 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeizhao Zhang
Unbiased Teacher for Semi-Supervised Object Detection
Feb 18, 2021
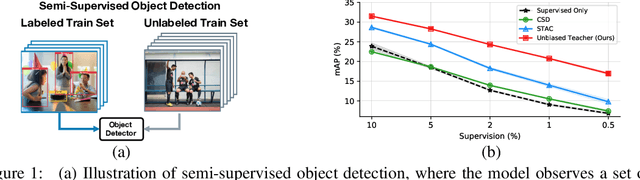

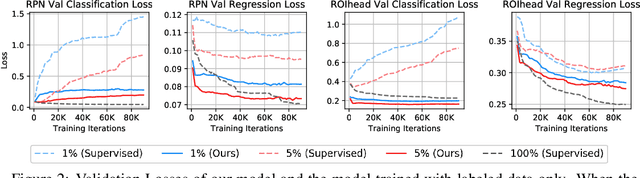
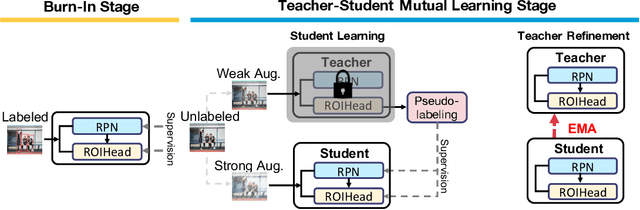
Semi-supervised learning, i.e., training networks with both labeled and unlabeled data, has made significant progress recently. However, existing works have primarily focused on image classification tasks and neglected object detection which requires more annotation effort. In this work, we revisit the Semi-Supervised Object Detection (SS-OD) and identify the pseudo-labeling bias issue in SS-OD. To address this, we introduce Unbiased Teacher, a simple yet effective approach that jointly trains a student and a gradually progressing teacher in a mutually-beneficial manner. Together with a class-balance loss to downweight overly confident pseudo-labels, Unbiased Teacher consistently improved state-of-the-art methods by significant margins on COCO-standard, COCO-additional, and VOC datasets. Specifically, Unbiased Teacher achieves 6.8 absolute mAP improvements against state-of-the-art method when using 1% of labeled data on MS-COCO, achieves around 10 mAP improvements against the supervised baseline when using only 0.5, 1, 2% of labeled data on MS-COCO.
Low Bandwidth Video-Chat Compression using Deep Generative Models
Dec 01, 2020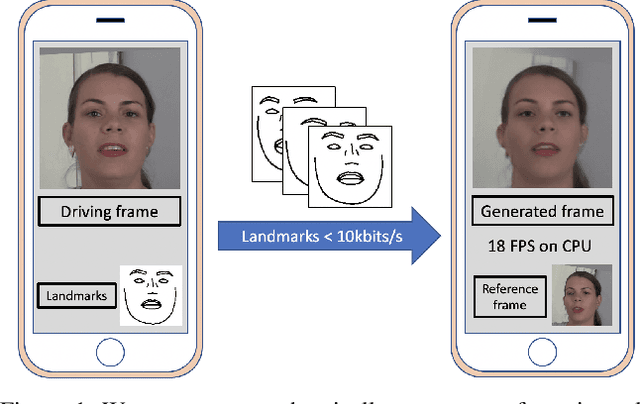
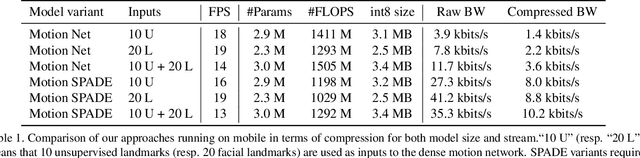
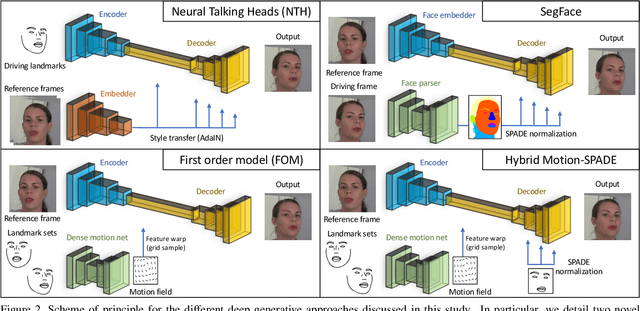
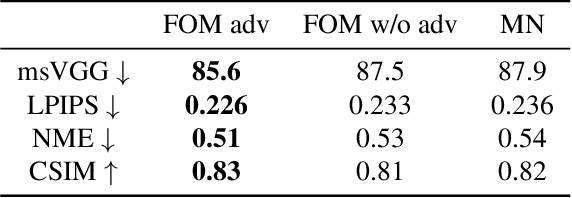
To unlock video chat for hundreds of millions of people hindered by poor connectivity or unaffordable data costs, we propose to authentically reconstruct faces on the receiver's device using facial landmarks extracted at the sender's side and transmitted over the network. In this context, we discuss and evaluate the benefits and disadvantages of several deep adversarial approaches. In particular, we explore quality and bandwidth trade-offs for approaches based on static landmarks, dynamic landmarks or segmentation maps. We design a mobile-compatible architecture based on the first order animation model of Siarohin et al. In addition, we leverage SPADE blocks to refine results in important areas such as the eyes and lips. We compress the networks down to about 3MB, allowing models to run in real time on iPhone 8 (CPU). This approach enables video calling at a few kbits per second, an order of magnitude lower than currently available alternatives.
