 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoseong Park
An Empirical Study on the Membership Inference Attack against Tabular Data Synthesis Models
Aug 25, 2022
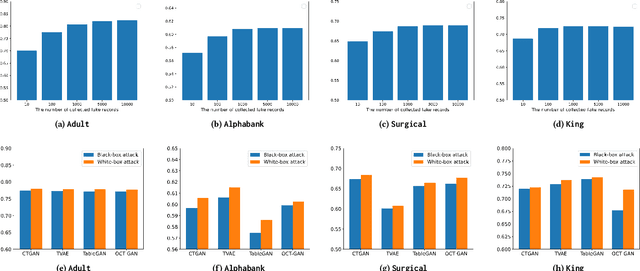
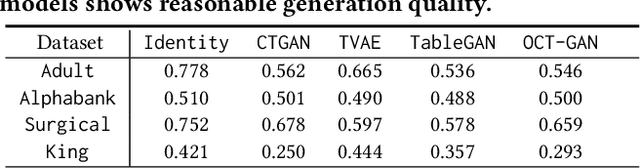

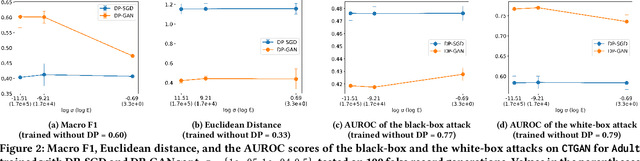
Tabular data typically contains private and important information; thus, precautions must be taken before they are shared with others. Although several methods (e.g., differential privacy and k-anonymity) have been proposed to prevent information leakage, in recent years, tabular data synthesis models have become popular because they can well trade-off between data utility and privacy. However, recent research has shown that generative models for image data are susceptible to the membership inference attack, which can determine whether a given record was used to train a victim synthesis model. In this paper, we investigate the membership inference attack in the context of tabular data synthesis. We conduct experiments on 4 state-of-the-art tabular data synthesis models under two attack scenarios (i.e., one black-box and one white-box attack), and find that the membership inference attack can seriously jeopardize these models. We next conduct experiments to evaluate how well two popular differentially-private deep learning training algorithms, DP-SGD and DP-GAN, can protect the models against the attack. Our key finding is that both algorithms can largely alleviate this threat by sacrificing the generation quality.
AdamNODEs: When Neural ODE Meets Adaptive Moment Estimation
Jul 13, 2022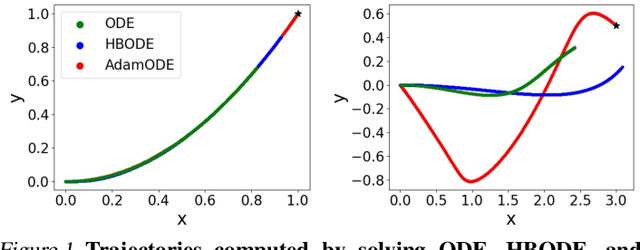


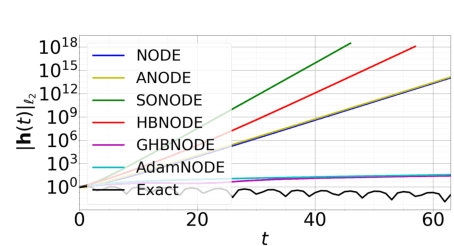
Recent work by Xia et al. leveraged the continuous-limit of the classical momentum accelerated gradient descent and proposed heavy-ball neural ODEs. While this model offers computational efficiency and high utility over vanilla neural ODEs, this approach often causes the overshooting of internal dynamics, leading to unstable training of a model. Prior work addresses this issue by using ad-hoc approaches, e.g., bounding the internal dynamics using specific activation functions, but the resulting models do not satisfy the exact heavy-ball ODE. In this work, we propose adaptive momentum estimation neural ODEs (AdamNODEs) that adaptively control the acceleration of the classical momentum-based approach. We find that its adjoint states also satisfy AdamODE and do not require ad-hoc solutions that the prior work employs. In evaluation, we show that AdamNODEs achieve the lowest training loss and efficacy over existing neural ODEs. We also show that AdamNODEs have better training stability than classical momentum-based neural ODEs. This result sheds some light on adapting the techniques proposed in the optimization community to improving the training and inference of neural ODEs further. Our code is available at https://github.com/pmcsh04/AdamNODE.
