 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePascal Van Hentenryck
Just-In-Time Learning for Operational Risk Assessment in Power Grids
Sep 26, 2022
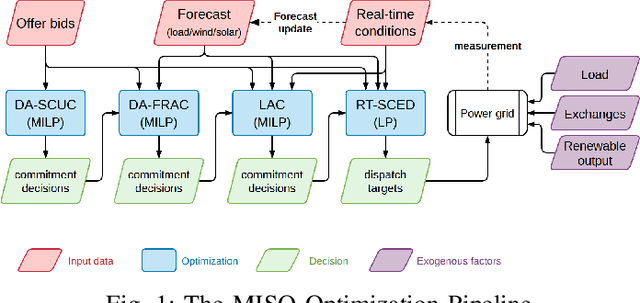
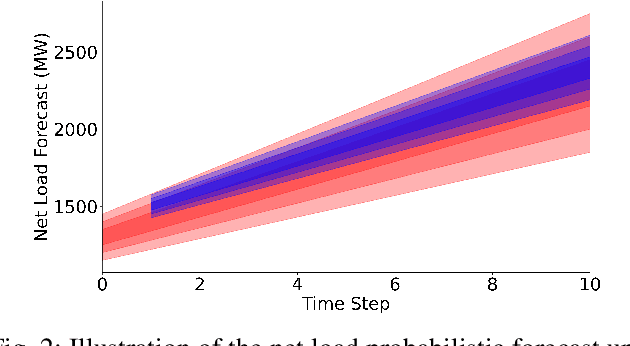
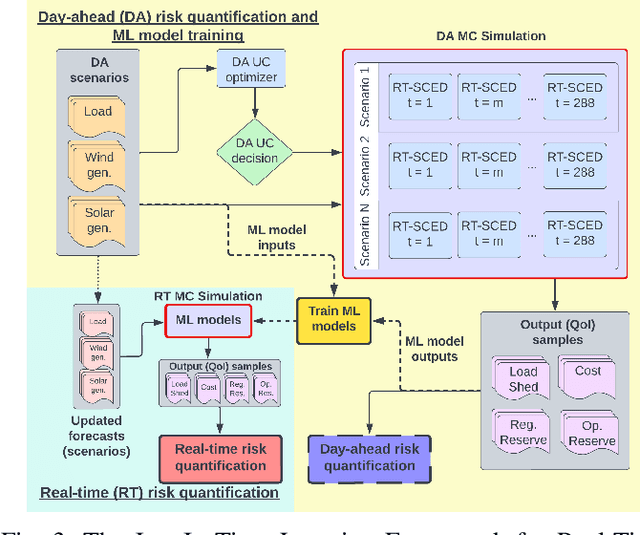
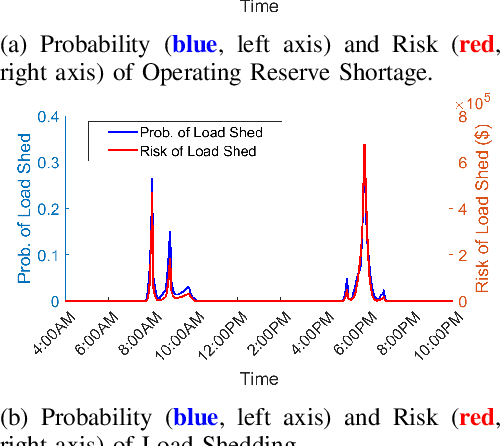
In a grid with a significant share of renewable generation, operators will need additional tools to evaluate the operational risk due to the increased volatility in load and generation. The computational requirements of the forward uncertainty propagation problem, which must solve numerous security-constrained economic dispatch (SCED) optimizations, is a major barrier for such real-time risk assessment. This paper proposes a Just-In-Time Risk Assessment Learning Framework (JITRALF) as an alternative. JITRALF trains risk surrogates, one for each hour in the day, using Machine Learning (ML) to predict the quantities needed to estimate risk, without explicitly solving the SCED problem. This significantly reduces the computational burden of the forward uncertainty propagation and allows for fast, real-time risk estimation. The paper also proposes a novel, asymmetric loss function and shows that models trained using the asymmetric loss perform better than those using symmetric loss functions. JITRALF is evaluated on the French transmission system for assessing the risk of insufficient operating reserves, the risk of load shedding, and the expected operating cost.
