 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Domain-Specific Language Models with Graph-Oriented Databases: A Paradigm Shift in Performance and Model Maintenance
Oct 04, 2024In an era dominated by data, the management and utilization of domain-specific language have emerged as critical challenges in various application domains, particularly those with industry-specific requirements. Our work is driven by the need to effectively manage and process large volumes of short text documents inherent in specific application domains. By leveraging domain-specific knowledge and expertise, our approach aims to shape factual data within these domains, thereby facilitating enhanced utilization and understanding by end-users. Central to our methodology is the integration of domain-specific language models with graph-oriented databases, facilitating seamless processing, analysis, and utilization of textual data within targeted domains. Our work underscores the transformative potential of the partnership of domain-specific language models and graph-oriented databases. This cooperation aims to assist researchers and engineers in metric usage, mitigation of latency issues, boosting explainability, enhancing debug and improving overall model performance. Moving forward, we envision our work as a guide AI engineers, providing valuable insights for the implementation of domain-specific language models in conjunction with graph-oriented databases, and additionally provide valuable experience in full-life cycle maintenance of this kind of products.
Optimization meets Big Data: A survey
Feb 03, 2021This paper reviews recent advances in big data optimization, providing the state-of-art of this emerging field. The main focus in this review are optimization techniques being applied in big data analysis environments. Integer linear programming, coordinate descent methods, alternating direction method of multipliers, simulation optimization and metaheuristics like evolutionary and genetic algorithms, particle swarm optimization, differential evolution, fireworks, bat, firefly and cuckoo search algorithms implementations are reviewed and discussed. The relation between big data optimization and software engineering topics like information work-flow styles, software architectures, and software framework is discussed. Comparative analysis in platforms being used in big data optimization environments are highlighted in order to bring a state-or-art of possible architectures and topologies.
Machine learning for improving performance in an evolutionary algorithm for minimum path with uncertain costs given by massively simulated scenarios
Feb 03, 2021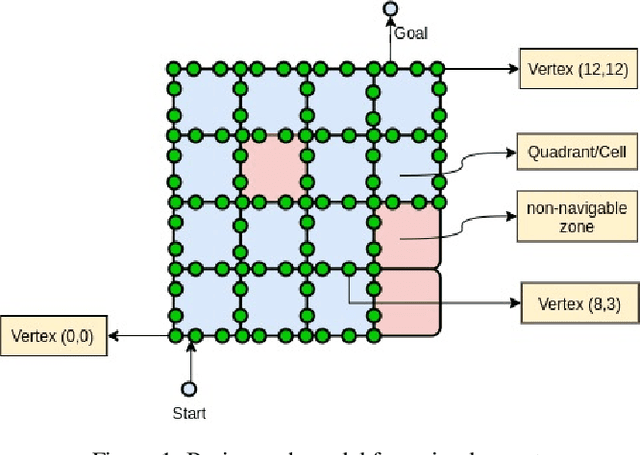
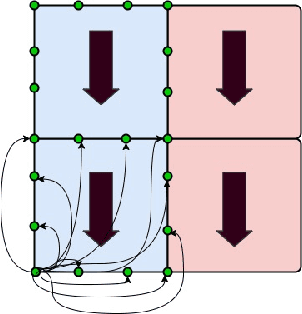
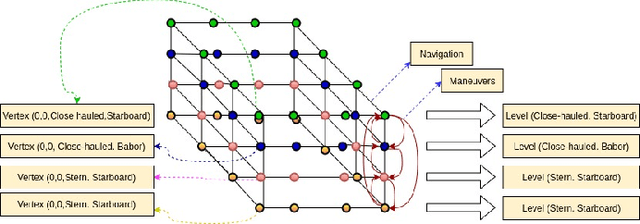
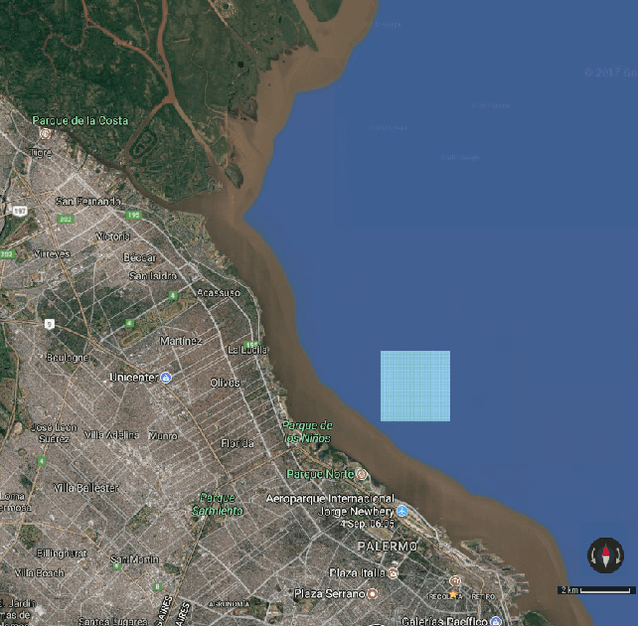
In this work we introduce an implementation for which machine learning techniques helped improve the overall performance of an evolutionary algorithm for an optimization problem, namely a variation of robust minimum-cost path in graphs. In this big data optimization problem, a path achieving a good cost in most scenarios from an available set of scenarios (generated by a simulation process) must be obtained. The most expensive task of our evolutionary algorithm, in terms of computational resources, is the evaluation of candidate paths: the fitness function must calculate the cost of the candidate path in every generated scenario. Given the large number of scenarios, this task must be implemented in a distributed environment. We implemented gradient boosting decision trees to classify candidate paths in order to identify good candidates. The cost of the not-so-good candidates is simply forecasted. We studied the training process, gain performance, accuracy, and other variables. Our computational experiments show that the computational performance was significantly improved at the expense of a limited loss of accuracy.