SPI-GAN: Distilling Score-based Generative Models with Straight-Path Interpolations
Jun 29, 2022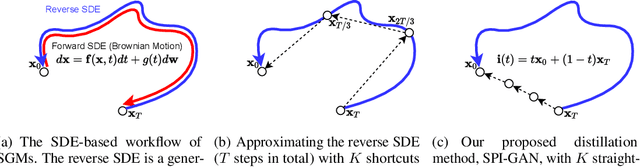
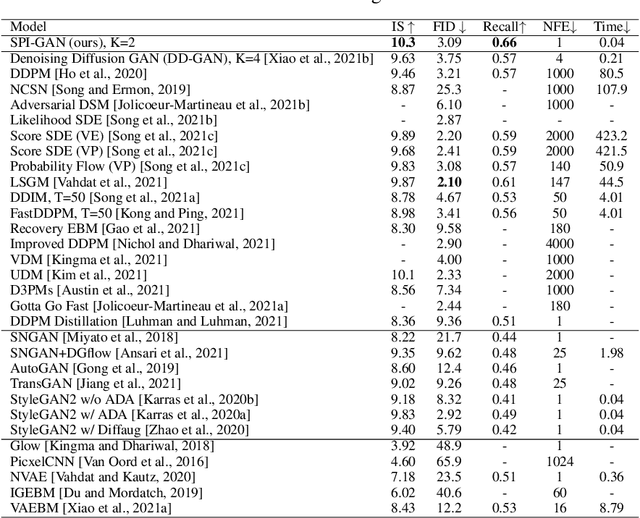
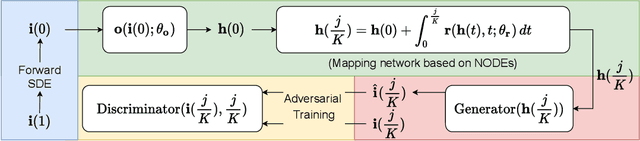
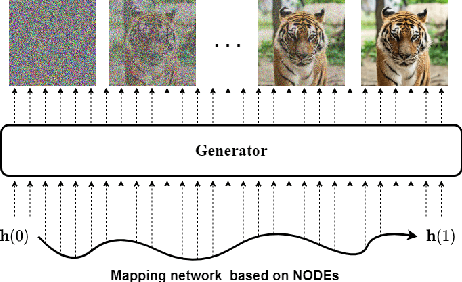
Score-based generative models (SGMs) are a recently proposed paradigm for deep generative tasks and now show the state-of-the-art sampling performance. It is known that the original SGM design solves the two problems of the generative trilemma: i) sampling quality, and ii) sampling diversity. However, the last problem of the trilemma was not solved, i.e., their training/sampling complexity is notoriously high. To this end, distilling SGMs into simpler models, e.g., generative adversarial networks (GANs), is gathering much attention currently. We present an enhanced distillation method, called straight-path interpolation GAN (SPI-GAN), which can be compared to the state-of-the-art shortcut-based distillation method, called denoising diffusion GAN (DD-GAN). However, our method corresponds to an extreme method that does not use any intermediate shortcut information of the reverse SDE path, in which case DD-GAN fails to obtain good results. Nevertheless, our straight-path interpolation method greatly stabilizes the overall training process. As a result, SPI-GAN is one of the best models in terms of the sampling quality/diversity/time for CIFAR-10, CelebA-HQ-256, and LSUN-Church-256.