FBWave: Efficient and Scalable Neural Vocoders for Streaming Text-To-Speech on the Edge
Nov 25, 2020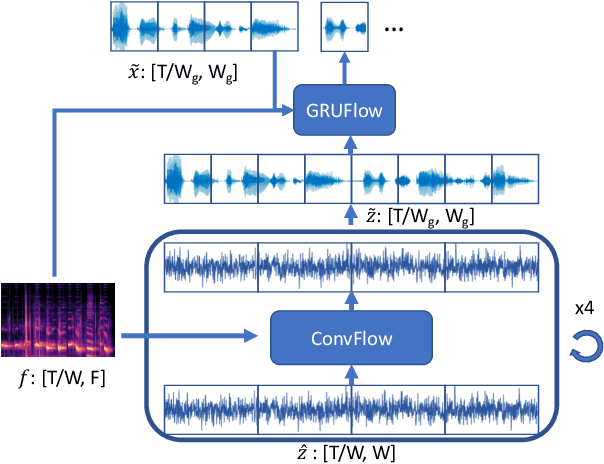
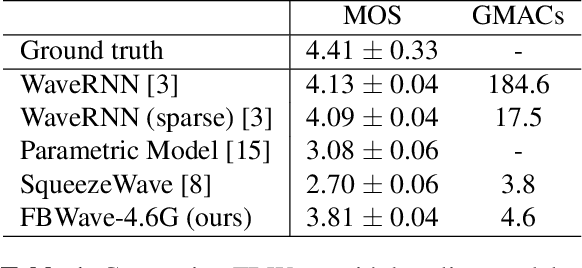
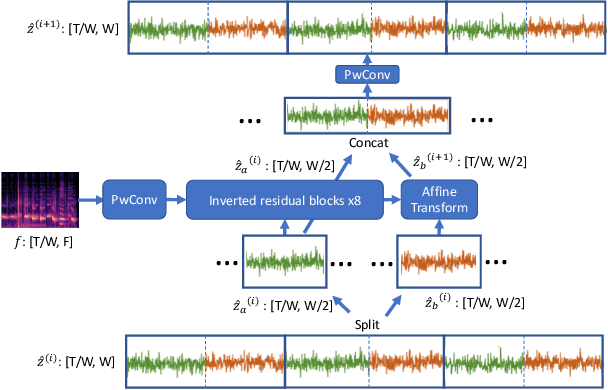

Nowadays more and more applications can benefit from edge-based text-to-speech (TTS). However, most existing TTS models are too computationally expensive and are not flexible enough to be deployed on the diverse variety of edge devices with their equally diverse computational capacities. To address this, we propose FBWave, a family of efficient and scalable neural vocoders that can achieve optimal performance-efficiency trade-offs for different edge devices. FBWave is a hybrid flow-based generative model that combines the advantages of autoregressive and non-autoregressive models. It produces high quality audio and supports streaming during inference while remaining highly computationally efficient. Our experiments show that FBWave can achieve similar audio quality to WaveRNN while reducing MACs by 40x. More efficient variants of FBWave can achieve up to 109x fewer MACs while still delivering acceptable audio quality. Audio demos are available at https://bichenwu09.github.io/vocoder_demos.
