 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Workspace Generation of Serial-link Manipulators by Deep Learning based Jacobian Estimation
Sep 14, 2018
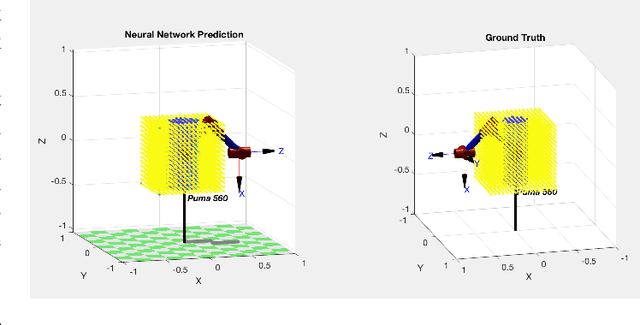
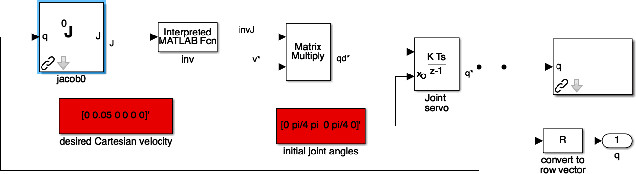
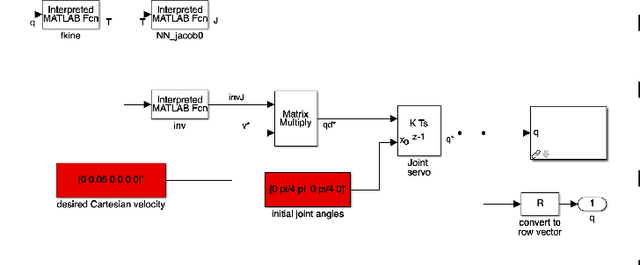
Apart from solving complicated problems that require a certain level of intelligence, fine-tuned deep neural networks can also create fast algorithms for slow, numerical tasks. In this paper, we introduce an improved version of [1]'s work, a fast, deep-learning framework capable of generating the full workspace of serial-link manipulators. The architecture consists of two neural networks: an estimation net that approximates the manipulator Jacobian, and a confidence net that measures the confidence of the approximation. We also introduce M3 (Manipulability Maps of Manipulators), a MATLAB robotics library based on [2](RTB), the datasets generated by which are used by this work. Results have shown that not only are the neural networks significantly faster than numerical inverse kinematics, it also offers superior accuracy when compared to other machine learning alternatives. Implementations of the algorithm (based on Keras[3]), including benchmark evaluation script, are available at https://github.com/liaopeiyuan/Jacobian-Estimation . The M3 Library APIs and datasets are also available at https://github.com/liaopeiyuan/M3 .
Deep Neural Network Based Subspace Learning of Robotic Manipulator Workspace Mapping
Apr 25, 2018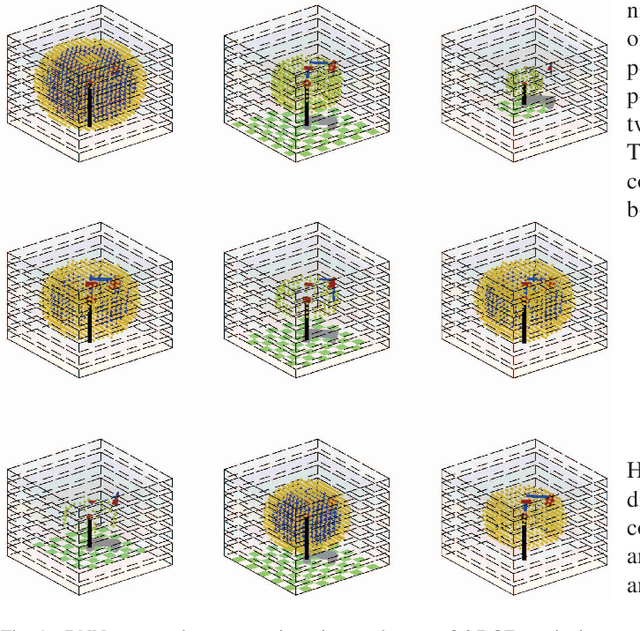
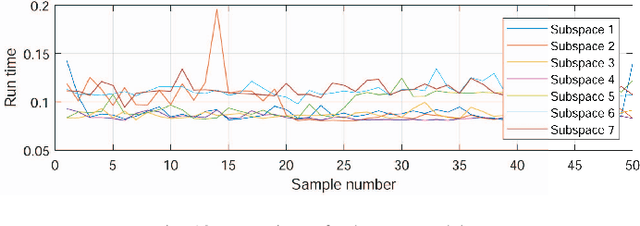
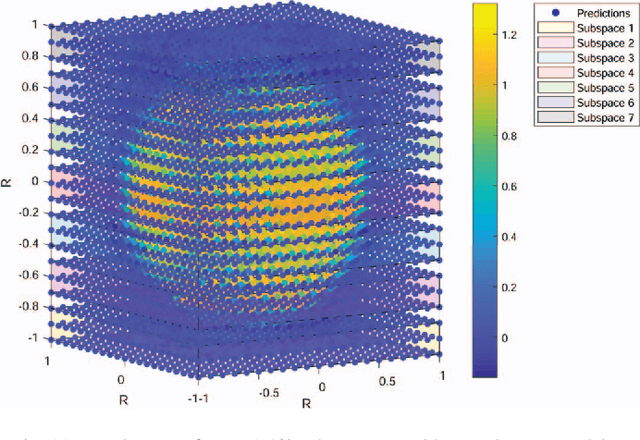
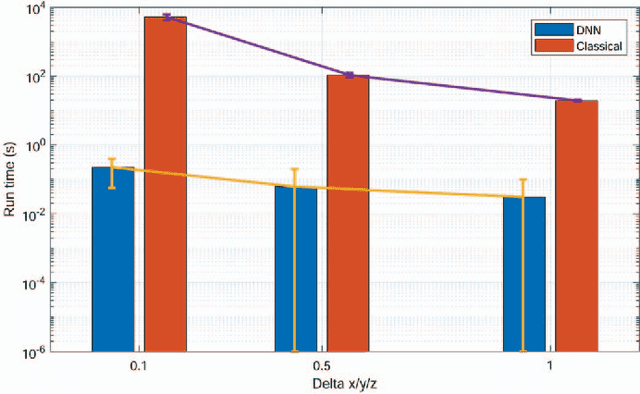
The manipulator workspace mapping is an important problem in robotics and has attracted significant attention in the community. However, most of the pre-existing algorithms have expensive time complexity due to the reliance on sophisticated kinematic equations. To solve this problem, this paper introduces subspace learning (SL), a variant of subspace embedding, where a set of robot and scope parameters is mapped to the corresponding workspace by a deep neural network (DNN). Trained on a large dataset of around $\mathbf{6\times 10^4}$ samples obtained from a MATLAB$^\circledR$ implementation of a classical method and sampling of designed uniform distributions, the experiments demonstrate that the embedding significantly reduces run-time from $\mathbf{5.23 \times 10^3}$ s of traditional discretization method to $\mathbf{0.224}$ s, with high accuracies (average F-measure is $\mathbf{0.9665}$ with batch gradient descent and resilient backpropagation).