 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Translation with an Affinity-Based Change Prior for Unsupervised Multimodal Change Detection
Jan 13, 2020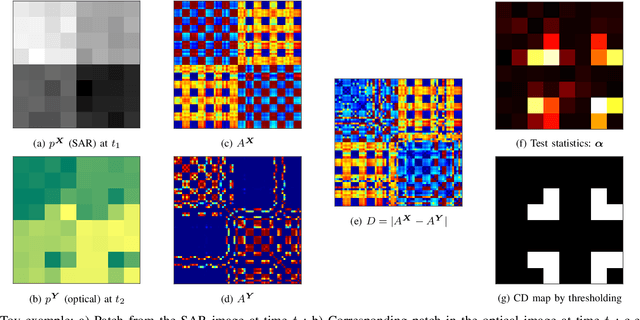
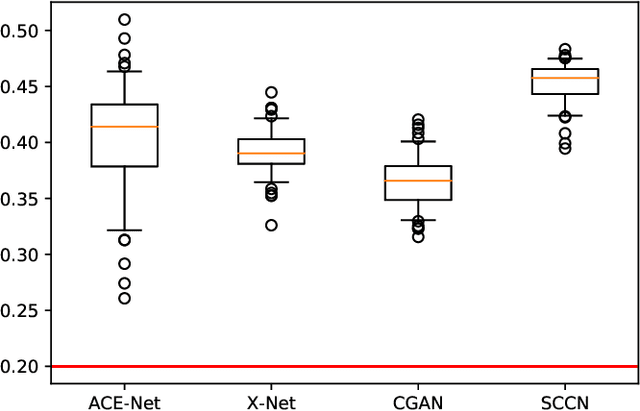
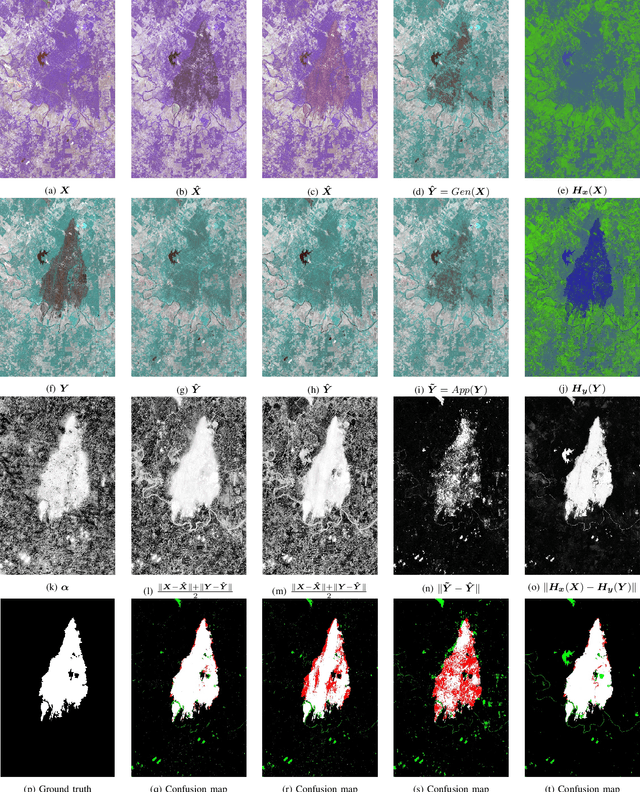
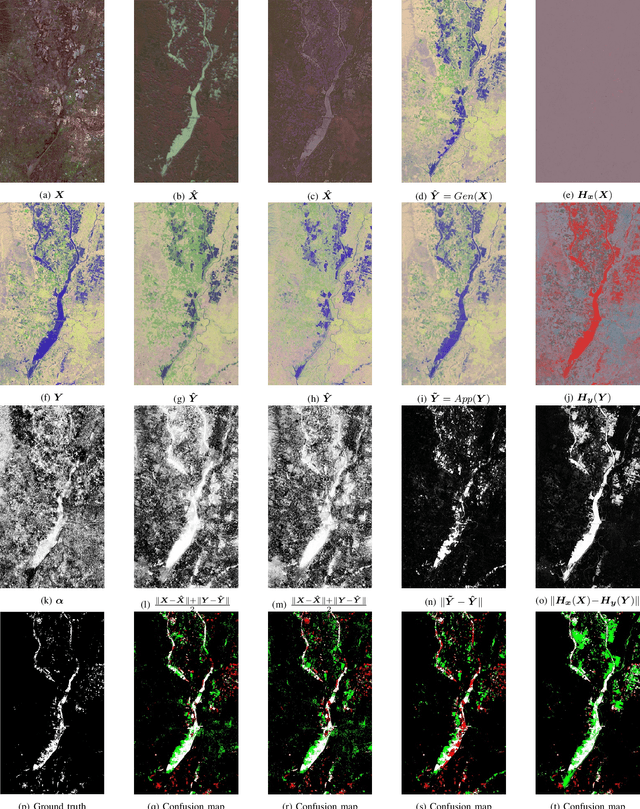
Image translation with convolutional neural networks has recently been used as an approach to multimodal change detection. Existing approaches train the networks by exploiting supervised information of the change areas, which, however, is not always available. A main challenge in the unsupervised problem setting is to avoid that change pixels affect the learning of the translation function. We propose two new network architectures trained with loss functions weighted by priors that reduce the impact of change pixels on the learning objective. The change prior is derived in an unsupervised fashion from relational pixel information captured by domain-specific affinity matrices. Specifically, we use the vertex degrees associated with an absolute affinity difference matrix and demonstrate their utility in combination with cycle consistency and adversarial training. The proposed neural networks are compared with state-of-the-art algorithms. Experiments conducted on two real datasets show the effectiveness of our methodology.
