 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Facial Geometry Learning for Sketch to Photo Synthesis
Oct 12, 2018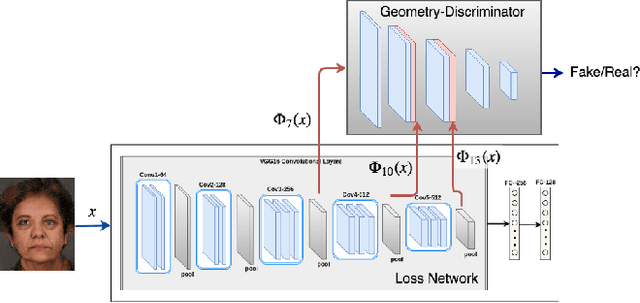
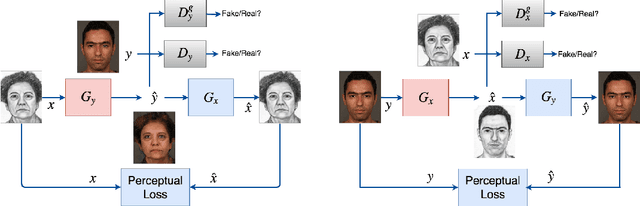

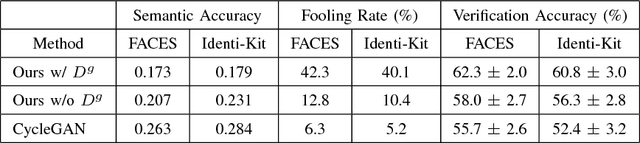
Face sketch-photo synthesis is a critical application in law enforcement and digital entertainment industry where the goal is to learn the mapping between a face sketch image and its corresponding photo-realistic image. However, the limited number of paired sketch-photo training data usually prevents the current frameworks to learn a robust mapping between the geometry of sketches and their matching photo-realistic images. Consequently, in this work, we present an approach for learning to synthesize a photo-realistic image from a face sketch in an unsupervised fashion. In contrast to current unsupervised image-to-image translation techniques, our framework leverages a novel perceptual discriminator to learn the geometry of human face. Learning facial prior information empowers the network to remove the geometrical artifacts in the face sketch. We demonstrate that a simultaneous optimization of the face photo generator network, employing the proposed perceptual discriminator in combination with a texture-wise discriminator, results in a significant improvement in quality and recognition rate of the synthesized photos. We evaluate the proposed network by conducting extensive experiments on multiple baseline sketch-photo datasets.
Fast Geometrically-Perturbed Adversarial Faces
Sep 28, 2018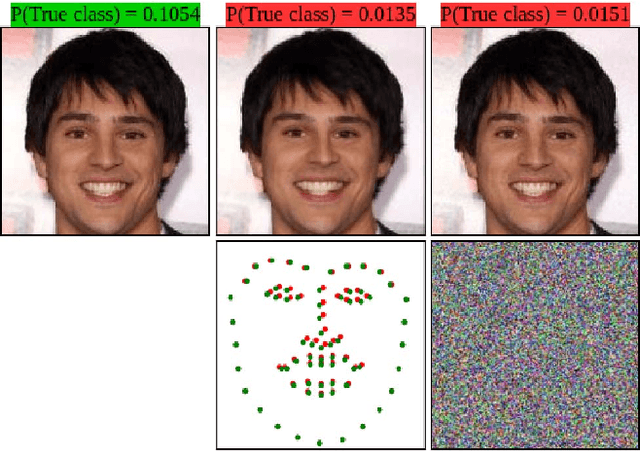
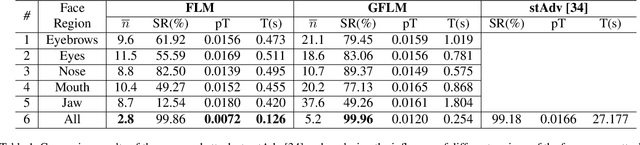
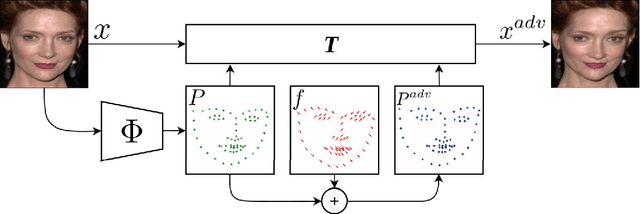
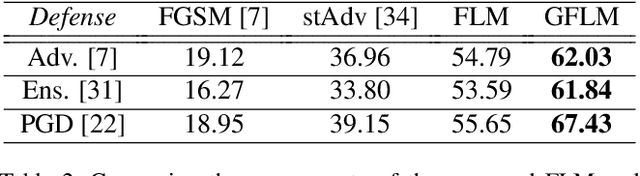