FP-NAS: Fast Probabilistic Neural Architecture Search
Nov 24, 2020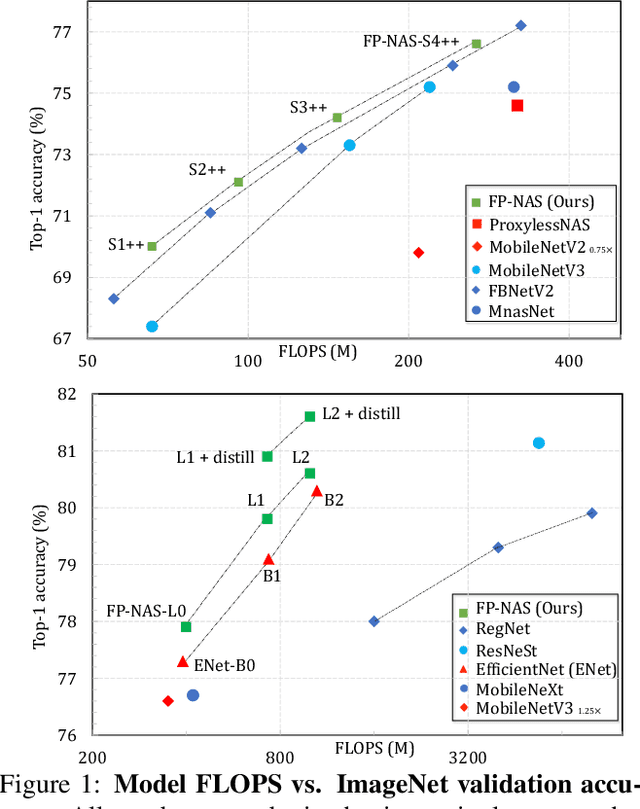
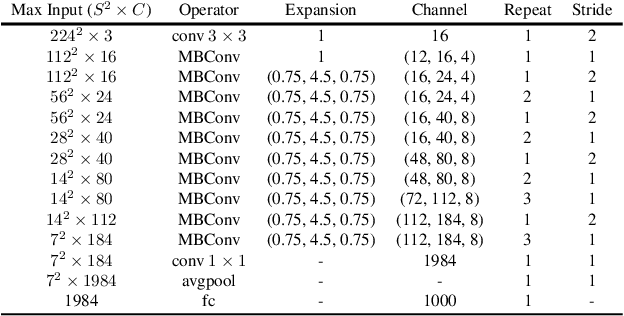
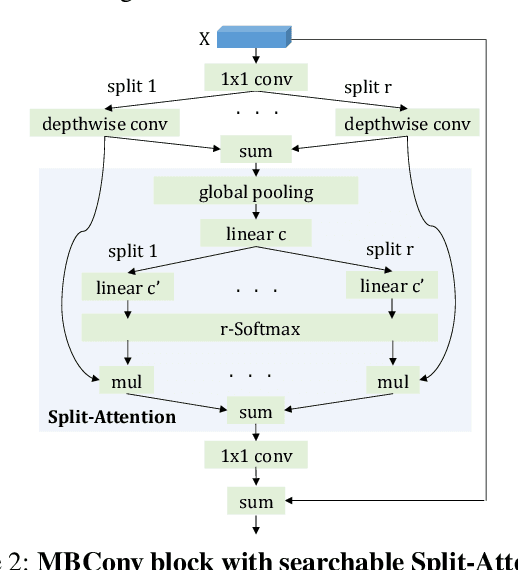

Differential Neural Architecture Search (NAS) requires all layer choices to be held in memory simultaneously; this limits the size of both search space and final architecture. In contrast, Probabilistic NAS, such as PARSEC, learns a distribution over high-performing architectures, and uses only as much memory as needed to train a single model. Nevertheless, it needs to sample many architectures, making it computationally expensive for searching in an extensive space. To solve these problems, we propose a sampling method adaptive to the distribution entropy, drawing more samples to encourage explorations at the beginning, and reducing samples as learning proceeds. Furthermore, to search fast in the multi-variate space, we propose a coarse-to-fine strategy by using a factorized distribution at the beginning which can reduce the number of architecture parameters by over an order of magnitude.We call this method Fast Probabilistic NAS (FP-NAS). Compared with PARSEC, it can sample 64% fewer architectures and search 2.1x faster. Compared with FBNetV2, FP-NAS is 1.9x - 3.6x faster, and the searched models outperform FBNetV2 models on ImageNet. FP-NAS allows us to expand the giant FBNetV2 space to be wider (i.e. larger channel choices) and deeper (i.e. more blocks), while adding Split-Attention block and enabling the search over the number of splits. When searching a model of size 0.4G FLOPS, FP-NAS is 132x faster than EfficientNet, and the searched FP-NAS-L0 model outperforms EfficientNet-B0 by 0.6% accuracy. Without using any architecture surrogate or scaling tricks, we directly search large models up to 1.0G FLOPS. Our FP-NAS-L2 model with simple distillation outperforms BigNAS-XL with advanced inplace distillation by 0.7% accuracy with less FLOPS.
