 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Loss Function for Generative Neural Networks Based on Watson's Perceptual Model
Jun 26, 2020



To train Variational Autoencoders (VAEs) to generate realistic imagery requires a loss function that reflects human perception of image similarity. We propose such a loss function based on Watson's perceptual model, which computes a weighted distance in frequency space and accounts for luminance and contrast masking. We extend the model to color images, increase its robustness to translation by using the Fourier Transform, remove artifacts due to splitting the image into blocks, and make it differentiable. In experiments, VAEs trained with the new loss function generated realistic, high-quality image samples. Compared to using the Euclidean distance and the Structural Similarity Index, the images were less blurry; compared to deep neural network based losses, the new approach required less computational resources and generated images with less artifacts.
The Hessian Estimation Evolution Strategy
Mar 30, 2020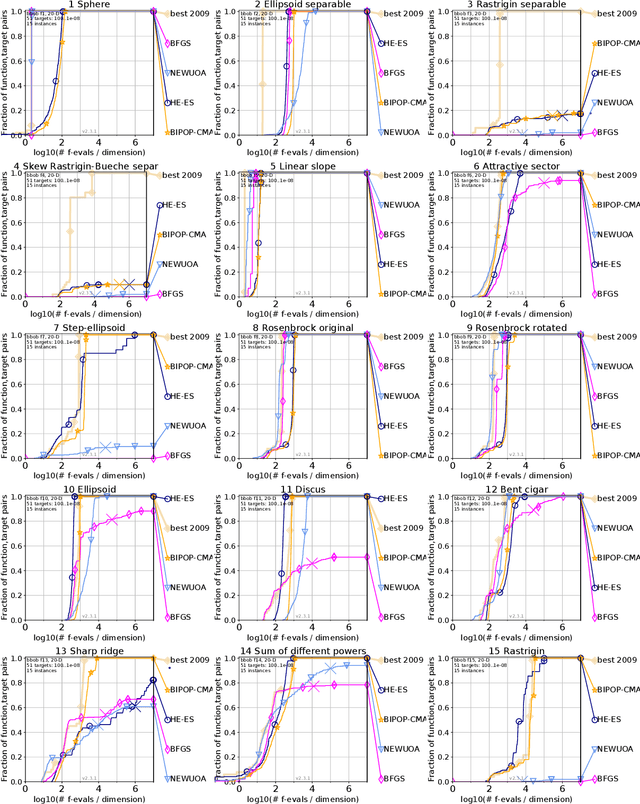
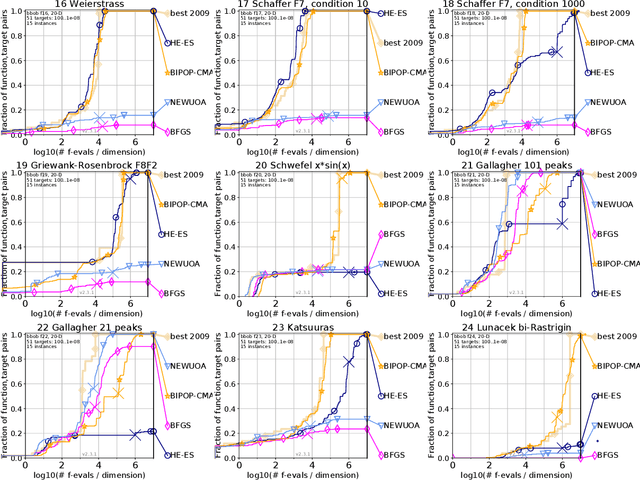
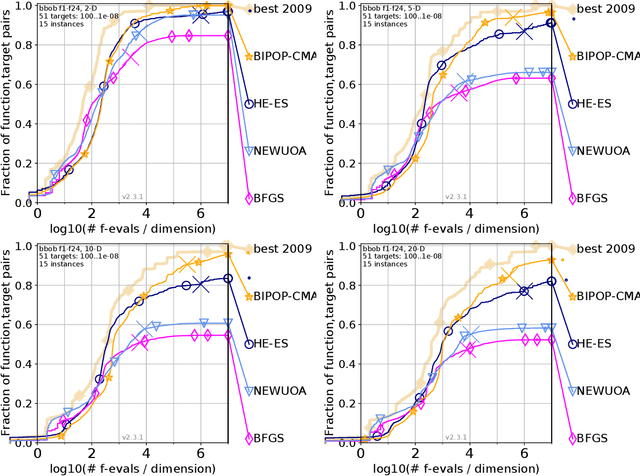
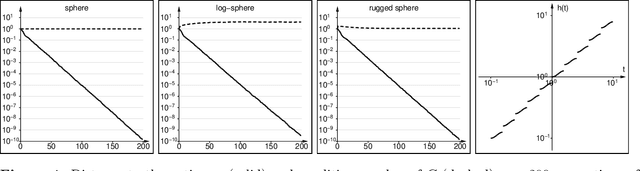
We present a novel black box optimization algorithm called Hessian Estimation Evolution Strategy. The algorithm updates the covariance matrix of its sampling distribution by directly estimating the curvature of the objective function. This algorithm design is targeted at twice continuously differentiable problems. For this, we extend the cumulative step-size adaptation algorithm of the CMA-ES to mirrored sampling. We demonstrate that our approach to covariance matrix adaptation is efficient by evaluation it on the BBOB/COCO testbed. We also show that the algorithm is surprisingly robust when its core assumption of a twice continuously differentiable objective function is violated. The approach yields a new evolution strategy with competitive performance, and at the same time it also offers an interesting alternative to the usual covariance matrix update mechanism.