The state-of-the-art performance of deep learning algorithms has led to a considerable increase in the utilization of machine learning in security-sensitive and critical applications. However, it has recently been shown that a small and carefully crafted perturbation in the input space can completely fool a deep model. In this study, we explore the extent to which face recognition systems are vulnerable to geometrically-perturbed adversarial faces. We propose a fast landmark manipulation method for generating adversarial faces, which is approximately 200 times faster than the previous geometric attacks and obtains 99.86% success rate on the state-of-the-art face recognition models. To further force the generated samples to be natural, we introduce a second attack constrained on the semantic structure of the face which has the half speed of the first attack with the success rate of 99.96%. Both attacks are extremely robust against the state-of-the-art defense methods with the success rate of equal or greater than 53.59%. Code is available at https://github.com/alldbi/FLM
Convolutional Neural Networks for Aerial Vehicle Detection and Recognition
Aug 26, 2018
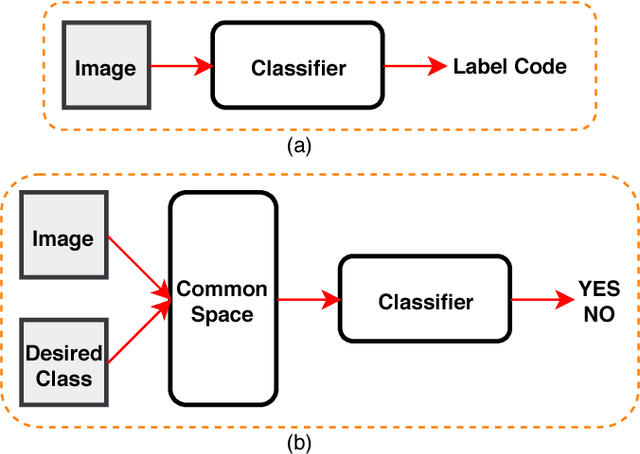
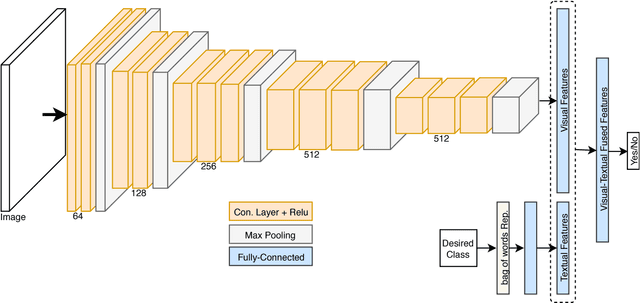

This paper investigates the problem of aerial vehicle recognition using a text-guided deep convolutional neural network classifier. The network receives an aerial image and a desired class, and makes a yes or no output by matching the image and the textual description of the desired class. We train and test our model on a synthetic aerial dataset and our desired classes consist of the combination of the class types and colors of the vehicles. This strategy helps when considering more classes in testing than in training.
