 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaul Smolensky
A Neural-Symbolic Approach to Design of CAPTCHA
Sep 25, 2018
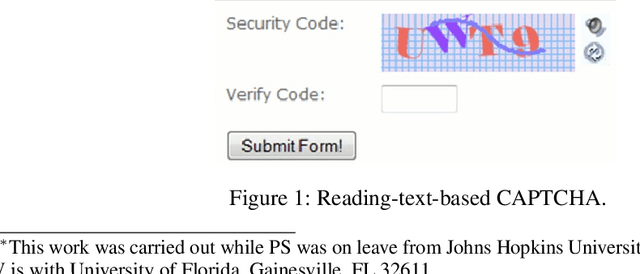


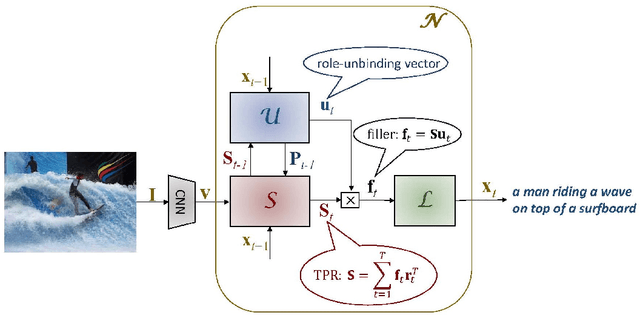
CAPTCHAs based on reading text are susceptible to machine-learning-based attacks due to recent significant advances in deep learning (DL). To address this, this paper promotes image/visual captioning based CAPTCHAs, which is robust against machine-learning-based attacks. To develop image/visual-captioning-based CAPTCHAs, this paper proposes a new image captioning architecture by exploiting tensor product representations (TPR), a structured neural-symbolic framework developed in cognitive science over the past 20 years, with the aim of integrating DL with explicit language structures and rules. We call it the Tensor Product Generation Network (TPGN). The key ideas of TPGN are: 1) unsupervised learning of role-unbinding vectors of words via a TPR-based deep neural network, and 2) integration of TPR with typical DL architectures including Long Short-Term Memory (LSTM) models. The novelty of our approach lies in its ability to generate a sentence and extract partial grammatical structure of the sentence by using role-unbinding vectors, which are obtained in an unsupervised manner. Experimental results demonstrate the effectiveness of the proposed approach.
Predicting Argumenthood of English Preposition Phrases
Sep 24, 2018


Distinguishing between core and non-core dependents (i.e., arguments and adjuncts) of a verb is a longstanding, nontrivial problem. In natural language processing, argumenthood information is important in tasks such as semantic role labeling (SRL) and preposition phrase (PP) attachment disambiguation. In theoretical linguistics, many diagnostic tests for argumenthood exist but they often yield conflicting and potentially gradient results. This is especially the case for syntactically oblique items such as PPs. We propose two PP argumenthood prediction tasks branching from these two motivations: (1) binary argument/adjunct classification of PPs in VerbNet, and (2) gradient argumenthood prediction using human judgments as gold standard, and report results from prediction models that use pretrained word embeddings and other linguistically informed features. Our best results on each task are (1) $acc.=0.955$, $F_1=0.954$ (ELMo+BiLSTM) and (2) Pearson's $r=0.624$ (word2vec+MLP). Furthermore, we demonstrate the utility of argumenthood prediction in improving sentence representations via performance gains on SRL when a sentence encoder is pretrained with our tasks.
Learning and analyzing vector encoding of symbolic representations
Mar 10, 2018
We present a formal language with expressions denoting general symbol structures and queries which access information in those structures. A sequence-to-sequence network processing this language learns to encode symbol structures and query them. The learned representation (approximately) shares a simple linearity property with theoretical techniques for performing this task.
Discrete symbolic optimization and Boltzmann sampling by continuous neural dynamics: Gradient Symbolic Computation
Jan 04, 2018Gradient Symbolic Computation is proposed as a means of solving discrete global optimization problems using a neurally plausible continuous stochastic dynamical system. Gradient symbolic dynamics involves two free parameters that must be adjusted as a function of time to obtain the global maximizer at the end of the computation. We provide a summary of what is known about the GSC dynamics for special cases of settings of the parameters, and also establish that there is a schedule for the two parameters for which convergence to the correct answer occurs with high probability. These results put the empirical results already obtained for GSC on a sound theoretical footing.
Tensor Product Generation Networks for Deep NLP Modeling
Dec 16, 2017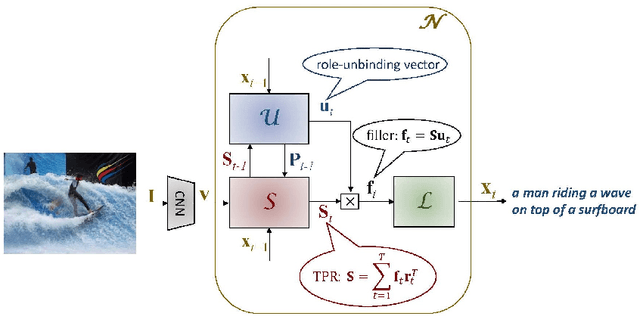

