 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavdeep Jaitly
Learning Hard Alignments with Variational Inference
Nov 01, 2017
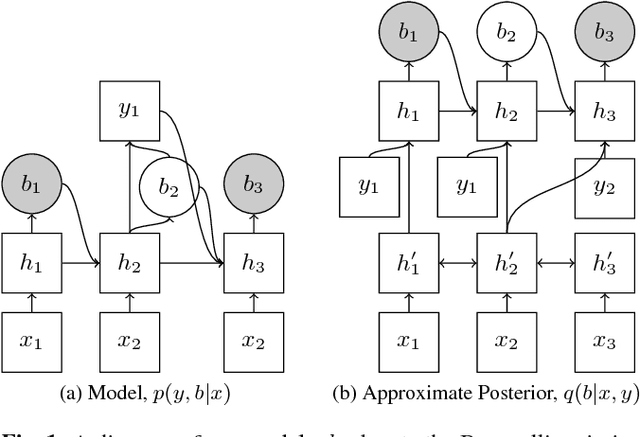
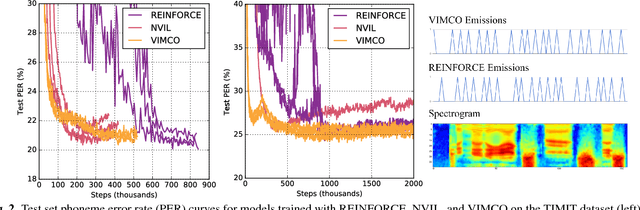
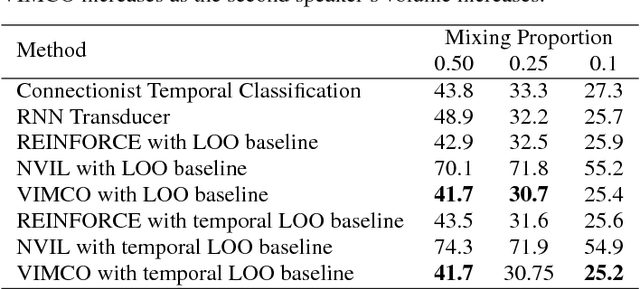
There has recently been significant interest in hard attention models for tasks such as object recognition, visual captioning and speech recognition. Hard attention can offer benefits over soft attention such as decreased computational cost, but training hard attention models can be difficult because of the discrete latent variables they introduce. Previous work used REINFORCE and Q-learning to approach these issues, but those methods can provide high-variance gradient estimates and be slow to train. In this paper, we tackle the problem of learning hard attention for a sequential task using variational inference methods, specifically the recently introduced VIMCO and NVIL. Furthermore, we propose a novel baseline that adapts VIMCO to this setting. We demonstrate our method on a phoneme recognition task in clean and noisy environments and show that our method outperforms REINFORCE, with the difference being greater for a more complicated task.
An online sequence-to-sequence model for noisy speech recognition
Jun 16, 2017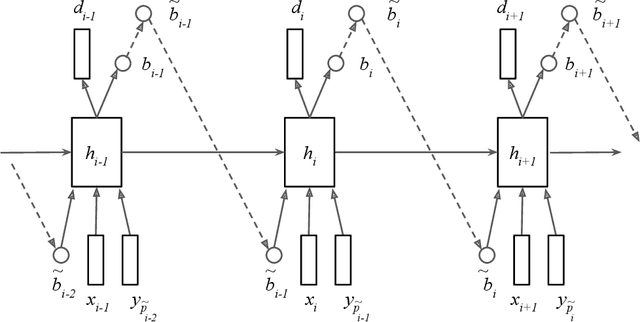
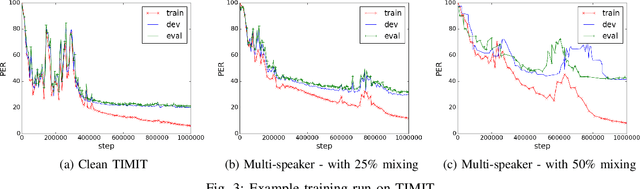
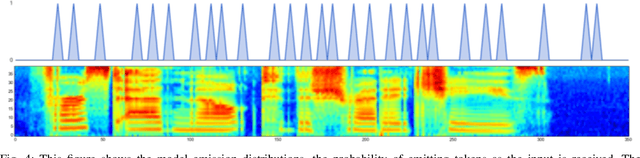
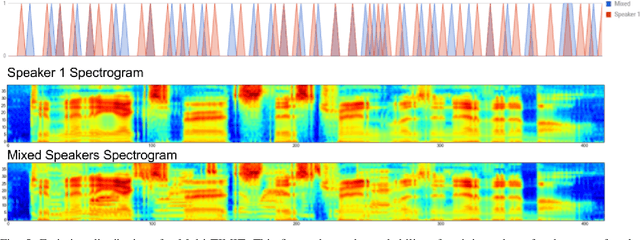
Generative models have long been the dominant approach for speech recognition. The success of these models however relies on the use of sophisticated recipes and complicated machinery that is not easily accessible to non-practitioners. Recent innovations in Deep Learning have given rise to an alternative - discriminative models called Sequence-to-Sequence models, that can almost match the accuracy of state of the art generative models. While these models are easy to train as they can be trained end-to-end in a single step, they have a practical limitation that they can only be used for offline recognition. This is because the models require that the entirety of the input