 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNicolas Heist
Knowledge Graphs on the Web -- an Overview
Mar 05, 2020
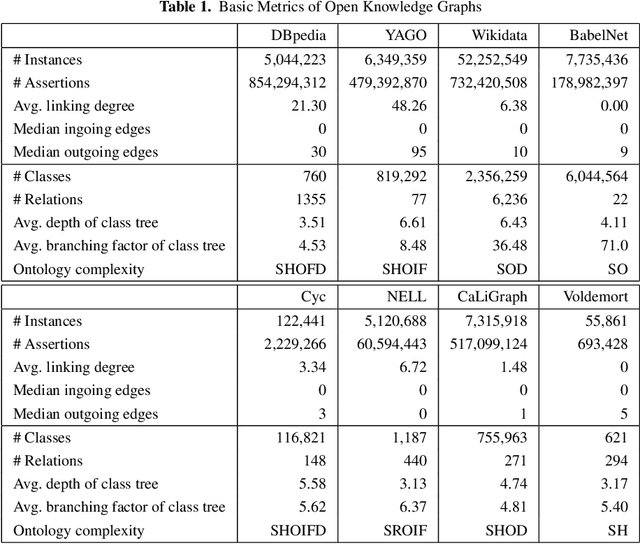
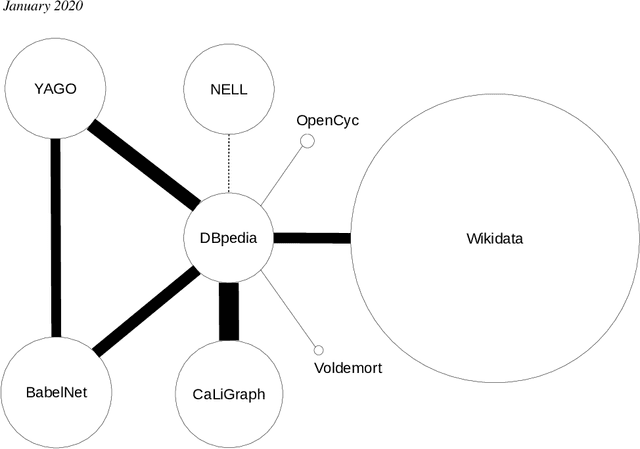
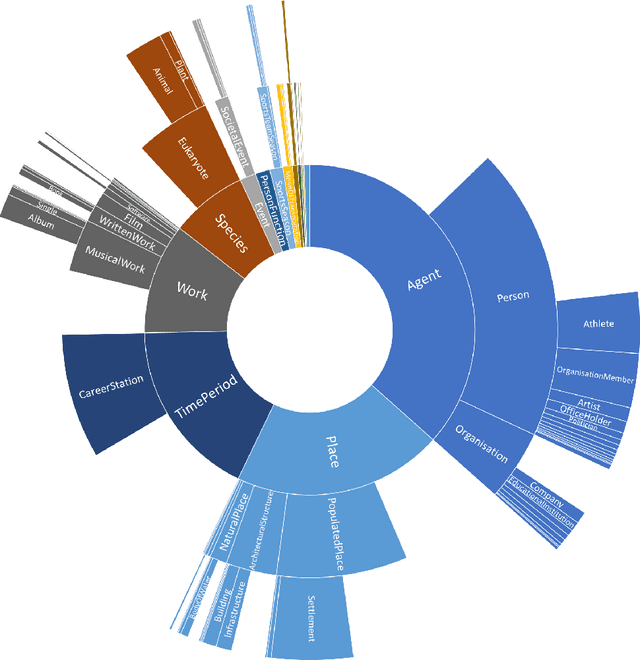
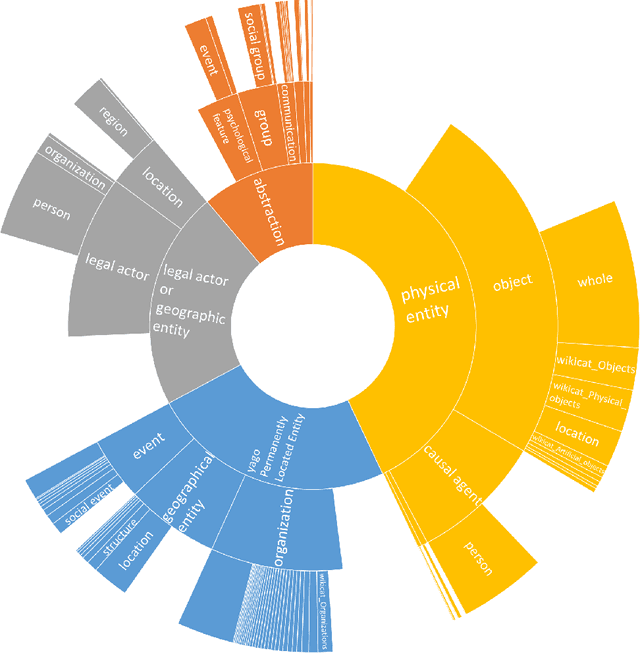
Knowledge Graphs are an emerging form of knowledge representation. While Google coined the term Knowledge Graph first and promoted it as a means to improve their search results, they are used in many applications today. In a knowledge graph, entities in the real world and/or a business domain (e.g., people, places, or events) are represented as nodes, which are connected by edges representing the relations between those entities. While companies such as Google, Microsoft, and Facebook have their own, non-public knowledge graphs, there is also a larger body of publicly available knowledge graphs, such as DBpedia or Wikidata. In this chapter, we provide an overview and comparison of those publicly available knowledge graphs, and give insights into their contents, size, coverage, and overlap.
