 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrateeth Nayak
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022
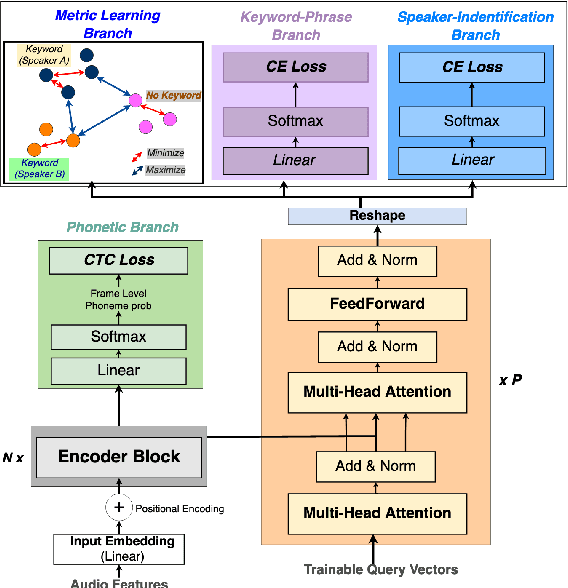
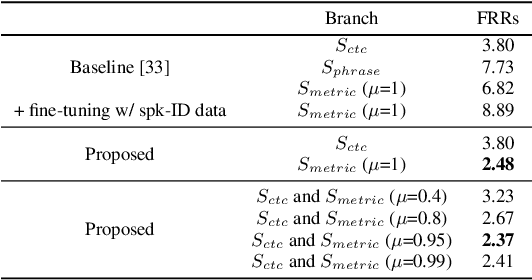
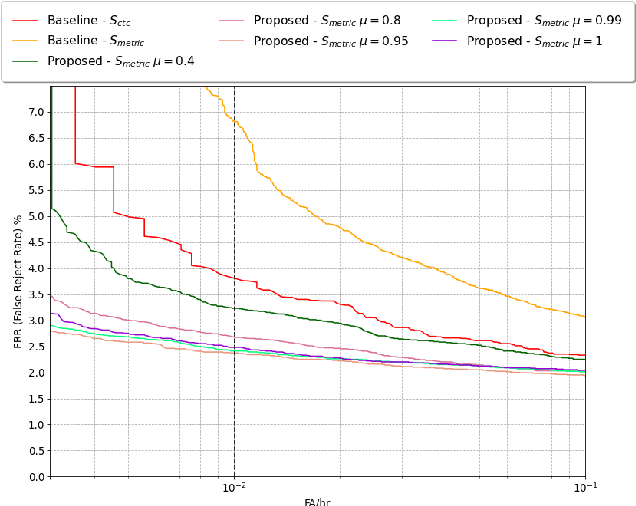
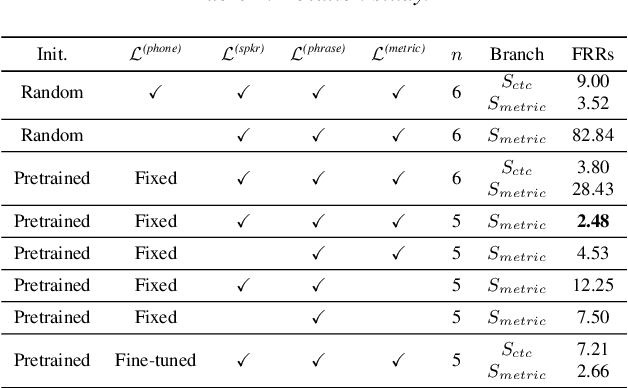
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Zero-Shot Learning with Knowledge Enhanced Visual Semantic Embeddings
Nov 21, 2020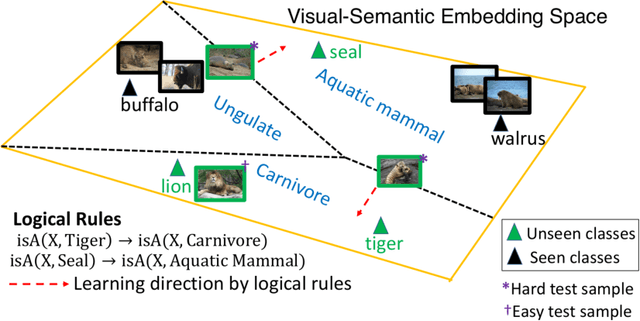
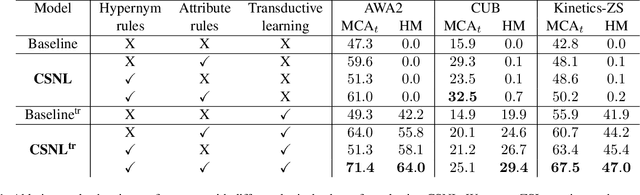
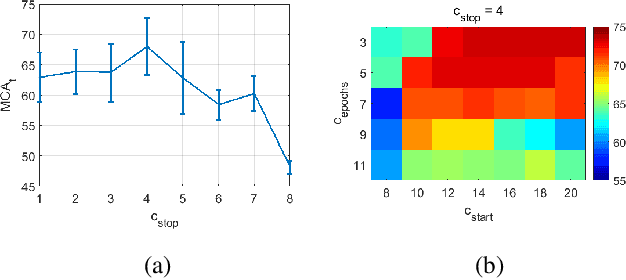
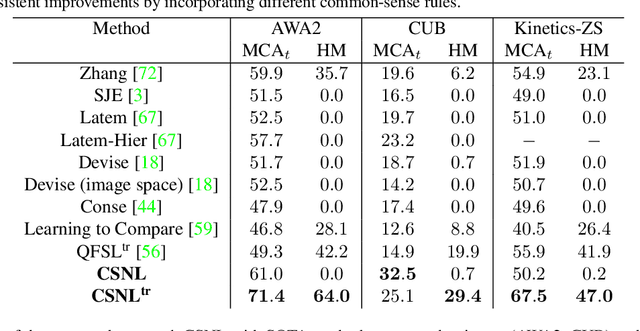
We improve zero-shot learning (ZSL) by incorporating common-sense knowledge in DNNs. We propose Common-Sense based Neuro-Symbolic Loss (CSNL) that formulates prior knowledge as novel neuro-symbolic loss functions that regularize visual-semantic embedding. CSNL forces visual features in the VSE to obey common-sense rules relating to hypernyms and attributes. We introduce two key novelties for improved learning: (1) enforcement of rules for a group instead of a single concept to take into account class-wise relationships, and (2) confidence margins inside logical operators that enable implicit curriculum learning and prevent premature overfitting. We evaluate the advantages