 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Aware Deep Face Hallucination via Adversarial Face Verification
Sep 17, 2019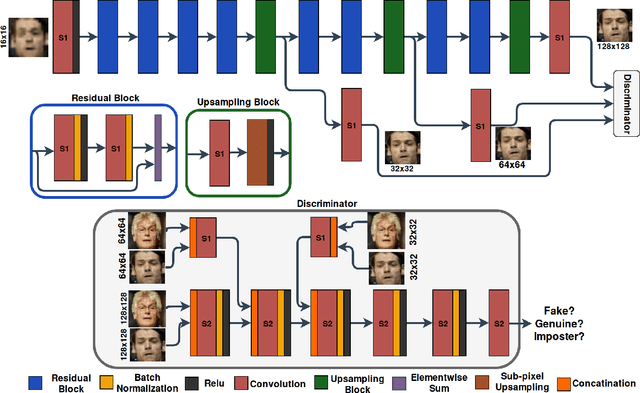
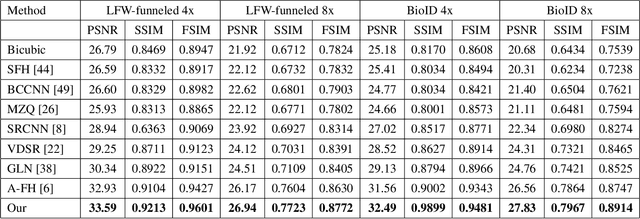

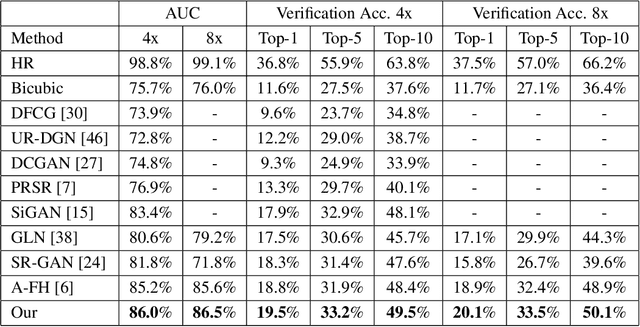
In this paper, we address the problem of face hallucination by proposing a novel multi-scale generative adversarial network (GAN) architecture optimized for face verification. First, we propose a multi-scale generator architecture for face hallucination with a high up-scaling ratio factor, which has multiple intermediate outputs at different resolutions. The intermediate outputs have the growing goal of synthesizing small to large images. Second, we incorporate a face verifier with the original GAN discriminator and propose a novel discriminator which learns to discriminate different identities while distinguishing fake generated HR face images from their ground truth images. In particular, the learned generator cares for not only the visual quality of hallucinated face images but also preserving the discriminative features in the hallucination process. In addition, to capture perceptually relevant differences we employ a perceptual similarity loss, instead of similarity in pixel space. We perform a quantitative and qualitative evaluation of our framework on the LFW and CelebA datasets. The experimental results show the advantages of our proposed method against the state-of-the-art methods on the 8x downsampled testing dataset.
Deep Sparse Band Selection for Hyperspectral Face Recognition
Aug 15, 2019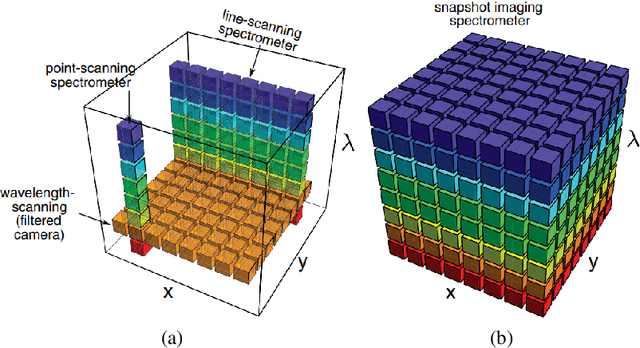


Hyperspectral imaging systems collect and process information from specific wavelengths across the electromagnetic spectrum. The fusion of multi-spectral bands in the visible spectrum has been exploited to improve face recognition performance over all the conventional broad band face images. In this book chapter, we propose a new Convolutional Neural Network (CNN) framework which adopts a structural sparsity learning technique to select the optimal spectral bands to obtain the best face recognition performance over all of the spectral bands. Specifically, in this method, images from all bands are fed to a CNN, and the convolutional filters in the first layer of the CNN are then regularized by employing a group Lasso algorithm to zero out the redundant bands during the training of the network. Contrary to other methods which usually select the useful bands manually or in a greedy fashion, our method selects the optimal spectral bands automatically to achieve the best face recognition performance over all spectral bands. Moreover, experimental results demonstrate that our method outperforms state of the art band selection methods for face recognition on several publicly-available hyperspectral face image datasets.