Self-Supervised Primal-Dual Learning for Constrained Optimization
Aug 18, 2022
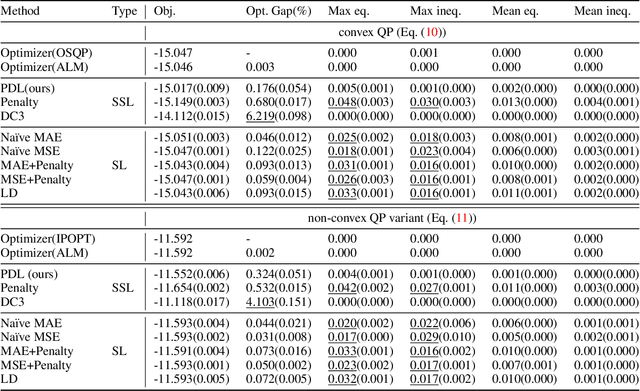
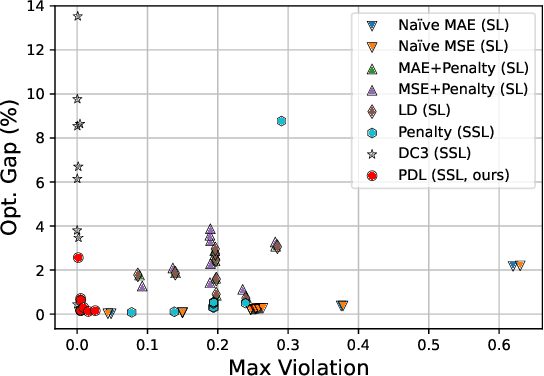
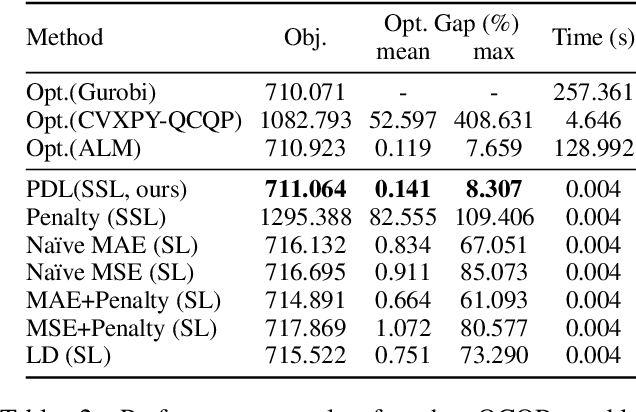
This paper studies how to train machine-learning models that directly approximate the optimal solutions of constrained optimization problems. This is an empirical risk minimization under constraints, which is challenging as training must balance optimality and feasibility conditions. Supervised learning methods often approach this challenge by training the model on a large collection of pre-solved instances. This paper takes a different route and proposes the idea of Primal-Dual Learning (PDL), a self-supervised training method that does not require a set of pre-solved instances or an optimization solver for training and inference. Instead, PDL mimics the trajectory of an Augmented Lagrangian Method (ALM) and jointly trains primal and dual neural networks. Being a primal-dual method, PDL uses instance-specific penalties of the constraint terms in the loss function used to train the primal network. Experiments show that, on a set of nonlinear optimization benchmarks, PDL typically exhibits negligible constraint violations and minor optimality gaps, and is remarkably close to the ALM optimization. PDL also demonstrated improved or similar performance in terms of the optimality gaps, constraint violations, and training times compared to existing approaches.
Active Bucketized Learning for ACOPF Optimization Proxies
Aug 16, 2022
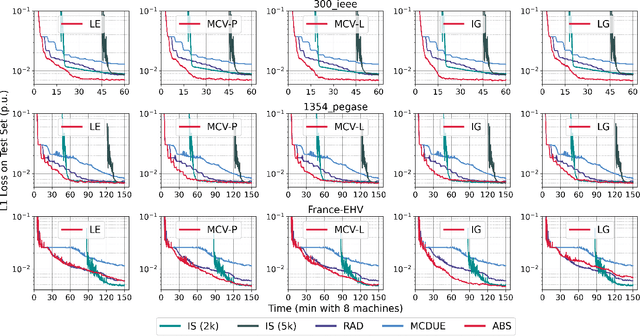
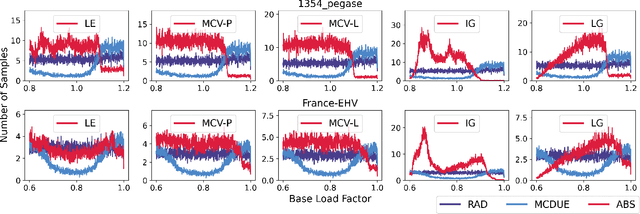
This paper considers optimization proxies for Optimal Power Flow (OPF), i.e., machine-learning models that approximate the input/output relationship of OPF. Recent work has focused on showing that such proxies can be of high fidelity. However, their training requires significant data, each instance necessitating the (offline) solving of an OPF for a sample of the input distribution. To meet the requirements of market-clearing applications, this paper proposes Active Bucketized Sampling (ABS), a novel active learning framework that aims at training the best possible OPF proxy within a time limit. ABS partitions the input distribution into buckets and uses an acquisition function to determine where to sample next. It relies on an adaptive learning rate that increases and decreases over time. Experimental results demonstrate the benefits of ABS.
