 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParis Smaragdis
Unified Gradient Reweighting for Model Biasing with Applications to Source Separation
Oct 25, 2020
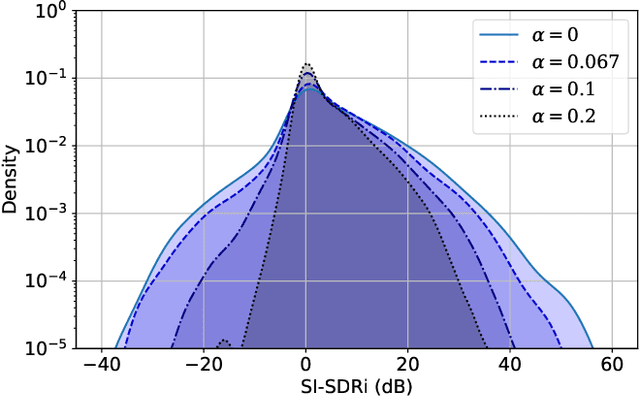
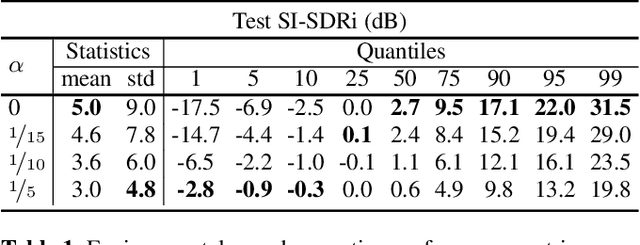
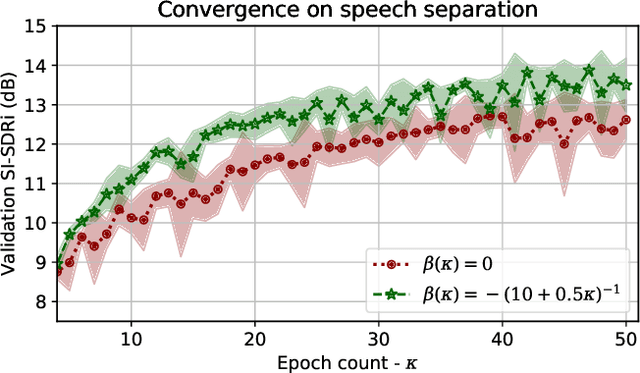
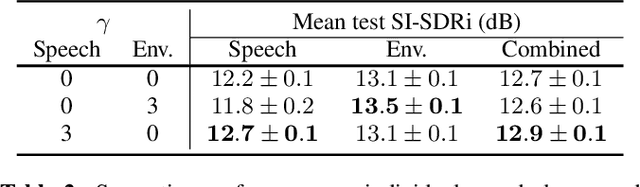
Recent deep learning approaches have shown great improvement in audio source separation tasks. However, the vast majority of such work is focused on improving average separation performance, often neglecting to examine or control the distribution of the results. In this paper, we propose a simple, unified gradient reweighting scheme, with a lightweight modification to bias the learning process of a model and steer it towards a certain distribution of results. More specifically, we reweight the gradient updates of each batch, using a user-specified probability distribution. We apply this method to various source separation tasks, in order to shift the operating point of the models towards different objectives. We demonstrate different parameterizations of our unified reweighting scheme can be used towards addressing several real-world problems, such as unreliable separation estimates. Our framework enables the user to control a robustness trade-off between worst and average performance. Moreover, we experimentally show that our unified reweighting scheme can also be used in order to shift the focus of the model towards being more accurate for user-specified sound classes or even towards easier examples in order to enable faster convergence.
