 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRama Chellappa
The Pursuit of Knowledge: Discovering and Localizing Novel Categories using Dual Memory
May 05, 2021

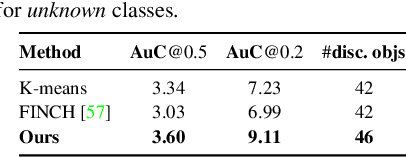
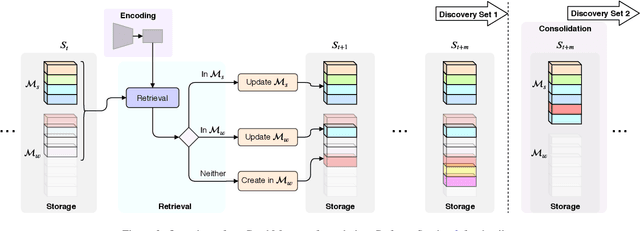

We tackle object category discovery, which is the problem of discovering and localizing novel objects in a large unlabeled dataset. While existing methods show results on datasets with less cluttered scenes and fewer object instances per image, we present our results on the challenging COCO dataset. Moreover, we argue that, rather than discovering new categories from scratch, discovery algorithms can benefit from identifying what is already known and focusing their attention on the unknown. We propose a method to use prior knowledge about certain object categories to discover new categories by leveraging two memory modules, namely Working and Semantic memory. We show the performance of our detector on the COCO minival dataset to demonstrate its in-the-wild capabilities.
Cortical Features for Defense Against Adversarial Audio Attacks
Jan 30, 2021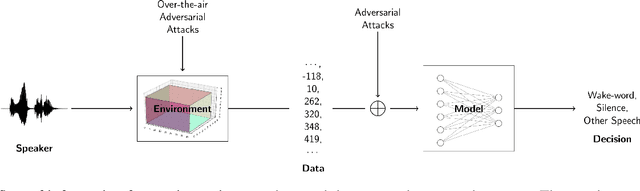
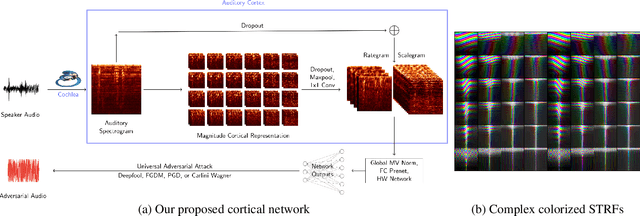

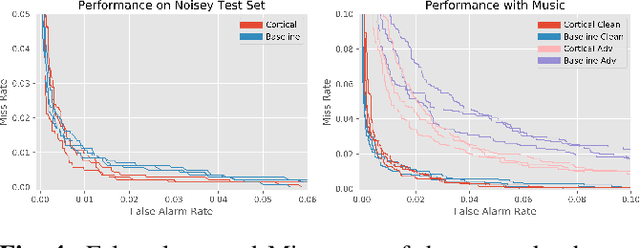
We propose using a computational model of the auditory cortex as a defense against adversarial attacks on audio. We apply several white-box iterative optimization-based adversarial attacks to an implementation of Amazon Alexa's HW network, and a modified version of this network with an integrated cortical representation, and show that the cortical features help defend against universal adversarial examples. At the same level of distortion, the adversarial noises found for the cortical network are always less effective for universal audio attacks. We make our code publicly available at https://github.com/ilyakava/py3fst.
XraySyn: Realistic View Synthesis From a Single Radiograph Through CT Priors
Dec 04, 2020

