 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Lifelong Learning
Mar 01, 2021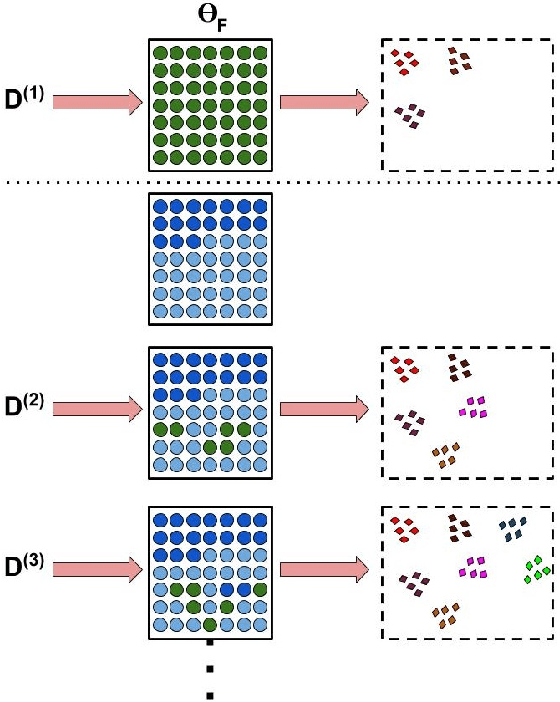
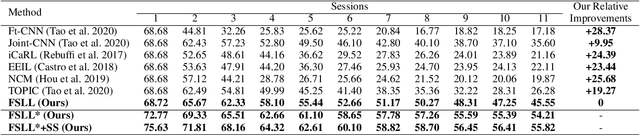
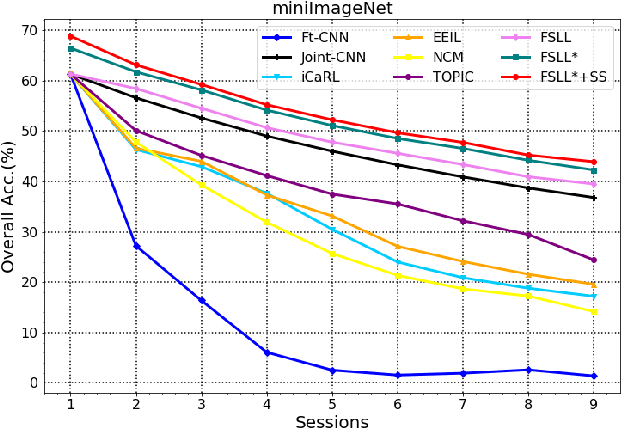

Many real-world classification problems often have classes with very few labeled training samples. Moreover, all possible classes may not be initially available for training, and may be given incrementally. Deep learning models need to deal with this two-fold problem in order to perform well in real-life situations. In this paper, we propose a novel Few-Shot Lifelong Learning (FSLL) method that enables deep learning models to perform lifelong/continual learning on few-shot data. Our method selects very few parameters from the model for training every new set of classes instead of training the full model. This helps in preventing overfitting. We choose the few parameters from the model in such a way that only the currently unimportant parameters get selected. By keeping the important parameters in the model intact, our approach minimizes catastrophic forgetting. Furthermore, we minimize the cosine similarity between the new and the old class prototypes in order to maximize their separation, thereby improving the classification performance. We also show that integrating our method with self-supervision improves the model performance significantly. We experimentally show that our method significantly outperforms existing methods on the miniImageNet, CIFAR-100, and CUB-200 datasets. Specifically, we outperform the state-of-the-art method by an absolute margin of 19.27% for the CUB dataset.
