 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Color Illusions from the Perspective of Computational Color Constancy
Dec 20, 2023



Color constancy and color illusion perception are two phenomena occurring in the human visual system, which can help us reveal unknown mechanisms of human perception. For decades computer vision scientists have developed numerous color constancy methods, which estimate the reflectance of the surface by discounting the illuminant. However, color illusions have not been analyzed in detail in the field of computational color constancy, which we find surprising since the relationship they share is significant and may let us design more robust systems. We argue that any model that can reproduce our sensation on color illusions should also be able to provide pixel-wise estimates of the light source. In other words, we suggest that the analysis of color illusions helps us to improve the performance of the existing global color constancy methods, and enable them to provide pixel-wise estimates for scenes illuminated by multiple light sources. In this study, we share the outcomes of our investigation in which we take several color constancy methods and modify them to reproduce the behavior of the human visual system on color illusions. Also, we show that parameters purely extracted from illusions are able to improve the performance of color constancy methods. A noteworthy outcome is that our strategy based on the investigation of color illusions outperforms the state-of-the-art methods that are specifically designed to transform global color constancy algorithms into multi-illuminant algorithms.
PAS-MEF: Multi-exposure image fusion based on principal component analysis, adaptive well-exposedness and saliency map
May 25, 2021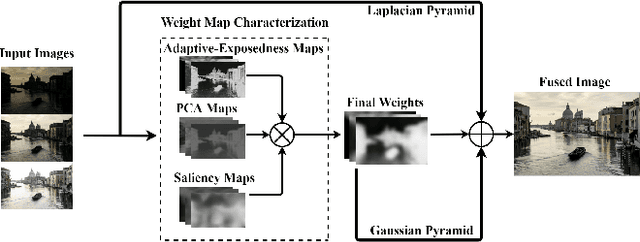
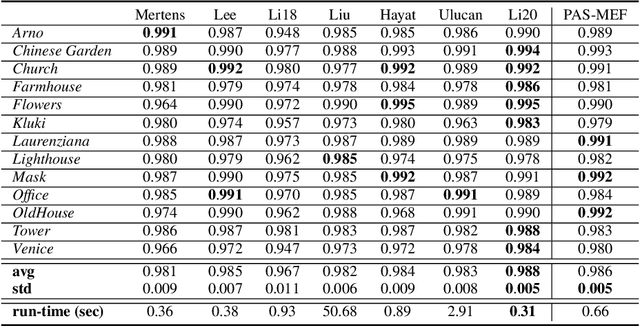


High dynamic range (HDR) imaging enables to immortalize natural scenes similar to the way that they are perceived by human observers. With regular low dynamic range (LDR) capture/display devices, significant details may not be preserved in images due to the huge dynamic range of natural scenes. To minimize the information loss and produce high quality HDR-like images for LDR screens, this study proposes an efficient multi-exposure fusion (MEF) approach with a simple yet effective weight extraction method relying on principal component analysis, adaptive well-exposedness and saliency maps. These weight maps are later refined through a guided filter and the fusion is carried out by employing a pyramidal decomposition. Experimental comparisons with existing techniques demonstrate that the proposed method produces very strong statistical and visual results.
Convolutional Neural Networks: A Binocular Vision Perspective
Dec 21, 2019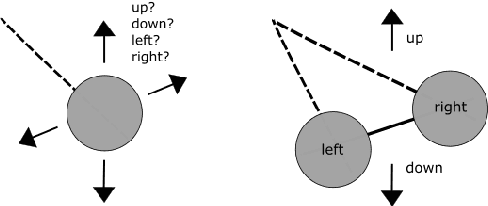
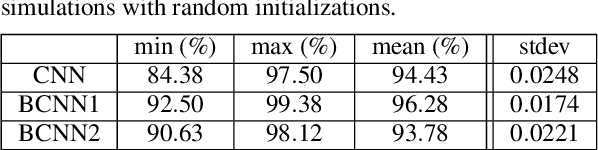
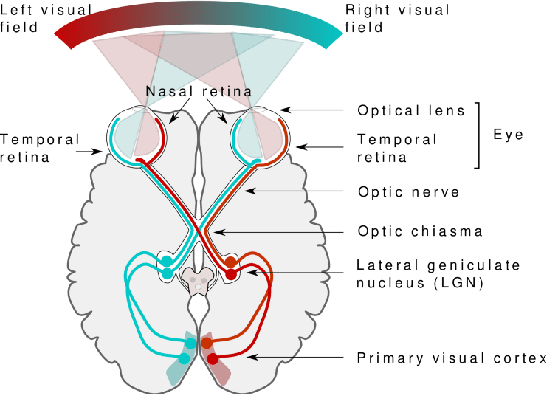

It is arguable that whether the single camera captured (monocular) image datasets are sufficient enough to train and test convolutional neural networks (CNNs) for imitating the biological neural network structures of the human brain. As human visual system works in binocular, the collaboration of the eyes with the two brain lobes needs more investigation for improvements in such CNN-based visual imagery analysis applications. It is indeed questionable that if respective visual fields of each eye and the associated brain lobes are responsible for different learning abilities of the same scene. There are such open questions in this field of research which need rigorous investigation in order to further understand the nature of the human visual system, hence improve the currently available deep learning applications. This position paper analyses a binocular CNNs architecture that is more analogous to the biological structure of the human visual system than the conventional deep learning techniques. While taking a structure called optic chiasma into account, this architecture consists of basically two parallel CNN structures associated with each visual field and the brain lobe, fully connected later possibly as in the primary visual cortex (V1). Experimental results demonstrate that binocular learning of two different visual fields leads to better classification rates on average, when compared to classical CNN architectures.