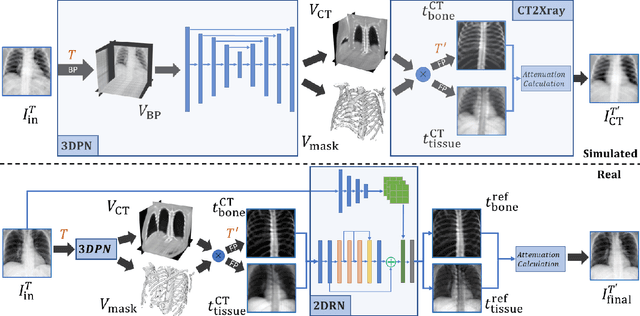

A radiograph visualizes the internal anatomy of a patient through the use of X-ray, which projects 3D information onto a 2D plane. Hence, radiograph analysis naturally requires physicians to relate the prior about 3D human anatomy to 2D radiographs. Synthesizing novel radiographic views in a small range can assist physicians in interpreting anatomy more reliably; however, radiograph view synthesis is heavily ill-posed, lacking in paired data, and lacking in differentiable operations to leverage learning-based approaches. To address these problems, we use Computed Tomography (CT) for radiograph simulation and design a differentiable projection algorithm, which enables us to achieve geometrically consistent transformations between the radiography and CT domains. Our method, XraySyn, can synthesize novel views on real radiographs through a combination of realistic simulation and finetuning on real radiographs. To the best of our knowledge, this is the first work on radiograph view synthesis. We show that by gaining an understanding of radiography in 3D space, our method can be applied to radiograph bone extraction and suppression without groundtruth bone labels.
Pose And Joint-Aware Action Recognition
Oct 16, 2020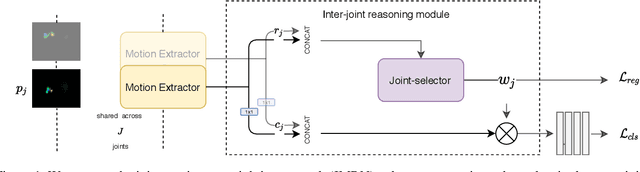
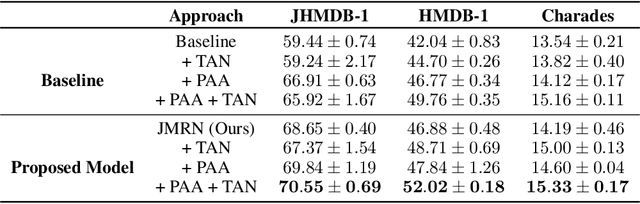
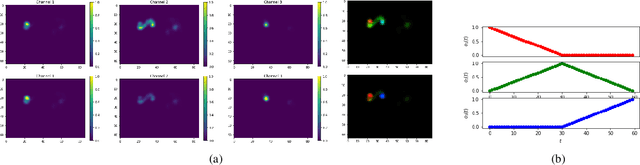
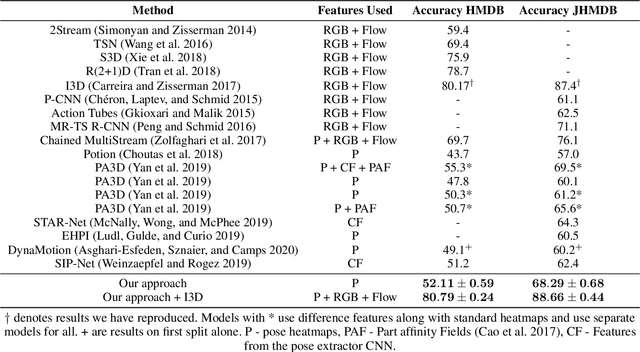
Most human action recognition systems typically consider static appearances and motion as independent streams of information. In this paper, we consider the evolution of human pose and propose a method to better capture interdependence among skeleton joints. Our model extracts motion information from each joint independently, reweighs the information and finally performs inter-joint reasoning. The effectiveness of pose and joint-based representations is strengthened using a geometry-aware data augmentation technique which jitters pose heatmaps while retaining the dynamics of the action. Our best model gives an absolute improvement of 8.19% on JHMDB, 4.31% on HMDB and 1.55 mAP on Charades datasets over state-of-the-art methods using pose heat-maps alone. Fusing with RGB and flow streams leads to improvement over state-of-the-art. Our model also outperforms the baseline on Mimetics, a dataset with out-of-context videos by 1.14% while using only pose heatmaps. Further, to filter out clips irrelevant for action recognition, we re-purpose our model for clip selection guided by pose information and show improved performance using fewer clips.
Robust Optimal Transport with Applications in Generative Modeling and Domain Adaptation
Oct 12, 2020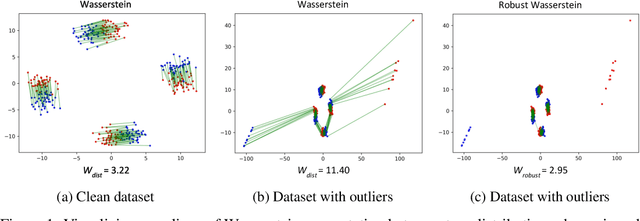
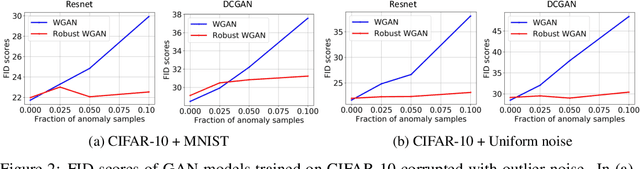