Learning Regionally Decentralized AC Optimal Power Flows with ADMM
May 08, 2022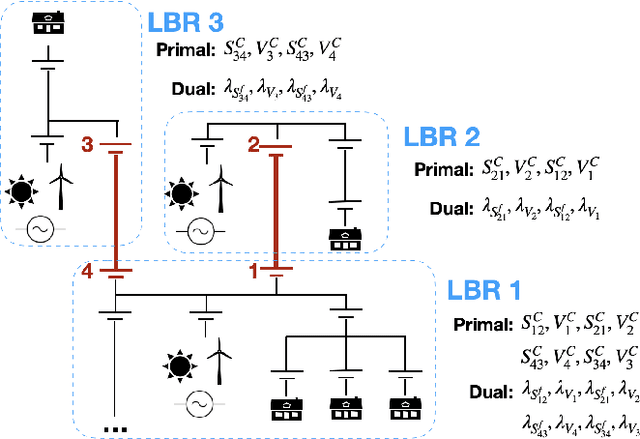

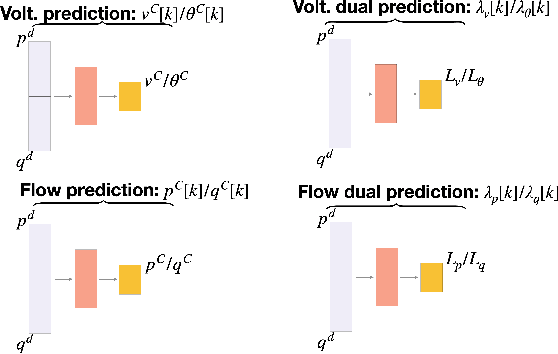

One potential future for the next generation of smart grids is the use of decentralized optimization algorithms and secured communications for coordinating renewable generation (e.g., wind/solar), dispatchable devices (e.g., coal/gas/nuclear generations), demand response, battery & storage facilities, and topology optimization. The Alternating Direction Method of Multipliers (ADMM) has been widely used in the community to address such decentralized optimization problems and, in particular, the AC Optimal Power Flow (AC-OPF). This paper studies how machine learning may help in speeding up the convergence of ADMM for solving AC-OPF. It proposes a novel decentralized machine-learning approach, namely ML-ADMM, where each agent uses deep learning to learn the consensus parameters on the coupling branches. The paper also explores the idea of learning only from ADMM runs that exhibit high-quality convergence properties, and proposes filtering mechanisms to select these runs. Experimental results on test cases based on the French system demonstrate the potential of the approach in speeding up the convergence of ADMM significantly.
