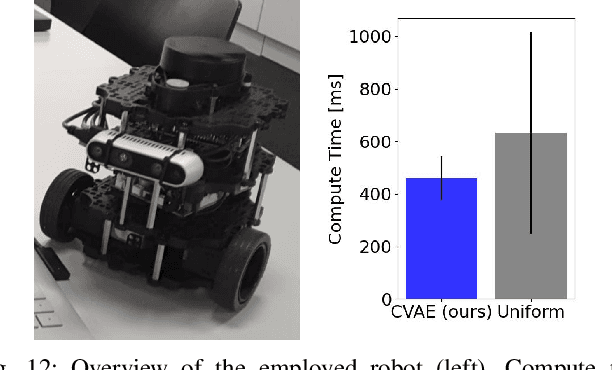
Exploration is a fundamental problem in robotics. While sampling-based planners have shown high performance, they are oftentimes compute intensive and can exhibit high variance. To this end, we propose to directly learn the underlying distribution of informative views based on the spatial context in the robot's map. We further explore a variety of methods to also learn the information gain. We show in thorough experimental evaluation that our proposed system improves exploration performance by up to 28\% over classical methods, and find that learning the gains in addition to the sampling distribution can provide favorable performance vs. compute trade-offs for compute-constrained systems. We demonstrate in simulation and on a low-cost mobile robot that our system generalizes well to varying environments.
Energy Tank-Based Policies for Robust Aerial Physical Interaction with Moving Objects
Feb 14, 2022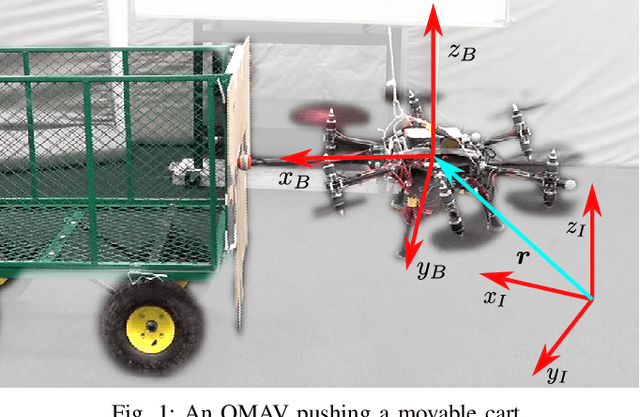
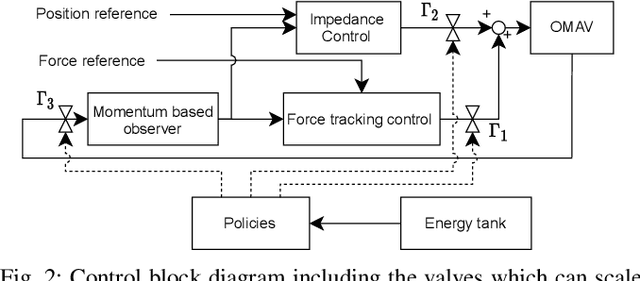
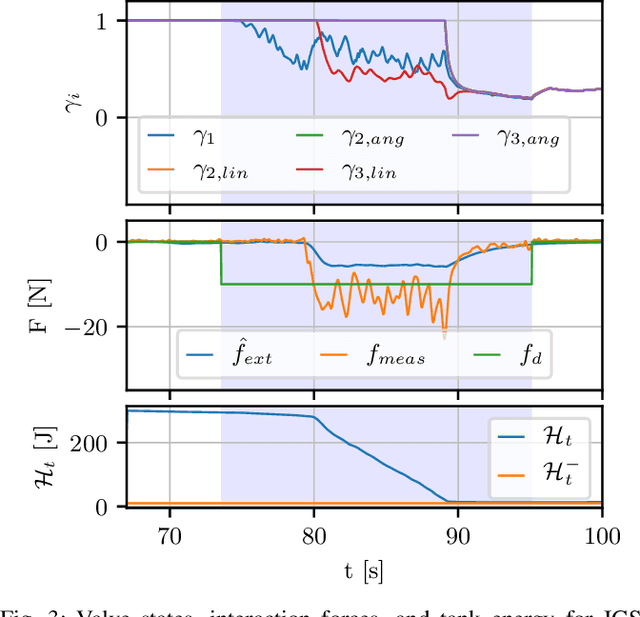
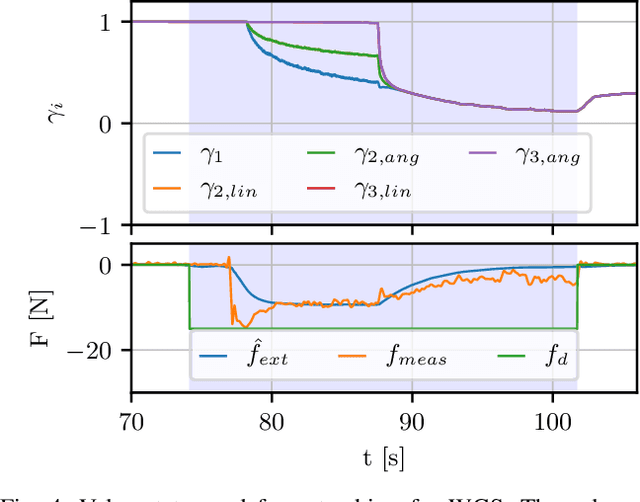
Although manipulation capabilities of aerial robots greatly improved in the last decade, only few works addressed the problem of aerial physical interaction with dynamic environments, proposing strongly model-based approaches. However, in real scenarios, modeling the environment with high accuracy is often impossible. In this work we aim at developing a control framework for OMAVs for reliable physical interaction tasks with articulated and movable objects in the presence of possibly unforeseen disturbances, and without relying on an accurate model of the environment. Inspired by previous applications of energy-based controllers for physical interaction, we propose a passivity-based impedance and wrench tracking controller in combination with a momentum-based wrench estimator. This is combined with an energy-tank framework to guarantee the stability of the system, while energy and power