Towards Zero-Shot Learning with Fewer Seen Class Examples
Nov 14, 2020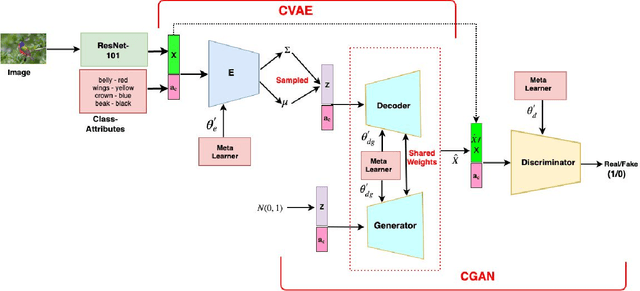
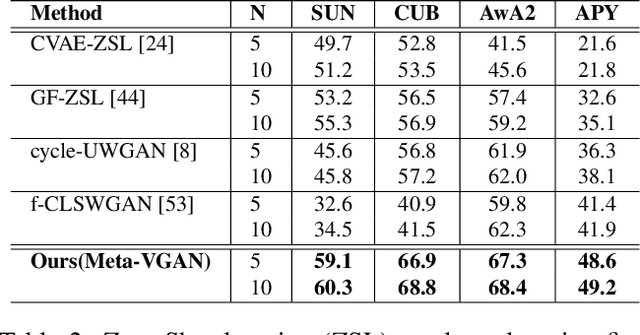
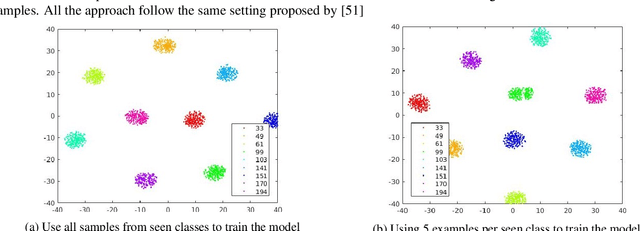
We present a meta-learning based generative model for zero-shot learning (ZSL) towards a challenging setting when the number of training examples from each \emph{seen} class is very few. This setup contrasts with the conventional ZSL approaches, where training typically assumes the availability of a sufficiently large number of training examples from each of the seen classes. The proposed approach leverages meta-learning to train a deep generative model that integrates variational autoencoder and generative adversarial networks. We propose a novel task distribution where meta-train and meta-validation classes are disjoint to simulate the ZSL behaviour in training. Once trained, the model can generate synthetic examples from seen and unseen classes. Synthesize samples can then be used to train the ZSL framework in a supervised manner. The meta-learner enables our model to generates high-fidelity samples using only a small number of training examples from seen classes. We conduct extensive experiments and ablation studies on four benchmark datasets of ZSL and observe that the proposed model outperforms state-of-the-art approaches by a significant margin when the number of examples per seen class is very small.
Generalized Adversarially Learned Inference
Jun 15, 2020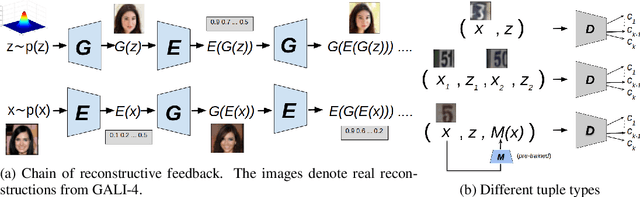
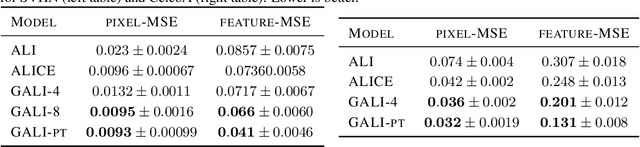
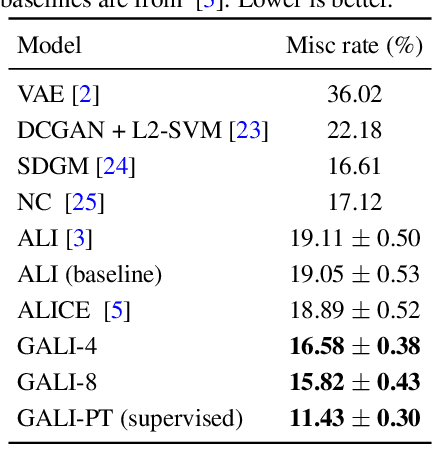

Allowing effective inference of latent vectors while training GANs can greatly increase their applicability in various downstream tasks. Recent approaches, such as ALI and BiGAN frameworks, develop methods of inference of latent variables in GANs by adversarially training an image generator along with an encoder to match two joint distributions of image and latent vector pairs. We generalize these approaches to incorporate multiple layers of feedback on reconstructions, self-supervision, and other forms of supervision based on prior or learned knowledge about the desired solutions. We achieve this by modifying the discriminator's objective to