SF-PATE: Scalable, Fair, and Private Aggregation of Teacher Ensembles
Apr 11, 2022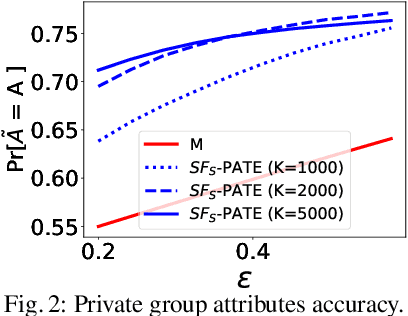
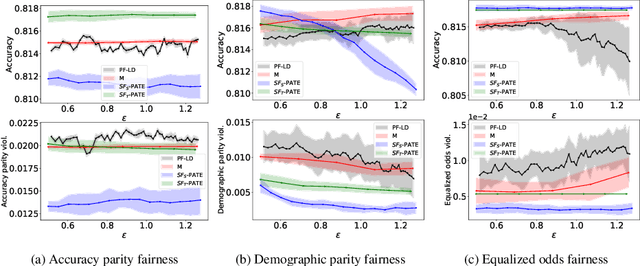
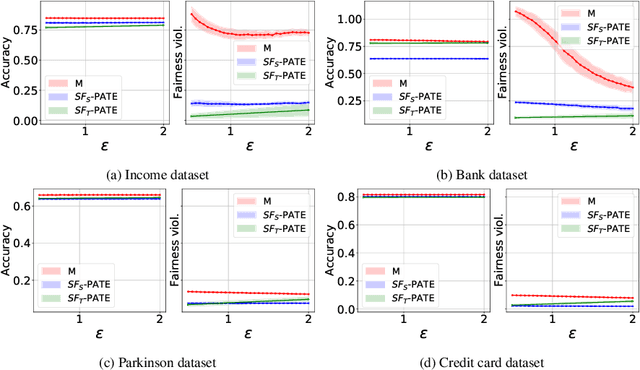
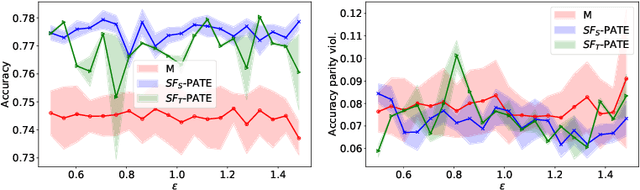
A critical concern in data-driven processes is to build models whose outcomes do not discriminate against some demographic groups, including gender, ethnicity, or age. To ensure non-discrimination in learning tasks, knowledge of the group attributes is essential. However, in practice, these attributes may not be available due to legal and ethical requirements. To address this challenge, this paper studies a model that protects the privacy of the individuals' sensitive information while also allowing it to learn non-discriminatory predictors. A key characteristic of the proposed model is to enable the adoption of off-the-selves and non-private fair models to create a privacy-preserving and fair model. The paper analyzes the relation between accuracy, privacy, and fairness, and the experimental evaluation illustrates the benefits of the proposed models on several prediction tasks. In particular, this proposal is the first to allow both scalable and accurate training of private and fair models for very large neural networks.
Risk-Aware Control and Optimization for High-Renewable Power Grids
Apr 02, 2022
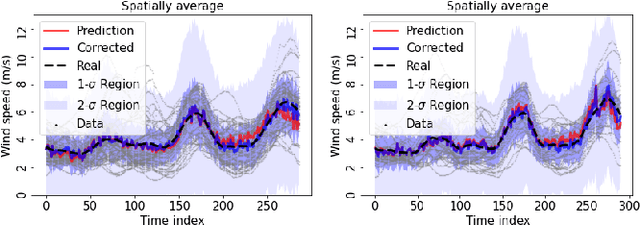
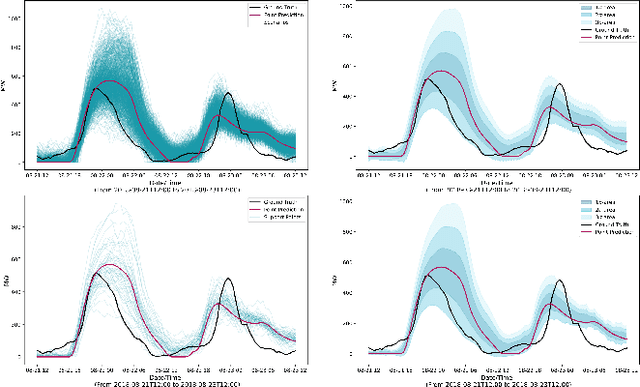
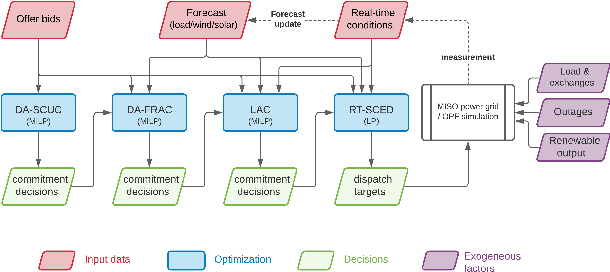
The transition of the electrical power grid from fossil fuels to renewable sources of energy raises fundamental challenges to the market-clearing algorithms that drive its operations. Indeed, the increased stochasticity in load and the volatility of renewable energy sources have led to significant increases in prediction errors, affecting the reliability and efficiency of existing deterministic optimization models. The RAMC project was initiated to investigate how to move from this deterministic setting into a risk-aware framework where uncertainty is quantified explicitly and incorporated in the market-clearing optimizations. Risk-aware market-clearing raises challenges on its own, primarily from a computational standpoint. This paper reviews how RAMC approaches risk-aware market clearing and presents some of its innovations in uncertainty quantification, optimization, and machine learning. Experimental results on real networks are presented.