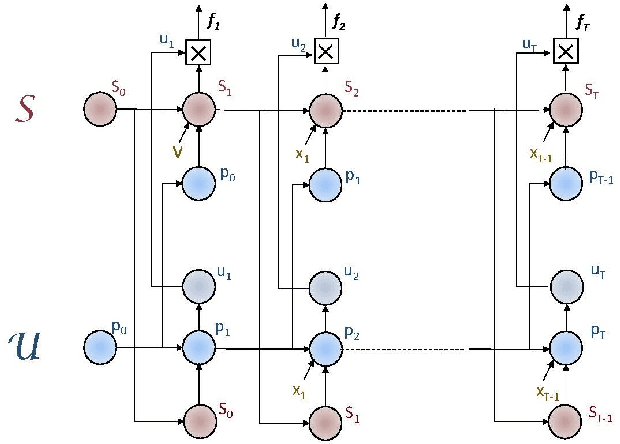
We present a new approach to the design of deep networks for natural language processing (NLP), based on the general technique of Tensor Product Representations (TPRs) for encoding and processing symbol structures in distributed neural networks. A network architecture --- the Tensor Product Generation Network (TPGN) --- is proposed which is capable in principle of carrying out TPR computation, but which uses unconstrained deep learning to design its internal representations. Instantiated in a model for image-caption generation, TPGN outperforms LSTM baselines when evaluated on the COCO dataset. The TPR-capable structure enables interpretation of internal representations and operations, which prove to contain considerable grammatical content. Our caption-generation model can be interpreted as generating sequences of grammatical categories and retrieving words by their categories from a plan encoded as a distributed representation.
Question-Answering with Grammatically-Interpretable Representations
Sep 25, 2017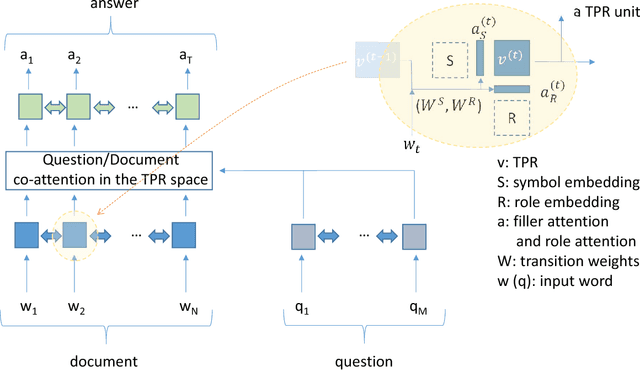