correctly identify more than two joint distributions of tuples of an arbitrary number of random variables consisting of images, latent vectors, and other variables generated through auxiliary tasks, such as reconstruction and inpainting or as outputs of suitable pre-trained models. We design a non-saturating maximization objective for the generator-encoder pair and prove that the resulting adversarial game corresponds to a global optimum that simultaneously matches all the distributions. Within our proposed framework, we introduce a novel set of techniques for providing self-supervised feedback to the model based on properties, such as patch-level correspondence and cycle consistency of reconstructions. Through comprehensive experiments, we demonstrate the efficacy, scalability, and flexibility of the proposed approach for a variety of tasks.
P-SIF: Document Embeddings Using Partition Averaging
May 18, 2020


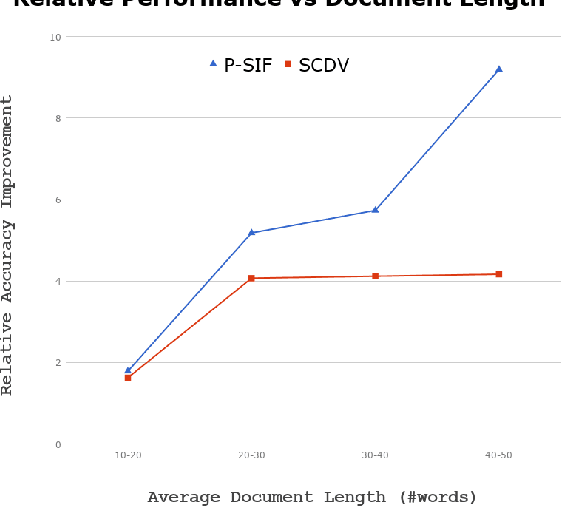
Simple weighted averaging of word vectors often yields effective representations for sentences which outperform sophisticated seq2seq neural models in many tasks. While it is desirable to use the same method to represent documents as well, unfortunately, the effectiveness is lost when representing long documents involving multiple sentences. One of the key reasons is that a longer document is likely to contain words from many different topics; hence, creating a single vector while ignoring all the topical structure is unlikely to yield an effective document representation. This problem is less acute in single sentences and other short text fragments where the presence of a single topic is most likely. To alleviate this problem, we present P-SIF, a partitioned word averaging model to represent long documents. P-SIF retains the simplicity of simple weighted word averaging while taking a document's topical structure into account. In particular, P-SIF learns topic-specific vectors from a document and finally concatenates them all to represent the overall document. We provide theoretical justifications on the correctness of P-SIF. Through a comprehensive set of experiments, we demonstrate P-SIF's effectiveness compared to simple weighted averaging and many other baselines.