Information Plane Analysis of Deep Neural Networks via Matrix-Based Renyi's Entropy and Tensor Kernels
Sep 25, 2019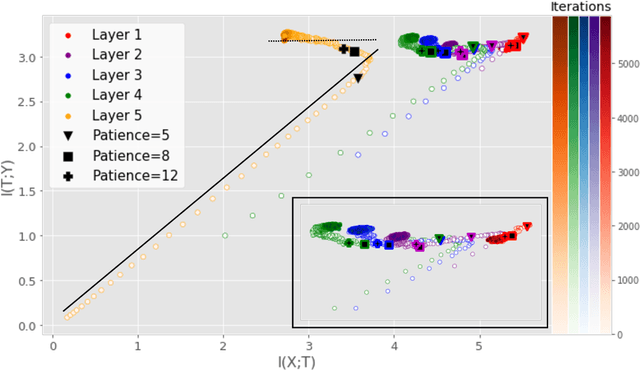
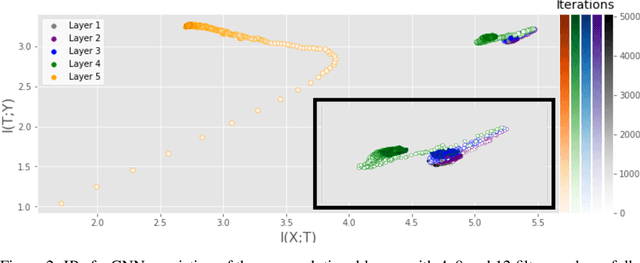
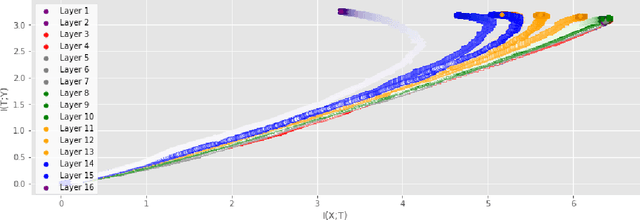
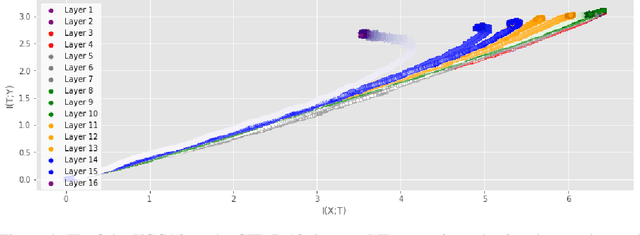
Analyzing deep neural networks (DNNs) via information plane (IP) theory has gained tremendous attention recently as a tool to gain insight into, among others, their generalization ability. However, it is by no means obvious how to estimate mutual information (MI) between each hidden layer and the input/desired output, to construct the IP. For instance, hidden layers with many neurons require MI estimators with robustness towards the high dimensionality associated with such layers. MI estimators should also be able to naturally handle convolutional layers, while at the same time being computationally tractable to scale to large networks. None of the existing IP methods to date have been able to study truly deep Convolutional Neural Networks (CNNs), such as the e.g.\ VGG-16. In this paper, we propose an IP analysis using the new matrix--based R\'enyi's entropy coupled with tensor kernels over convolutional layers, leveraging the power of kernel methods to represent properties of the probability distribution independently of the dimensionality of the data. The obtained results shed new light on the previous literature concerning small-scale DNNs, however using a completely new approach. Importantly, the new framework enables us to provide the first comprehensive IP analysis of contemporary large-scale DNNs and CNNs, investigating the different training phases and providing new insights into the training dynamics of large-scale neural networks.