flow-based adaptation policies are deployed to enable safe interaction with any type of passive environment. The control framework provides formal guarantees of stability, which is validated in practice considering the challenging task of pushing a cart of unknown mass, moving on a surface of unknown friction, as well as subjected to unknown disturbances. For this scenario, we present, evaluate and discuss three different policies.
SL Sensor: An Open-Source, ROS-Based, Real-Time Structured Light Sensor for High Accuracy Construction Robotic Applications
Jan 22, 2022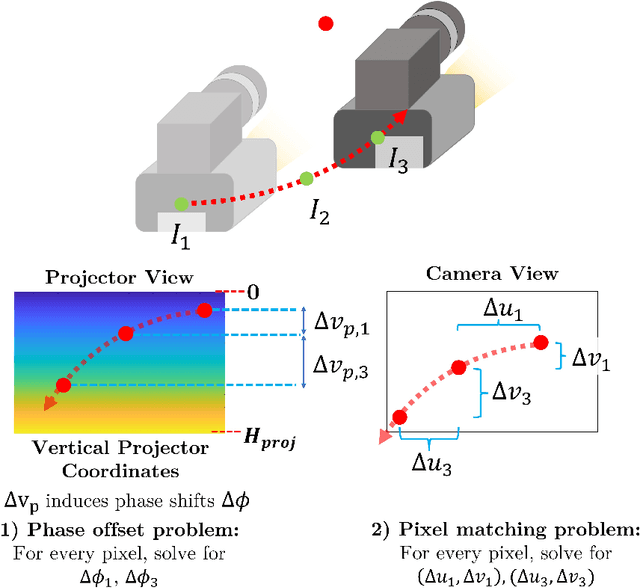


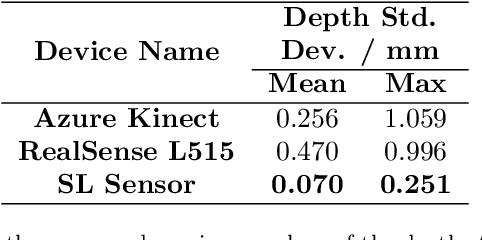
High accuracy 3D surface information is required for many construction robotics tasks such as automated cement polishing or robotic plaster spraying. However, consumer-grade depth cameras currently found in the market are not accurate enough for these tasks where millimeter (mm)-level accuracy is required. We present SL Sensor, a structured light sensing solution capable of producing high fidelity point clouds at 5Hz by leveraging on phase shifting profilometry (PSP) codification techniques. We compared SL Sensor to two commercial depth cameras - the Azure Kinect and RealSense L515. Experiments showed that the SL Sensor surpasses the two devices in both precision and accuracy. Furthermore, to demonstrate SL Sensor's ability to be a structured light sensing research platform for robotic applications, we developed a motion compensation strategy that allows the SL Sensor to operate during linear motion when traditional PSP methods only work when the sensor is static. Field experiments show that the SL Sensor is able produce highly detailed reconstructions of spray plastered surfaces. The software and a sample hardware build of the SL Sensor are made open-source with the objective to make structured light sensing more accessible to the construction robotics community. All documentation and code is available at https://github.com/ethz-asl/sl_sensor/ .