Defending Against Adversarial Iris Examples Using Wavelet Decomposition
Aug 08, 2019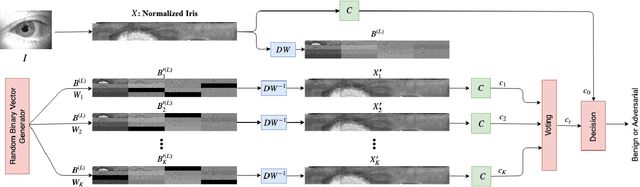
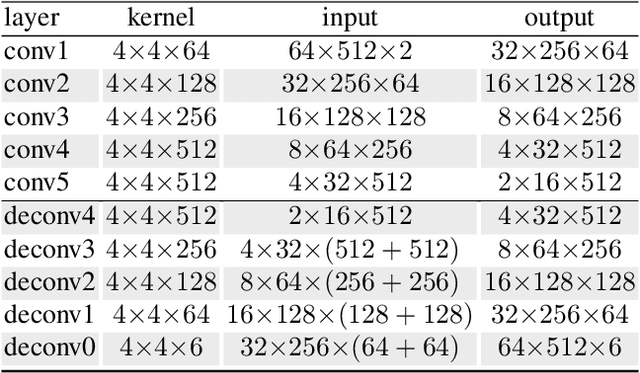
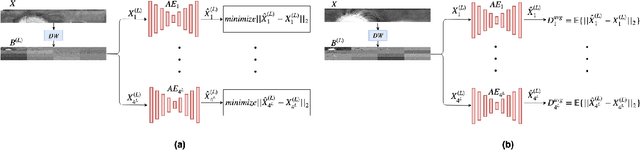

Deep neural networks have presented impressive performance in biometric applications. However, their performance is highly at risk when facing carefully crafted input samples known as adversarial examples. In this paper, we present three defense strategies to detect adversarial iris examples. These defense strategies are based on wavelet domain denoising of the input examples by investigating each wavelet sub-band and removing the sub-bands that are most affected by the adversary. The first proposed defense strategy reconstructs multiple denoised versions of the input example through manipulating the mid- and high-frequency components of the wavelet domain representation of the input example and makes a decision upon the classification result of the majority of the denoised examples. The second and third proposed defense strategies aim to denoise each wavelet domain sub-band and determine the sub-bands that are most likely affected by the adversary using the reconstruction error computed for each sub-band. We test the performance of the proposed defense strategies against several attack scenarios and compare the results with five state of the art defense strategies.
Zero-Shot Deep Hashing and Neural Network Based Error Correction for Face Template Protection
Aug 05, 2019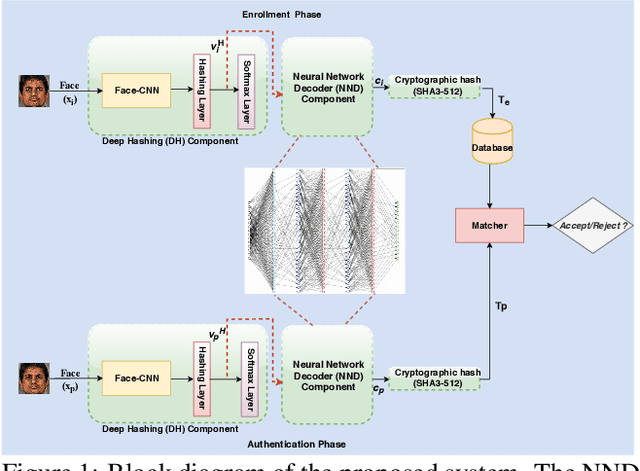
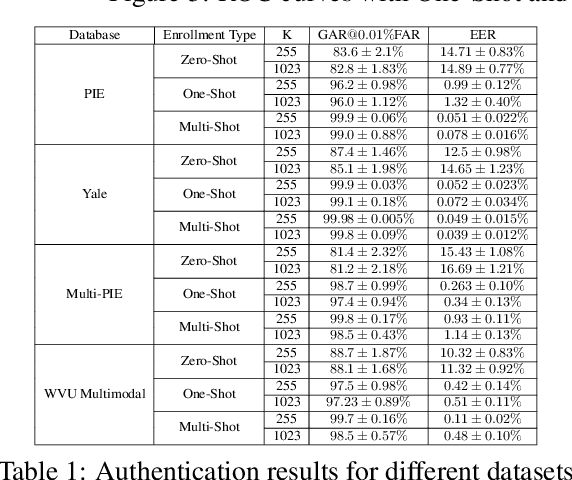
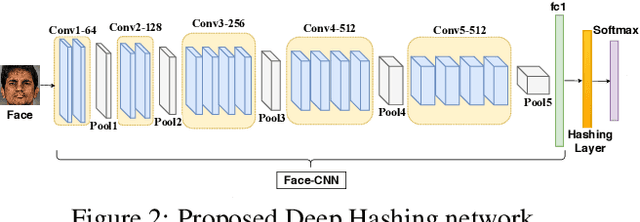
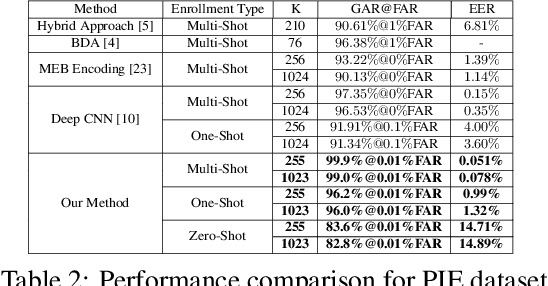
In this paper, we present a novel architecture that integrates a deep hashing framework with a neural network decoder (NND) for application to face template protection. It improves upon existing face template protection techniques to provide better matching performance with one-shot and multi-shot enrollment. A key novelty of our proposed architecture is that the framework can also be used with zero-shot enrollment. This implies that our architecture does not need to be re-trained even if a new subject is to be enrolled into the system. The proposed architecture consists of two major components: a deep hashing (DH) component, which is used for robust mapping of face images to their corresponding intermediate binary codes, and a NND component, which corrects errors in the intermediate binary codes that are caused by differences in the enrollment and probe biometrics due to factors such as variation in pose, illumination, and other factors. The final binary code generated by the NND is then cryptographically hashed and stored as a secure face template in the database. The efficacy of our approach with zero-shot, one-shot, and multi-shot enrollments is shown for CMU-PIE, Extended Yale B, WVU multimodal and Multi-PIE face databases. With zero-shot enrollment, the system achieves approximately 85% genuine accept rates (GAR) at 0.01% false accept rate (FAR), and with one-shot and multi-shot enrollments, it achieves approximately 99.95% GAR at 0.01% FAR, while providing a high level of template security.