Road Mapping In LiDAR Images Using A Joint-Task Dense Dilated Convolutions Merging Network
Sep 07, 2019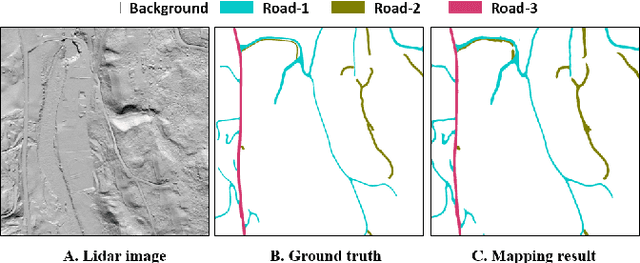
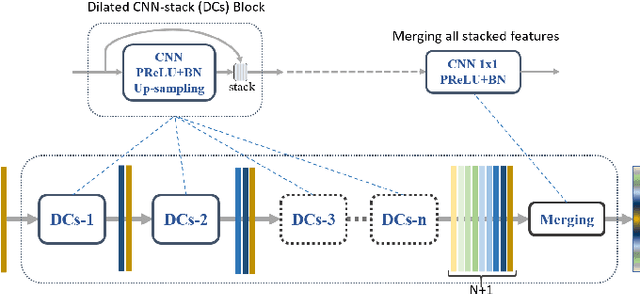
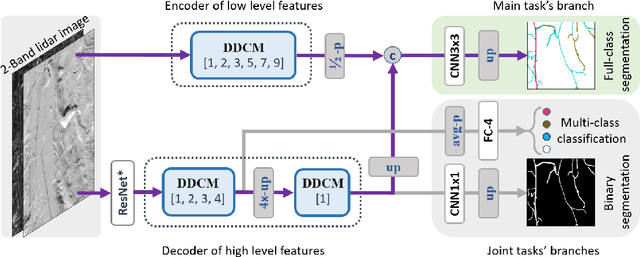
It is important, but challenging, for the forest industry to accurately map roads which are used for timber transport by trucks. In this work, we propose a Dense Dilated Convolutions Merging Network (DDCM-Net) to detect these roads in lidar images. The DDCM-Net can effectively recognize multi-scale and complex shaped roads with similar texture and colors, and also is shown to have superior performance over existing methods. To further improve its ability to accurately infer categories of roads, we propose the use of a joint-task learning strategy that utilizes two auxiliary output branches, i.e, multi-class classification and binary segmentation, joined with the main output of full-class segmentation. This pushes the network towards learning more robust representations that are expected to boost the ultimate performance of the main task. In addition, we introduce an iterative-random-weighting method to automatically weigh the joint losses for auxiliary tasks. This can avoid the difficult and expensive process of tuning the weights of each task's loss by hand. The experiments demonstrate that our proposed joint-task DDCM-Net can achieve better performance with fewer parameters and higher computational efficiency than previous state-of-the-art approaches.
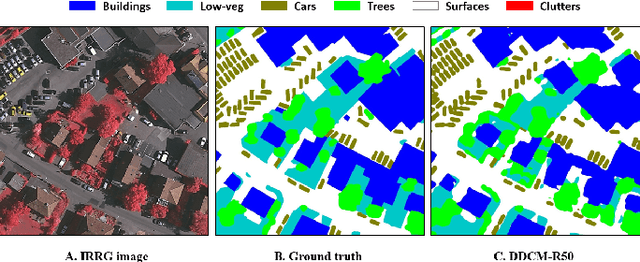
Dense Dilated Convolutions Merging Network for Semantic Mapping of Remote Sensing Images
Aug 30, 2019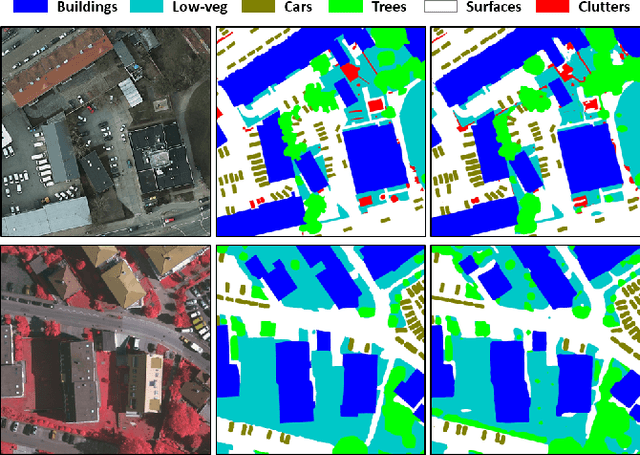
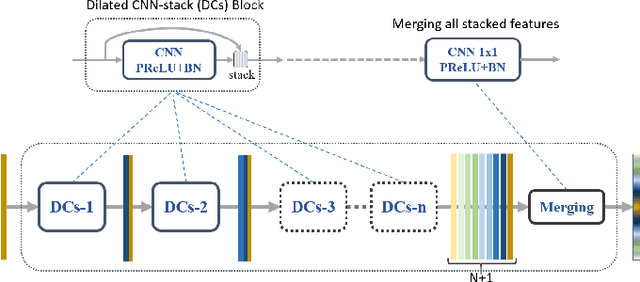
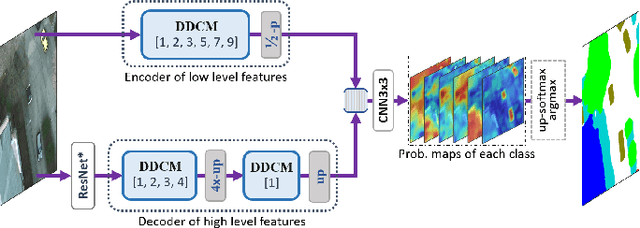

We propose a network for semantic mapping called the Dense Dilated Convolutions Merging Network (DDCM-Net) to provide a deep learning approach that can recognize multi-scale and complex shaped objects with similar color and textures, such as buildings, surfaces/roads, and trees in very high resolution remote sensing images. The proposed DDCM-Net consists of dense dilated convolutions merged with varying dilation rates. This can effectively enlarge the kernels' receptive