 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen FastText Pays Attention: Efficient Estimation of Word Representations using Constrained Positional Weighting
Apr 21, 2021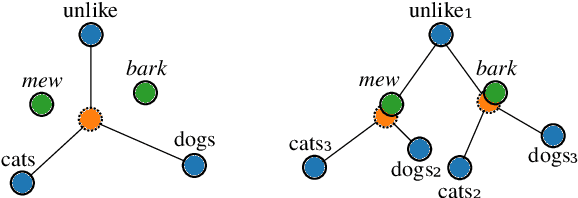
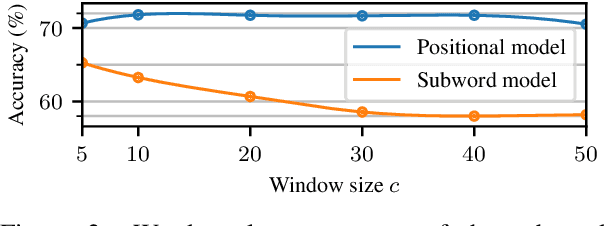
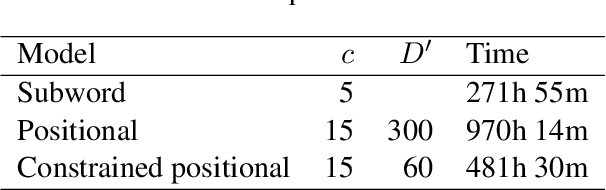
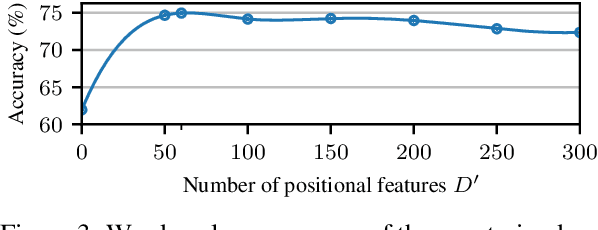
Since the seminal work of Mikolov et al. (2013a) and Bojanowski et al. (2017), word representations of shallow log-bilinear language models have found their way into many NLP applications. Mikolov et al. (2018) introduced a positional log-bilinear language model, which has characteristics of an attention-based language model and which has reached state-of-the-art performance on the intrinsic word analogy task. However, the positional model has never been evaluated on qualitative criteria or extrinsic tasks and its speed is impractical. We outline the similarities between the attention mechanism and the positional model, and we propose a constrained positional model, which adapts the sparse attention mechanism of Dai et al. (2018). We evaluate the positional and constrained positional models on three novel qualitative criteria and on the extrinsic language modeling task of Botha and Blunsom (2014). We show that the positional and constrained positional models contain interpretable information about word order and outperform the subword model of Bojanowski et al. (2017) on language modeling. We also show that the constrained positional model outperforms the positional model on language modeling and is twice as fast.
EDS-MEMBED: Multi-sense embeddings based on enhanced distributional semantic structures via a graph walk over word senses
Feb 27, 2021


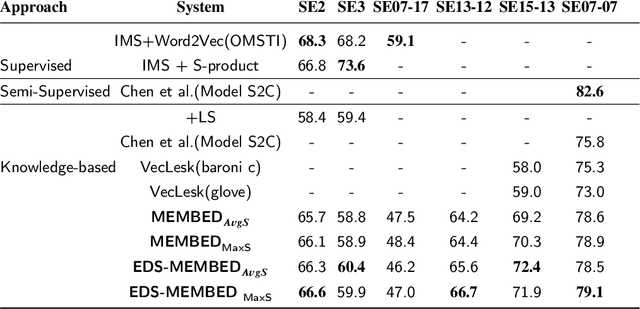
Several language applications often require word semantics as a core part of their processing pipeline, either as precise meaning inference or semantic similarity. Multi-sense embeddings (M-SE) can be exploited for this important requirement. M-SE seeks to represent each word by their distinct senses in order to resolve the conflation of meanings of words as used in different contexts. Previous works usually approach this task by training a model on a large corpus and often ignore the effect and usefulness of the semantic relations offered by lexical resources. However, even with large training data, coverage of all possible word senses is still an issue. In addition, a considerable percentage of contextual semantic knowledge are never learned because a huge amount of possible distributional semantic structures are never explored. In this paper, we leverage the rich semantic structures in WordNet using a graph-theoretic walk technique over word senses to enhance the quality of multi-sense embeddings. This algorithm composes enriched texts from the original texts. Furthermore, we derive new distributional semantic similarity measures for M-SE from prior ones. We adapt these measures to word sense disambiguation (WSD) aspect of our experiment. We report evaluation results on 11 benchmark datasets involving WSD and Word Similarity tasks and show that our method for enhancing distributional semantic structures improves embeddings quality on the baselines. Despite the small training data, it achieves state-of-the-art performance on some of the datasets.