sequence be available at the beginning of inference, an assumption that is not valid for instantaneous speech recognition. To address this problem, online sequence-to-sequence models were recently introduced. These models are able to start producing outputs as data arrives, and the model feels confident enough to output partial transcripts. These models, like sequence-to-sequence are causal - the output produced by the model until any time, $t$, affects the features that are computed subsequently. This makes the model inherently more powerful than generative models that are unable to change features that are computed from the data. This paper highlights two main contributions - an improvement to online sequence-to-sequence model training, and its application to noisy settings with mixed speech from two speakers.
Sequence-to-Sequence Models Can Directly Translate Foreign Speech
Jun 12, 2017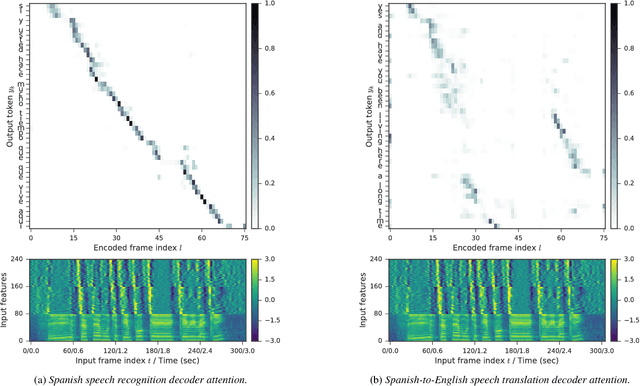
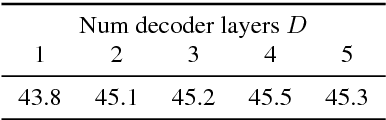

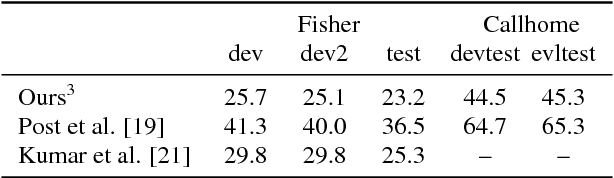
We present a recurrent encoder-decoder deep neural network architecture that directly translates speech in one language into text in another. The model does not explicitly transcribe the speech into text in the source language, nor does it require supervision from the ground truth source language transcription during training. We apply a slightly modified sequence-to-sequence with attention architecture that has previously been used for speech recognition and show that it can be repurposed for this more complex task, illustrating the power of attention-based models. A single model trained end-to-end obtains state-of-the-art performance on the Fisher Callhome Spanish-English speech translation task, outperforming a cascade of independently trained sequence-to-sequence speech recognition and machine translation models by 1.8 BLEU points on the Fisher test set. In addition, we find that making use of the training data in both languages by multi-task training sequence-to-sequence speech translation and recognition models with a shared encoder network can improve performance by a further 1.4 BLEU points.
