 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Mining Embeddings: Learning Vector Representations for Petri Nets
Apr 26, 2024



Process mining offers powerful techniques for discovering, analyzing, and enhancing real-world business processes. In this context, Petri nets provide an expressive means of modeling process behavior. However, directly analyzing and comparing intricate Petri net presents challenges. This study introduces PetriNet2Vec, a novel unsupervised methodology based on Natural Language Processing concepts inspired by Doc2Vec and designed to facilitate the effective comparison, clustering, and classification of process models represented as embedding vectors. These embedding vectors allow us to quantify similarities and relationships between different process models. Our methodology was experimentally validated using the PDC Dataset, featuring 96 diverse Petri net models. We performed cluster analysis, created UMAP visualizations, and trained a decision tree to provide compelling evidence for the capability of PetriNet2Vec to discern meaningful patterns and relationships among process models and their constituent tasks. Through a series of experiments, we demonstrated that PetriNet2Vec was capable of learning the structure of Petri nets, as well as the main properties used to simulate the process models of our dataset. Furthermore, our results showcase the utility of the learned embeddings in two crucial downstream tasks within process mining enhancement: process classification and process retrieval.
Task Conditioned BERT for Joint Intent Detection and Slot-filling
Aug 11, 2023



Dialogue systems need to deal with the unpredictability of user intents to track dialogue state and the heterogeneity of slots to understand user preferences. In this paper we investigate the hypothesis that solving these challenges as one unified model will allow the transfer of parameter support data across the different tasks. The proposed principled model is based on a Transformer encoder, trained on multiple tasks, and leveraged by a rich input that conditions the model on the target inferences. Conditioning the Transformer encoder on multiple target inferences over the same corpus, i.e., intent and multiple slot types, allows learning richer language interactions than a single-task model would be able to. In fact, experimental results demonstrate that conditioning the model on an increasing number of dialogue inference tasks leads to improved results: on the MultiWOZ dataset, the joint intent and slot detection can be improved by 3.2\% by conditioning on intent, 10.8\% by conditioning on slot and 14.4\% by conditioning on both intent and slots. Moreover, on real conversations with Farfetch costumers, the proposed conditioned BERT can achieve high joint-goal and intent detection performance throughout a dialogue.