One Size Does Not Fit All: Finding the Optimal N-gram Sizes for FastText Models across Languages
Feb 04, 2021
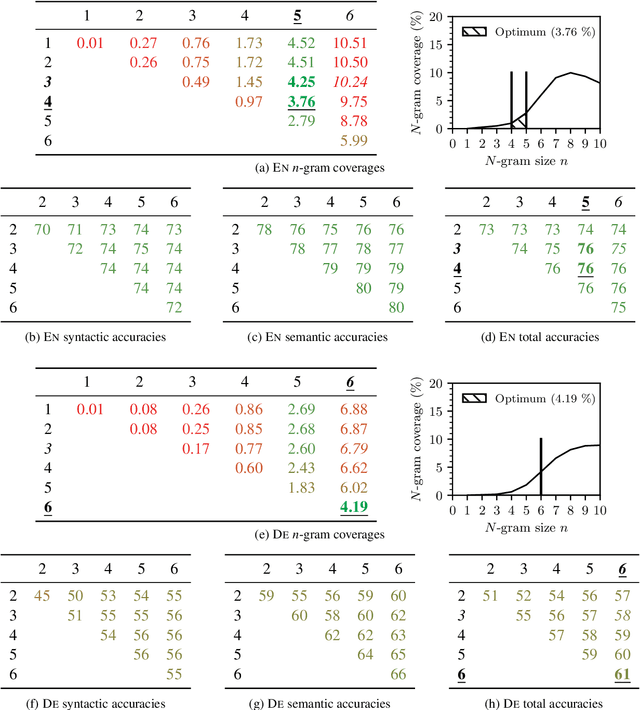
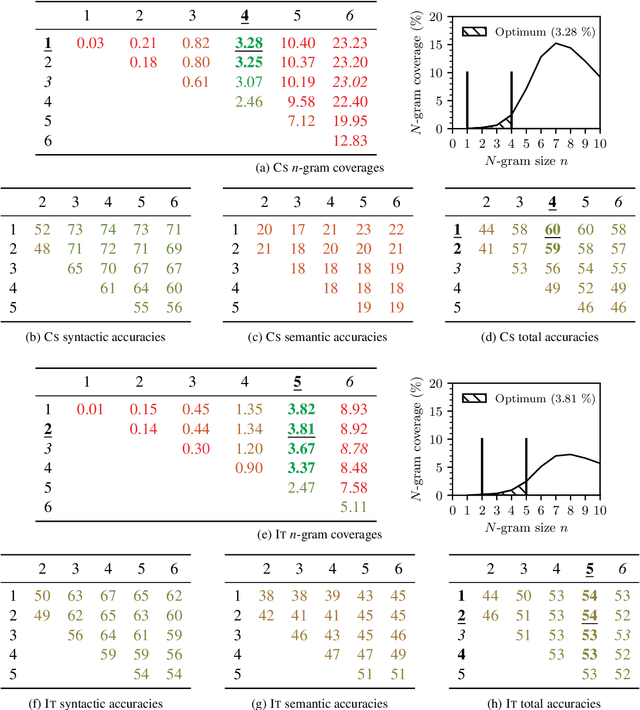
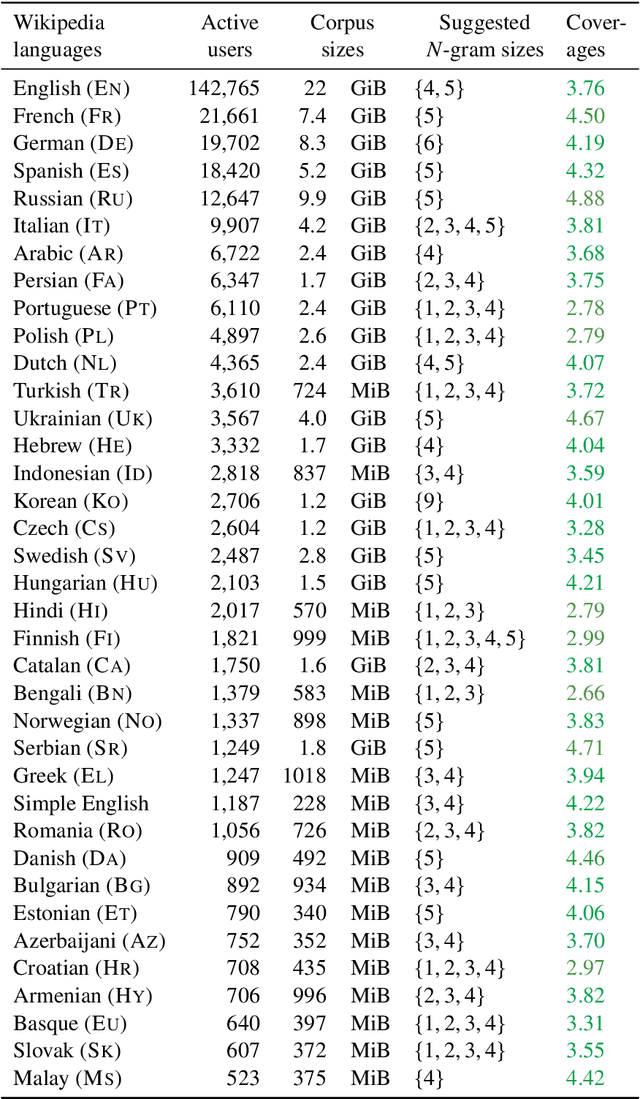
Unsupervised word representation learning from large corpora is badly needed for downstream tasks such as text classification, information retrieval, and machine translation. The representation precision of the fastText language models is mostly due to their use of subword information. In previous work, the optimization of fastText subword sizes has been largely neglected, and non-English fastText language models were trained using subword sizes optimized for English and German. In our work, we train English, German, Czech, and Italian fastText language models on Wikipedia, and we optimize the subword sizes on the English, German, Czech, and Italian word analogy tasks. We show that the optimization of subword sizes results in a 5% improvement on the Czech word analogy task. We also show that computationally expensive hyperparameter optimization can be replaced with cheap $n$-gram frequency analysis: subword sizes that are the closest to covering 3.76% of all unique subwords in a language are shown to be the optimal fastText hyperparameters on the English, German, Czech, and Italian word analogy tasks.
