 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStance Detection with BERT Embeddings for Credibility Analysis of Information on Social Media
May 21, 2021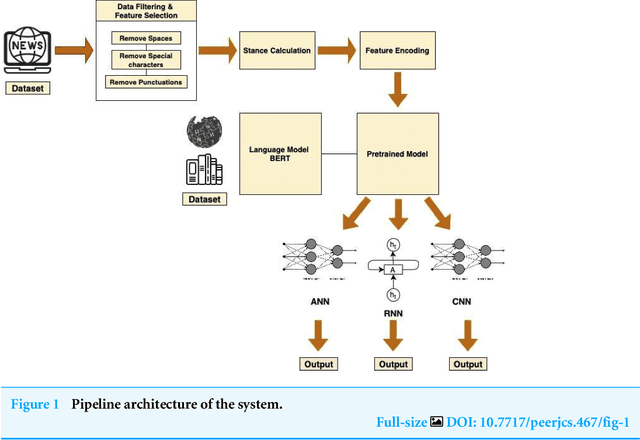
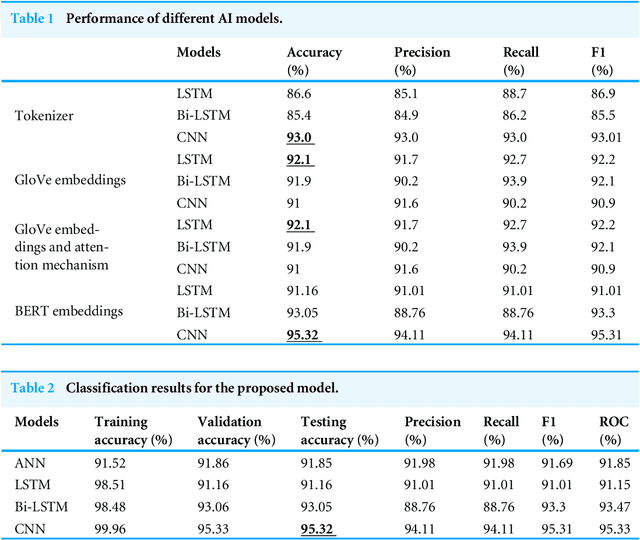
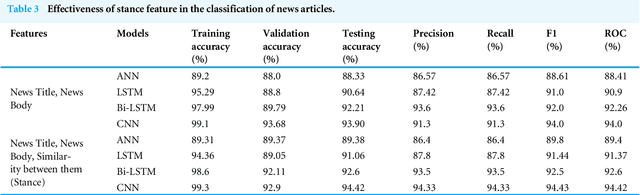
The evolution of electronic media is a mixed blessing. Due to the easy access, low cost, and faster reach of the information, people search out and devour news from online social networks. In contrast, the increasing acceptance of social media reporting leads to the spread of fake news. This is a minacious problem that causes disputes and endangers societal stability and harmony. Fake news spread has gained attention from researchers due to its vicious nature. proliferation of misinformation in all media, from the internet to cable news, paid advertising and local news outlets, has made it essential for people to identify the misinformation and sort through the facts. Researchers are trying to analyze the credibility of information and curtail false information on such platforms. Credibility is the believability of the piece of information at hand. Analyzing the credibility of fake news is challenging due to the intent of its creation and the polychromatic nature of the news. In this work, we propose a model for detecting fake news. Our method investigates the content of the news at the early stage i.e. when the news is published but is yet to be disseminated through social media. Our work interprets the content with automatic feature extraction and the relevance of the text pieces. In summary, we introduce stance as one of the features along with the content of the article and employ the pre-trained contextualized word embeddings BERT to obtain the state-of-art results for fake news detection. The experiment conducted on the real-world dataset indicates that our model outperforms the previous work and enables fake news detection with an accuracy of 95.32%.