Sudo rm -rf: Efficient Networks for Universal Audio Source Separation
Jul 14, 2020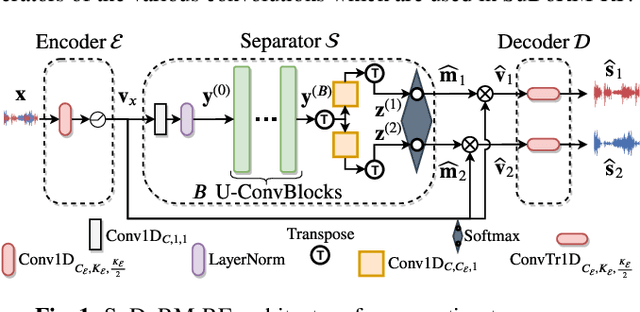
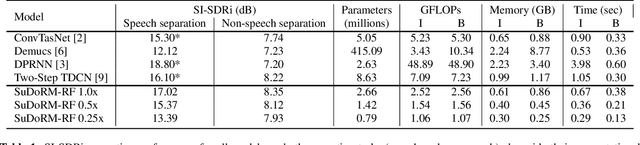
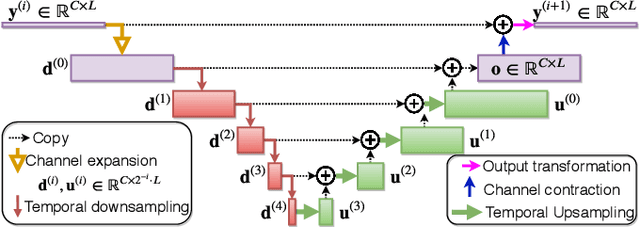
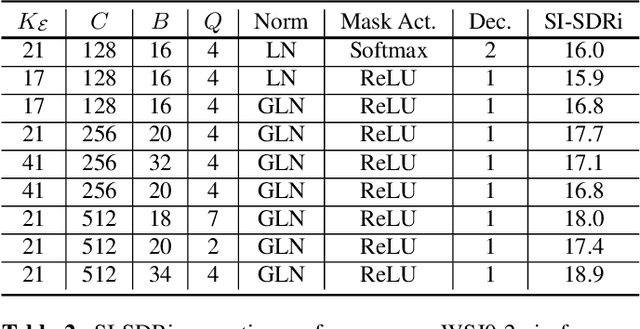
In this paper, we present an efficient neural network for end-to-end general purpose audio source separation. Specifically, the backbone structure of this convolutional network is the SUccessive DOwnsampling and Resampling of Multi-Resolution Features (SuDoRMRF) as well as their aggregation which is performed through simple one-dimensional convolutions. In this way, we are able to obtain high quality audio source separation with limited number of floating point operations, memory requirements, number of parameters and latency. Our experiments on both speech and environmental sound separation datasets show that SuDoRMRF performs comparably and even surpasses various state-of-the-art approaches with significantly higher computational resource requirements.
Two-Step Sound Source Separation: Training on Learned Latent Targets
Oct 23, 2019


In this paper, we propose a two-step training procedure for source separation via a deep neural network. In the first step we learn a transform (and it's inverse) to a latent space where masking-based separation performance using oracles is optimal. For the second step, we train a separation module that operates on the previously learned space. In order to do so, we also make use of a scale-invariant signal to distortion ratio (SI-SDR) loss function that works in the latent space, and we prove that it lower-bounds the SI-SDR in the time domain. We run various sound separation experiments that show how this approach can obtain better performance as compared to systems that learn the transform and the separation module jointly. The proposed methodology is general enough to be applicable to a large class of neural network end-to-end separation systems.