Text classification with word embedding regularization and soft similarity measure
Mar 10, 2020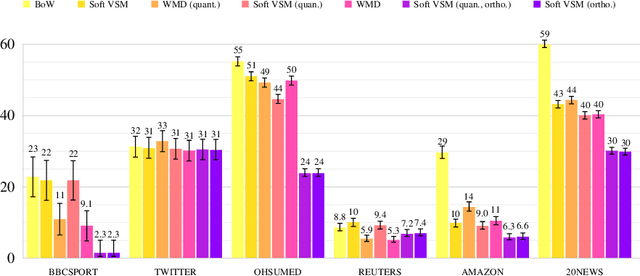
Since the seminal work of Mikolov et al., word embeddings have become the preferred word representations for many natural language processing tasks. Document similarity measures extracted from word embeddings, such as the soft cosine measure (SCM) and the Word Mover's Distance (WMD), were reported to achieve state-of-the-art performance on semantic text similarity and text classification. Despite the strong performance of the WMD on text classification and semantic text similarity, its super-cubic average time complexity is impractical. The SCM has quadratic worst-case time complexity, but its performance on text classification has never been compared with the WMD. Recently, two word embedding regularization techniques were shown to reduce storage and memory costs, and to improve training speed, document processing speed, and task performance on word analogy, word similarity, and semantic text similarity. However, the effect of these techniques on text classification has not yet been studied. In our work, we investigate the individual and joint effect of the two word embedding regularization techniques on the document processing speed and the task performance of the SCM and the WMD on text classification. For evaluation, we use the $k$NN classifier and six standard datasets: BBCSPORT, TWITTER, OHSUMED, REUTERS-21578, AMAZON, and 20NEWS. We show 39% average $k$NN test error reduction with regularized word embeddings compared to