Deep Sketch-Photo Face Recognition Assisted by Facial Attributes
Jul 31, 2018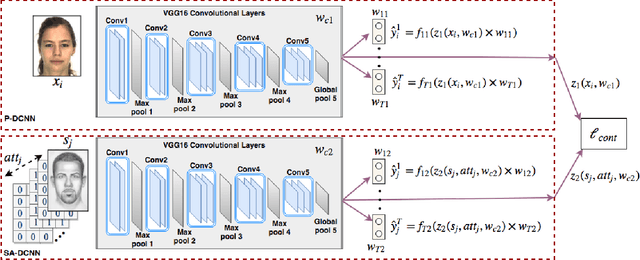

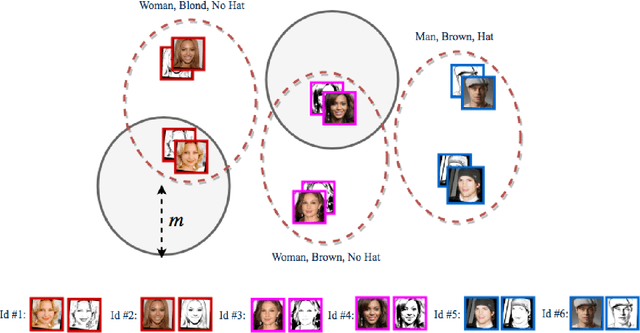
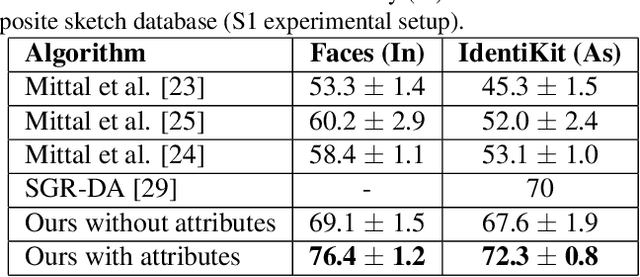
In this paper, we present a deep coupled framework to address the problem of matching sketch image against a gallery of mugshots. Face sketches have the essential in- formation about the spatial topology and geometric details of faces while missing some important facial attributes such as ethnicity, hair, eye, and skin color. We propose a cou- pled deep neural network architecture which utilizes facial attributes in order to improve the sketch-photo recognition performance. The proposed Attribute-Assisted Deep Con- volutional Neural Network (AADCNN) method exploits the facial attributes and leverages the loss functions from the facial attributes identification and face verification tasks in order to learn rich discriminative features in a common em- bedding subspace. The facial attribute identification task increases the inter-personal variations by pushing apart the embedded features extracted from individuals with differ- ent facial attributes, while the verification task reduces the intra-personal variations by pulling together all the fea- tures that are related to one person. The learned discrim- inative features can be well generalized to new identities not seen in the training data. The proposed architecture is able to make full use of the sketch and complementary fa- cial attribute information to train a deep model compared to the conventional sketch-photo recognition methods. Exten- sive experiments are performed on composite (E-PRIP) and semi-forensic (IIIT-D semi-forensic) datasets. The results show the superiority of our method compared to the state- of-the-art models in sketch-photo recognition algorithms
Prosodic-Enhanced Siamese Convolutional Neural Networks for Cross-Device Text-Independent Speaker Verification
Jul 31, 2018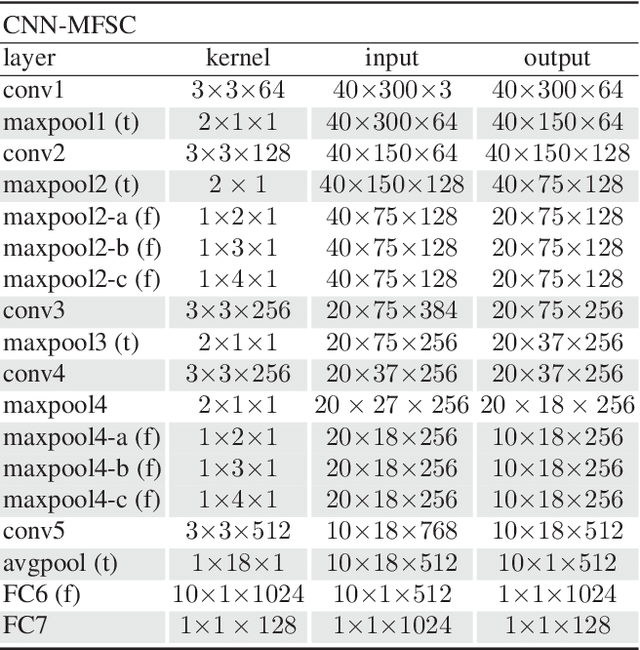
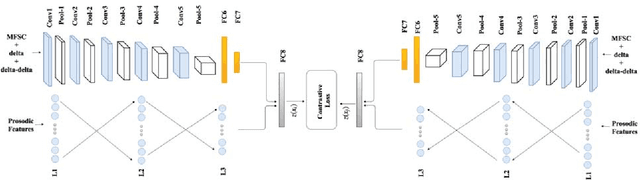
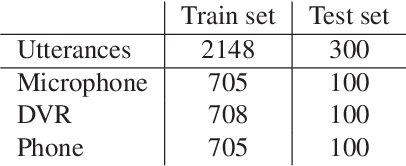
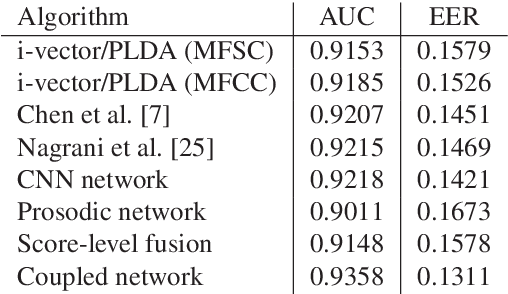
In this paper a novel cross-device text-independent speaker verification architecture is proposed. Majority of the state-of-the-art deep architectures that are used for speaker verification tasks consider Mel-frequency cepstral coefficients. In contrast, our proposed Siamese convolutional neural network architecture uses Mel-frequency spectrogram coefficients to benefit from the dependency of the adjacent spectro-temporal features. Moreover, although spectro-temporal features have proved to be highly reliable