A Review on Explainability in Multimodal Deep Neural Nets
May 18, 2021
Artificial Intelligence techniques powered by deep neural nets have achieved much success in several application domains, most significantly and notably in the Computer Vision applications and Natural Language Processing tasks. Surpassing human-level performance propelled the research in the applications where different modalities amongst language, vision, sensory, text play an important role in accurate predictions and identification. Several multimodal fusion methods employing deep learning models are proposed in the literature. Despite their outstanding performance, the complex, opaque and black-box nature of the deep neural nets limits their social acceptance and usability. This has given rise to the quest for model interpretability and explainability, more so in the complex tasks involving multimodal AI methods. This paper extensively reviews the present literature to present a comprehensive survey and commentary on the explainability in multimodal deep neural nets, especially for the vision and language tasks. Several topics on multimodal AI and its applications for generic domains have been covered in this paper, including the significance, datasets, fundamental building blocks of the methods and techniques, challenges, applications, and future trends in this domain
* 24 pages 6 figures
Comparison of machine learning and deep learning techniques in promoter prediction across diverse species
May 17, 2021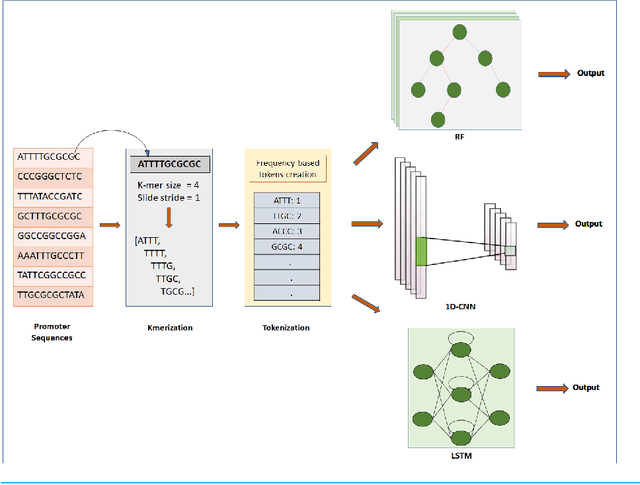

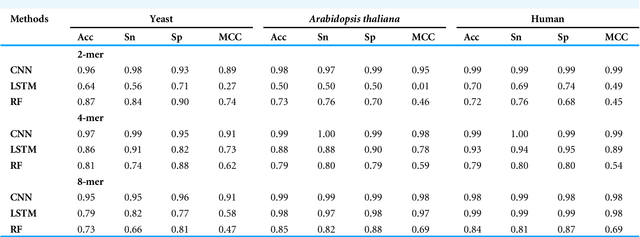
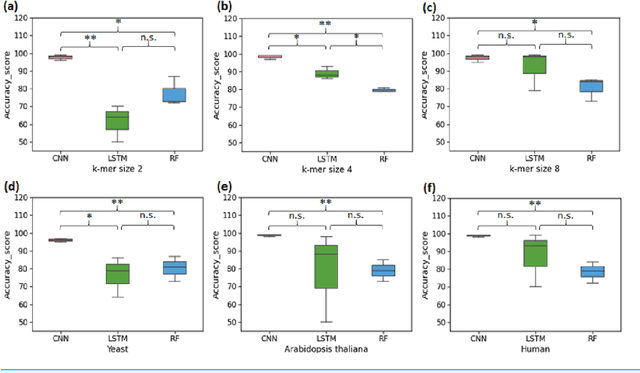
Gene promoters are the key DNA regulatory elements positioned around the transcription start sites and are responsible for regulating gene transcription process. Various alignment-based, signal-based and content-based approaches are reported for the prediction of promoters. However, since all promoter sequences do not show explicit features, the prediction performance of these techniques is poor. Therefore, many machine learning and deep learning models have been proposed for promoter prediction. In this work, we studied methods for vector encoding and promoter classification using genome sequences of three distinct higher eukaryotes viz. yeast (Saccharomyces cerevisiae), A. thaliana (plant) and human (Homo sapiens). We compared one-hot vector encoding method with frequency-based tokenization (FBT) for data pre-processing on 1-D Convolutional Neural Network (CNN) model. We found that FBT gives a shorter input dimension reducing the training time without affecting the sensitivity and specificity of classification. We employed the deep learning techniques, mainly CNN and recurrent neural network with Long Short Term Memory (LSTM) and random forest (RF) classifier for promoter classification at k-mer sizes of 2, 4 and 8. We found CNN to be superior in classification of promoters from non-promoter sequences (binary classification) as well as species-specific classification of promoter sequences (multiclass classification). In summary, the contribution of this work lies in the use of synthetic shuffled negative dataset and frequency-based tokenization for pre-processing. This study provides a comprehensive and generic framework for classification tasks in genomic applications and can be extended to various classification problems.