One Shot 3D Photography
Sep 01, 2020
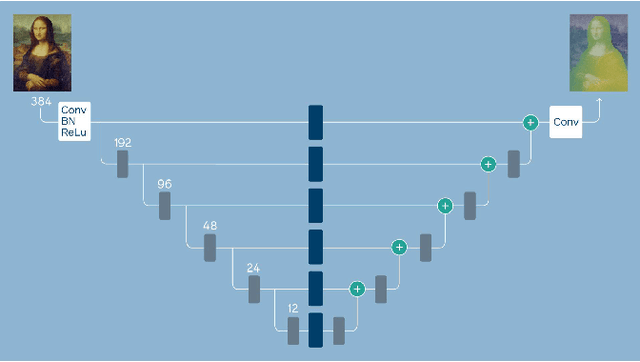

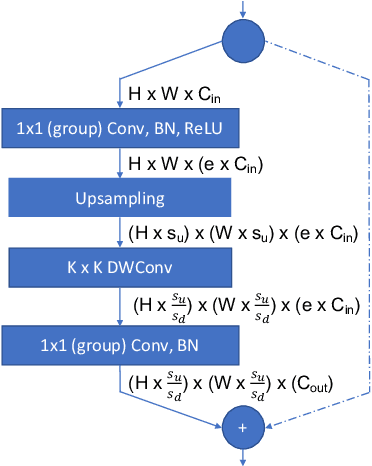
3D photography is a new medium that allows viewers to more fully experience a captured moment. In this work, we refer to a 3D photo as one that displays parallax induced by moving the viewpoint (as opposed to a stereo pair with a fixed viewpoint). 3D photos are static in time, like traditional photos, but are displayed with interactive parallax on mobile or desktop screens, as well as on Virtual Reality devices, where viewing it also includes stereo. We present an end-to-end system for creating and viewing 3D photos, and the algorithmic and design choices therein. Our 3D photos are captured in a single shot and processed directly on a mobile device. The method starts by estimating depth from the 2D input image using a new monocular depth estimation network that is optimized for mobile devices. It performs competitively to the state-of-the-art, but has lower latency and peak memory consumption and uses an order of magnitude fewer parameters. The resulting depth is lifted to a layered depth image, and new geometry is synthesized in parallax regions. We synthesize color texture and structures in the parallax regions as well, using an inpainting network, also optimized for mobile devices, on the LDI directly. Finally, we convert the result into a mesh-based representation that can be efficiently transmitted and rendered even on low-end devices and over poor network connections. Altogether, the processing takes just a few seconds on a mobile device, and the result can be instantly viewed and shared. We perform extensive quantitative evaluation to validate our system and compare its new components against the current state-of-the-art.
* Project page: https://facebookresearch.github.io/one_shot_3d_photography/ Code: https://github.com/facebookresearch/one_shot_3d_photography
Geometric Correspondence Fields: Learned Differentiable Rendering for 3D Pose Refinement in the Wild
Jul 17, 2020
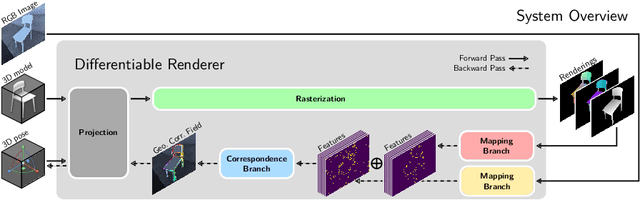
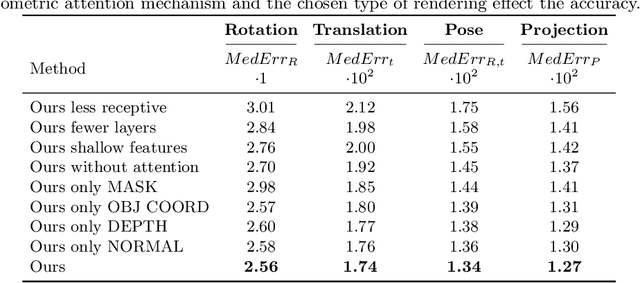
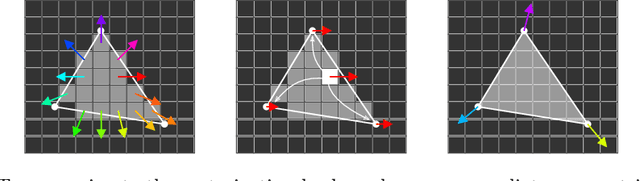
We present a novel 3D pose refinement approach based on differentiable rendering for objects of arbitrary categories in the wild. In contrast to previous methods, we make two main contributions: First, instead of comparing real-world images and synthetic renderings in the RGB or mask space, we compare them in a feature space optimized for 3D pose refinement. Second, we introduce a novel differentiable renderer that learns to approximate the rasterization backward pass from data instead of relying on a hand-crafted algorithm. For this purpose, we predict deep cross-domain correspondences between RGB images and 3D model renderings in the form of what we call geometric correspondence fields. These correspondence fields serve as pixel-level gradients which are analytically propagated backward through the rendering pipeline to perform a gradient-based optimization directly on the 3D pose. In this way, we precisely align 3D models to objects in RGB images which results in significantly improved 3D pose estimates. We evaluate our approach on the challenging Pix3D dataset and achieve up to 55% relative improvement compared to state-of-the-art refinement methods in multiple metrics.