in speaker verification models, they only represent some aspects of short-term acoustic level traits of the speaker's voice. However, the human voice consists of several linguistic levels such as acoustic, lexicon, prosody, and phonetics, that can be utilized in speaker verification models. To compensate for these inherited shortcomings in spectro-temporal features, we propose to enhance the proposed Siamese convolutional neural network architecture by deploying a multilayer perceptron network to incorporate the prosodic, jitter, and shimmer features. The proposed end-to-end verification architecture performs feature extraction and verification simultaneously. This proposed architecture displays significant improvement over classical signal processing approaches and deep algorithms for forensic cross-device speaker verification.
ID Preserving Generative Adversarial Network for Partial Latent Fingerprint Reconstruction
Jul 31, 2018
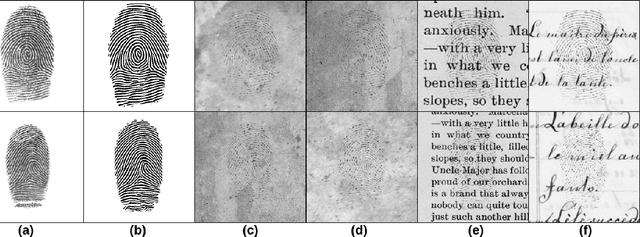

Performing recognition tasks using latent fingerprint samples is often challenging for automated identification systems due to poor quality, distortion, and partially missing information from the input samples. We propose a direct latent fingerprint reconstruction model based on conditional generative adversarial networks (cGANs). Two modifications are applied to the cGAN to adapt it for the task of latent fingerprint reconstruction. First, the model is forced to generate three additional maps to the ridge map to ensure that the orientation and frequency information is considered in the generation process, and prevent the model from filling large missing areas and generating erroneous minutiae. Second, a perceptual ID preservation approach is developed to force the generator to preserve the ID information during the reconstruction process. Using a synthetically generated database of latent fingerprints, the deep network learns to predict missing information from the input latent samples. We evaluate the proposed method in combination with two different fingerprint matching algorithms on several publicly available latent fingerprint datasets. We achieved the rank-10 accuracy of 88.02\% on the IIIT-Delhi latent fingerprint database for the task of latent-to-latent matching and rank-50 accuracy of 70.89\% on the IIIT-Delhi MOLF database for the task of latent-to-sensor matching. Experimental results of matching reconstructed samples in both latent-to-sensor and latent-to-latent frameworks indicate that the proposed method significantly increases the matching accuracy of the fingerprint recognition systems for the latent samples.