Semi-automatic 3D Object Keypoint Annotation and Detection for the Masses
Jan 19, 2022
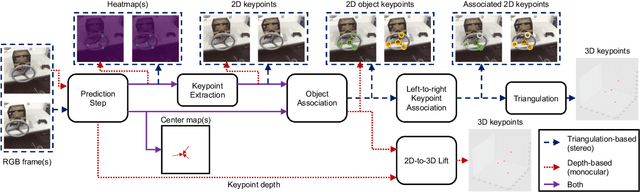

Creating computer vision datasets requires careful planning and lots of time and effort. In robotics research, we often have to use standardized objects, such as the YCB object set, for tasks such as object tracking, pose estimation, grasping and manipulation, as there are datasets and pre-learned methods available for these objects. This limits the impact of our research since learning-based computer vision methods can only be used in scenarios that are supported by existing datasets. In this work, we present a full object keypoint tracking toolkit, encompassing the entire process from data collection, labeling, model learning and evaluation. We present a semi-automatic way of collecting and labeling datasets using a wrist mounted camera on a standard robotic arm. Using our toolkit and method, we are able to obtain a working 3D object keypoint detector and go through the whole process of data collection, annotation and learning in just a couple hours of active time.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

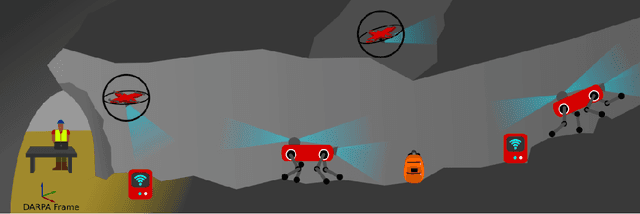

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
Autonomous Teamed Exploration of Subterranean Environments using Legged and Aerial Robots
Nov 11, 2021
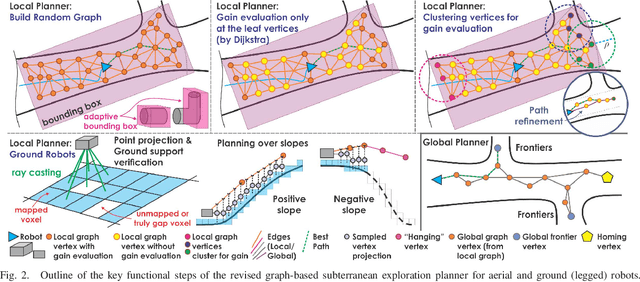
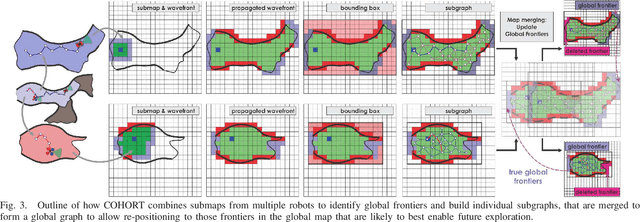
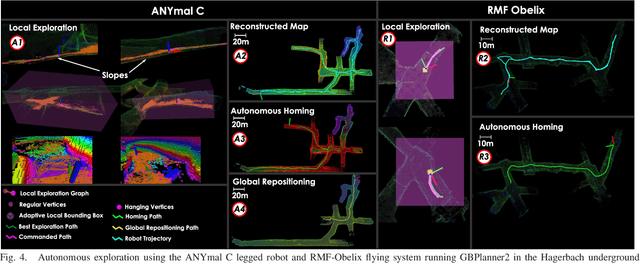
This paper presents a novel strategy for autonomous teamed exploration of subterranean environments using legged and aerial robots. Tailored to the fact that subterranean settings, such as cave networks and underground mines, often involve complex, large-scale and multi-branched topologies, while wireless communication within them can be particularly challenging, this work is structured around the synergy of an onboard exploration path planner that allows for resilient long-term autonomy, and a multi-robot coordination framework. The onboard path planner is unified across legged and flying robots and enables navigation in environments with steep slopes, and diverse geometries. When a communication link is available, each robot of the team shares submaps to a centralized location where a multi-robot coordination framework identifies global frontiers of the exploration space to inform each system about where it should re-position to best continue its mission. The strategy is verified through a field deployment inside an underground mine in Switzerland using a legged and a flying robot collectively exploring for 45 min, as well as a longer simulation study with three systems.