Quantile Regularization: Towards Implicit Calibration of Regression Models
Feb 28, 2020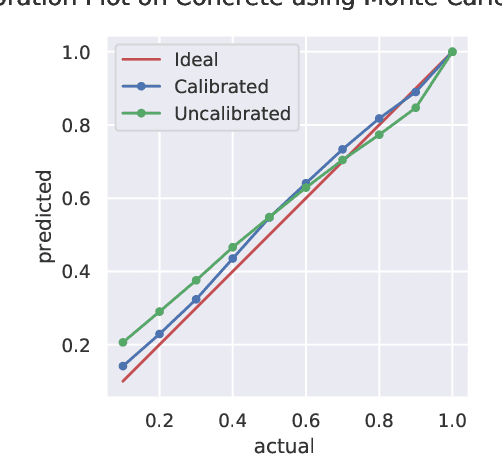
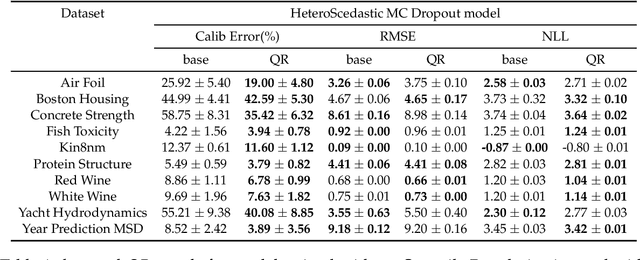
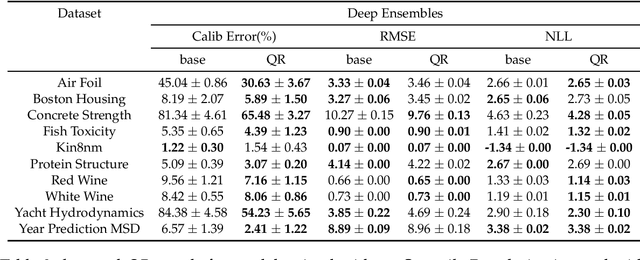
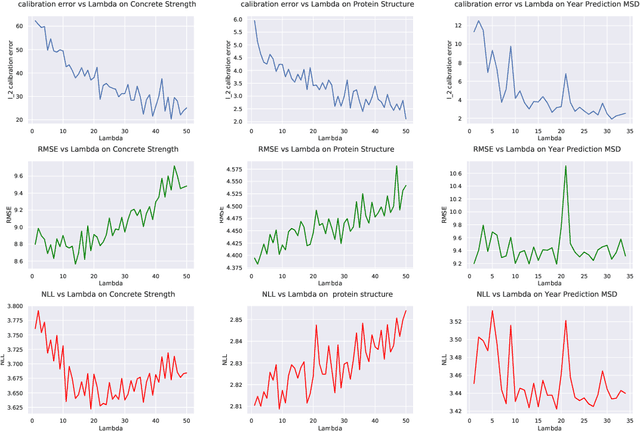
Recent works have shown that most deep learning models are often poorly calibrated, i.e., they may produce overconfident predictions that are wrong. It is therefore desirable to have models that produce predictive uncertainty estimates that are reliable. Several approaches have been proposed recently to calibrate classification models. However, there is relatively little work on calibrating regression models. We present a method for calibrating regression models based on a novel quantile regularizer defined as the cumulative KL divergence between two CDFs. Unlike most of the existing approaches for calibrating regression models, which are based on post-hoc processing of the model's output and require an additional dataset, our method is trainable in an end-to-end fashion without requiring an additional dataset. The proposed regularizer can be used with any training objective for regression. We also show that post-hoc calibration methods like Isotonic Calibration sometimes compound miscalibration whereas our method provides consistently better calibrations. We provide empirical results demonstrating that the proposed quantile regularizer significantly improves calibration for regression models trained using approaches, such as Dropout VI and Deep Ensembles.