Convolutional Neural Networks for Aerial Multi-Label Pedestrian Detection
Jul 16, 2018

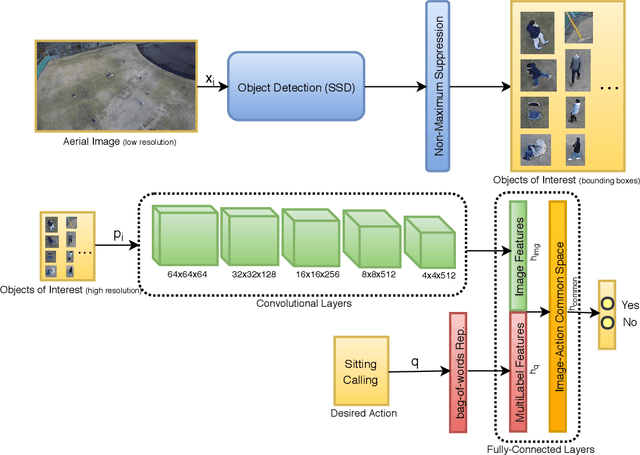

The low resolution of objects of interest in aerial images makes pedestrian detection and action detection extremely challenging tasks. Furthermore, using deep convolutional neural networks to process large images can be demanding in terms of computational requirements. In order to alleviate these challenges, we propose a two-step, yes and no question answering framework to find specific individuals doing one or multiple specific actions in aerial images. First, a deep object detector, Single Shot Multibox Detector (SSD), is used to generate object proposals from small aerial images. Second, another deep network, is used to learn a latent common sub-space which associates the high resolution aerial imagery and the pedestrian action labels that are provided by the human-based sources
Attention-Based Guided Structured Sparsity of Deep Neural Networks
Jul 14, 2018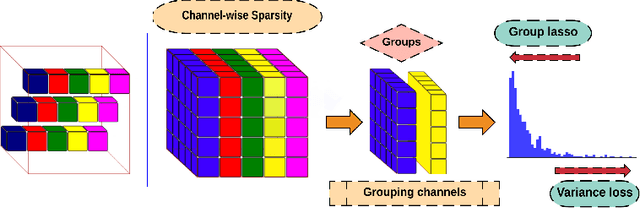
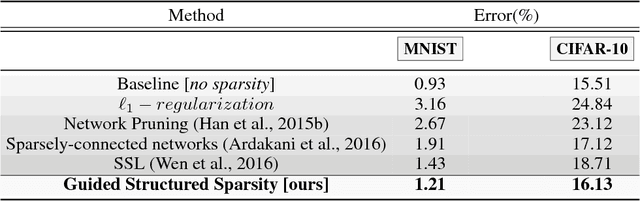
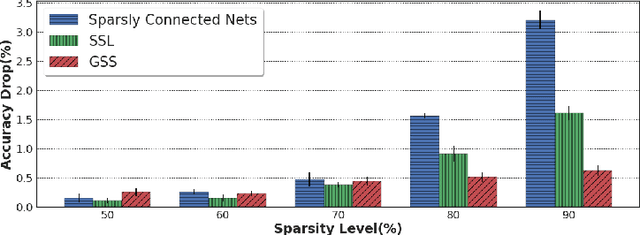
Network pruning is aimed at imposing sparsity in a neural network architecture by increasing the portion of zero-valued weights for reducing its size regarding energy-efficiency consideration and increasing evaluation speed. In most of the conducted research efforts, the sparsity is enforced for network pruning without any attention to the internal network characteristics such as unbalanced outputs of the neurons or more specifically the distribution of the weights and outputs of the neurons. That may cause severe accuracy drop due to uncontrolled sparsity. In this work, we propose an attention mechanism that simultaneously controls the sparsity intensity and supervised network pruning by keeping important information bottlenecks of the network to be active. On CIFAR-10, the proposed method outperforms the best baseline method by 6% and reduced the accuracy drop by 2.6x at the same level of sparsity.