Hierarchical Qualitative Clustering: clustering mixed datasets with critical qualitative information
Jul 06, 2020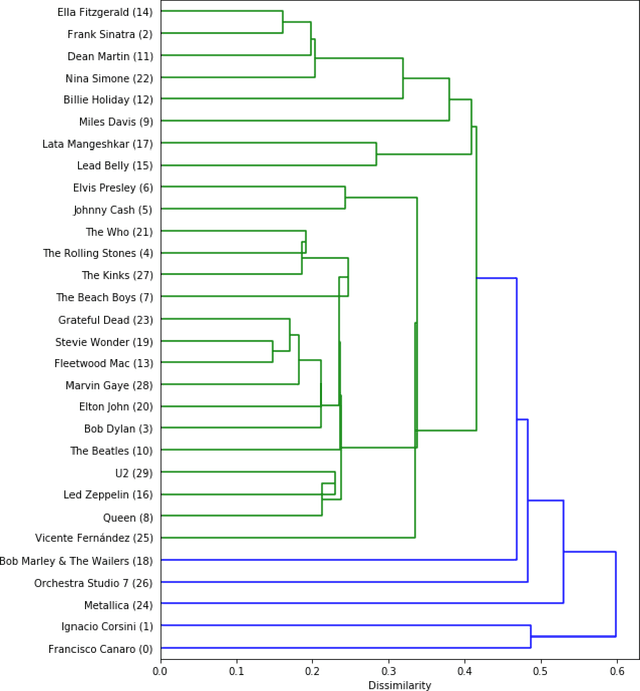
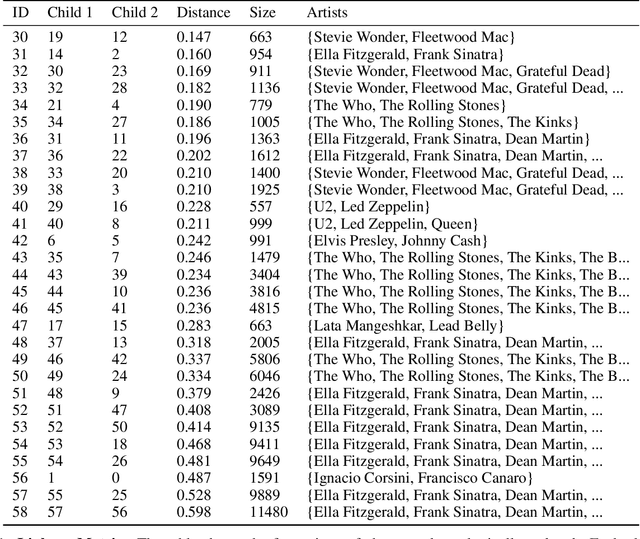
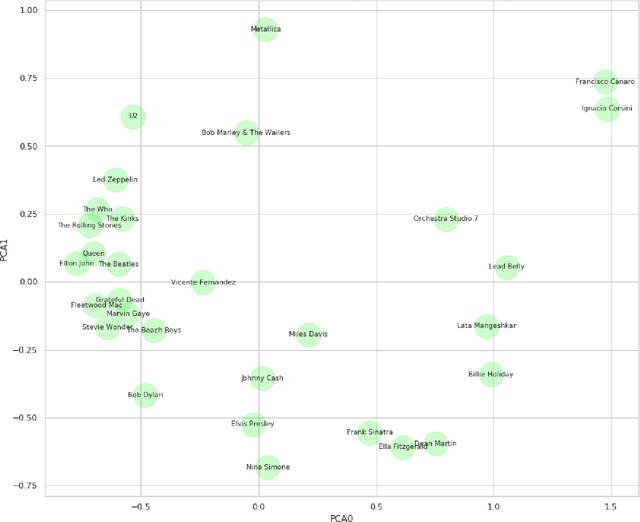
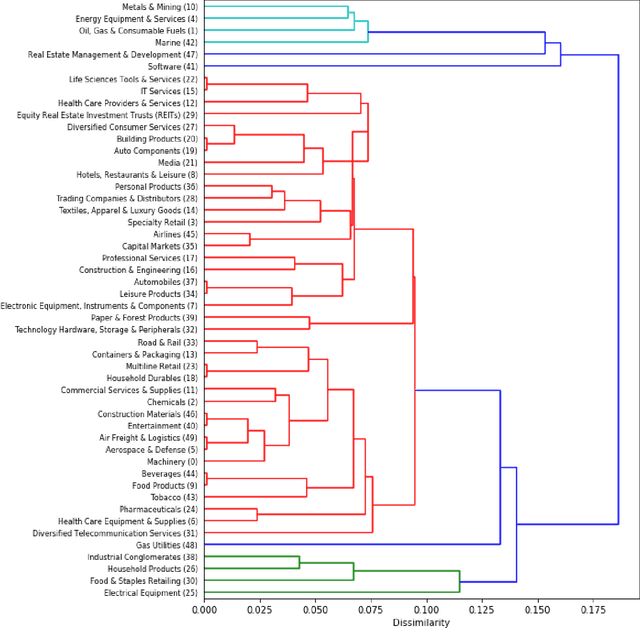
Clustering can be used to extract insights from data or to verify some of the assumptions held by the domain experts, namely data segmentation. In the literature, few methods can be applied in clustering qualitative values using the context associated with other variables present in the data, without losing interpretability. Moreover, the metrics for calculating dissimilarity between qualitative values often scale poorly for high dimensional mixed datasets. In this study, we propose a novel method for clustering qualitative values, based on Hierarchical Clustering (HQC), and using Maximum Mean Discrepancy. HQC maintains the original interpretability of the qualitative information present in the dataset. We apply HQC to two datasets. Using a mixed dataset provided by Spotify, we showcase how our method can be used for clustering music artists based on the quantitative features of thousands of songs. In addition, using financial features of companies, we cluster company industries, and discuss the implications in investment portfolios diversification.
The Data Replication Method for the Classification with Reject Option
Jul 15, 2011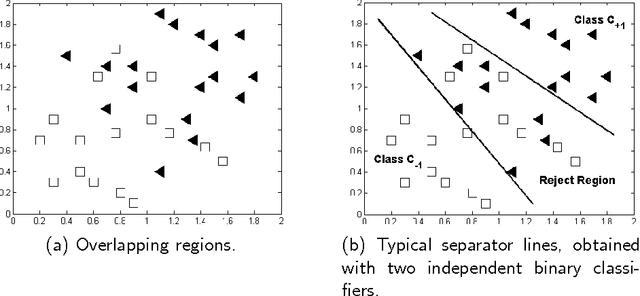
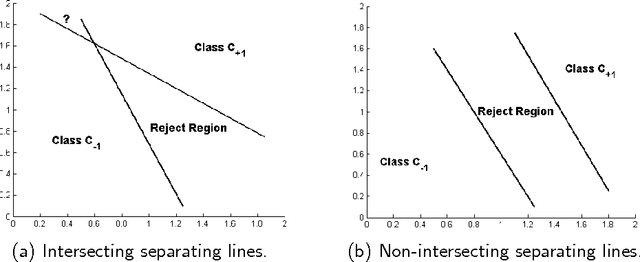
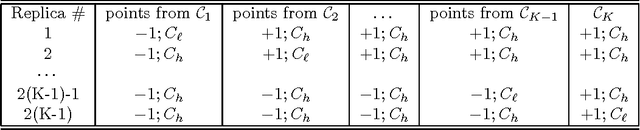
Classification is one of the most important tasks of machine learning. Although the most well studied model is the two-class problem, in many scenarios there is the opportunity to label critical items for manual revision, instead of trying to automatically classify every item. In this paper we adapt a paradigm initially proposed for the classification of ordinal data to address the classification problem with reject option. The technique reduces the problem of classifying with reject option to the standard two-class problem. The introduced method is then mapped into support vector machines and neural networks. Finally, the framework is extended to multiclass ordinal data with reject option. An experimental study with synthetic and real data sets, verifies the usefulness of the proposed approach.