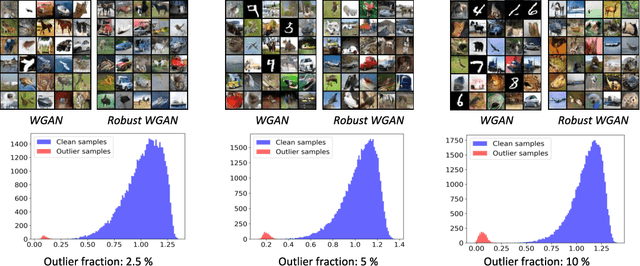
Optimal Transport (OT) distances such as Wasserstein have been used in several areas such as GANs and domain adaptation. OT, however, is very sensitive to outliers (samples with large noise) in the data since in its objective function, every sample, including outliers, is weighed similarly due to the marginal constraints. To remedy this issue, robust formulations of OT with unbalanced marginal constraints have previously been proposed. However, employing these methods in deep learning problems such as GANs and domain adaptation is challenging due to the instability of their dual optimization solvers. In this paper, we resolve these issues by deriving a computationally-efficient dual form of the robust OT optimization that is amenable to modern deep learning applications. We demonstrate the effectiveness of our formulation in two applications of GANs and domain adaptation. Our approach can train state-of-the-art GAN models on noisy datasets corrupted with outlier distributions. In particular, our optimization computes weights for training samples reflecting how difficult it is for those samples to be generated in the model. In domain adaptation, our robust OT formulation leads to improved accuracy compared to the standard adversarial adaptation methods. Our code is available at https://github.com/yogeshbalaji/robustOT.
GANs with Variational Entropy Regularizers: Applications in Mitigating the Mode-Collapse Issue
Sep 24, 2020
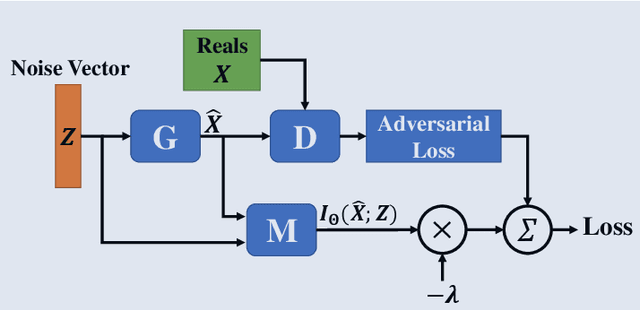
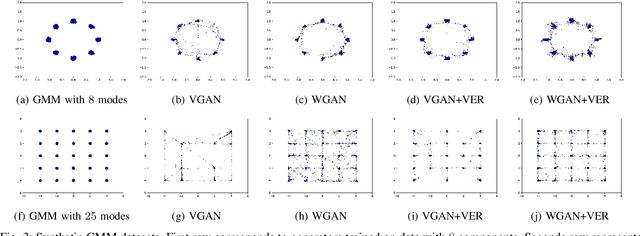
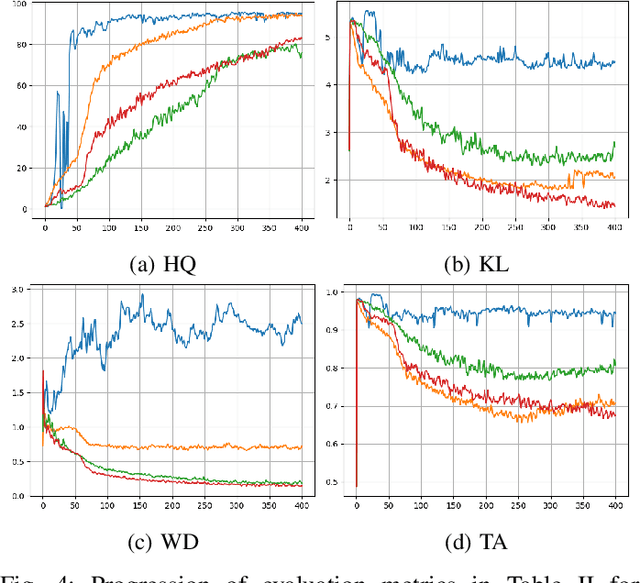
Building on the success of deep learning, Generative Adversarial Networks (GANs) provide a modern approach to learn a probability distribution from observed samples. GANs are often formulated as a zero-sum game between two sets of functions; the generator and the discriminator. Although GANs have shown great potentials in learning complex distributions such as images, they often suffer from the mode collapse issue where the generator fails to capture all existing modes of the input distribution. As a consequence, the diversity of generated samples is lower than that of the observed ones. To tackle this issue, we take an information-theoretic approach and maximize a variational lower bound on the entropy of the generated samples to increase their diversity. We call this approach GANs with Variational Entropy Regularizers (GAN+VER). Existing remedies for the mode collapse issue in GANs can be easily coupled with our proposed variational entropy regularization. Through extensive experimentation on standard benchmark datasets, we show all the existing evaluation metrics highlighting difference of real and generated samples are significantly improved with GAN+VER.
Dual Manifold Adversarial Robustness: Defense against Lp and non-Lp Adversarial Attacks
Sep 05, 2020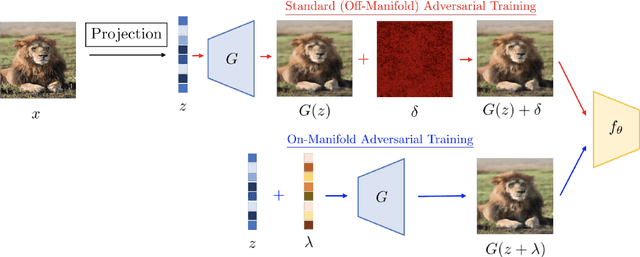