Multi-Level Feature Abstraction from Convolutional Neural Networks for Multimodal Biometric Identification
Jul 03, 2018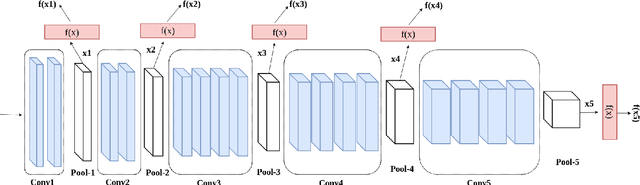
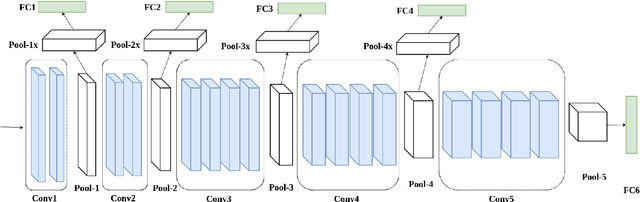
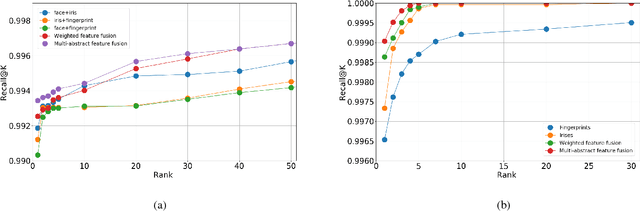
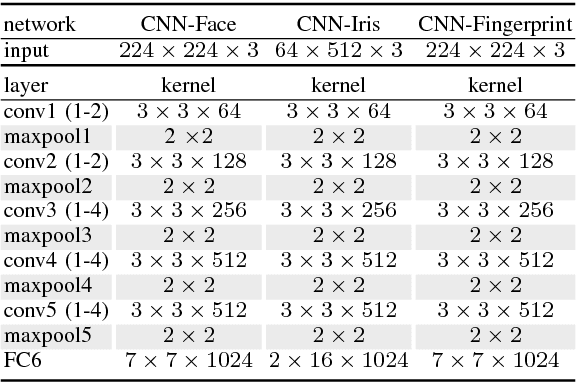
In this paper, we propose a deep multimodal fusion network to fuse multiple modalities (face, iris, and fingerprint) for person identification. The proposed deep multimodal fusion algorithm consists of multiple streams of modality-specific Convolutional Neural Networks (CNNs), which are jointly optimized at multiple feature abstraction levels. Multiple features are extracted at several different convolutional layers from each modality-specific CNN for joint feature fusion, optimization, and classification. Features extracted at different convolutional layers of a modality-specific CNN represent the input at several different levels of abstract representations. We demonstrate that an efficient multimodal classification can be accomplished with a significant reduction in the number of network parameters by exploiting these multi-level abstract representations extracted from all the modality-specific CNNs. We demonstrate an increase in multimodal person identification performance by utilizing the proposed multi-level feature abstract representations in our multimodal fusion, rather than using only the features from the last layer of each modality-specific CNNs. We show that our deep multi-modal CNNs with multimodal fusion at several different feature level abstraction can significantly outperform the unimodal representation accuracy. We also demonstrate that the joint optimization of all the modality-specific CNNs excels the score and decision level fusions of independently optimized CNNs.