SOS: Score-based Oversampling for Tabular Data
Jun 17, 2022
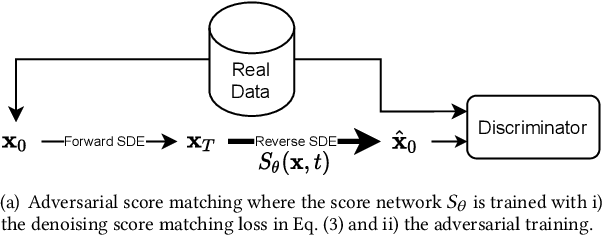
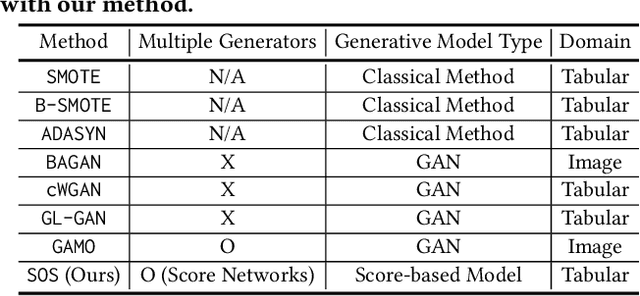
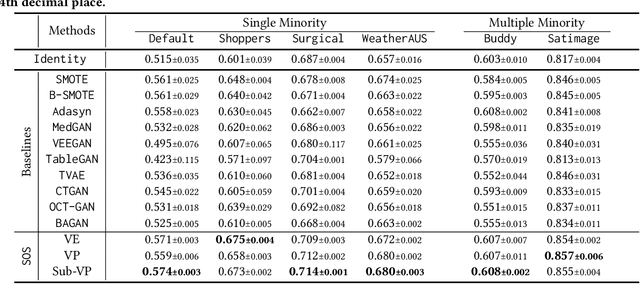
Score-based generative models (SGMs) are a recent breakthrough in generating fake images. SGMs are known to surpass other generative models, e.g., generative adversarial networks (GANs) and variational autoencoders (VAEs). Being inspired by their big success, in this work, we fully customize them for generating fake tabular data. In particular, we are interested in oversampling minor classes since imbalanced classes frequently lead to sub-optimal training outcomes. To our knowledge, we are the first presenting a score-based tabular data oversampling method. Firstly, we re-design our own score network since we have to process tabular data. Secondly, we propose two options for our generation method: the former is equivalent to a style transfer for tabular data and the latter uses the standard generative policy of SGMs. Lastly, we define a fine-tuning method, which further enhances the oversampling quality. In our experiments with 6 datasets and 10 baselines, our method outperforms other oversampling methods in all cases.
LORD: Lower-Dimensional Embedding of Log-Signature in Neural Rough Differential Equations
Apr 19, 2022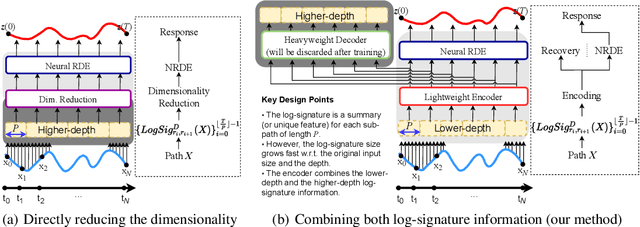

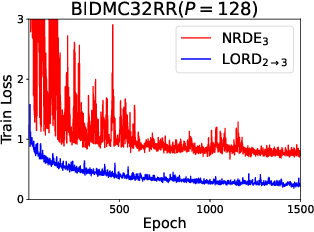
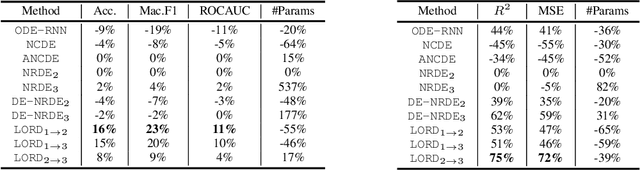
The problem of processing very long time-series data (e.g., a length of more than 10,000) is a long-standing research problem in machine learning. Recently, one breakthrough, called neural rough differential equations (NRDEs), has been proposed and has shown that it is able to process such data. Their main concept is to use the log-signature transform, which is known to be more efficient than the Fourier transform for irregular long time-series, to convert a very long time-series sample into a relatively shorter series of feature vectors. However, the log-signature transform causes non-trivial spatial overheads. To this end, we present the method of LOweR-Dimensional embedding of log-signature (LORD), where we define an NRDE-based autoencoder to implant the higher-depth log-signature knowledge into the lower-depth log-signature. We show that the encoder successfully combines the higher-depth and the lower-depth log-signature knowledge, which greatly stabilizes the training process and increases the model accuracy. In our experiments with benchmark datasets, the improvement ratio by our method is up to 75\% in terms of various classification and forecasting evaluation metrics.