Population-Contrastive-Divergence: Does Consistency help with RBM training?
Jun 28, 2017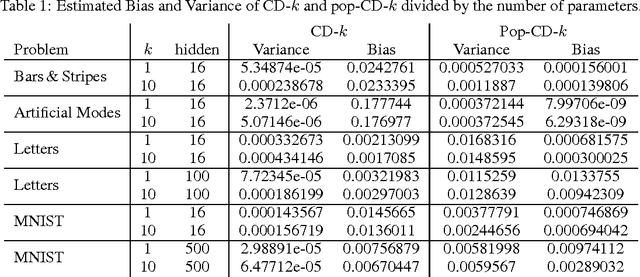
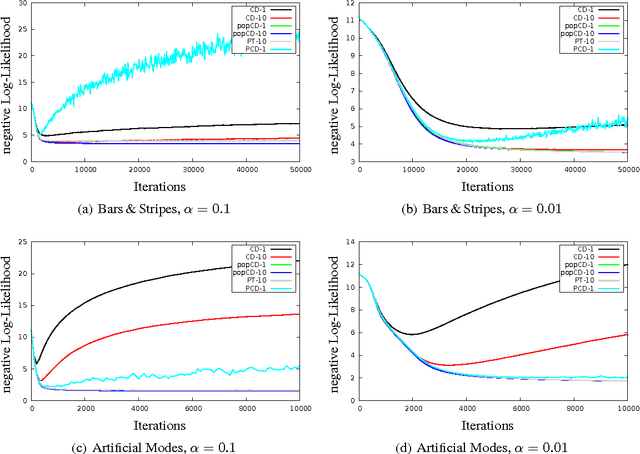
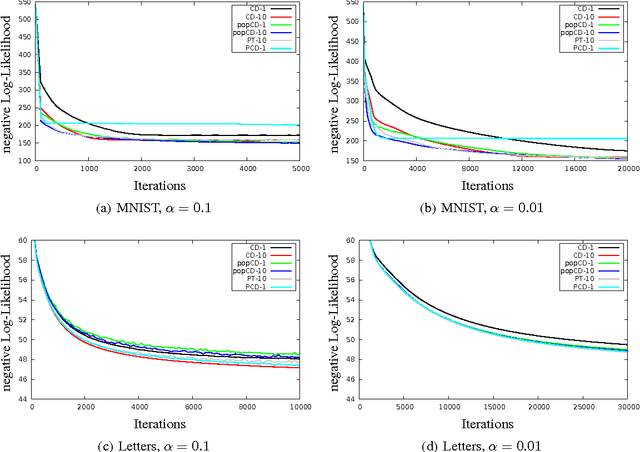
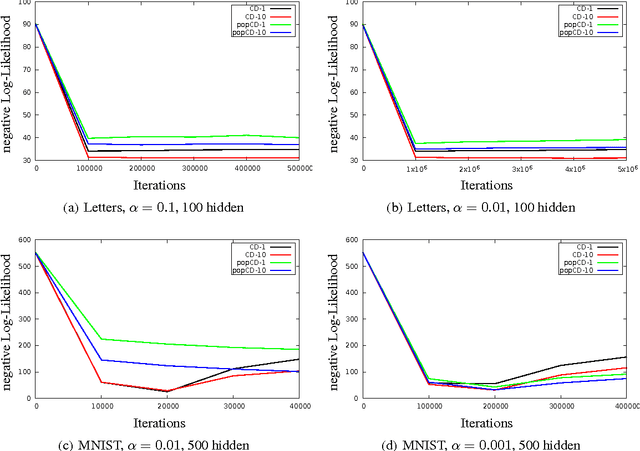
Estimating the log-likelihood gradient with respect to the parameters of a Restricted Boltzmann Machine (RBM) typically requires sampling using Markov Chain Monte Carlo (MCMC) techniques. To save computation time, the Markov chains are only run for a small number of steps, which leads to a biased estimate. This bias can cause RBM training algorithms such as Contrastive Divergence (CD) learning to deteriorate. We adopt the idea behind Population Monte Carlo (PMC) methods to devise a new RBM training algorithm termed Population-Contrastive-Divergence (pop-CD). Compared to CD, it leads to a consistent estimate and may have a significantly lower bias. Its computational overhead is negligible compared to CD. However, the variance of the gradient estimate increases. We experimentally show that pop-CD can significantly outperform CD. In many cases, we observed a smaller bias and achieved higher log-likelihood values. However, when the RBM distribution has many hidden neurons, the consistent estimate of pop-CD may still have a considerable bias and the variance of the gradient estimate requires a smaller learning rate. Thus, despite its superior theoretical properties, it is not advisable to use pop-CD in its current form on large problems.