Multi-Resolution Elevation Mapping and Safe Landing Site Detection with Applications to Planetary Rotorcraft
Nov 11, 2021
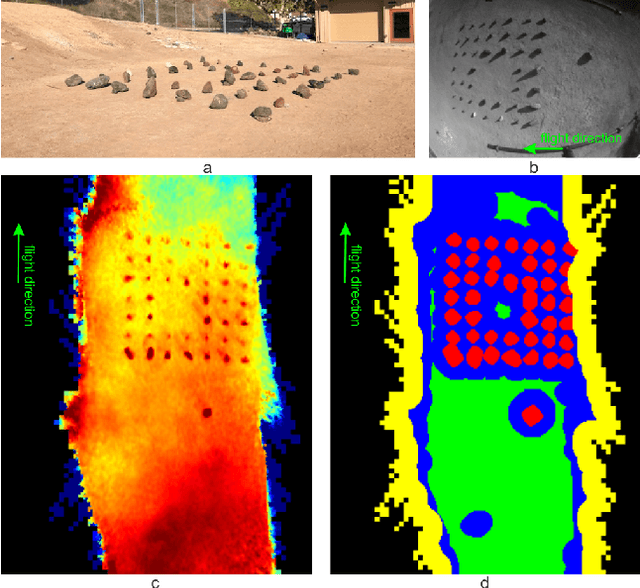
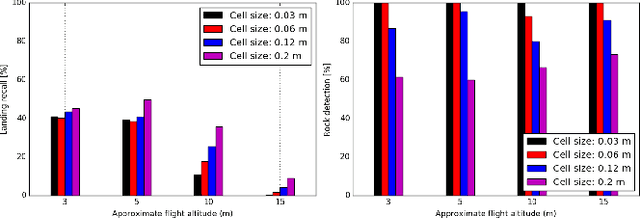

In this paper, we propose a resource-efficient approach to provide an autonomous UAV with an on-board perception method to detect safe, hazard-free landing sites during flights over complex 3D terrain. We aggregate 3D measurements acquired from a sequence of monocular images by a Structure-from-Motion approach into a local, robot-centric, multi-resolution elevation map of the overflown terrain, which fuses depth measurements according to their lateral surface resolution (pixel-footprint) in a probabilistic framework based on the concept of dynamic Level of Detail. Map aggregation only requires depth maps and the associated poses, which are obtained from an onboard Visual Odometry algorithm. An efficient landing site detection method then exploits the features of the underlying multi-resolution map to detect safe landing sites based on slope, roughness, and quality of the reconstructed terrain surface. The evaluation of the performance of the mapping and landing site detection modules are analyzed independently and jointly in simulated and real-world experiments in order to establish the efficacy of the proposed approach.