EXIT: Extrapolation and Interpolation-based Neural Controlled Differential Equations for Time-series Classification and Forecasting
Apr 19, 2022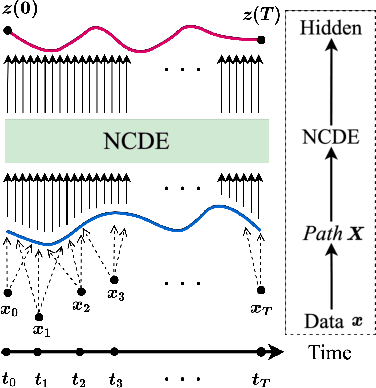
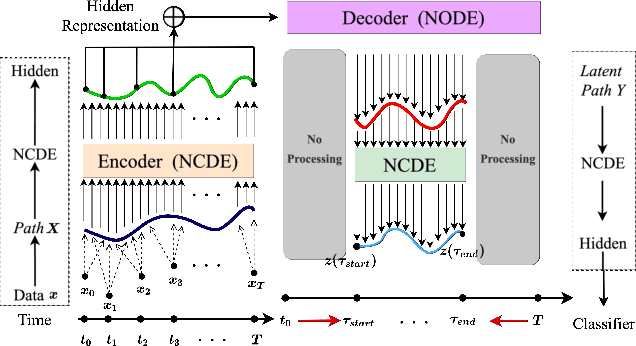
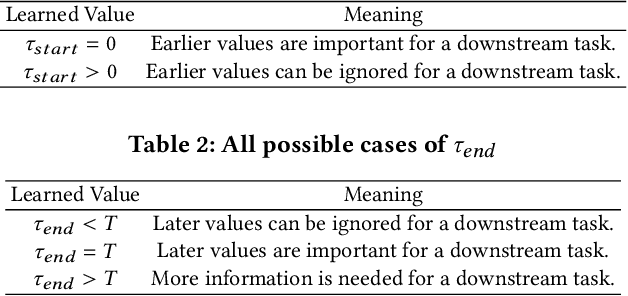
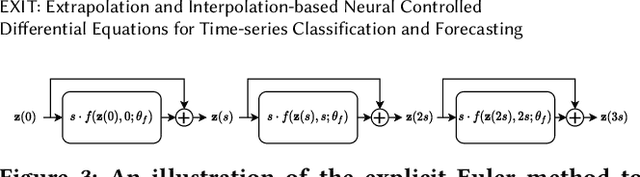
Deep learning inspired by differential equations is a recent research trend and has marked the state of the art performance for many machine learning tasks. Among them, time-series modeling with neural controlled differential equations (NCDEs) is considered as a breakthrough. In many cases, NCDE-based models not only provide better accuracy than recurrent neural networks (RNNs) but also make it possible to process irregular time-series. In this work, we enhance NCDEs by redesigning their core part, i.e., generating a continuous path from a discrete time-series input. NCDEs typically use interpolation algorithms to convert discrete time-series samples to continuous paths. However, we propose to i) generate another latent continuous path using an encoder-decoder architecture, which corresponds to the interpolation process of NCDEs, i.e., our neural network-based interpolation vs. the existing explicit interpolation, and ii) exploit the generative characteristic of the decoder, i.e., extrapolation beyond the time domain of original data if needed. Therefore, our NCDE design can use both the interpolated and the extrapolated information for downstream machine learning tasks. In our experiments with 5 real-world datasets and 12 baselines, our extrapolation and interpolation-based NCDEs outperform existing baselines by non-trivial margins.
