 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lovasz-Bregman Divergence and connections to rank aggregation, clustering, and web ranking
Aug 09, 2014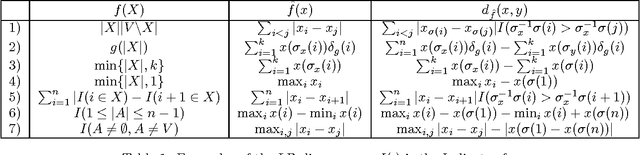

We extend the recently introduced theory of Lovasz-Bregman (LB) divergences (Iyer & Bilmes 2012) in several ways. We show that they represent a distortion between a "score" and an "ordering", thus providing a new view of rank aggregation and order based clustering with interesting connections to web ranking. We show how the LB divergences have a number of properties akin to many permutation based metrics, and in fact have as special cases forms very similar to the Kendall-tau metric. We also show how the LB divergences subsume a number of commonly used ranking measures in information retrieval, like NDCG and AUC. Unlike the traditional permutation based metrics, however, the LB divergence naturally captures a notion of "confidence" in the orderings, thus providing a new representation to applications involving aggregating scores as opposed to just orderings. We show how a number of recently used web ranking models are forms of Lovasz-Bregman rank aggregation and also observe that a natural form of Mallow's model using the LB divergence has been used as conditional ranking models for the "Learning to Rank" problem.
Algorithms for Approximate Minimization of the Difference Between Submodular Functions, with Applications
Aug 09, 2014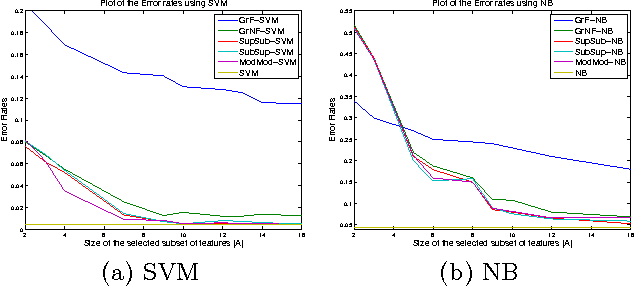
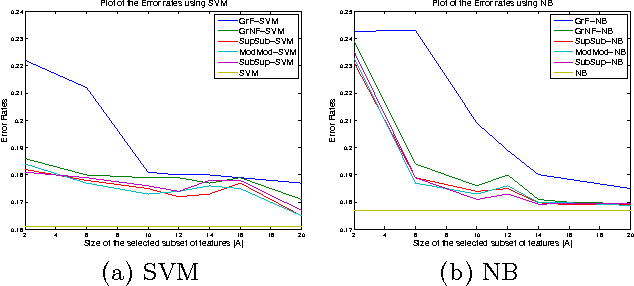
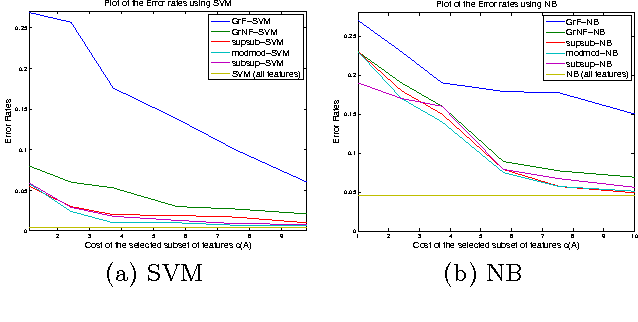
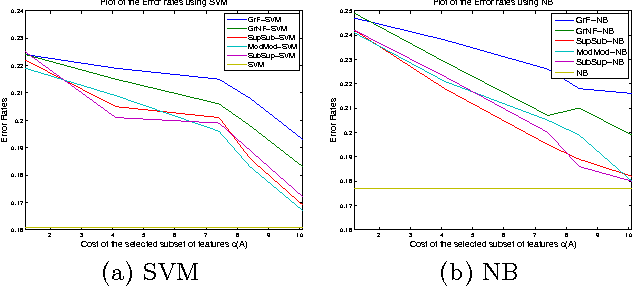
We extend the work of Narasimhan and Bilmes [30] for minimizing set functions representable as a dierence between submodular functions. Similar to [30], our new algorithms are guaranteed to monotonically reduce the objective function at every step. We empirically and theoretically show that the per-iteration cost of our algorithms is much less than [30], and our algorithms can be used to efficiently minimize a dierence between submodular functions under various combinatorial constraints, a problem not previously addressed. We provide computational bounds and a hardness result on the multiplicative inapproximability of minimizing the dierence between submodular functions. We show, however, that it is possible to give worst-case additive bounds by providing a polynomial time computable lower-bound on the minima. Finally we show how a number of machine learning problems can be modeled as minimizing the dierence between submodular functions. We experimentally show the validity of our algorithms by testing them on the problem of feature selection with submodular cost features.