Continual Learning of Semantic Segmentation using Complementary 2D-3D Data Representations
Nov 03, 2021
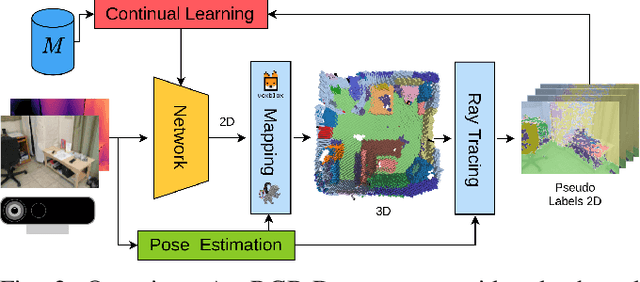
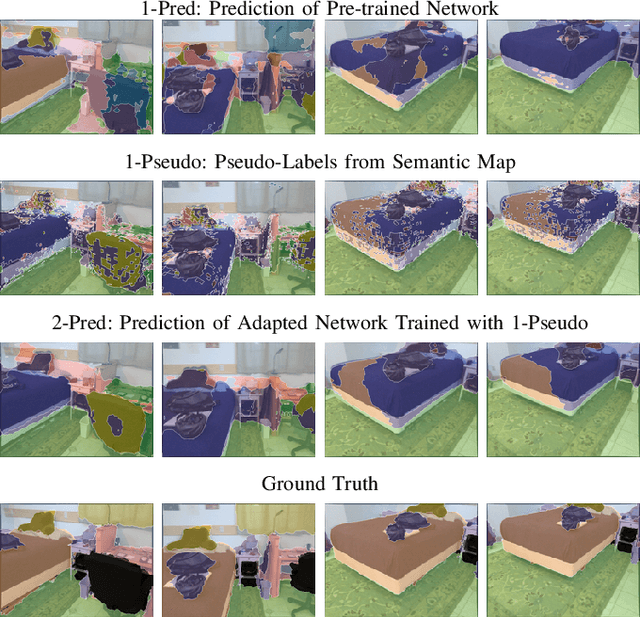

Semantic segmentation networks are usually pre-trained and not updated during deployment. As a consequence, misclassifications commonly occur if the distribution of the training data deviates from the one encountered during the robot's operation. We propose to mitigate this problem by adapting the neural network to the robot's environment during deployment, without any need for external supervision. Leveraging complementary data representations, we generate a supervision signal, by probabilistically accumulating consecutive 2D semantic predictions in a volumetric 3D map. We then retrain the network on renderings of the accumulated semantic map, effectively resolving ambiguities and enforcing multi-view consistency through the 3D representation. To preserve the previously-learned knowledge while performing network adaptation, we employ a continual learning strategy based on experience replay. Through extensive experimental evaluation, we show successful adaptation to real-world indoor scenes both on the ScanNet dataset and on in-house data recorded with an RGB-D sensor. Our method increases the segmentation performance on average by 11.8% compared to the fixed pre-trained neural network, while effectively retaining knowledge from the pre-training dataset.
NeuralBlox: Real-Time Neural Representation Fusion for Robust Volumetric Mapping
Oct 18, 2021
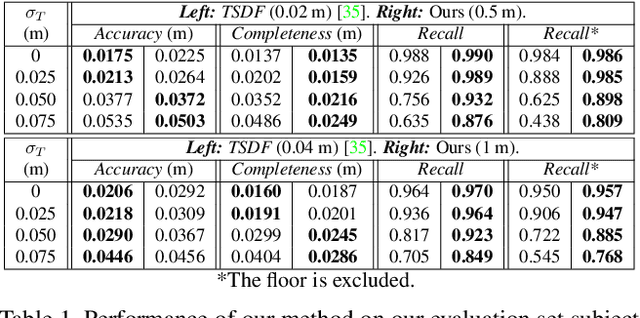
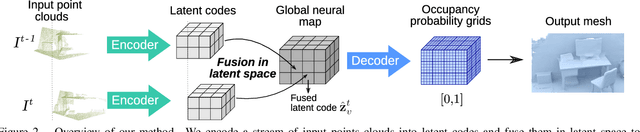

We present a novel 3D mapping method leveraging the recent progress in neural implicit representation for 3D reconstruction. Most existing state-of-the-art neural implicit representation methods are limited to object-level reconstructions and can not incrementally perform updates given new data. In this work, we propose a fusion strategy and training pipeline to incrementally build and update neural implicit representations that enable the reconstruction of large scenes from sequential partial observations. By representing an arbitrarily sized scene as a grid of latent codes and performing updates directly in latent space, we show that incrementally built occupancy maps can be obtained in real-time even on a CPU. Compared to traditional approaches such as Truncated Signed Distance Fields (TSDFs), our map representation is significantly more robust in yielding a better scene completeness given noisy inputs. We demonstrate the performance of our approach in thorough experimental validation on real-world datasets with varying degrees of added pose noise.