It's All In the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
Apr 01, 2022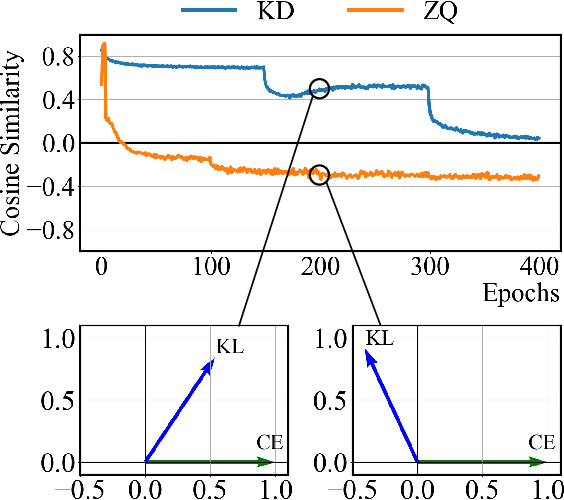
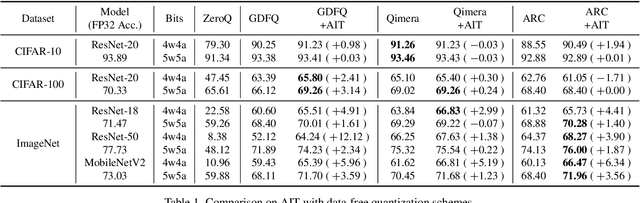
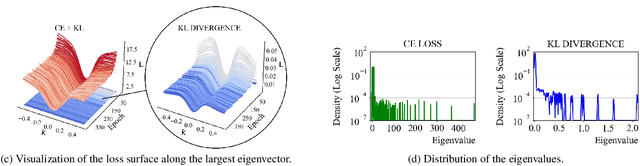
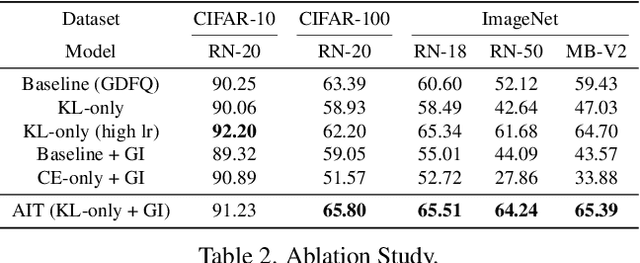
Model quantization is considered as a promising method to greatly reduce the resource requirements of deep neural networks. To deal with the performance drop induced by quantization errors, a popular method is to use training data to fine-tune quantized networks. In real-world environments, however, such a method is frequently infeasible because training data is unavailable due to security, privacy, or confidentiality concerns. Zero-shot quantization addresses such problems, usually by taking information from the weights of a full-precision teacher network to compensate the performance drop of the quantized networks. In this paper, we first analyze the loss surface of state-of-the-art zero-shot quantization techniques and provide several findings. In contrast to usual knowledge distillation problems, zero-shot quantization often suffers from 1) the difficulty of optimizing multiple loss terms together, and 2) the poor generalization capability due to the use of synthetic samples. Furthermore, we observe that many weights fail to cross the rounding threshold during training the quantized networks even when it is necessary to do so for better performance. Based on the observations, we propose AIT, a simple yet powerful technique for zero-shot quantization, which addresses the aforementioned two problems in the following way: AIT i) uses a KL distance loss only without a cross-entropy loss, and ii) manipulates gradients to guarantee that a certain portion of weights are properly updated after crossing the rounding thresholds. Experiments show that AIT outperforms the performance of many existing methods by a great margin, taking over the overall state-of-the-art position in the field.
Invertible Tabular GANs: Killing Two Birds with OneStone for Tabular Data Synthesis
Feb 08, 2022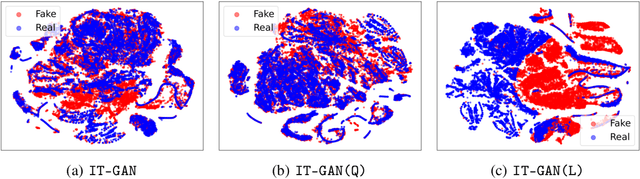
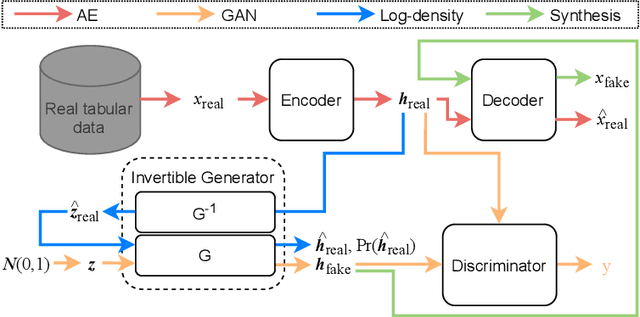
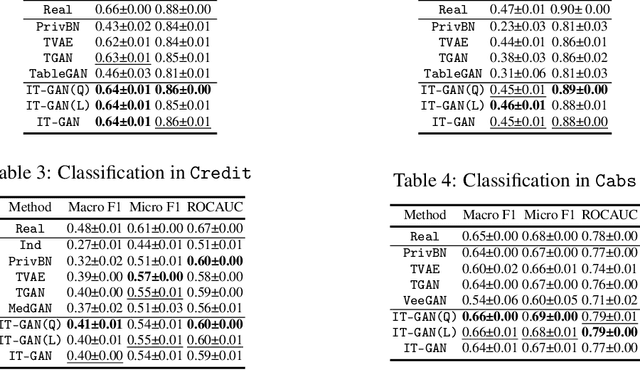
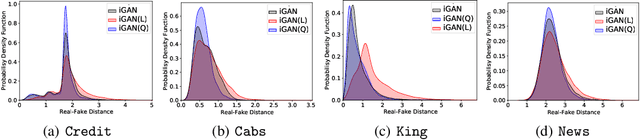