non-regularized word embeddings. We describe a practical procedure for deriving such regularized embeddings through Cholesky factorization. We also show that the SCM with regularized word embeddings significantly outperforms the WMD on text classification and is over 10,000 times faster.
Gait Recognition from Motion Capture Data
Aug 24, 2017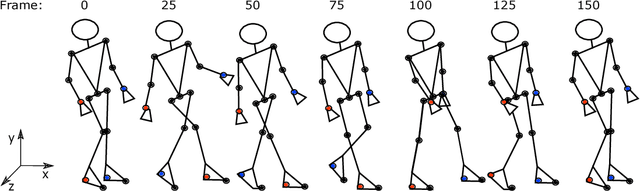
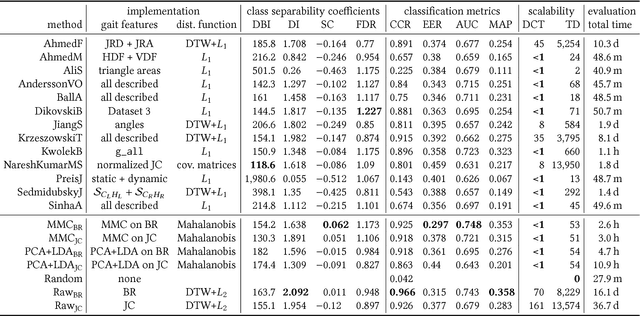
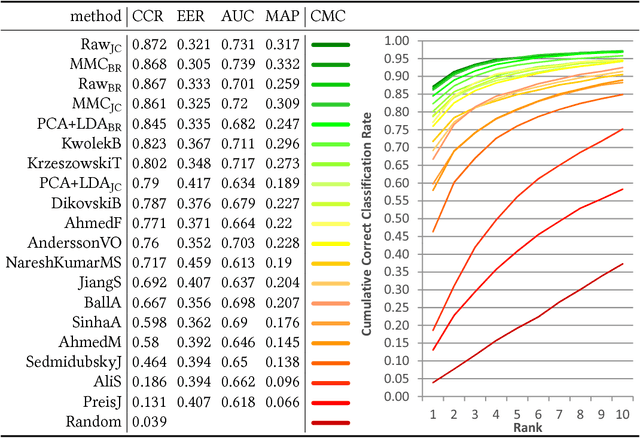
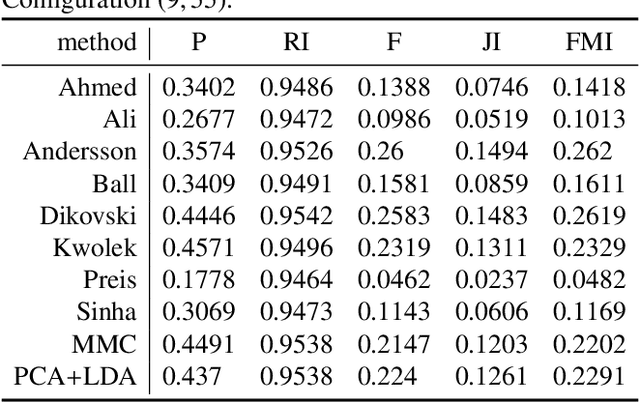
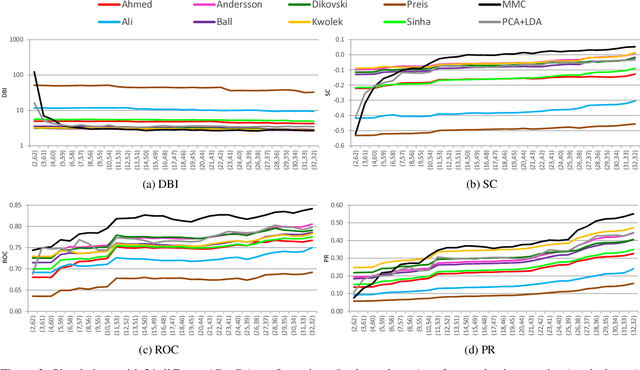
Gait recognition from motion capture data, as a pattern classification discipline, can be improved by the use of machine learning. This paper contributes to the state-of-the-art with a statistical approach for extracting robust gait features directly from raw data by a modification of Linear Discriminant Analysis with Maximum Margin Criterion. Experiments on the CMU MoCap database show that the suggested method outperforms thirteen relevant methods based on geometric features and a method to learn the features by a combination of Principal Component Analysis and Linear Discriminant Analysis. The methods are evaluated in terms of the distribution of biometric templates in respective feature spaces expressed in a number of class separability coefficients and classification metrics. Results also indicate a high portability of learned features, that means, we can learn what aspects of walk people generally differ in and extract those as general gait features. Recognizing people without needing group-specific features is