Differential Privacy and Fairness in Decisions and Learning Tasks: A Survey
Feb 16, 2022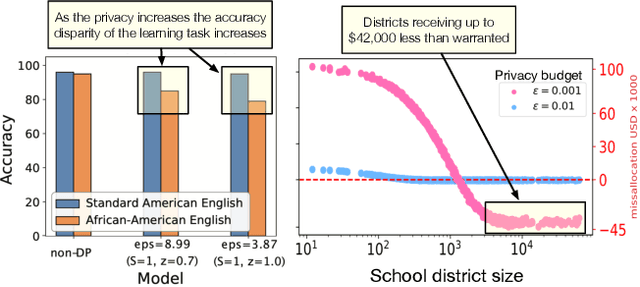
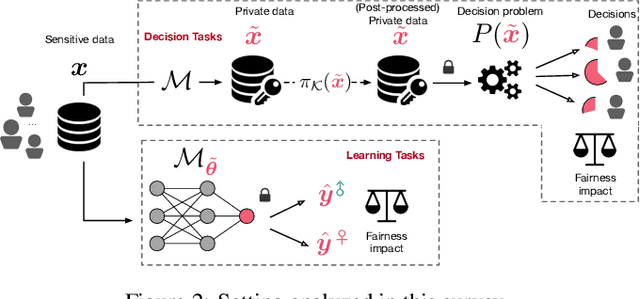
This paper surveys recent work in the intersection of differential privacy (DP) and fairness. It reviews the conditions under which privacy and fairness may have aligned or contrasting goals, analyzes how and why DP may exacerbate bias and unfairness in decision problems and learning tasks, and describes available mitigation measures for the fairness issues arising in DP systems. The survey provides a unified understanding of the main challenges and potential risks arising when deploying privacy-preserving machine-learning or decisions-making tasks under a fairness lens.
Post-processing of Differentially Private Data: A Fairness Perspective
Jan 24, 2022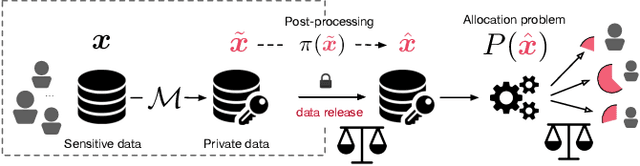

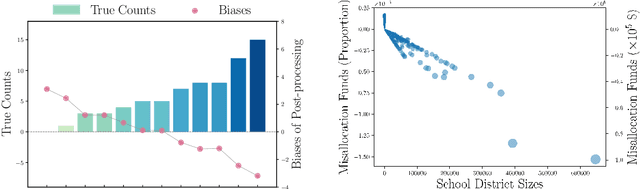

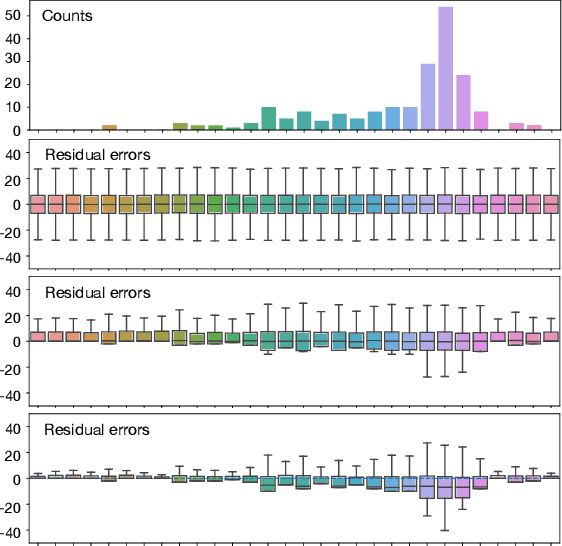
Post-processing immunity is a fundamental property of differential privacy: it enables arbitrary data-independent transformations to differentially private outputs without affecting their privacy guarantees. Post-processing is routinely applied in data-release applications, including census data, which are then used to make allocations with substantial societal impacts. This paper shows that post-processing causes disparate impacts on individuals or groups and analyzes two critical settings: the release of differentially private datasets and the use of such private datasets for downstream decisions, such as the allocation of funds informed by US Census data. In the first setting, the paper proposes tight bounds on the unfairness of traditional post-processing mechanisms, giving a unique tool to decision-makers to quantify the disparate impacts introduced by their release. In the second setting, this paper proposes a novel post-processing mechanism that is (approximately) optimal under different fairness metrics, either reducing fairness issues substantially or reducing the cost of privacy. The theoretical analysis is complemented with numerical simulations on Census data.