Generalized Bilinear Deep Convolutional Neural Networks for Multimodal Biometric Identification
Jul 03, 2018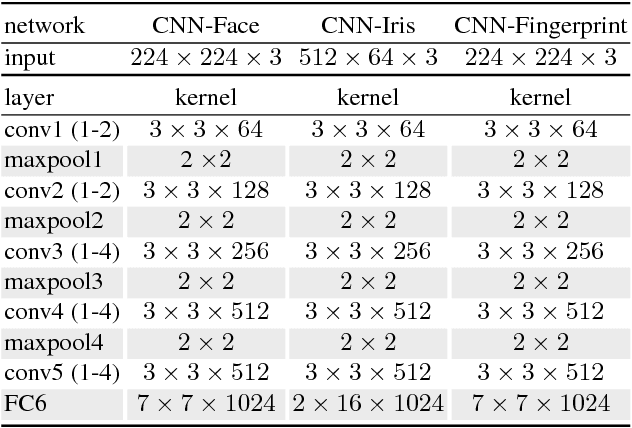
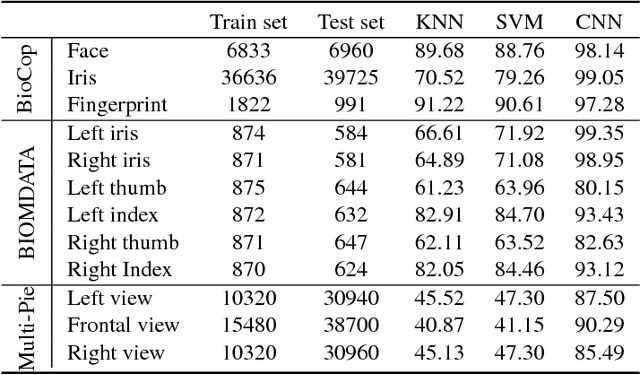
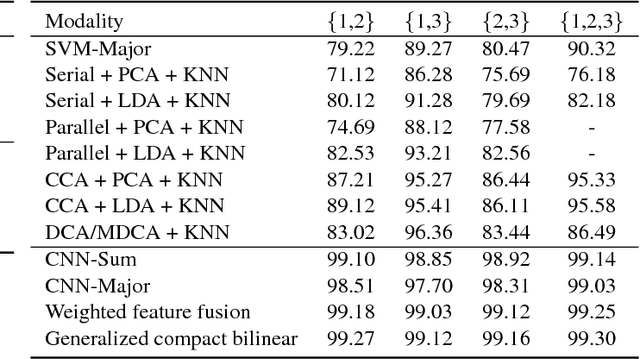
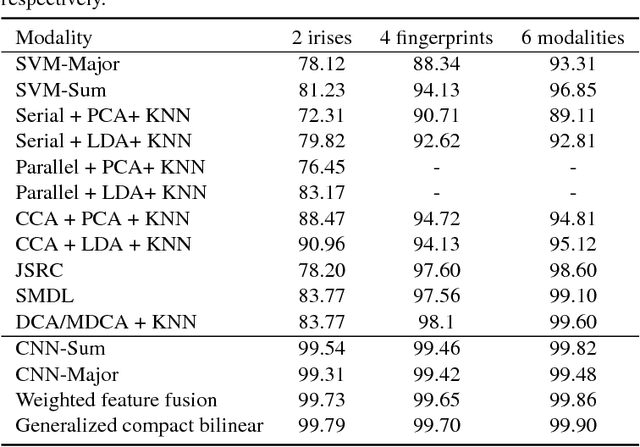
In this paper, we propose to employ a bank of modality-dedicated Convolutional Neural Networks (CNNs), fuse, train, and optimize them together for person classification tasks. A modality-dedicated CNN is used for each modality to extract modality-specific features. We demonstrate that, rather than spatial fusion at the convolutional layers, the fusion can be performed on the outputs of the fully-connected layers of the modality-specific CNNs without any loss of performance and with significant reduction in the number of parameters. We show that, using multiple CNNs with multimodal fusion at the feature-level, we significantly outperform systems that use unimodal representation. We study weighted feature, bilinear, and compact bilinear feature-level fusion algorithms for multimodal biometric person identification. Finally, We propose generalized compact bilinear fusion algorithm to deploy both the weighted feature fusion and compact bilinear schemes. We provide the results for the proposed algorithms on three challenging databases: CMU Multi-PIE, BioCop, and BIOMDATA.