A "Network Pruning Network" Approach to Deep Model Compression
Jan 15, 2020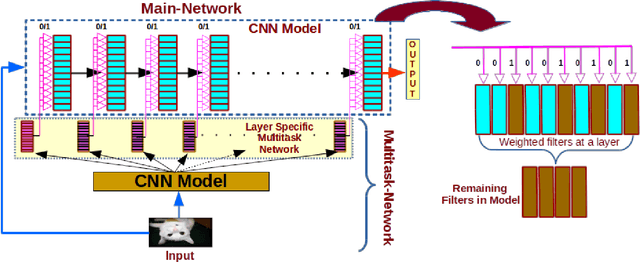
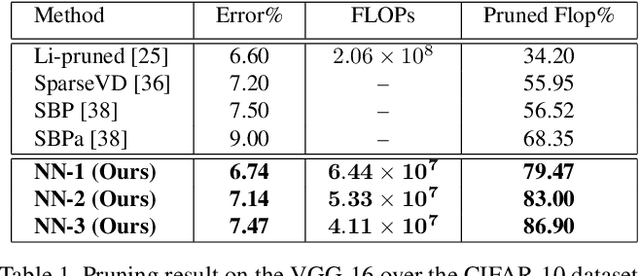
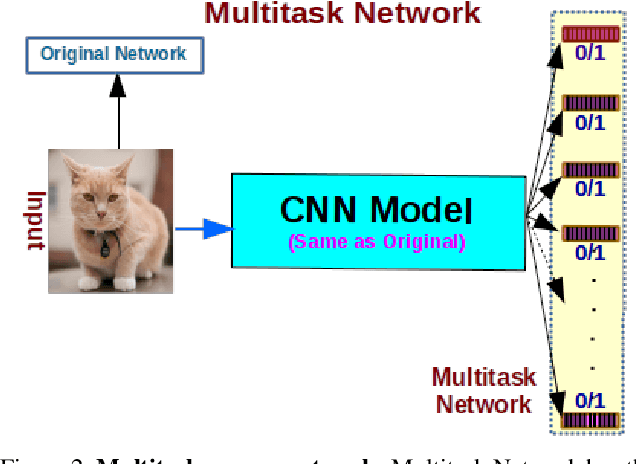
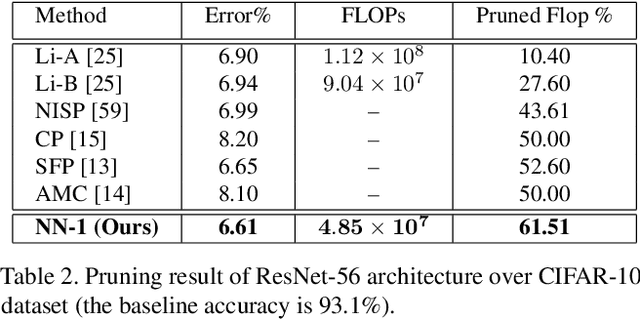
We present a filter pruning approach for deep model compression, using a multitask network. Our approach is based on learning a a pruner network to prune a pre-trained target network. The pruner is essentially a multitask deep neural network with binary outputs that help identify the filters from each layer of the original network that do not have any significant contribution to the model and can therefore be pruned. The pruner network has the same architecture as the original network except that it has a multitask/multi-output last layer containing binary-valued outputs (one per filter), which indicate which filters have to be pruned. The pruner's goal is to minimize the number of filters from the original network by assigning zero weights to the corresponding output feature-maps. In contrast to most of the existing methods, instead of relying on iterative pruning, our approach can prune the network (original network) in one go and, moreover, does not require specifying the degree of pruning for each layer (and can learn it instead). The compressed model produced by our approach is generic and does not need any special hardware/software support. Moreover, augmenting with other methods such as knowledge distillation, quantization, and connection pruning can increase the degree of compression for the proposed approach. We show the efficacy of our proposed approach for classification and object detection tasks.