Tacotron: Towards End-to-End Speech Synthesis
Apr 06, 2017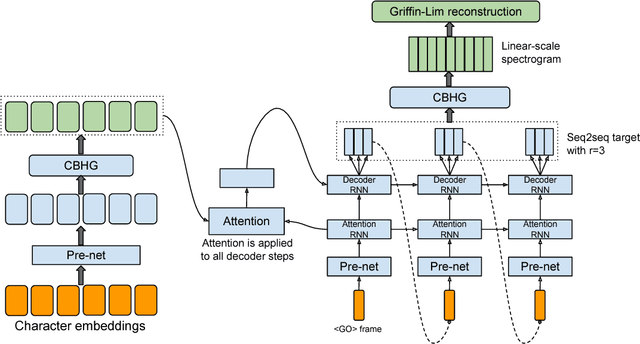
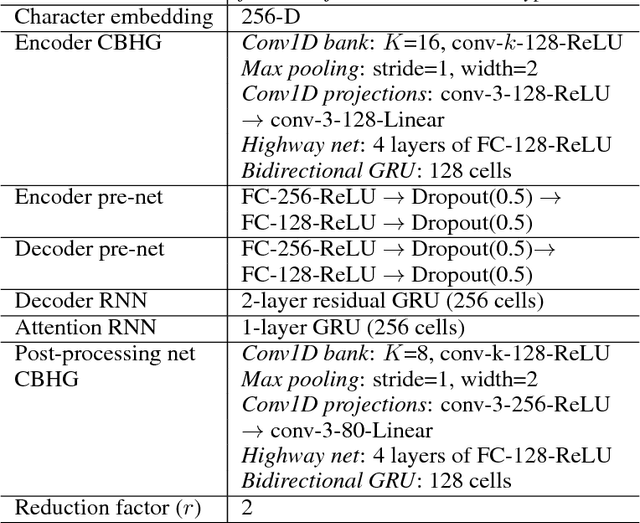
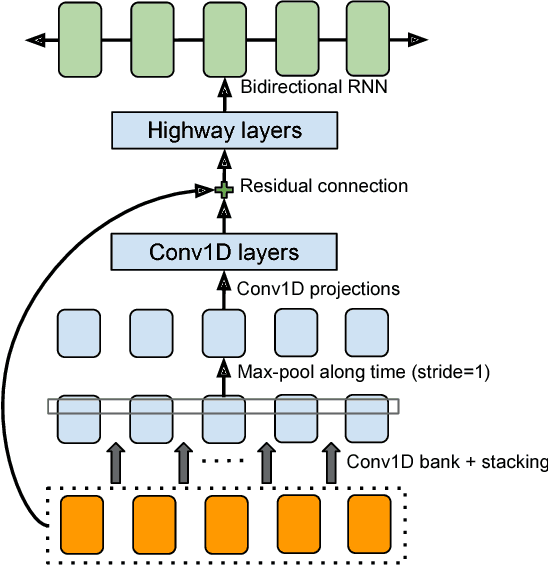
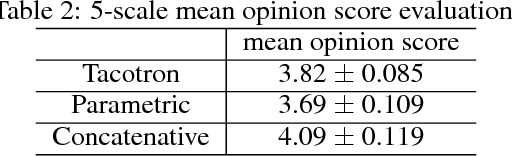
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design choices. In this paper, we present Tacotron, an end-to-end generative text-to-speech model that synthesizes speech directly from characters. Given <text, audio> pairs, the model can be trained completely from scratch with random initialization. We present several key techniques to make the sequence-to-sequence framework perform well for this challenging task. Tacotron achieves a 3.82 subjective 5-scale mean opinion score on US English, outperforming a production parametric system in terms of naturalness. In addition, since Tacotron generates speech at the frame level, it's substantially faster than sample-level autoregressive methods.