convenient as particular people might not always provide annotated learning data. As a contribution to reproducible research, our evaluation framework and database have been made publicly available. This research makes motion capture technology directly applicable for human recognition.
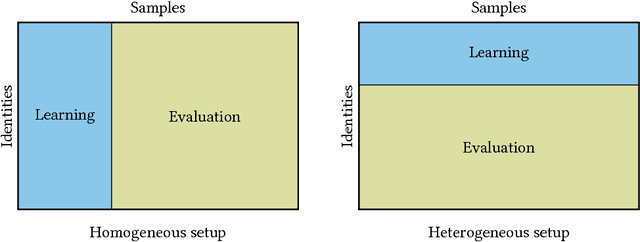
An Evaluation Framework and Database for MoCap-Based Gait Recognition Methods
Aug 24, 2017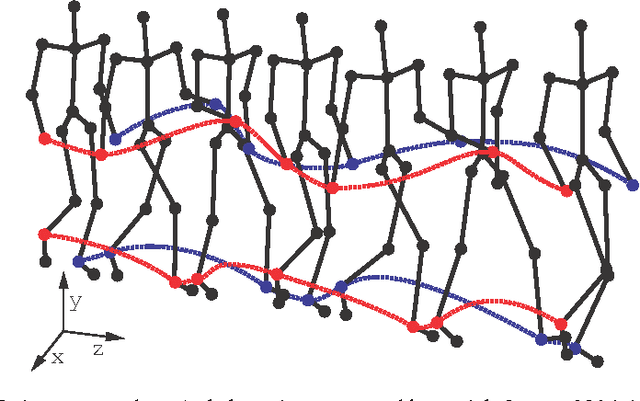

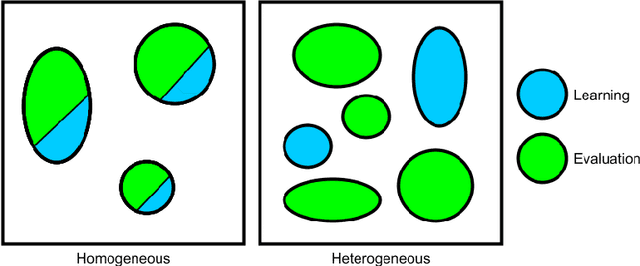
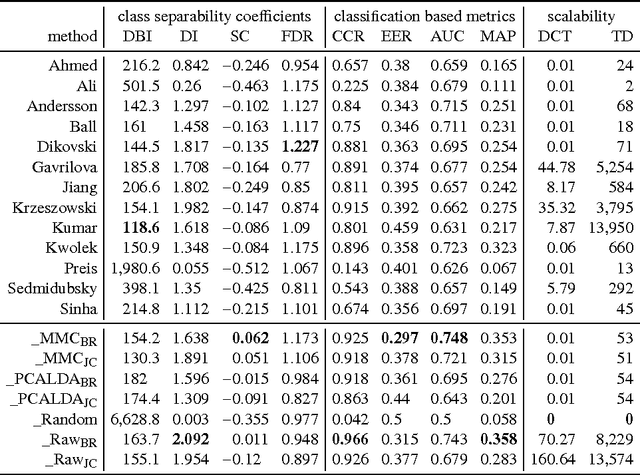
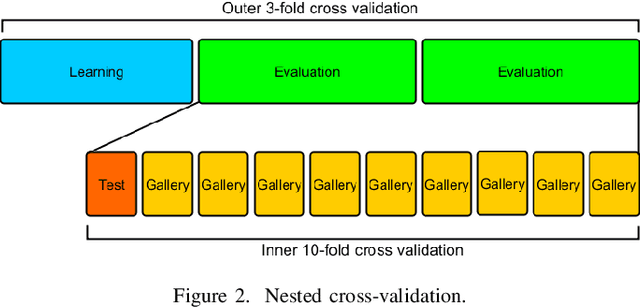
As a contribution to reproducible research, this paper presents a framework and a database to improve the development, evaluation and comparison of methods for gait recognition from motion capture (MoCap) data. The evaluation framework provides implementation details and source codes of state-of-the-art human-interpretable geometric features as well as our own approaches where gait features are learned by a modification of Fisher's Linear Discriminant Analysis with the Maximum Margin Criterion, and by a combination of Principal Component Analysis and Linear Discriminant Analysis. It includes a description and source codes of a mechanism for evaluating four class separability coefficients of feature space and four rank-based classifier performance metrics. This framework also contains a tool for learning a custom classifier and for classifying a custom query on a custom gallery. We provide an experimental database along with source codes for its extraction from the general CMU MoCap database.