Deep Attentive Ranking Networks for Learning to Order Sentences
Dec 31, 2019
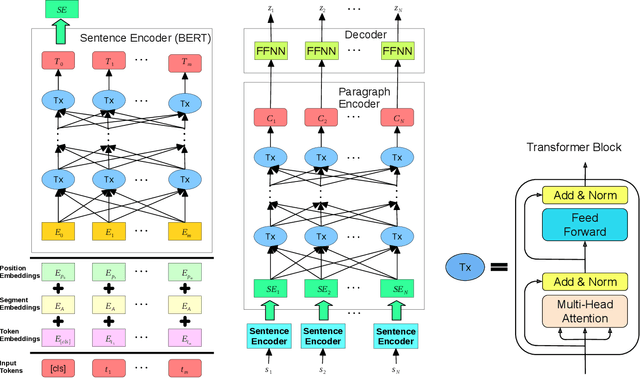
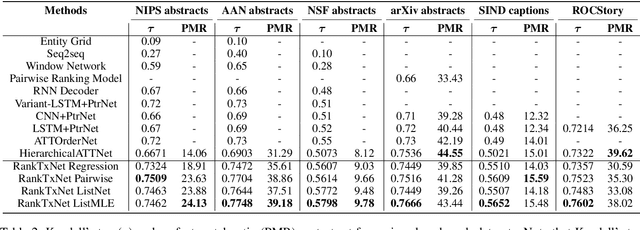

We present an attention-based ranking framework for learning to order sentences given a paragraph. Our framework is built on a bidirectional sentence encoder and a self-attention based transformer network to obtain an input order invariant representation of paragraphs. Moreover, it allows seamless training using a variety of ranking based loss functions, such as pointwise, pairwise, and listwise ranking. We apply our framework on two tasks: Sentence Ordering and Order Discrimination. Our framework outperforms various state-of-the-art methods on these tasks on a variety of evaluation metrics. We also show that it achieves better results when using pairwise and listwise ranking losses, rather than the pointwise ranking loss, which suggests that incorporating relative positions of two or more sentences in the loss function contributes to better learning.
Jointly Trained Image and Video Generation using Residual Vectors
Dec 17, 2019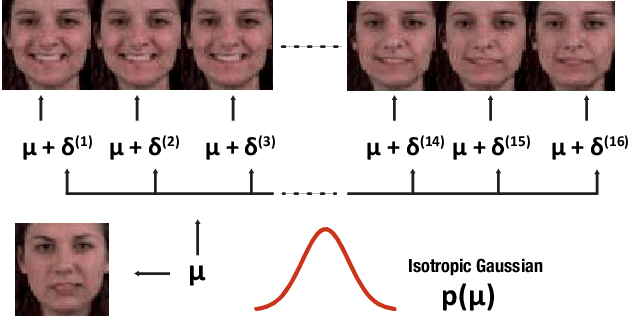
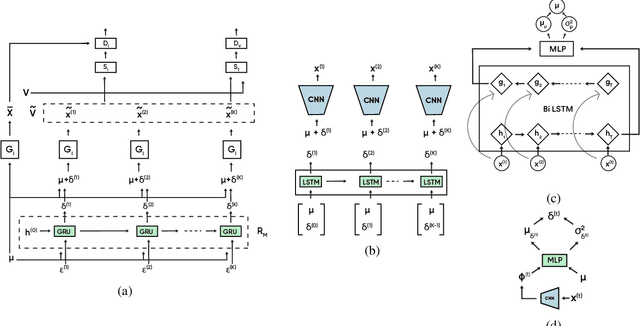
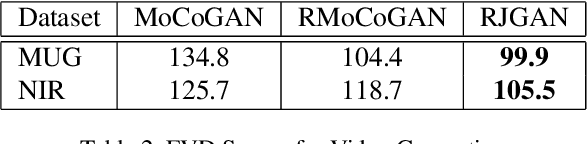

In this work, we propose a modeling technique for jointly training image and video generation models by simultaneously learning to map latent variables with a fixed prior onto real images and interpolate over images to generate videos. The proposed approach models the variations in representations using residual vectors encoding the change at each time step over a summary vector for the entire video. We utilize the technique to jointly train an image generation model with a fixed prior along with a video generation model lacking constraints such as disentanglement. The joint training enables the image generator to exploit temporal information while the video generation model learns to flexibly share information across frames. Moreover, experimental results verify our approach's compatibility with pre-training on videos or images and training on datasets containing a mixture of both. A comprehensive set of quantitative and qualitative evaluations reveal the improvements in sample quality and diversity over both video generation and image generation baselines. We further demonstrate the technique's capabilities of exploiting similarity in features across frames by applying it to a model based on decomposing the video into motion and content. The proposed model allows minor variations in content across frames while maintaining the temporal dependence through latent vectors encoding the pose or motion features.