Visual Transformers: Token-based Image Representation and Processing for Computer Vision
Jul 02, 2020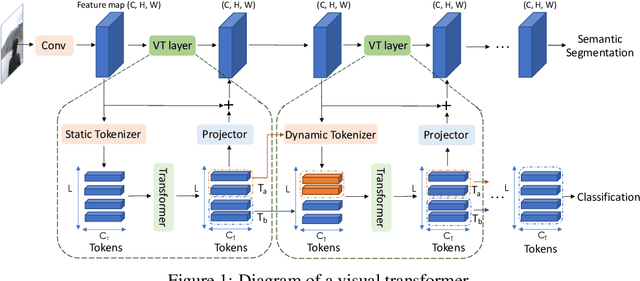
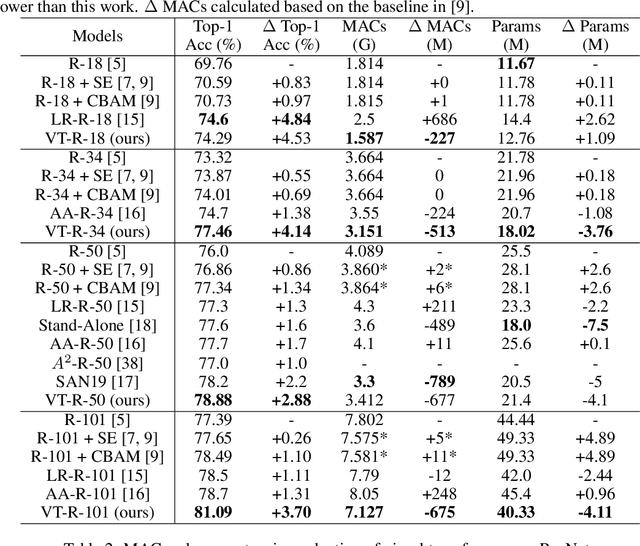
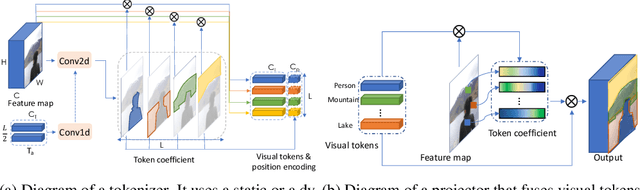

Computer vision has achieved great success using standardized image representations -- pixel arrays, and the corresponding deep learning operators -- convolutions. In this work, we challenge this paradigm: we instead (a) represent images as a set of visual tokens and (b) apply visual transformers to find relationships between visual semantic concepts. Given an input image, we dynamically extract a set of visual tokens from the image to obtain a compact representation for high-level semantics. We then use visual transformers to operate over the visual tokens to densely model relationships between them. We find that this paradigm of token-based image representation and processing drastically outperforms its convolutional counterparts on image classification and semantic segmentation. To demonstrate the power of this approach on ImageNet classification, we use ResNet as a convenient baseline and use visual transformers to replace the last stage of convolutions. This reduces the stage's MACs by up to 6.9x, while attaining up to 4.53 points higher top-1 accuracy. For semantic segmentation, we use a visual-transformer-based FPN (VT-FPN) module to replace a convolution-based FPN, saving 6.5x fewer MACs while achieving up to 0.35 points higher mIoU on LIP and COCO-stuff.