Tabular data synthesis has received wide attention in the literature. This is because available data is often limited, incomplete, or cannot be obtained easily, and data privacy is becoming increasingly important. In this work, we present a generalized GAN framework for tabular synthesis, which combines the adversarial training of GANs and the negative log-density regularization of invertible neural networks. The proposed framework can be used for two distinctive objectives. First, we can further improve the synthesis quality, by decreasing the negative log-density of real records in the process of adversarial training. On the other hand, by increasing the negative log-density of real records, realistic fake records can be synthesized in a way that they are not too much close to real records and reduce the chance of potential information leakage. We conduct experiments with real-world datasets for classification, regression, and privacy attacks. In general, the proposed method demonstrates the best synthesis quality (in terms of task-oriented evaluation metrics, e.g., F1) when decreasing the negative log-density during the adversarial training. If increasing the negative log-density, our experimental results show that the distance between real and fake records increases, enhancing robustness against privacy attacks.
Graph Neural Controlled Differential Equations for Traffic Forecasting
Dec 07, 2021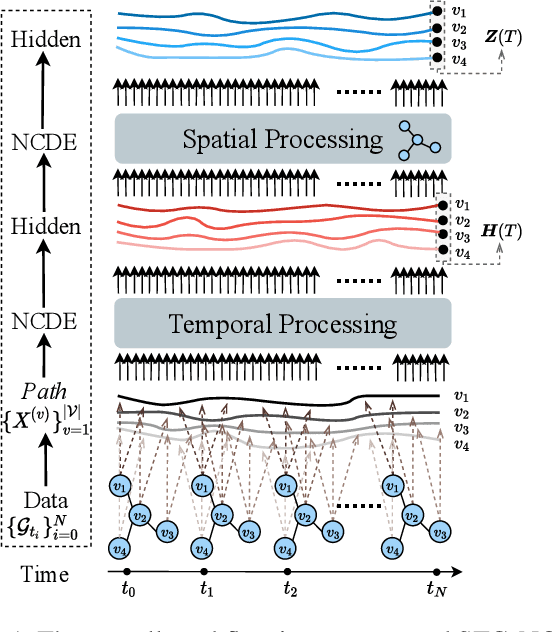
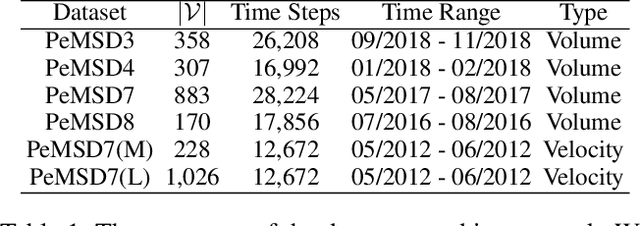
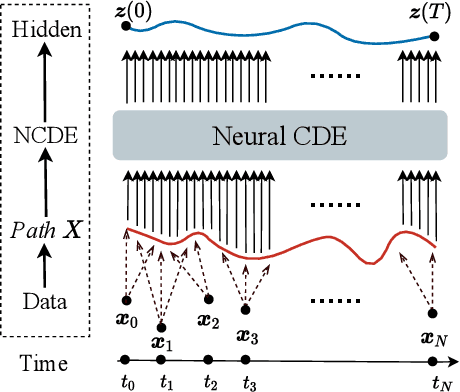
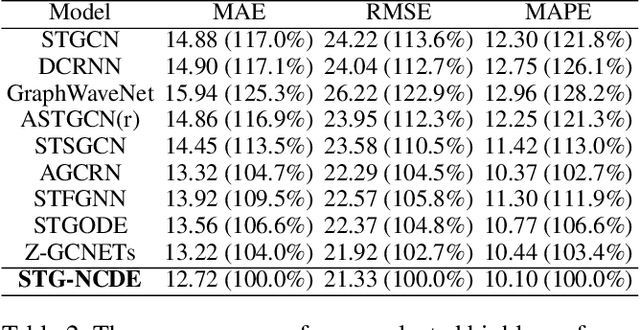
Traffic forecasting is one of the most popular spatio-temporal tasks in the field of machine learning. A prevalent approach in the field is to combine graph convolutional networks and recurrent neural networks for the spatio-temporal processing. There has been fierce competition and many novel methods have been proposed. In this paper, we present the method of spatio-temporal graph neural controlled differential equation (STG-NCDE). Neural controlled differential equations (NCDEs) are a breakthrough concept for processing sequential data. We extend the concept and design two NCDEs: one for the temporal processing and the other for the spatial processing. After that, we combine them into a single framework. We conduct experiments with 6 benchmark datasets and 20 baselines. STG-NCDE shows the best accuracy in all cases, outperforming all those 20 baselines by non-trivial margins.