of incorporating each knowledge source and show consistent gains over prior state-of-art methods in both conventional and generalized ZSL e.g. 11.5%, 5.5%, and 11.6% improvements on AWA2, CUB, and Kinetics respectively.
Bit Efficient Quantization for Deep Neural Networks
Oct 07, 2019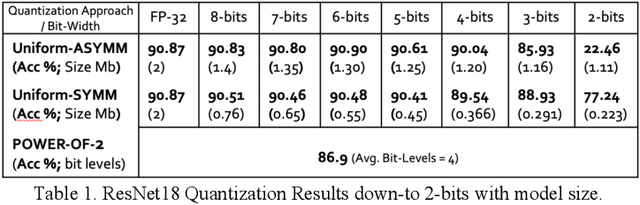
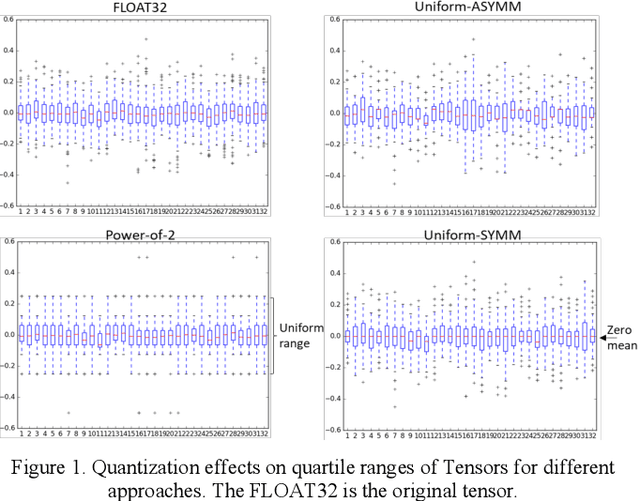
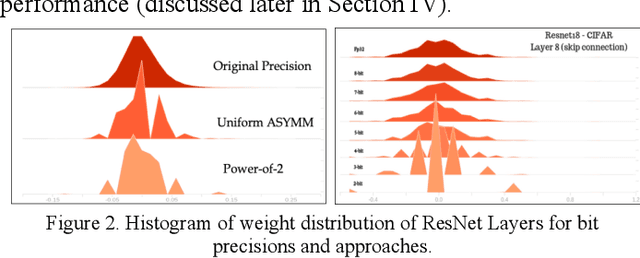

Quantization for deep neural networks have afforded models for edge devices that use less on-board memory and enable efficient low-power inference. In this paper, we present a comparison of model-parameter driven quantization approaches that can achieve as low as 3-bit precision without affecting accuracy. The post-training quantization approaches are data-free, and the resulting weight values are closely tied to the dataset distribution on which the model has converged to optimality. We show quantization results for a number of state-of-art deep neural networks (DNN) using large dataset like ImageNet. To better analyze quantization results, we describe the overall range and local sparsity of values afforded through various quantization schemes. We show the methods to lower bit-precision beyond quantization limits with object class clustering.