 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODOC: A Modular Interface for Flexible Interlinking of Text Retrieval and Text Generation Functions
Aug 26, 2024



Large Language Models (LLMs) produce eloquent texts but often the content they generate needs to be verified. Traditional information retrieval systems can assist with this task, but most systems have not been designed with LLM-generated queries in mind. As such, there is a compelling need for integrated systems that provide both retrieval and generation functionality within a single user interface. We present MODOC, a modular user interface that leverages the capabilities of LLMs and provides assistance with detecting their confabulations, promoting integrity in scientific writing. MODOC represents a significant step forward in scientific writing assistance. Its modular architecture supports flexible functions for retrieving information and for writing and generating text in a single, user-friendly interface.
TinyBird-ML: An ultra-low Power Smart Sensor Node for Bird Vocalization Analysis and Syllable Classification
Jul 31, 2024



Animal vocalisations serve a wide range of vital functions. Although it is possible to record animal vocalisations with external microphones, more insights are gained from miniature sensors mounted directly on animals' backs. We present TinyBird-ML; a wearable sensor node weighing only 1.4 g for acquiring, processing, and wirelessly transmitting acoustic signals to a host system using Bluetooth Low Energy. TinyBird-ML embeds low-latency tiny machine learning algorithms for song syllable classification. To optimize battery lifetime of TinyBird-ML during fault-tolerant continuous recordings, we present an efficient firmware and hardware design. We make use of standard lossy compression schemes to reduce the amount of data sent over the Bluetooth antenna, which increases battery lifetime by 70% without negative impact on offline sound analysis. Furthermore, by not transmitting signals during silent periods, we further increase battery lifetime. One advantage of our sensor is that it allows for closed-loop experiments in the microsecond range by processing sounds directly on the device instead of streaming them to a computer. We demonstrate this capability by detecting and classifying song syllables with minimal latency and a syllable error rate of 7%, using a light-weight neural network that runs directly on the sensor node itself. Thanks to our power-saving hardware and software design, during continuous operation at a sampling rate of 16 kHz, the sensor node achieves a lifetime of 25 hours on a single size 13 zinc-air battery.
MemSum-DQA: Adapting An Efficient Long Document Extractive Summarizer for Document Question Answering
Oct 10, 2023We introduce MemSum-DQA, an efficient system for document question answering (DQA) that leverages MemSum, a long document extractive summarizer. By prefixing each text block in the parsed document with the provided question and question type, MemSum-DQA selectively extracts text blocks as answers from documents. On full-document answering tasks, this approach yields a 9% improvement in exact match accuracy over prior state-of-the-art baselines. Notably, MemSum-DQA excels in addressing questions related to child-relationship understanding, underscoring the potential of extractive summarization techniques for DQA tasks.
SciLit: A Platform for Joint Scientific Literature Discovery, Summarization and Citation Generation
Jun 06, 2023Scientific writing involves retrieving, summarizing, and citing relevant papers, which can be time-consuming processes in large and rapidly evolving fields. By making these processes inter-operable, natural language processing (NLP) provides opportunities for creating end-to-end assistive writing tools. We propose SciLit, a pipeline that automatically recommends relevant papers, extracts highlights, and suggests a reference sentence as a citation of a paper, taking into consideration the user-provided context and keywords. SciLit efficiently recommends papers from large databases of hundreds of millions of papers using a two-stage pre-fetching and re-ranking literature search system that flexibly deals with addition and removal of a paper database. We provide a convenient user interface that displays the recommended papers as extractive summaries and that offers abstractively-generated citing sentences which are aligned with the provided context and which mention the chosen keyword(s). Our assistive tool for literature discovery and scientific writing is available at https://scilit.vercel.app
Unsupervised Scientific Abstract Segmentation with Normalized Mutual Information
May 19, 2023