Continual Learning of New Sound Classes using Generative Replay
Jun 03, 2019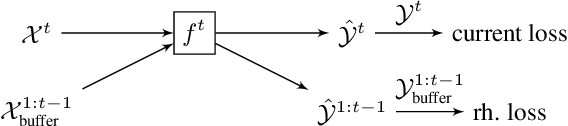

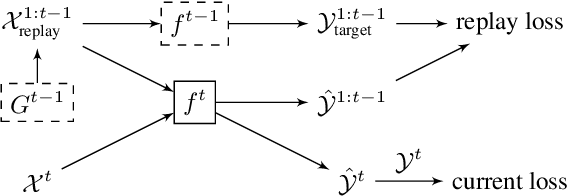
Continual learning consists in incrementally training a model on a sequence of datasets and testing on the union of all datasets. In this paper, we examine continual learning for the problem of sound classification, in which we wish to refine already trained models to learn new sound classes. In practice one does not want to maintain all past training data and retrain from scratch, but naively updating a model with new data(sets) results in a degradation of already learned tasks, which is referred to as "catastrophic forgetting." We develop a generative replay procedure for generating training audio spectrogram data, in place of keeping older training datasets. We show that by incrementally refining a classifier with generative replay a generator that is 4% of the size of all previous training data matches the performance of refining the classifier keeping 20% of all previous training data. We thus conclude that we can extend a trained sound classifier to learn new classes without having to keep previously used datasets.
Deep Tensor Factorization for Spatially-Aware Scene Decomposition
May 03, 2019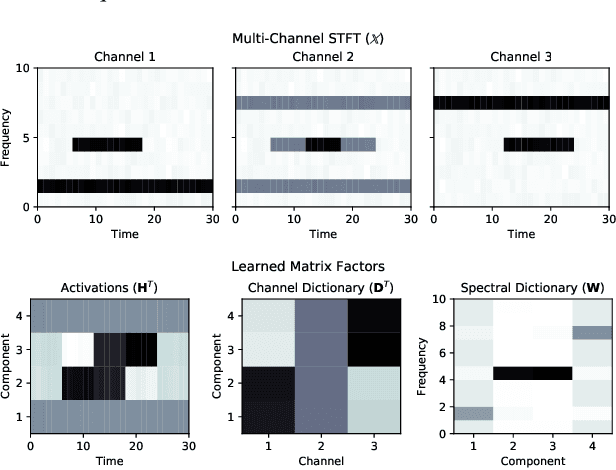
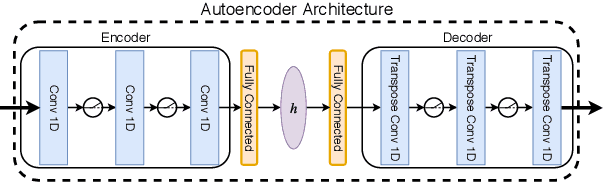
We propose a completely unsupervised method to understand audio scenes observed with random microphone arrangements by decomposing the scene into its constituent sources and their relative presence in each microphone. To this end, we formulate a neural network architecture that can be interpreted as a nonnegative tensor factorization of a multi-channel audio recording. By clustering on the learned network parameters corresponding to channel content, we can learn sources' individual spectral dictionaries and their activation patterns over time. Our method allows us to leverage deep learning advances like end-to-end training, while also allowing stochastic minibatch training so that we can feasibly decompose realistic audio scenes that are intractable to decompose using standard methods. This neural network architecture is easily extensible to other kinds of tensor factorizations.
Unsupervised Deep Clustering for Source Separation: Direct Learning from Mixtures using Spatial Information
Nov 05, 2018



We present a monophonic source separation system that is trained by only observing mixtures with no ground truth separation information. We use a deep clustering approach which trains on multi-channel mixtures and learns to project spectrogram bins to source clusters that correlate with various spatial features. We show that using such a training process we can obtain separation performance that is as good as making use of ground truth separation information. Once trained, this system is capable of performing sound separation on monophonic inputs, despite having learned how to do so using multi-channel recordings.