Curvature and Optimal Algorithms for Learning and Minimizing Submodular Functions
Nov 08, 2013

We investigate three related and important problems connected to machine learning: approximating a submodular function everywhere, learning a submodular function (in a PAC-like setting [53]), and constrained minimization of submodular functions. We show that the complexity of all three problems depends on the 'curvature' of the submodular function, and provide lower and upper bounds that refine and improve previous results [3, 16, 18, 52]. Our proof techniques are fairly generic. We either use a black-box transformation of the function (for approximation and learning), or a transformation of algorithms to use an appropriate surrogate function (for minimization). Curiously, curvature has been known to influence approximations for submodular maximization [7, 55], but its effect on minimization, approximation and learning has hitherto been open. We complete this picture, and also support our theoretical claims by empirical results.
Submodular Optimization with Submodular Cover and Submodular Knapsack Constraints
Nov 08, 2013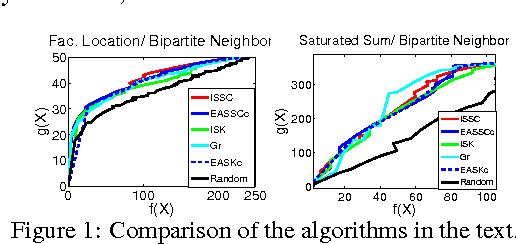
We investigate two new optimization problems -- minimizing a submodular function subject to a submodular lower bound constraint (submodular cover) and maximizing a submodular function subject to a submodular upper bound constraint (submodular knapsack). We are motivated by a number of real-world applications in machine learning including sensor placement and data subset selection, which require maximizing a certain submodular function (like coverage or diversity) while simultaneously minimizing another (like cooperative cost). These problems are often posed as minimizing the difference between submodular functions [14, 35] which is in the worst case inapproximable. We show, however, that by phrasing these problems as constrained optimization, which is more natural for many applications, we achieve a number of bounded approximation guarantees. We also show that both these problems are closely related and an approximation algorithm solving one can be used to obtain an approximation guarantee for the other. We provide hardness results for both problems thus showing that our approximation factors are tight up to log-factors. Finally, we empirically demonstrate the performance and good scalability properties of our algorithms.
Fast Semidifferential-based Submodular Function Optimization
Aug 05, 2013We present a practical and powerful new framework for both unconstrained and constrained submodular function optimization based on discrete semidifferentials (sub- and super-differentials). The resulting algorithms, which repeatedly compute and then efficiently optimize submodular semigradients, offer new and generalize many old methods for submodular optimization. Our approach, moreover, takes steps towards providing a unifying paradigm applicable to both submodular min- imization and maximization, problems that historically have been treated quite distinctly. The practicality of our algorithms is important since interest in submodularity, owing to its natural and wide applicability, has recently been in ascendance within machine learning. We analyze theoretical properties of our algorithms for minimization and maximization, and show that many state-of-the-art maximization algorithms are special cases. Lastly, we complement our theoretical analyses with supporting empirical experiments.