The abstracts of scientific papers consist of premises and conclusions. Structured abstracts explicitly highlight the conclusion sentences, whereas non-structured abstracts may have conclusion sentences at uncertain positions. This implicit nature of conclusion positions makes the automatic segmentation of scientific abstracts into premises and conclusions a challenging task. In this work, we empirically explore using Normalized Mutual Information (NMI) for abstract segmentation. We consider each abstract as a recurrent cycle of sentences and place segmentation boundaries by greedily optimizing the NMI score between premises and conclusions. On non-structured abstracts, our proposed unsupervised approach GreedyCAS achieves the best performance across all evaluation metrics; on structured abstracts, GreedyCAS outperforms all baseline methods measured by $P_k$. The strong correlation of NMI to our evaluation metrics reveals the effectiveness of NMI for abstract segmentation.
Balanced Deep CCA for Bird Vocalization Detection
Nov 17, 2022Event detection improves when events are captured by two different modalities rather than just one. But to train detection systems on multiple modalities is challenging, in particular when there is abundance of unlabelled data but limited amounts of labeled data. We develop a novel self-supervised learning technique for multi-modal data that learns (hidden) correlations between simultaneously recorded microphone (sound) signals and accelerometer (body vibration) signals. The key objective of this work is to learn useful embeddings associated with high performance in downstream event detection tasks when labeled data is scarce and the audio events of interest (songbird vocalizations) are sparse. We base our approach on deep canonical correlation analysis (DCCA) that suffers from event sparseness. We overcome the sparseness of positive labels by first learning a data sampling model from the labelled data and by applying DCCA on the output it produces. This method that we term balanced DCCA (b-DCCA) improves the performance of the unsupervised embeddings on the downstream supervised audio detection task compared to classsical DCCA. Because data labels are frequently imbalanced, our method might be of broad utility in low-resource scenarios.
Controllable Citation Text Generation
Nov 14, 2022