fields, and, more importantly, obtain fused local and global context information to promote surrounding discriminative capability. We demonstrate the effectiveness of the proposed DDCM-Net on the publicly available ISPRS Potsdam dataset and achieve a performance of 92.3% F1-score and 86.0% mean intersection over union accuracy by only using the RGB bands, without any post-processing. We also show results on the ISPRS Vaihingen dataset, where the DDCM-Net trained with IRRG bands, also obtained better mapping accuracy (89.8% F1-score) than previous state-of-the-art approaches.
Time series cluster kernels to exploit informative missingness and incomplete label information
Jul 10, 2019
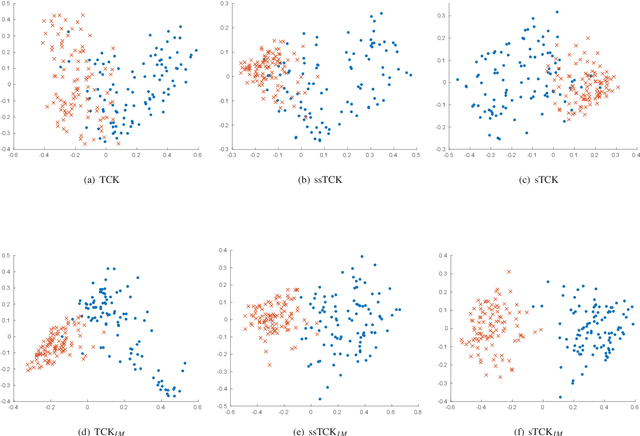
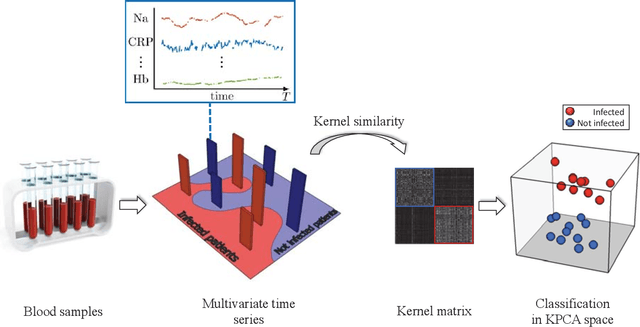
The time series cluster kernel (TCK) provides a powerful tool for analysing multivariate time series subject to missing data. TCK is designed using an ensemble learning approach in which Bayesian mixture models form the base models. Because of the Bayesian approach, TCK can naturally deal with missing values without resorting to imputation and the ensemble strategy ensures robustness to hyperparameters, making it particularly well suited for unsupervised learning. However, TCK assumes missing at random and that the underlying missingness mechanism is ignorable, i.e. uninformative, an assumption that does not hold in many real-world applications, such as e.g. medicine. To overcome this limitation, we present a kernel capable of exploiting the potentially rich information in the missing values and patterns, as well as the information from the observed data. In our approach, we create a representation of the missing pattern, which is incorporated into mixed mode mixture models in such a way that the information provided by the missing patterns is effectively exploited. Moreover, we also propose a semi-supervised kernel, capable of taking advantage of incomplete label information to learn more accurate similarities. Experiments on benchmark data, as well as a real-world case study of patients described by longitudinal electronic health record data who potentially suffer from hospital-acquired infections, demonstrate the effectiveness of the proposed methods.