Learning Optimization Proxies for Large-Scale Security-Constrained Economic Dispatch
Dec 27, 2021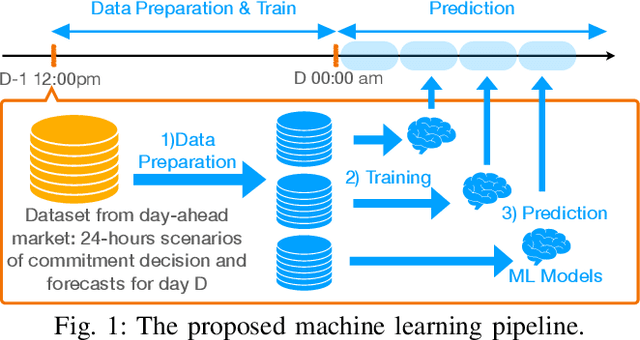
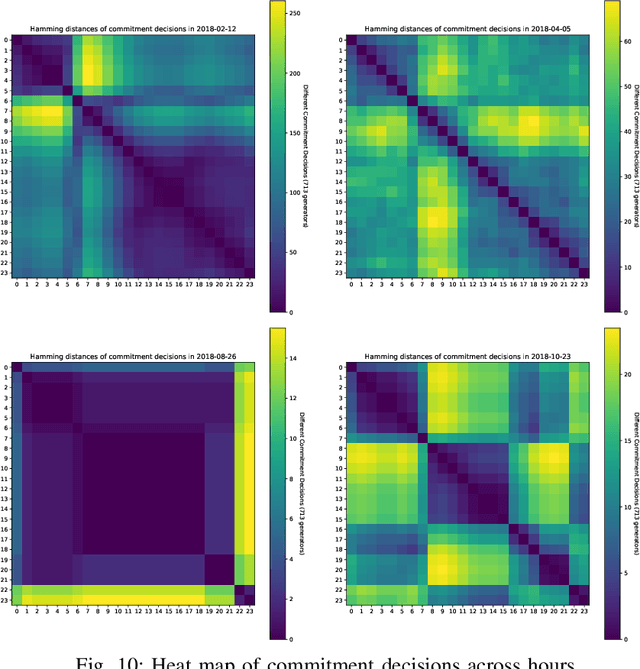
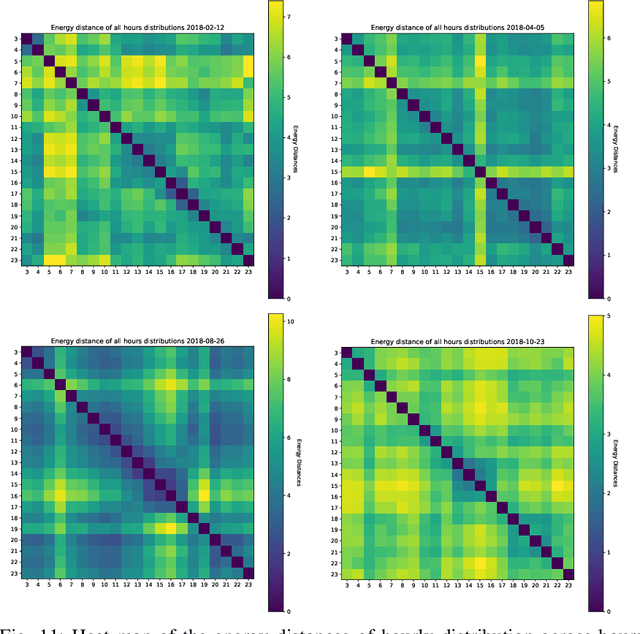
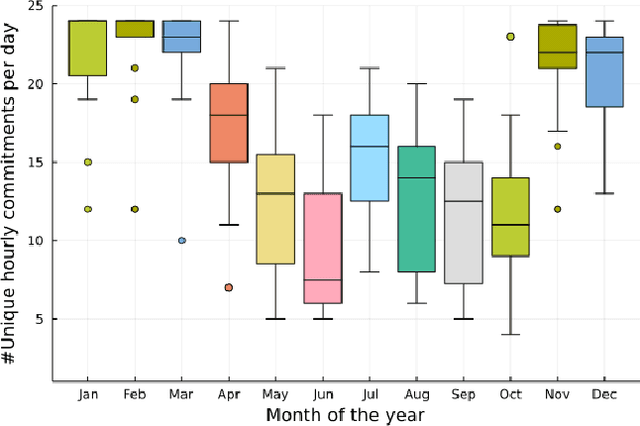
The Security-Constrained Economic Dispatch (SCED) is a fundamental optimization model for Transmission System Operators (TSO) to clear real-time energy markets while ensuring reliable operations of power grids. In a context of growing operational uncertainty, due to increased penetration of renewable generators and distributed energy resources, operators must continuously monitor risk in real-time, i.e., they must quickly assess the system's behavior under various changes in load and renewable production. Unfortunately, systematically solving an optimization problem for each such scenario is not practical given the tight constraints of real-time operations. To overcome this limitation, this paper proposes to learn an optimization proxy for SCED, i.e., a Machine Learning (ML) model that can predict an optimal solution for SCED in milliseconds. Motivated by a principled analysis of the market-clearing optimizations of MISO, the paper proposes a novel ML pipeline that addresses the main challenges of learning SCED solutions, i.e., the variability in load, renewable output and production costs, as well as the combinatorial structure of commitment decisions. A novel Classification-Then-Regression architecture