Linear, or Non-Linear, That is the Question!
Nov 14, 2021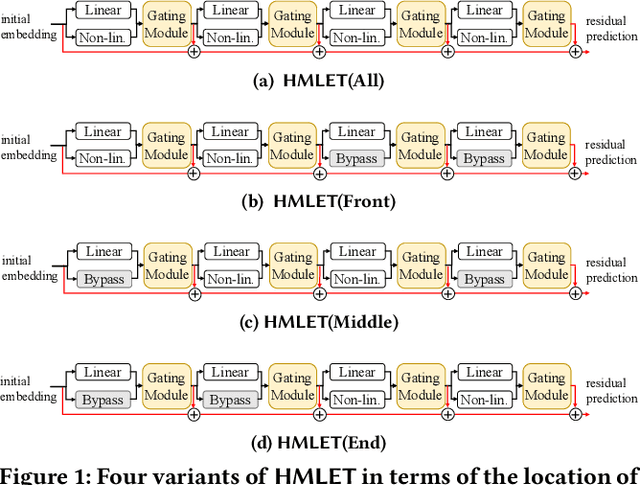

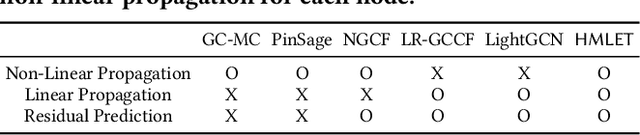
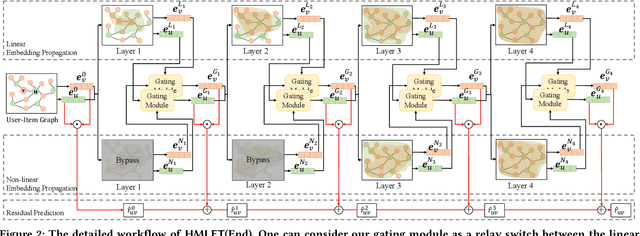
There were fierce debates on whether the non-linear embedding propagation of GCNs is appropriate to GCN-based recommender systems. It was recently found that the linear embedding propagation shows better accuracy than the non-linear embedding propagation. Since this phenomenon was discovered especially in recommender systems, it is required that we carefully analyze the linearity and non-linearity issue. In this work, therefore, we revisit the issues of i) which of the linear or non-linear propagation is better and ii) which factors of users/items decide the linearity/non-linearity of the embedding propagation. We propose a novel Hybrid Method of Linear and non-linEar collaborative filTering method (HMLET, pronounced as Hamlet). In our design, there exist both linear and non-linear propagation steps, when processing each user or item node, and our gating module chooses one of them, which results in a hybrid model of the linear and non-linear GCN-based collaborative filtering (CF). The proposed model yields the best accuracy in three public benchmark datasets. Moreover, we classify users/items into the following three classes depending on our gating modules' selections: Full-Non-Linearity (FNL), Partial-Non-Linearity (PNL), and Full-Linearity (FL). We found that there exist strong correlations between nodes' centrality and their class membership, i.e., important user/item nodes exhibit more preferences towards the non-linearity during the propagation steps. To our knowledge, we are the first who designs a hybrid method and reports the correlation between the graph centrality and the linearity/non-linearity of nodes. All HMLET codes and datasets are available at: https://github.com/qbxlvnf11/HMLET.