Next-Step Conditioned Deep Convolutional Neural Networks Improve Protein Secondary Structure Prediction
Feb 13, 2017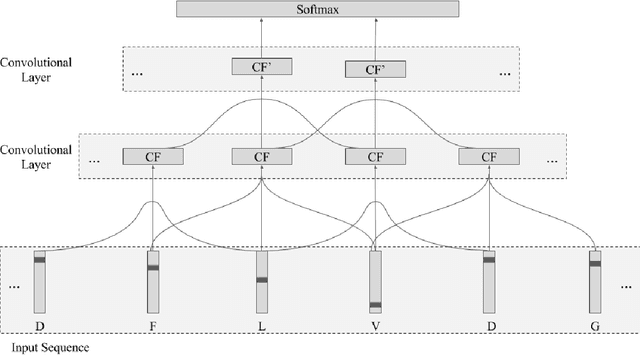
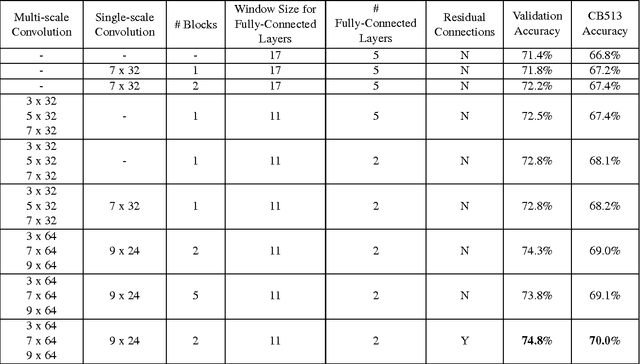
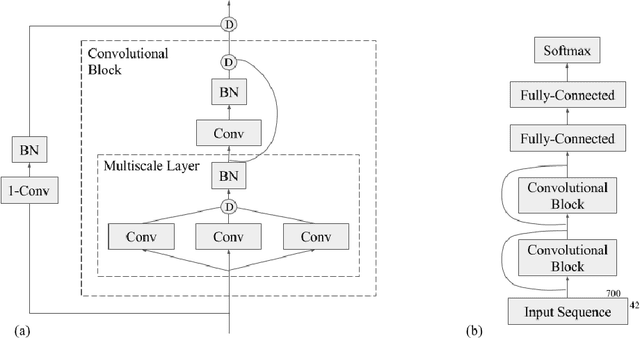
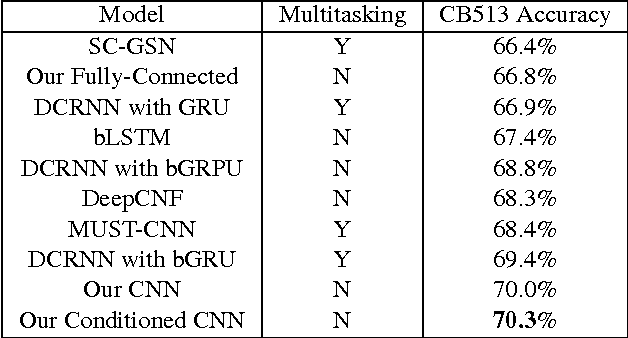
Recently developed deep learning techniques have significantly improved the accuracy of various speech and image recognition systems. In this paper we show how to adapt some of these techniques to create a novel chained convolutional architecture with next-step conditioning for improving performance on protein sequence prediction problems. We explore its value by demonstrating its ability to improve performance on eight-class secondary structure prediction. We first establish a state-of-the-art baseline by adapting recent advances in convolutional neural networks which were developed for vision tasks. This model achieves 70.0% per amino acid accuracy on the CB513 benchmark dataset without use of standard performance-boosting techniques such as ensembling or multitask learning. We then improve upon this state-of-the-art result using a novel chained prediction approach which frames the secondary structure prediction as a next-step prediction problem. This sequential model achieves 70.3% Q8 accuracy on CB513 with a single model; an ensemble of these models produces 71.4% Q8 accuracy on the same test set, improving upon the previous overall state of the art for the eight-class secondary structure problem. Our models are implemented using TensorFlow, an open-source machine learning software library available at TensorFlow.org; we aim to release the code for these experiments as part of the TensorFlow repository.