The aim of citation generation is usually to automatically generate a citation sentence that refers to a chosen paper in the context of a manuscript. However, a rigid citation generation process is at odds with an author's desire to control the generated text based on certain attributes, such as 1) the citation intent of e.g. either introducing background information or comparing results; 2) keywords that should appear in the citation text; or 3) specific sentences in the cited paper that characterize the citation content. To provide these degrees of freedom, we present a controllable citation generation system. In data from a large corpus, we first parse the attributes of each citation sentence and use these as additional input sources during training of the BART-based abstractive summarizer. We further develop an attribute suggestion module that infers the citation intent and suggests relevant keywords and sentences that users can select to tune the generation. Our framework gives users more control over generated citations, outperforming citation generation models without attribute awareness in both ROUGE and human evaluations.
Local Citation Recommendation with Hierarchical-Attention Text Encoder and SciBERT-based Reranking
Dec 02, 2021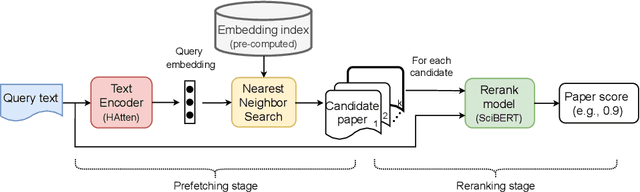
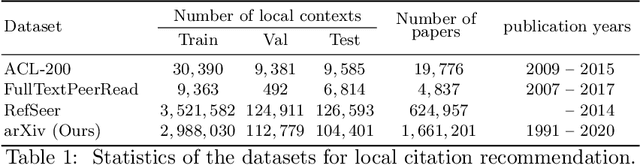
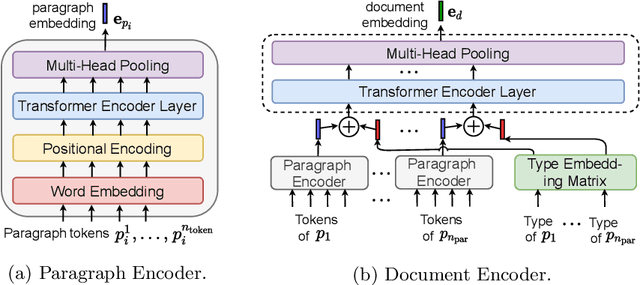
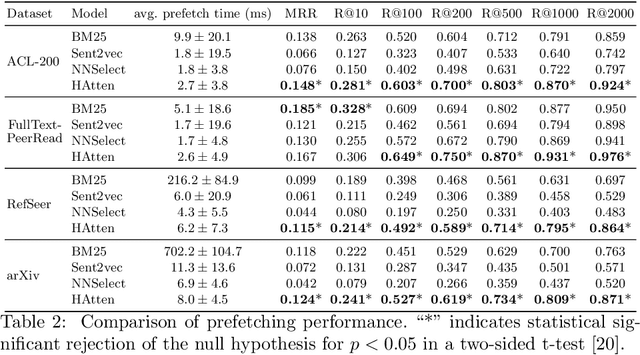
The goal of local citation recommendation is to recommend a missing reference from the local citation context and optionally also from the global context. To balance the tradeoff between speed and accuracy of citation recommendation in the context of a large-scale paper database, a viable approach is to first prefetch a limited number of relevant documents using efficient ranking methods and then to perform a fine-grained reranking using more sophisticated models. In that vein, BM25 has been found to be a tough-to-beat approach to prefetching, which is why recent work has focused mainly on the reranking step. Even so, we explore prefetching with nearest neighbor search among text embeddings constructed by a hierarchical attention network. When coupled with a SciBERT reranker fine-tuned on local citation recommendation tasks, our hierarchical Attention encoder (HAtten) achieves high prefetch recall for a given number of candidates to be reranked. Consequently, our reranker needs to rerank fewer prefetch candidates, yet still achieves state-of-the-art performance on various local citation recommendation datasets such as ACL-200, FullTextPeerRead, RefSeer, and arXiv.
MemSum: Extractive Summarization of Long Documents using Multi-step Episodic Markov Decision Processes
Jul 19, 2021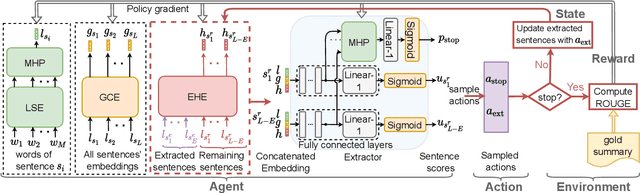
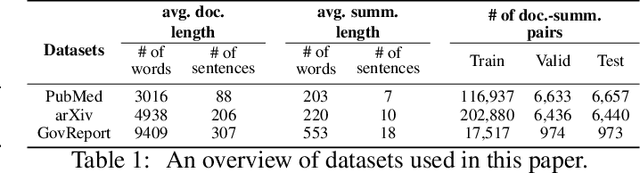
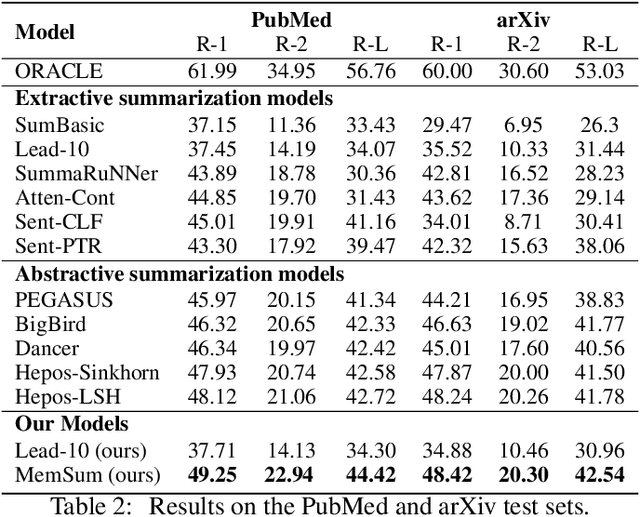
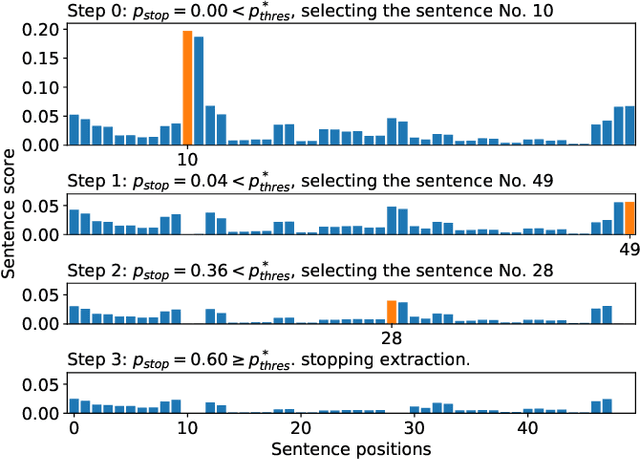
We introduce MemSum (Multi-step Episodic Markov decision process extractive SUMmarizer), a reinforcement-learning-based extractive summarizer enriched at any given time step with information on the current extraction history. Similar to previous models in this vein, MemSum iteratively selects sentences into the summary. Our innovation is in considering a broader information set when summarizing that would intuitively also be used by humans in this task: 1) the text content of the sentence, 2) the global text context of the rest of the document, and 3) the extraction history consisting of the set of sentences that have already been extracted. With a lightweight architecture, MemSum nonetheless obtains state-of-the-art test-set performance (ROUGE score) on long document datasets (PubMed, arXiv, and GovReport). Supporting analysis demonstrates that the added awareness of extraction history gives MemSum robustness against redundancy in the source document.
Character-Level Translation with Self-attention
Apr 30, 2020



We explore the suitability of self-attention models for character-level neural machine translation. We test the standard transformer model, as well as a novel variant in which the encoder block combines information from nearby characters using convolutions. We perform extensive experiments on WMT and UN datasets, testing both bilingual and multilingual translation to English using up to three input languages (French, Spanish, and Chinese). Our transformer variant consistently outperforms the standard transformer at the character-level and converges faster while learning more robust character-level alignments.