Deep Generative Models for Reject Inference in Credit Scoring
Apr 12, 2019
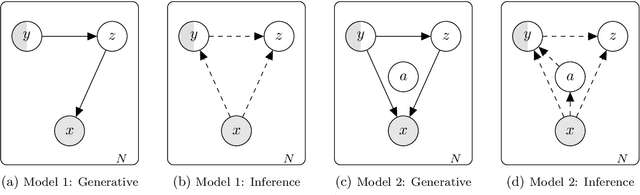

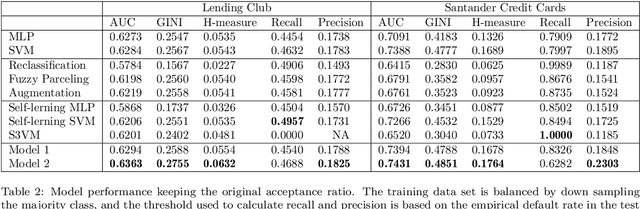
Credit scoring models based on accepted applications may be biased and their consequences can have a statistical and economic impact. Reject inference is the process of attempting to infer the creditworthiness status of the rejected applications. In this research, we use deep generative models to develop two new semi-supervised Bayesian models for reject inference in credit scoring, in which we model the data generating process to be dependent on a Gaussian mixture. The goal is to improve the classification accuracy in credit scoring models by adding reject applications. Our proposed models infer the unknown creditworthiness of the rejected applications by exact enumeration of the two possible outcomes of the loan (default or non-default). The efficient stochastic gradient optimization technique used in deep generative models makes our models suitable for large data sets. Finally, the experiments in this research show that our proposed models perform better than classical and alternative machine learning models for reject inference in credit scoring.
Learning Latent Representations of Bank Customers With The Variational Autoencoder
Mar 14, 2019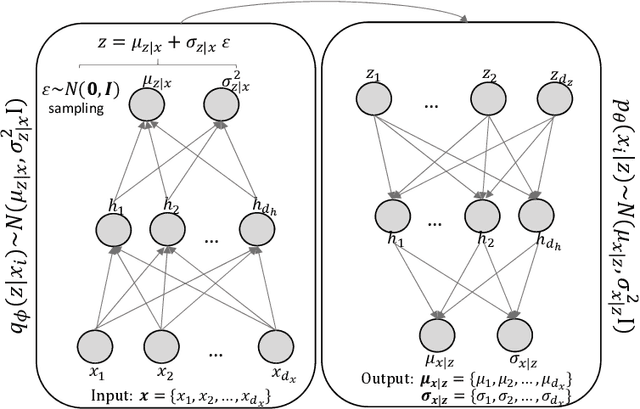
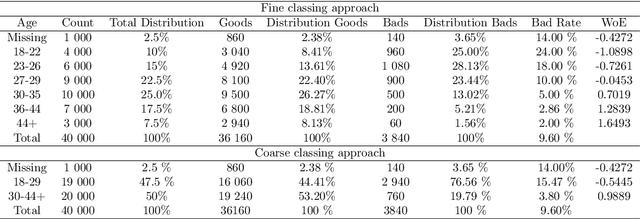
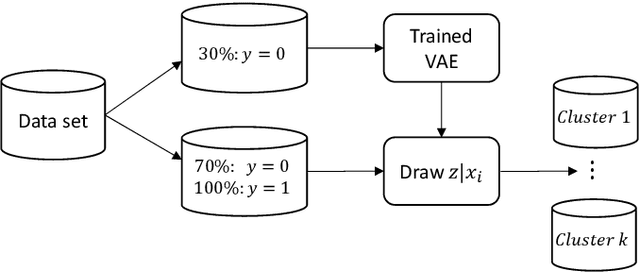

Learning data representations that reflect the customers' creditworthiness can improve marketing campaigns, customer relationship management, data and process management or the credit risk assessment in retail banks. In this research, we adopt the Variational Autoencoder (VAE), which has the ability to learn latent representations that contain useful information. We show that it is possible to steer the latent representations in the latent space of the VAE using the Weight of Evidence and forming a specific grouping of the data that reflects the customers' creditworthiness. Our proposed method learns a latent representation of the data, which shows a well-defied clustering structure capturing the customers' creditworthiness. These clusters are well suited for the aforementioned banks' activities. Further, our methodology generalizes to new customers, captures high-dimensional and complex financial data, and scales to large data sets.