On the relationship between multitask neural networks and multitask Gaussian Processes
Dec 12, 2019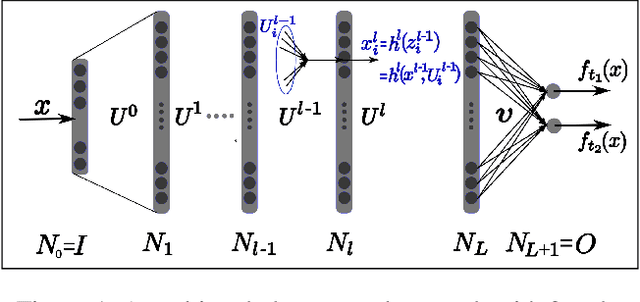
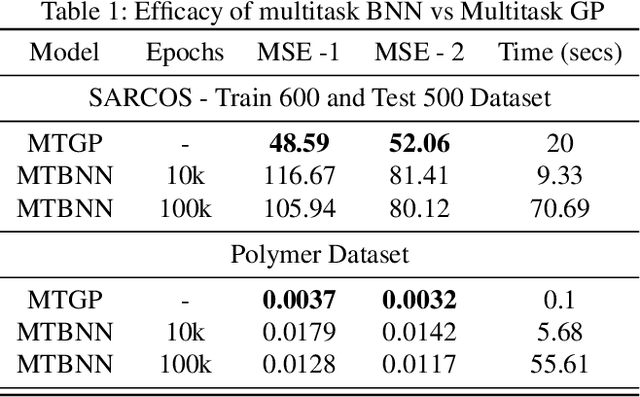
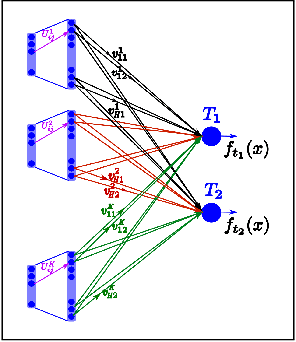
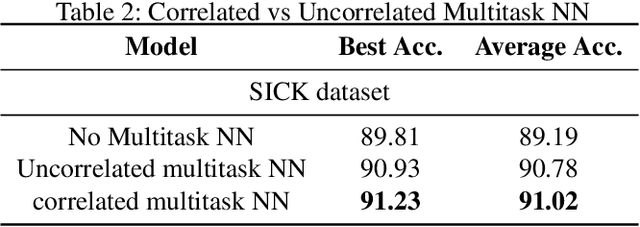
Despite the effectiveness of multitask deep neural network (MTDNN), there is a limited theoretical understanding on how the information is shared across different tasks in MTDNN. In this work, we establish a formal connection between MTDNN with infinitely-wide hidden layers and multitask Gaussian Process (GP). We derive multitask GP kernels corresponding to both single-layer and deep multitask Bayesian neural networks (MTBNN) and show that information among different tasks is shared primarily due to correlation across last layer weights of MTBNN and shared hyper-parameters, which is contrary to the popular hypothesis that information is shared because of shared intermediate layer weights. Our construction enables using multitask GP to perform efficient Bayesian inference for the equivalent MTDNN with infinitely-wide hidden layers. Prior work on the connection between deep neural networks and GP for single task settings can be seen as special cases of our construction. We also present an adaptive multitask neural network architecture that corresponds to a multitask GP with more flexible kernels, such as Linear Model of Coregionalization (LMC) and Cross-Coregionalization (CC) kernels. We provide experimental results to further illustrate these ideas on synthetic and real datasets.