Latent Sequence Decompositions
Feb 07, 2017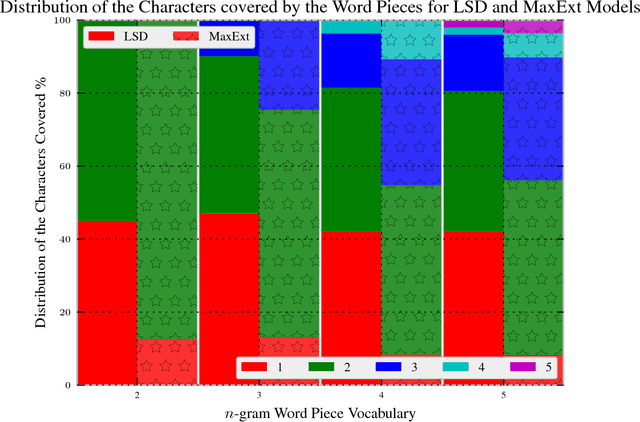
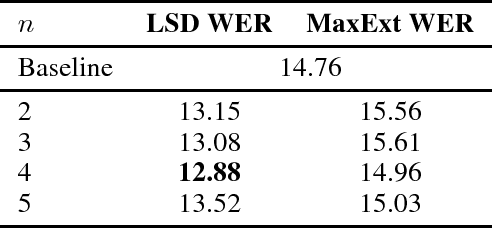
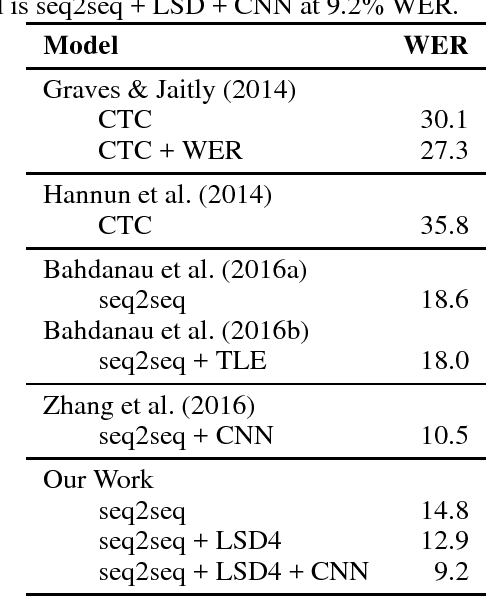
We present the Latent Sequence Decompositions (LSD) framework. LSD decomposes sequences with variable lengthed output units as a function of both the input sequence and the output sequence. We present a training algorithm which samples valid extensions and an approximate decoding algorithm. We experiment with the Wall Street Journal speech recognition task. Our LSD model achieves 12.9% WER compared to a character baseline of 14.8% WER. When combined with a convolutional network on the encoder, we achieve 9.6% WER.
RNN Approaches to Text Normalization: A Challenge
Jan 24, 2017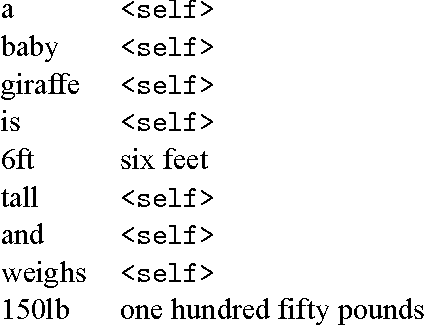

This paper presents a challenge to the community: given a large corpus of written text aligned to its normalized spoken form, train an RNN to learn the correct normalization function. We present a data set of general text where the normalizations were generated using an existing text normalization component of a text-to-speech system. This data set will be released open-source in the near future. We also present our own experiments with this data set with a variety of different RNN architectures. While some of the architectures do in fact produce very good results when measured in terms of overall accuracy, the errors that are produced are problematic, since they would convey completely the wrong message if such a system were deployed in a speech application. On the other hand, we show that a simple FST-based filter can mitigate those errors, and achieve a level of accuracy not achievable by the RNN alone. Though our conclusions are largely negative on this point, we are actually not arguing that the text normalization problem is intractable using an pure RNN approach, merely that it is not going to be something that can be solved merely by having huge amounts of annotated text data and feeding that to a general RNN model. And when we open-source our data, we will be providing a novel data set for sequence-to-sequence modeling in the hopes that the the community can find better solutions. The data used in this work have been released and are available at: https://github.com/rwsproat/text-normalization-data