Learning the Base Distribution in Implicit Generative Models
Mar 13, 2018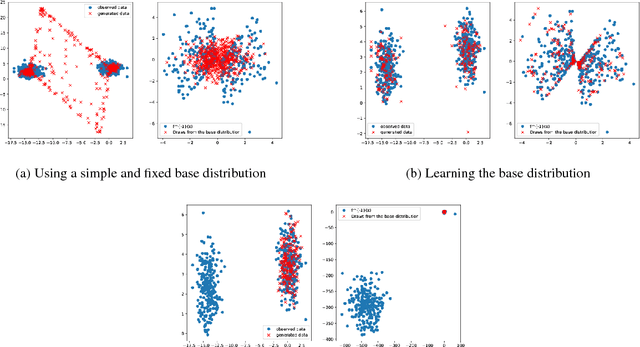

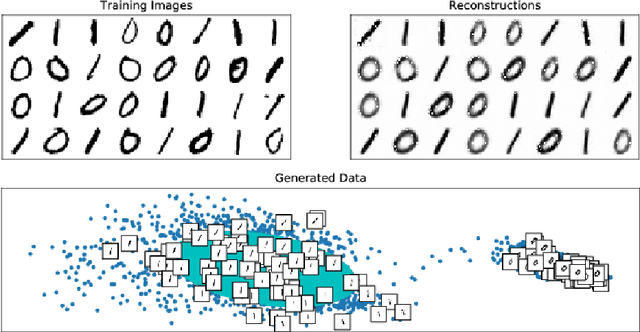
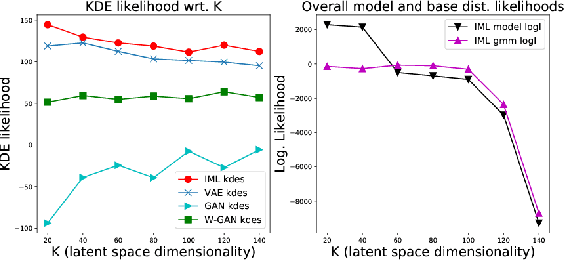
Popular generative model learning methods such as Generative Adversarial Networks (GANs), and Variational Autoencoders (VAE) enforce the latent representation to follow simple distributions such as isotropic Gaussian. In this paper, we argue that learning a complicated distribution over the latent space of an auto-encoder enables more accurate modeling of complicated data distributions. Based on this observation, we propose a two stage optimization procedure which maximizes an approximate implicit density model. We experimentally verify that our method outperforms GANs and VAEs on two image datasets (MNIST, CELEB-A). We also show that our approach is amenable to learning generative model for sequential data, by learning to generate speech and music.
Generative Adversarial Source Separation
Oct 30, 2017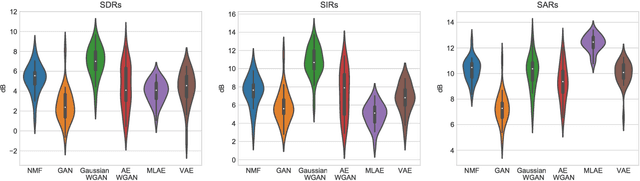
Generative source separation methods such as non-negative matrix factorization (NMF) or auto-encoders, rely on the assumption of an output probability density. Generative Adversarial Networks (GANs) can learn data distributions without needing a parametric assumption on the output density. We show on a speech source separation experiment that, a multi-layer perceptron trained with a Wasserstein-GAN formulation outperforms NMF, auto-encoders trained with maximum likelihood, and variational auto-encoders in terms of source to distortion ratio.