Noisy multi-label semi-supervised dimensionality reduction
Feb 20, 2019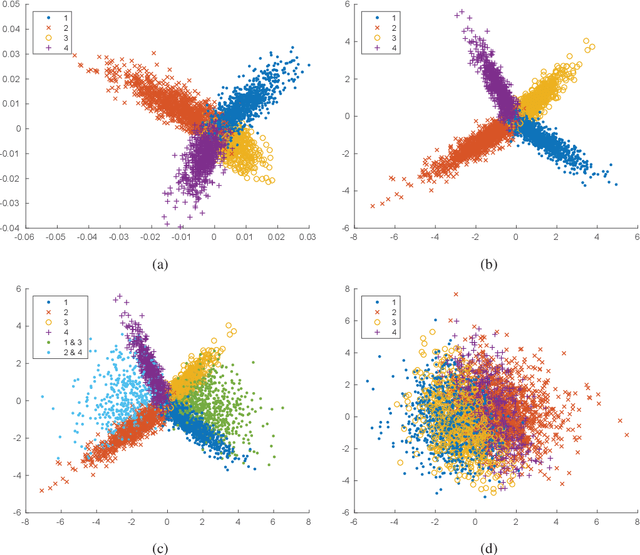
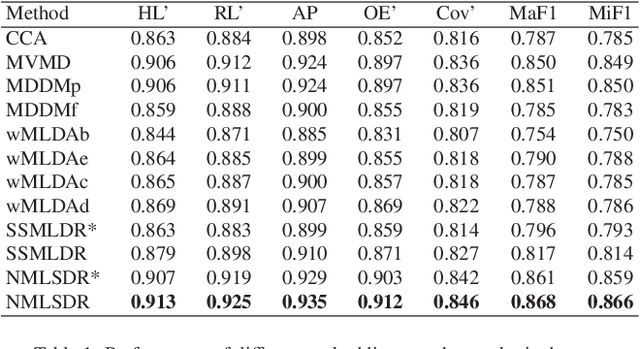
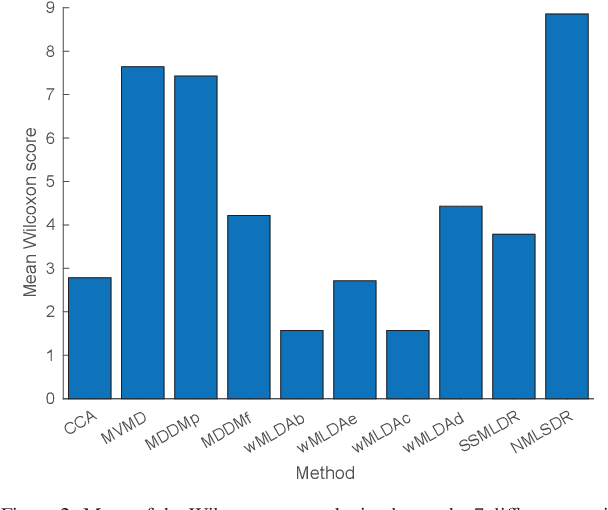

Noisy labeled data represent a rich source of information that often are easily accessible and cheap to obtain, but label noise might also have many negative consequences if not accounted for. How to fully utilize noisy labels has been studied extensively within the framework of standard supervised machine learning over a period of several decades. However, very little research has been conducted on solving the challenge posed by noisy labels in non-standard settings. This includes situations where only a fraction of the samples are labeled (semi-supervised) and each high-dimensional sample is associated with multiple labels. In this work, we present a novel semi-supervised and multi-label dimensionality reduction method that effectively utilizes information from both noisy multi-labels and unlabeled data. With the proposed Noisy multi-label semi-supervised dimensionality reduction (NMLSDR) method, the noisy multi-labels are denoised and unlabeled data are labeled simultaneously via a specially designed label propagation algorithm. NMLSDR then learns a projection matrix for reducing the dimensionality by maximizing the dependence between the enlarged and denoised multi-label space and the features in the projected space. Extensive experiments on synthetic data, benchmark datasets, as well as a real-world case study, demonstrate the effectiveness of the proposed algorithm and show that it outperforms state-of-the-art multi-label feature extraction algorithms.