Uncovering the Semantics of Wikipedia Categories
Jun 28, 2019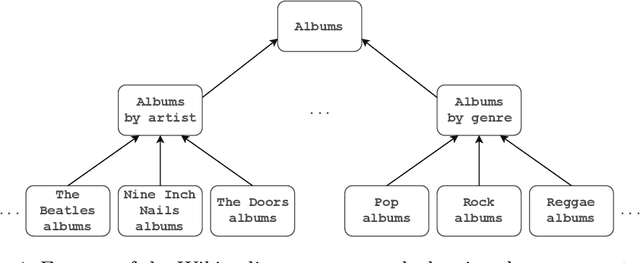
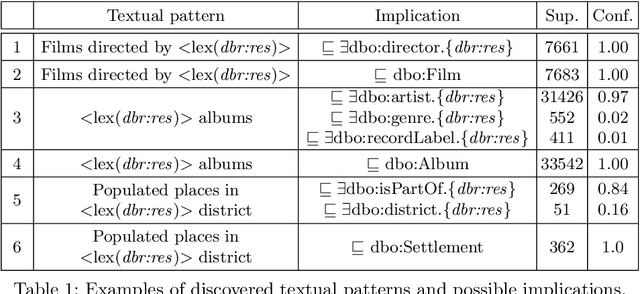
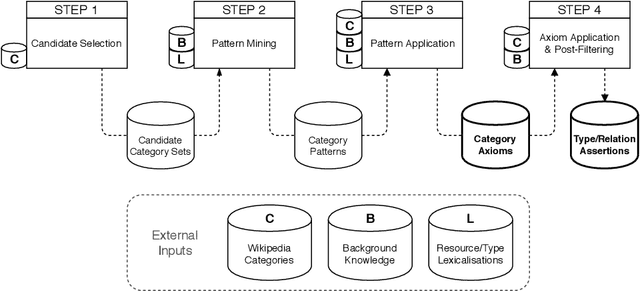
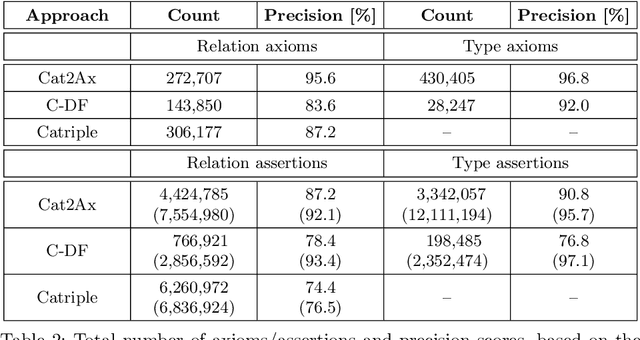
The Wikipedia category graph serves as the taxonomic backbone for large-scale knowledge graphs like YAGO or Probase, and has been used extensively for tasks like entity disambiguation or semantic similarity estimation. Wikipedia's categories are a rich source of taxonomic as well as non-taxonomic information. The category 'German science fiction writers', for example, encodes the type of its resources (Writer), as well as their nationality (German) and genre (Science Fiction). Several approaches in the literature make use of fractions of this encoded information without exploiting its full potential. In this paper, we introduce an approach for the discovery of category axioms that uses information from the category network, category instances, and their lexicalisations. With DBpedia as background knowledge, we discover 703k axioms covering 502k of Wikipedia's categories and populate the DBpedia knowledge graph with additional 4.4M relation assertions and 3.3M type assertions at more than 87% and 90% precision, respectively.