Supervised and Unsupervised Speech Enhancement Using Nonnegative Matrix Factorization
Sep 15, 2017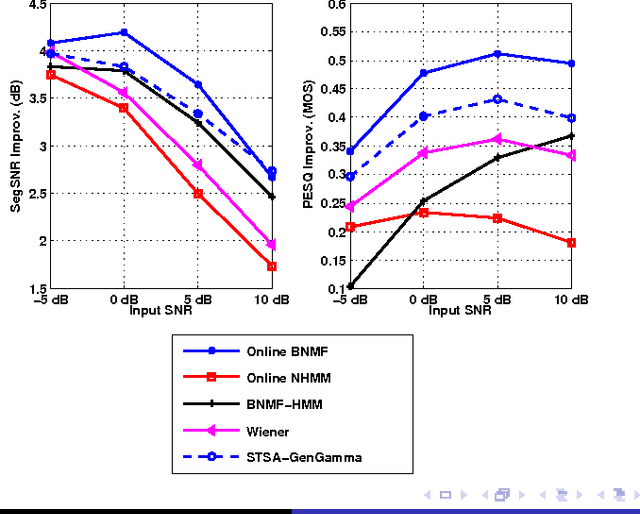
Reducing the interference noise in a monaural noisy speech signal has been a challenging task for many years. Compared to traditional unsupervised speech enhancement methods, e.g., Wiener filtering, supervised approaches, such as algorithms based on hidden Markov models (HMM), lead to higher-quality enhanced speech signals. However, the main practical difficulty of these approaches is that for each noise type a model is required to be trained a priori. In this paper, we investigate a new class of supervised speech denoising algorithms using nonnegative matrix factorization (NMF). We propose a novel speech enhancement method that is based on a Bayesian formulation of NMF (BNMF). To circumvent the mismatch problem between the training and testing stages, we propose two solutions. First, we use an HMM in combination with BNMF (BNMF-HMM) to derive a minimum mean square error (MMSE) estimator for the speech signal with no information about the underlying noise type. Second, we suggest a scheme to learn the required noise BNMF model online, which is then used to develop an unsupervised speech enhancement system. Extensive experiments are carried out to investigate the performance of the proposed methods under different conditions. Moreover, we compare the performance of the developed algorithms with state-of-the-art speech enhancement schemes using various objective measures. Our simulations show that the proposed BNMF-based methods outperform the competing algorithms substantially.
Diagonal RNNs in Symbolic Music Modeling
Apr 19, 2017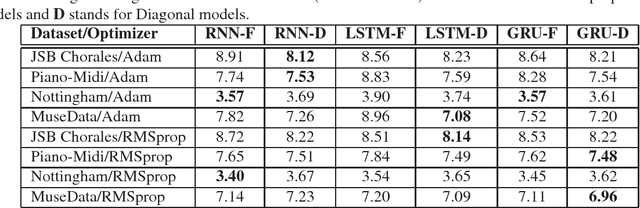
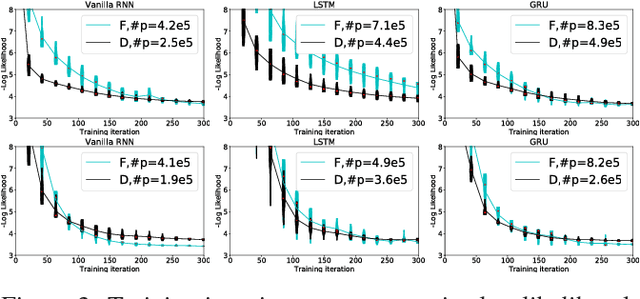
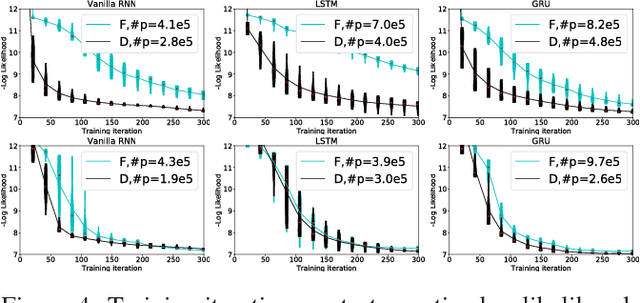
In this paper, we propose a new Recurrent Neural Network (RNN) architecture. The novelty is simple: We use diagonal recurrent matrices instead of full. This results in better test likelihood and faster convergence compared to regular full RNNs in most of our experiments. We show the benefits of using diagonal recurrent matrices with popularly used LSTM and GRU architectures as well as with the vanilla RNN architecture, on four standard symbolic music datasets.