* 38 pages
Deep Divergence-Based Approach to Clustering
Feb 13, 2019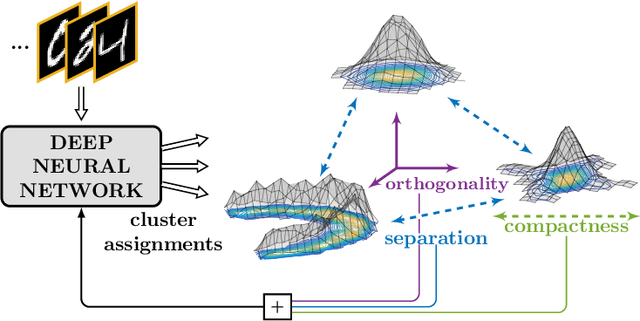
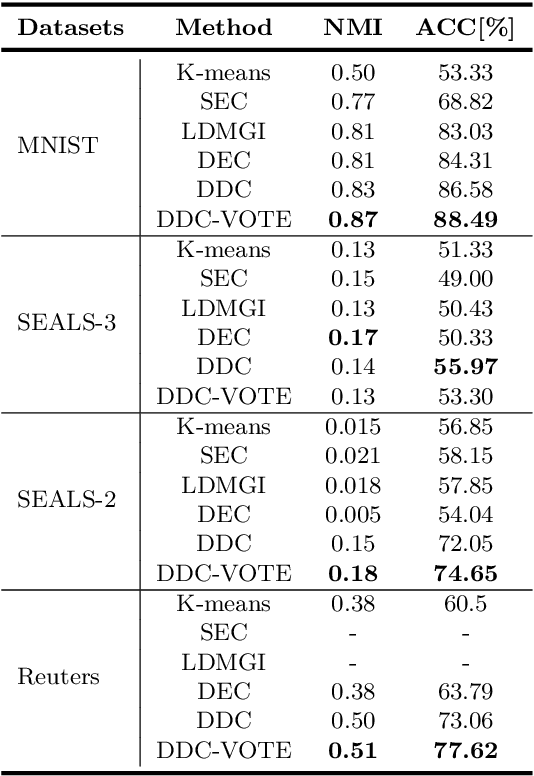
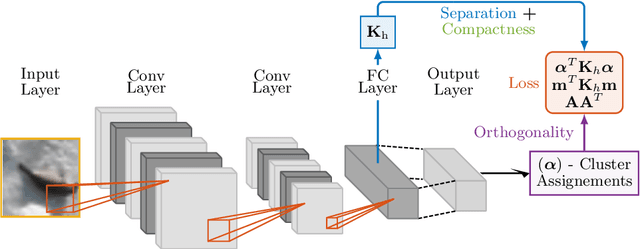
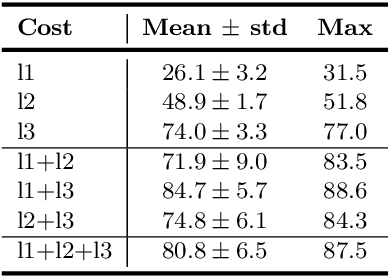
A promising direction in deep learning research consists in learning representations and simultaneously discovering cluster structure in unlabeled data by optimizing a discriminative loss function. As opposed to supervised deep learning, this line of research is in its infancy, and how to design and optimize suitable loss functions to train deep neural networks for clustering is still an open question. Our contribution to this emerging field is a new deep clustering network that leverages the discriminative power of information-theoretic divergence measures, which have been shown to be effective in traditional clustering. We propose a novel loss function that incorporates geometric regularization constraints, thus avoiding degenerate structures of the resulting clustering partition. Experiments on synthetic benchmarks and real datasets show that the proposed network achieves competitive performance with respect to other state-of-the-art methods, scales well to large datasets, and does not require pre-training steps.