Reward Augmented Maximum Likelihood for Neural Structured Prediction
Jan 04, 2017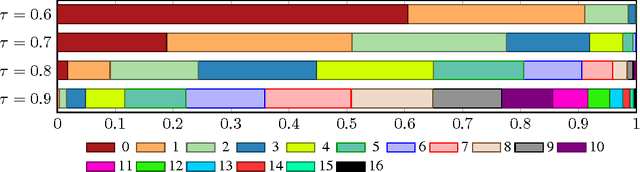
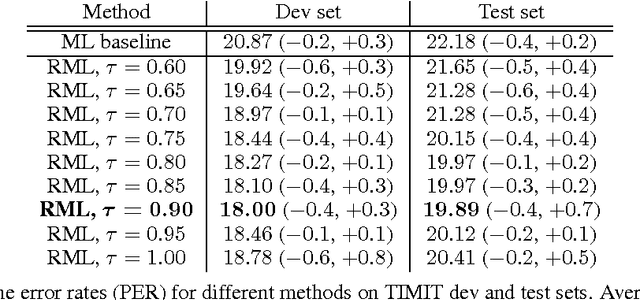
A key problem in structured output prediction is direct optimization of the task reward function that matters for test evaluation. This paper presents a simple and computationally efficient approach to incorporate task reward into a maximum likelihood framework. By establishing a link between the log-likelihood and expected reward objectives, we show that an optimal regularized expected reward is achieved when the conditional distribution of the outputs given the inputs is proportional to their exponentiated scaled rewards. Accordingly, we present a framework to smooth the predictive probability of the outputs using their corresponding rewards. We optimize the conditional log-probability of augmented outputs that are sampled proportionally to their exponentiated scaled rewards. Experiments on neural sequence to sequence models for speech recognition and machine translation show notable improvements over a maximum likelihood baseline by using reward augmented maximum likelihood (RAML), where the rewards are defined as the negative edit distance between the outputs and the ground truth labels.
Pointer Networks
Jan 02, 2017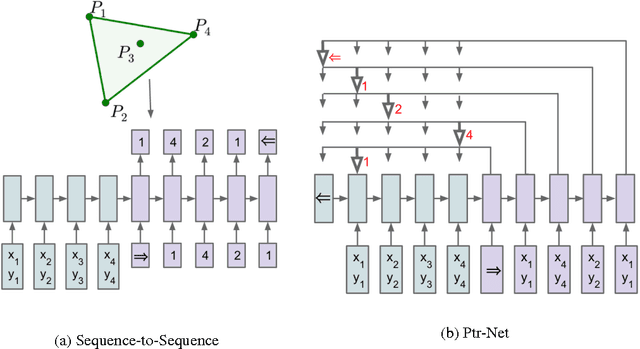

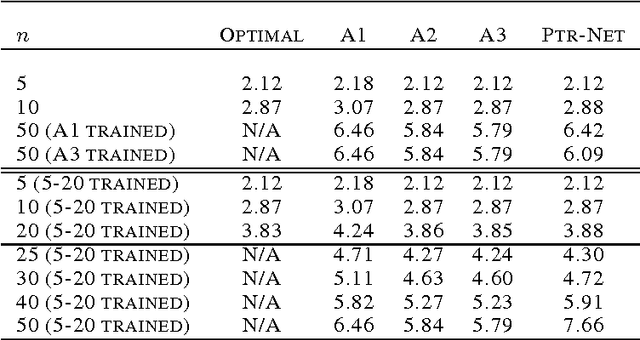
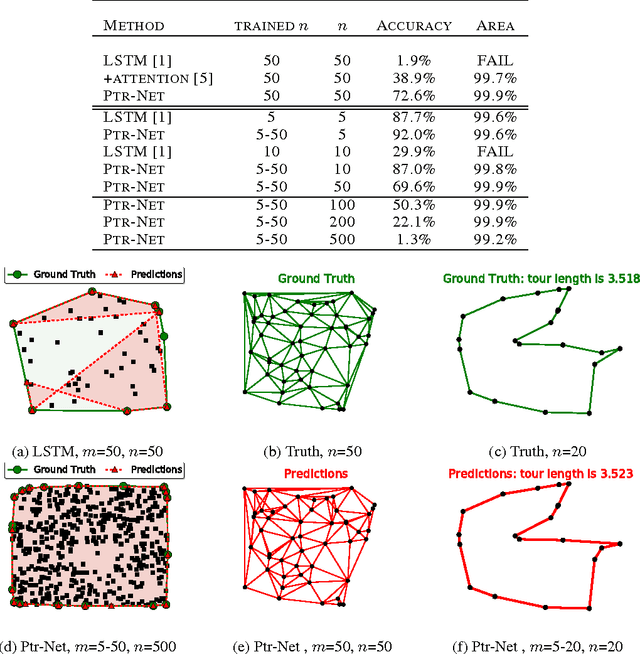
We introduce a new neural architecture to learn the conditional probability of an output sequence with elements that are discrete tokens corresponding to positions in an input sequence. Such problems cannot be trivially addressed by existent approaches such as sequence-to-sequence and Neural Turing Machines, because the number of target classes in each step of the output depends on the length of the input, which is variable. Problems such as sorting variable