Adversarial training is a popular defense strategy against attack threat models with bounded Lp norms. However, it often degrades the model performance on normal images and the defense does not generalize well to novel attacks. Given the success of deep generative models such as GANs and VAEs in characterizing the underlying manifold of images, we investigate whether or not the aforementioned problems can be remedied by exploiting the underlying manifold information. To this end, we construct an "On-Manifold ImageNet" (OM-ImageNet) dataset by projecting the ImageNet samples onto the manifold learned by StyleGSN. For this dataset, the underlying manifold information is exact. Using OM-ImageNet, we first show that adversarial training in the latent space of images improves both standard accuracy and robustness to on-manifold attacks. However, since no out-of-manifold perturbations are realized, the defense can be broken by Lp adversarial attacks. We further propose Dual Manifold Adversarial Training (DMAT) where adversarial perturbations in both latent and image spaces are used in robustifying the model. Our DMAT improves performance on normal images, and achieves comparable robustness to the standard adversarial training against Lp attacks. In addition, we observe that models defended by DMAT achieve improved robustness against novel attacks which manipulate images by global color shifts or various types of image filtering. Interestingly, similar improvements are also achieved when the defended models are tested on out-of-manifold natural images. These results demonstrate the potential benefits of using manifold information in enhancing robustness of deep learning models against various types of novel adversarial attacks.
Visual Question Answering on Image Sets
Aug 27, 2020