Walker-Independent Features for Gait Recognition from Motion Capture Data
Aug 24, 2017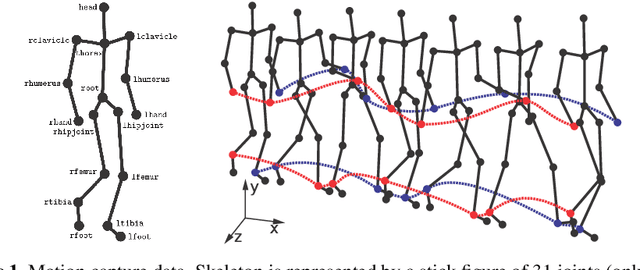
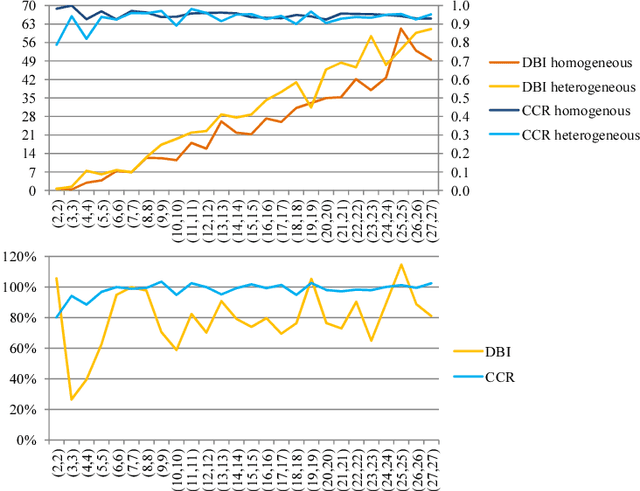
MoCap-based human identification, as a pattern recognition discipline, can be optimized using a machine learning approach. Yet in some applications such as video surveillance new identities can appear on the fly and labeled data for all encountered people may not always be available. This work introduces the concept of learning walker-independent gait features directly from raw joint coordinates by a modification of the Fisher Linear Discriminant Analysis with Maximum Margin Criterion. Our new approach shows not only that these features can discriminate different people than who they are learned on, but also that the number of learning identities can be much smaller than the number of walkers encountered in the real operation.
Learning Robust Features for Gait Recognition by Maximum Margin Criterion
Aug 24, 2017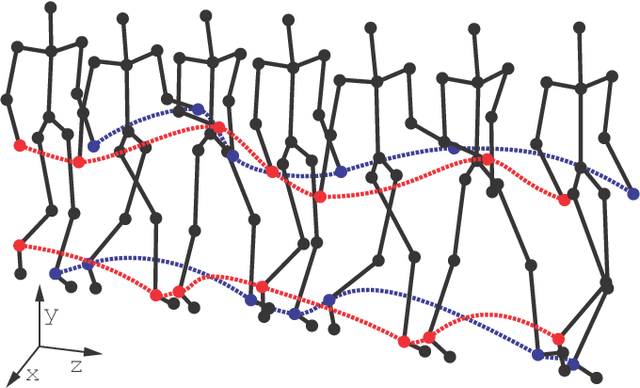
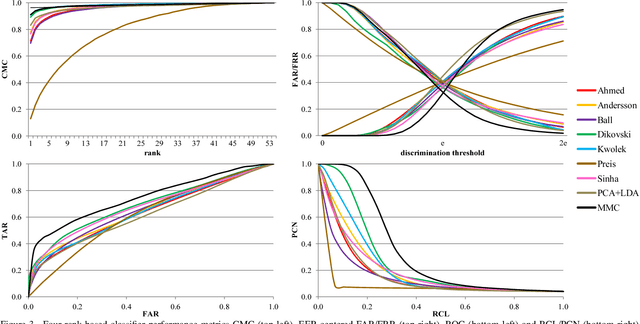

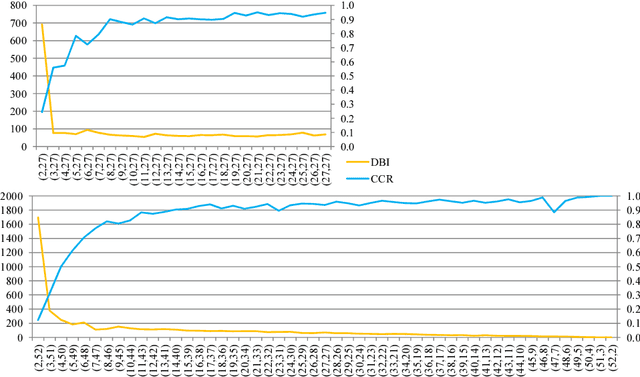
In the field of gait recognition from motion capture data, designing human-interpretable gait features is a common practice of many fellow researchers. To refrain from ad-hoc schemes and to find maximally discriminative features we may need to explore beyond the limits of human interpretability. This paper contributes to the state-of-the-art with a machine learning approach for extracting robust gait features directly from raw joint coordinates. The features are learned by a modification of Linear Discriminant Analysis with Maximum Margin Criterion so that the identities are maximally separated and, in combination with an appropriate classifier, used for gait recognition. Experiments on the CMU MoCap database show that this method outperforms eight other relevant methods in terms of the distribution of biometric templates in respective feature spaces expressed in four class separability coefficients. Additional experiments indicate that this method is a leading concept for rank-based classifier systems.