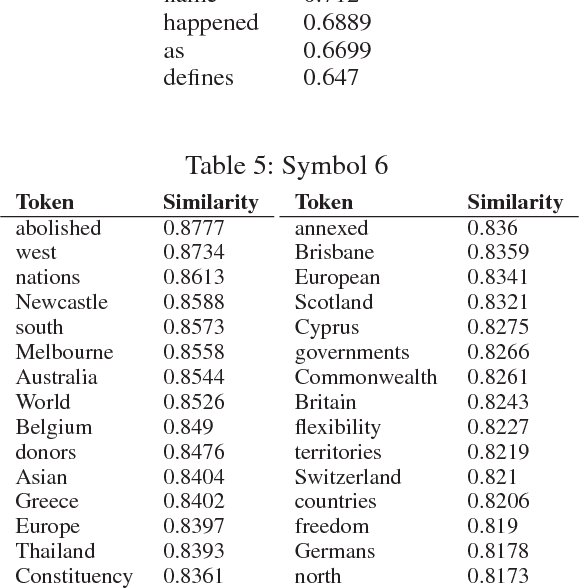

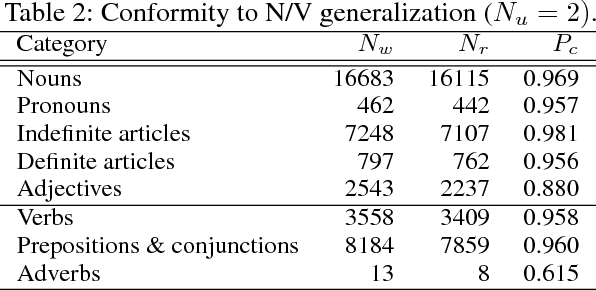
We introduce an architecture, the Tensor Product Recurrent Network (TPRN). In our application of TPRN, internal representations learned by end-to-end optimization in a deep neural network performing a textual question-answering (QA) task can be interpreted using basic concepts from linguistic theory. No performance penalty need be paid for this increased interpretability: the proposed model performs comparably to a state-of-the-art system on the SQuAD QA task. The internal representation which is interpreted is a Tensor Product Representation: for each input word, the model selects a symbol to encode the word, and a role in which to place the symbol, and binds the two together. The selection is via soft attention. The overall interpretation is built from interpretations of the symbols, as recruited by the trained model, and interpretations of the roles as used by the model. We find support for our initial hypothesis that symbols can be interpreted as lexical-semantic word meanings, while roles can be interpreted as approximations of grammatical roles (or categories) such as subject, wh-word, determiner, etc. Fine-grained analysis reveals specific correspondences between the learned roles and parts of speech as assigned by a standard tagger (Toutanova et al. 2003), and finds several discrepancies in the model's favor. In this sense, the model learns significant aspects of grammar, after having been exposed solely to linguistically unannotated text, questions, and answers: no prior linguistic knowledge is given to the model. What is given is the means to build representations using symbols and roles, with an inductive bias favoring use of these in an approximately discrete manner.
Reasoning in Vector Space: An Exploratory Study of Question Answering
Feb 26, 2016

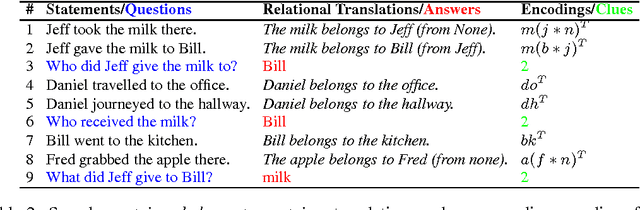

Question answering tasks have shown remarkable progress with distributed vector representation. In this paper, we investigate the recently proposed Facebook bAbI tasks which consist of twenty different categories of questions that require complex reasoning. Because the previous work on bAbI are all end-to-end models, errors could come from either an imperfect understanding of semantics or in certain steps of the reasoning. For clearer analysis, we propose two vector space models inspired by Tensor Product Representation (TPR) to perform knowledge encoding and logical reasoning based on common-sense inference. They together achieve near-perfect accuracy on all categories including positional reasoning and path finding that have proved difficult for most of the previous approaches. We hypothesize that the difficulties in these categories are due to the multi-relations in contrast to uni-relational characteristic of other categories. Our exploration sheds light on designing more sophisticated dataset and moving one step toward integrating transparent and interpretable formalism of TPR into existing learning paradigms.
Basic Reasoning with Tensor Product Representations
Jan 12, 2016In this paper we present the initial development of a general theory for mapping inference in predicate logic to computation over Tensor Product Representations (TPRs; Smolensky (1990), Smolensky & Legendre (2006)). After an initial brief synopsis of TPRs (Section 0), we begin with particular examples of inference with TPRs in the 'bAbI' question-answering task of Weston et al. (2015) (Section 1). We then present a simplification of the general analysis that suffices for the bAbI task (Section 2). Finally, we lay out the general treatment of inference over TPRs (Section 3). We also show the simplification in Section 2 derives the inference methods described in Lee et al. (2016); this shows how the simple methods of Lee et al. (2016) can be formally extended to more general reasoning tasks.