Convolutional neural networks for segmentation and object detection of human semen
Apr 03, 2017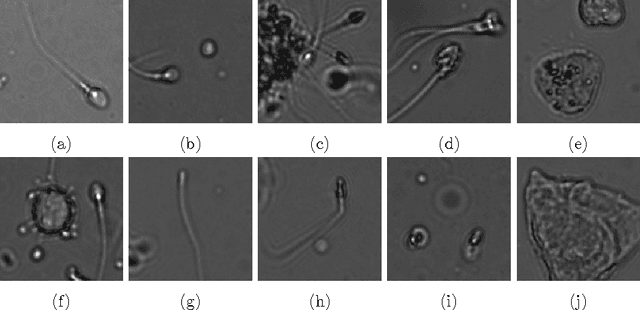
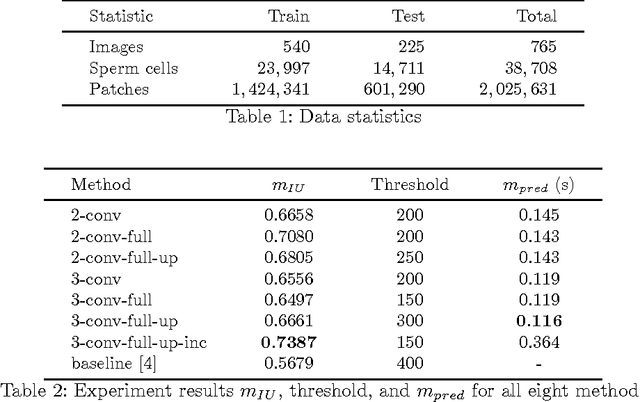
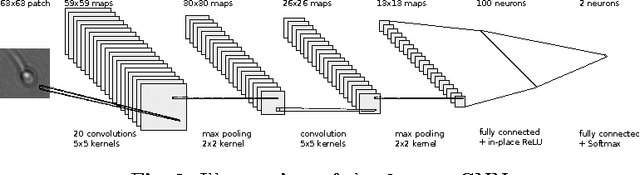
We compare a set of convolutional neural network (CNN) architectures for the task of segmenting and detecting human sperm cells in an image taken from a semen sample. In contrast to previous work, samples are not stained or washed to allow for full sperm quality analysis, making analysis harder due to clutter. Our results indicate that training on full images is superior to training on patches when class-skew is properly handled. Full image training including up-sampling during training proves to be beneficial in deep CNNs for pixel wise accuracy and detection performance. Predicted sperm cells are found by using connected components on the CNN predictions. We investigate optimization of a threshold parameter on the size of detected components. Our best network achieves 93.87% precision and 91.89% recall on our test dataset after thresholding outperforming a classical mage analysis approach.