You Are How You Walk: Uncooperative MoCap Gait Identification for Video Surveillance with Incomplete and Noisy Data
Jul 27, 2017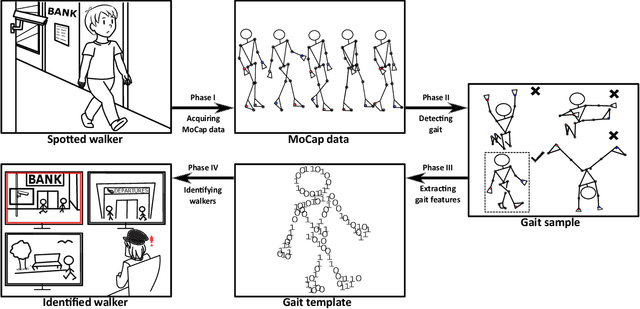
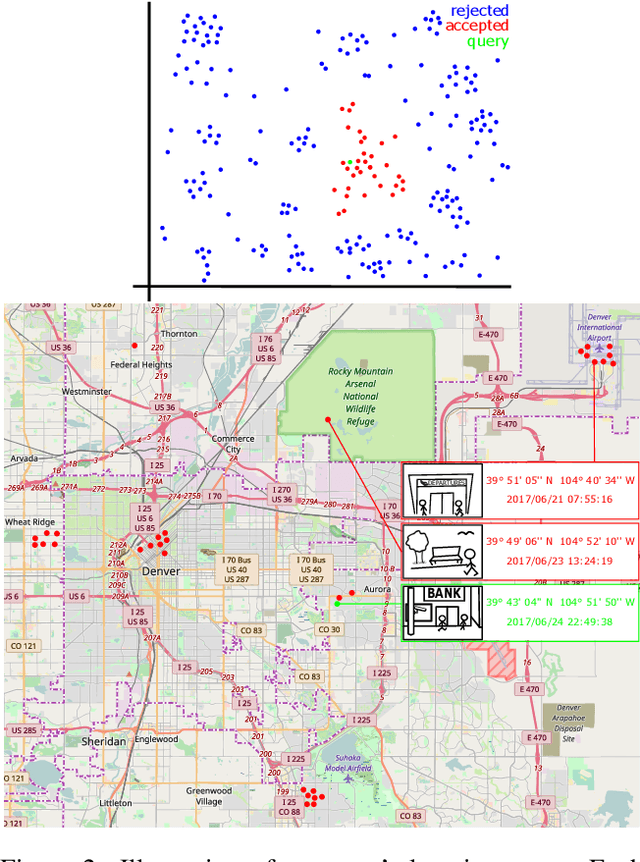
This work offers a design of a video surveillance system based on a soft biometric -- gait identification from MoCap data. The main focus is on two substantial issues of the video surveillance scenario: (1) the walkers do not cooperate in providing learning data to establish their identities and (2) the data are often noisy or incomplete. We show that only a few examples of human gait cycles are required to learn a projection of raw MoCap data onto a low-dimensional sub-space where the identities are well separable. Latent features learned by Maximum Margin Criterion (MMC) method discriminate better than any collection of geometric features. The MMC method is also highly robust to noisy data and works properly even with only a fraction of joints tracked. The overall workflow of the design is directly applicable for a day-to-day operation based on the available MoCap technology and algorithms for gait analysis. In the concept we introduce, a walker's identity is represented by a cluster of gait data collected at their incidents within the surveillance system: They are how they walk.