is also proposed, to further capture the behavior of SCED solutions. Numerical experiments are reported on the French transmission system, and demonstrate the approach's ability to produce, within a time frame that is compatible with real-time operations, accurate optimization proxies that produce relative errors below $0.6\%$.
End-to-end Learning for Fair Ranking Systems
Nov 21, 2021
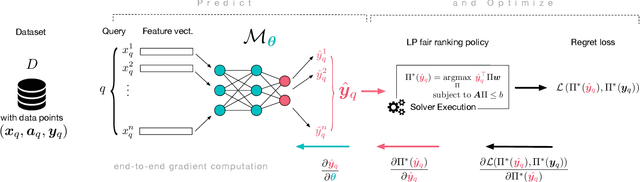
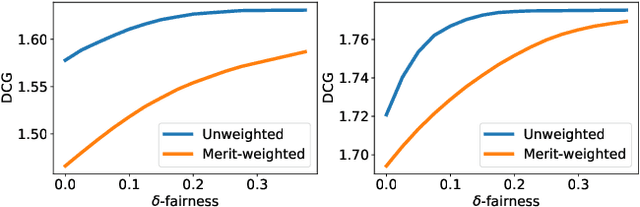
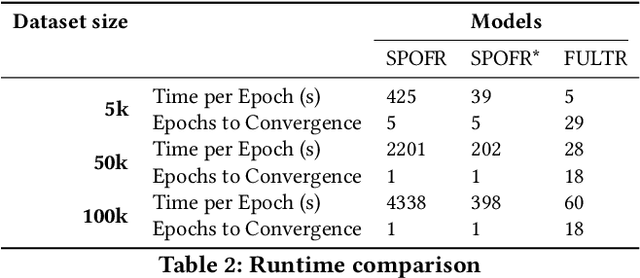
The learning-to-rank problem aims at ranking items to maximize exposure of those most relevant to a user query. A desirable property of such ranking systems is to guarantee some notion of fairness among specified item groups. While fairness has recently been considered in the context of learning-to-rank systems, current methods cannot provide guarantees on the fairness of the proposed ranking policies. This paper addresses this gap and introduces Smart Predict and Optimize for Fair Ranking (SPOFR), an integrated optimization and learning framework for fairness-constrained learning to rank. The end-to-end SPOFR framework includes a constrained optimization sub-model and produces ranking policies that are guaranteed to satisfy fairness constraints while allowing for fine control of the fairness-utility tradeoff. SPOFR is shown to significantly improve current state-of-the-art fair learning-to-rank systems with respect to established performance metrics.