* 17 pages, 4 figures, 4 tables
Role of Artificial Intelligence in Detection of Hateful Speech for Hinglish Data on Social Media
May 11, 2021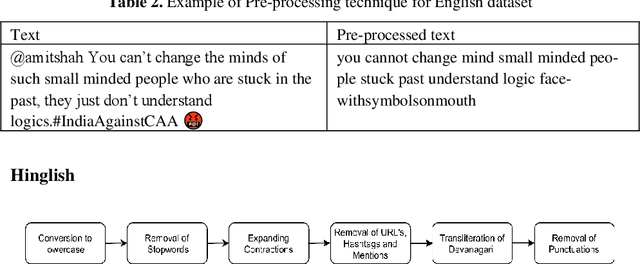

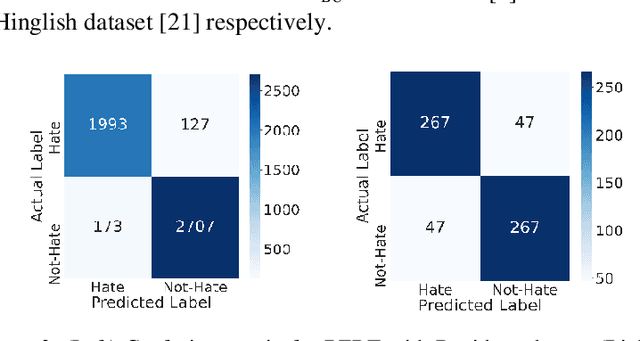

Social networking platforms provide a conduit to disseminate our ideas, views and thoughts and proliferate information. This has led to the amalgamation of English with natively spoken languages. Prevalence of Hindi-English code-mixed data (Hinglish) is on the rise with most of the urban population all over the world. Hate speech detection algorithms deployed by most social networking platforms are unable to filter out offensive and abusive content posted in these code-mixed languages. Thus, the worldwide hate speech detection rate of around 44% drops even more considering the content in Indian colloquial languages and slangs. In this paper, we propose a methodology for efficient detection of unstructured code-mix Hinglish language. Fine-tuning based approaches for Hindi-English code-mixed language are employed by utilizing contextual based embeddings such as ELMo (Embeddings for Language Models), FLAIR, and transformer-based BERT (Bidirectional Encoder Representations from Transformers). Our proposed approach is compared against the pre-existing methods and results are compared for various datasets. Our model outperforms the other methods and frameworks.
ARiA: Utilizing Richard's Curve for Controlling the Non-monotonicity of the Activation Function in Deep Neural Nets
May 22, 2018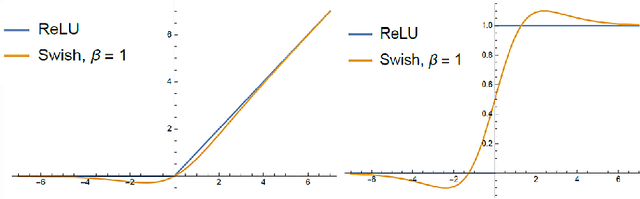
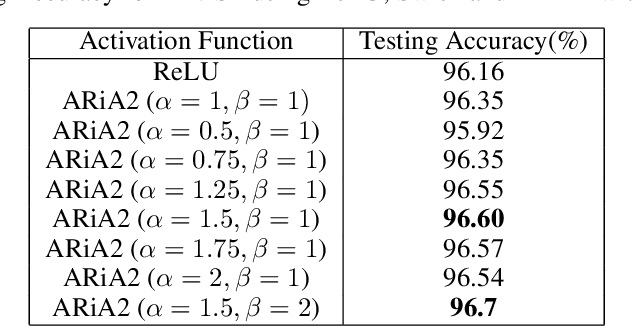
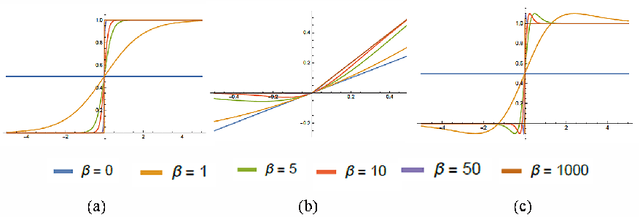

This work introduces a novel activation unit that can be efficiently employed in deep neural nets (DNNs) and performs significantly better than the traditional Rectified Linear Units (ReLU). The function developed is a two parameter version of the specialized Richard's Curve and we call it Adaptive Richard's Curve weighted Activation (ARiA). This function is non-monotonous, analogous to the newly introduced Swish, however allows a precise control over its non-monotonous convexity by varying the hyper-parameters. We first demonstrate the mathematical significance of the two parameter ARiA followed by its application to benchmark problems such as MNIST, CIFAR-10 and CIFAR-100, where we compare the performance with ReLU and Swish units. Our results illustrate a significantly superior performance on all these datasets, making ARiA a potential replacement for ReLU and other activations in DNNs.