Recurrent Deep Divergence-based Clustering for simultaneous feature learning and clustering of variable length time series
Nov 29, 2018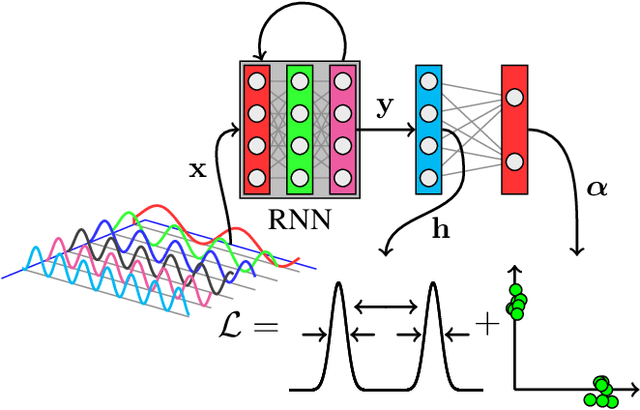
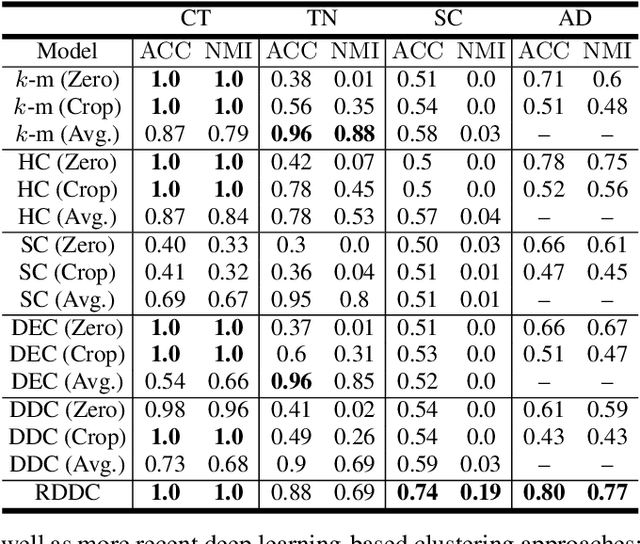
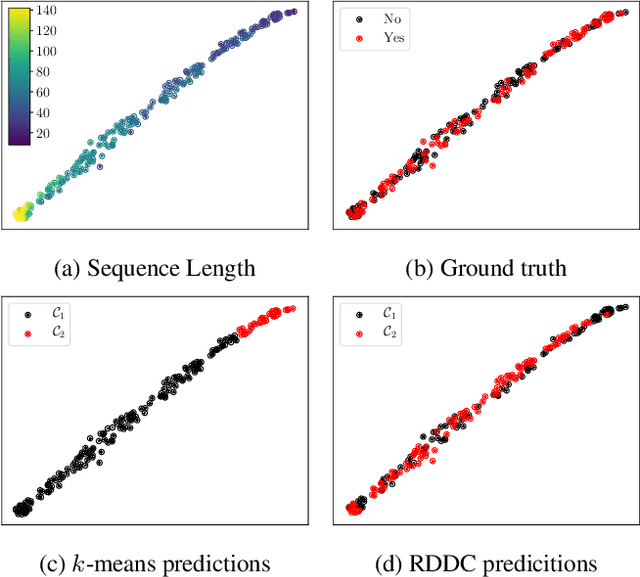
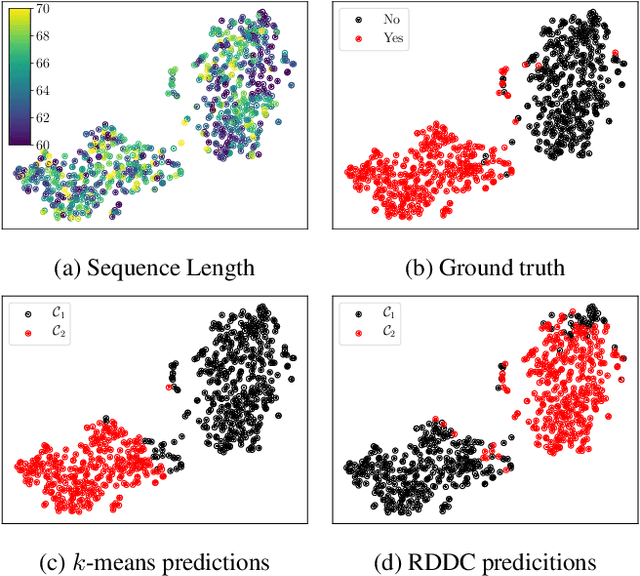
The task of clustering unlabeled time series and sequences entails a particular set of challenges, namely to adequately model temporal relations and variable sequence lengths. If these challenges are not properly handled, the resulting clusters might be of suboptimal quality. As a key solution, we present a joint clustering and feature learning framework for time series based on deep learning. For a given set of time series, we train a recurrent network to represent, or embed, each time series in a vector space such that a divergence-based clustering loss function can discover the underlying cluster structure in an end-to-end manner. Unlike previous approaches, our model inherently handles multivariate time series of variable lengths and does not require specification of a distance-measure in the input space. On a diverse set of benchmark datasets we illustrate that our proposed Recurrent Deep Divergence-based Clustering approach outperforms, or performs comparable to, previous approaches.