Nonparametric Bayesian Structure Adaptation for Continual Learning
Dec 08, 2019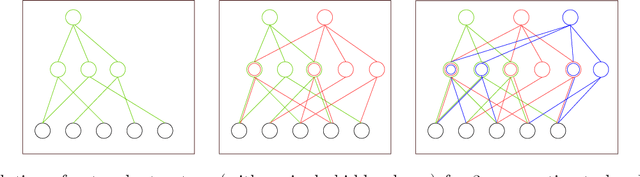
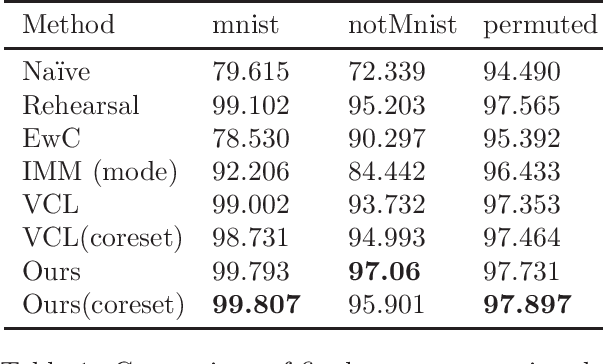
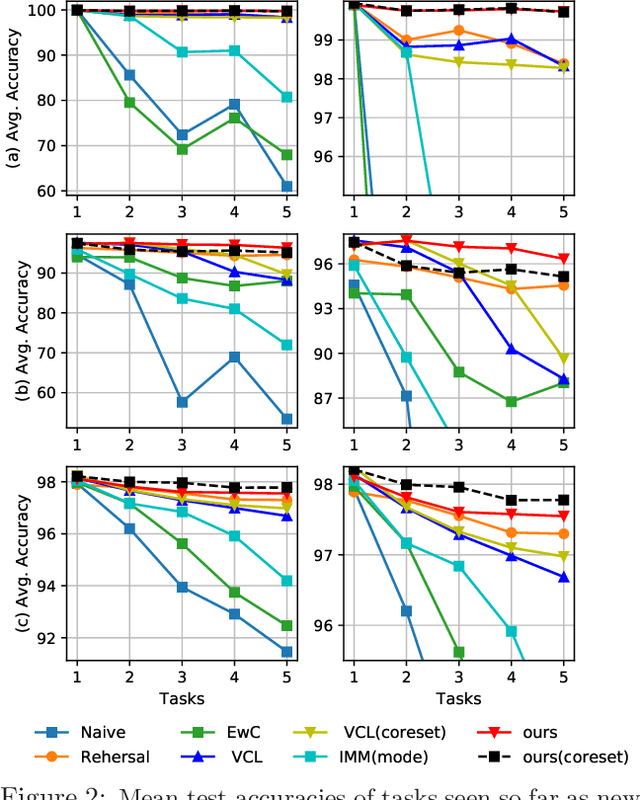
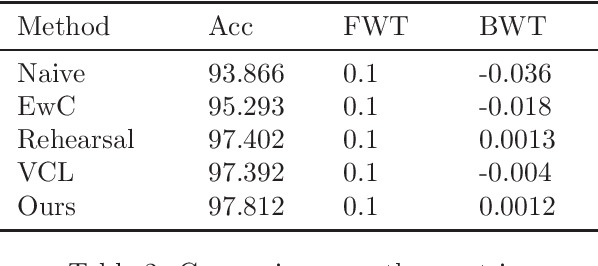
Continual Learning is a learning paradigm where machine learning models are trained with sequential or streaming tasks. Two notable directions among the recent advances in continual learning with neural networks are (i) variational Bayes based regularization by learning priors from previous tasks, and, (ii) learning the structure of deep networks to adapt to new tasks. So far, these two approaches have been orthogonal. We present a principled non-parametric Bayesian approach for learning the structure of feed-forward neural networks, addressing the shortcomings of both these approaches. In our model, the number of nodes in each hidden layer can automatically grow with the introduction of each new task, and inter-task transfer occurs through the overlapping of different sparse subsets of weights learned by different tasks. On benchmark datasets, our model performs comparably or better than the state-of-the-art approaches, while also being able to adaptively infer the evolving network structure in the continual learning setting.