sized sequences, and various combinatorial optimization problems belong to this class. Our model solves the problem of variable size output dictionaries using a recently proposed mechanism of neural attention. It differs from the previous attention attempts in that, instead of using attention to blend hidden units of an encoder to a context vector at each decoder step, it uses attention as a pointer to select a member of the input sequence as the output. We call this architecture a Pointer Net (Ptr-Net). We show Ptr-Nets can be used to learn approximate solutions to three challenging geometric problems -- finding planar convex hulls, computing Delaunay triangulations, and the planar Travelling Salesman Problem -- using training examples alone. Ptr-Nets not only improve over sequence-to-sequence with input attention, but also allow us to generalize to variable size output dictionaries. We show that the learnt models generalize beyond the maximum lengths they were trained on. We hope our results on these tasks will encourage a broader exploration of neural learning for discrete problems.
Towards better decoding and language model integration in sequence to sequence models
Dec 08, 2016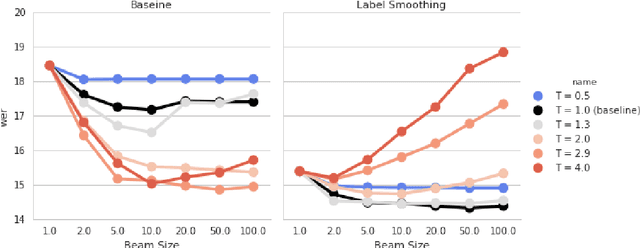

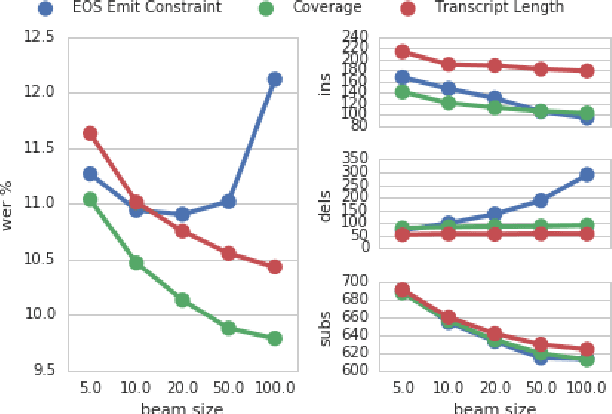
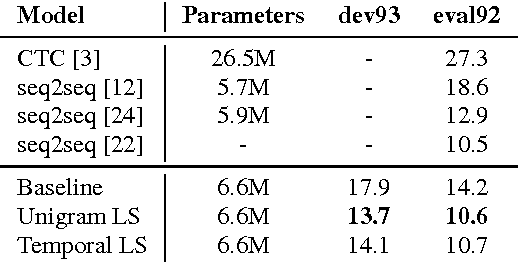
The recently proposed Sequence-to-Sequence (seq2seq) framework advocates replacing complex data processing pipelines, such as an entire automatic speech recognition system, with a single neural network trained in an end-to-end fashion. In this contribution, we analyse an attention-based seq2seq speech recognition system that directly transcribes recordings into characters. We observe two shortcomings: overconfidence in its predictions and a tendency to produce incomplete transcriptions when language models are used. We propose practical solutions to both problems achieving competitive speaker independent word error rates on the Wall Street Journal dataset: without separate language models we reach 10.6% WER, while together with a trigram language model, we reach 6.7% WER.