See Yourself in Others: Attending Multiple Tasks for Own Failure Detection
Oct 06, 2021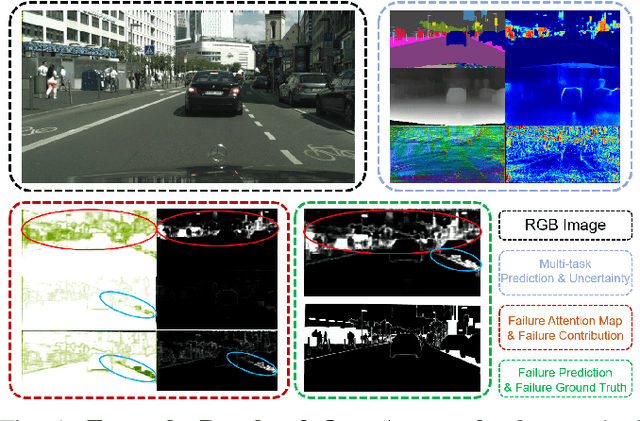
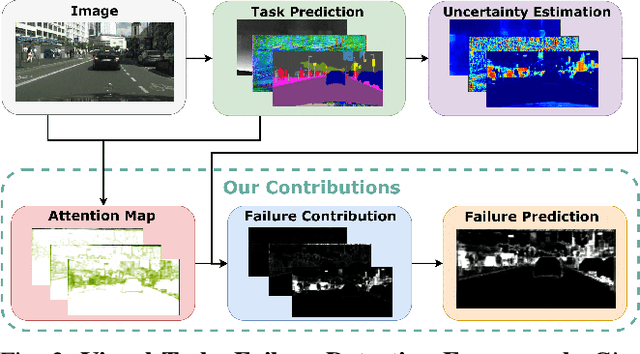
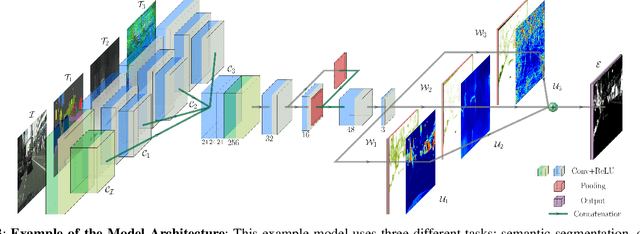
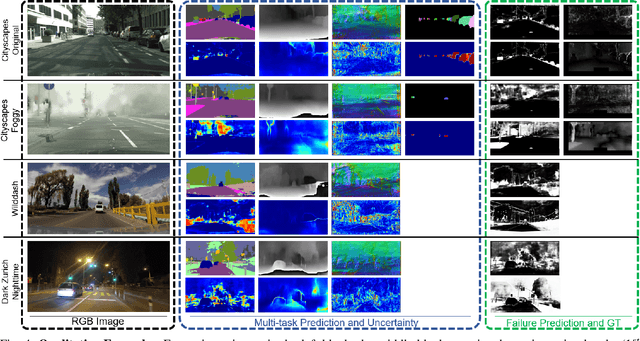
Autonomous robots deal with unexpected scenarios in real environments. Given input images, various visual perception tasks can be performed, e.g., semantic segmentation, depth estimation and normal estimation. These different tasks provide rich information for the whole robotic perception system. All tasks have their own characteristics while sharing some latent correlations. However, some of the task predictions may suffer from the unreliability dealing with complex scenes and anomalies. We propose an attention-based failure detection approach by exploiting the correlations among multiple tasks. The proposed framework infers task failures by evaluating the individual prediction, across multiple visual perception tasks for different regions in an image. The formulation of the evaluations is based on an attention network supervised by multi-task uncertainty estimation and their corresponding prediction errors. Our proposed framework generates more accurate estimations of the prediction error for the different task's predictions.