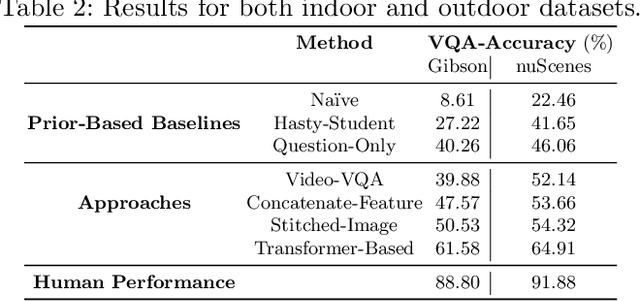
We introduce the task of Image-Set Visual Question Answering (ISVQA), which generalizes the commonly studied single-image VQA problem to multi-image settings. Taking a natural language question and a set of images as input, it aims to answer the question based on the content of the images. The questions can be about objects and relationships in one or more images or about the entire scene depicted by the image set. To enable research in this new topic, we introduce two ISVQA datasets - indoor and outdoor scenes. They simulate the real-world scenarios of indoor image collections and multiple car-mounted cameras, respectively. The indoor-scene dataset contains 91,479 human annotated questions for 48,138 image sets, and the outdoor-scene dataset has 49,617 questions for 12,746 image sets. We analyze the properties of the two datasets, including question-and-answer distributions, types of questions, biases in dataset, and question-image dependencies. We also build new baseline models to investigate new research challenges in ISVQA.
An adversarial learning algorithm for mitigating gender bias in face recognition
Jun 14, 2020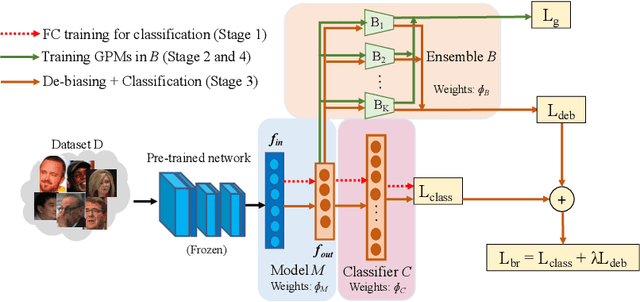
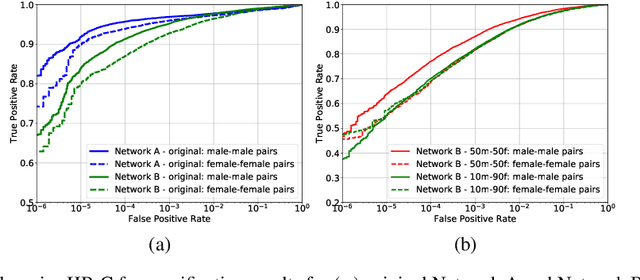
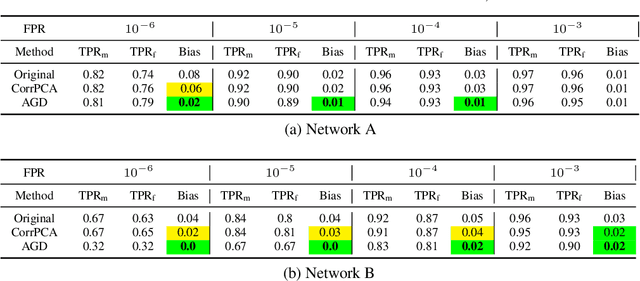

State-of-the-art face recognition networks implicitly encode gender information while being trained for identity classification. Gender is often viewed as an important face attribute to recognize humans. But, the expression of gender information in deep facial features appears to contribute to gender bias in face recognition, i.e. we find a significant difference in the recognition accuracy of DCNNs on male and female faces. We hypothesize that reducing implicitly encoded gender information will help reduce this gender bias. Therefore, we present a novel approach called `Adversarial Gender De-biasing (AGD)' to reduce the strength of gender information in face recognition features. We accomplish this by introducing a bias reducing classification loss $L_{br}$. We show that AGD significantly reduces bias, while achieving reasonable recognition performance. The results of our approach are presented on two state-of-the-art networks.