Attribute-Guided Deep Polarimetric Thermal-to-visible Face Recognition
Jul 27, 2019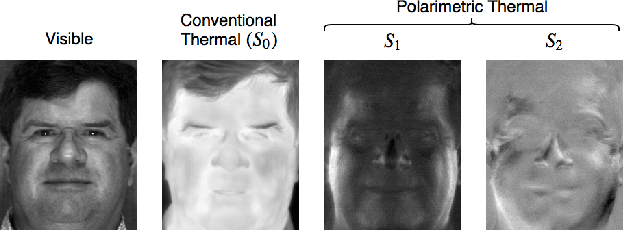
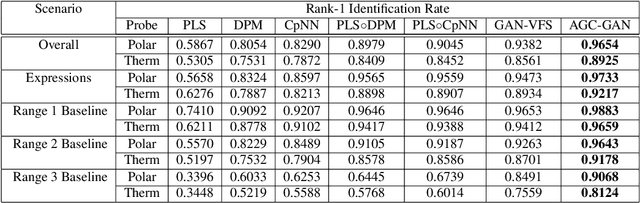
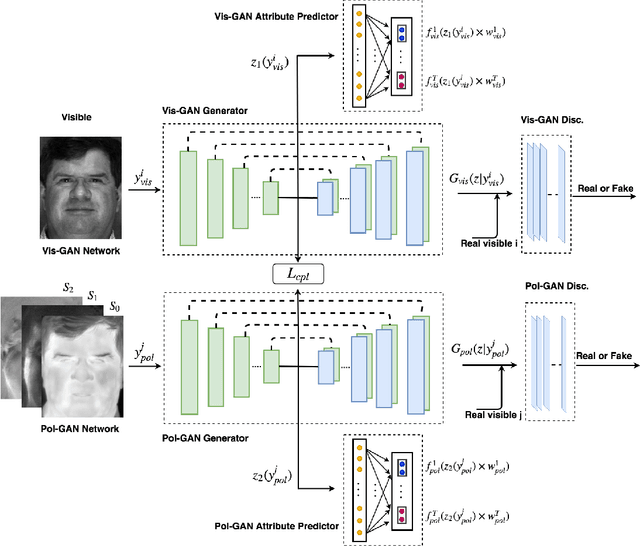

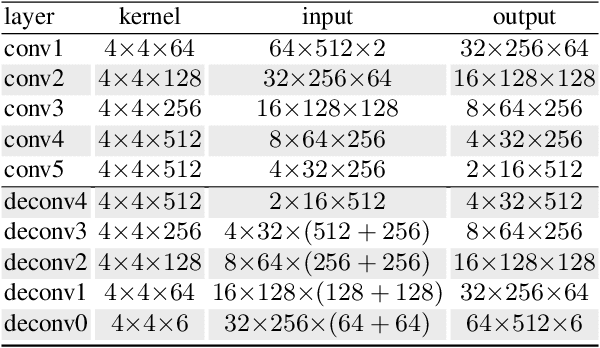
In this paper, we present an attribute-guided deep coupled learning framework to address the problem of matching polarimetric thermal face photos against a gallery of visible faces. The coupled framework contains two sub-networks, one dedicated to the visible spectrum and the second sub-network dedicated to the polarimetric thermal spectrum. Each sub-network is made of a generative adversarial network (GAN) architecture. We propose a novel Attribute-Guided Coupled Generative Adversarial Network (AGC-GAN) architecture which utilizes facial attributes to improve the thermal-to-visible face recognition performance. The proposed AGC-GAN exploits the facial attributes and leverages multiple loss functions in order to learn rich discriminative features in a common embedding subspace. To achieve a realistic photo reconstruction while preserving the discriminative information, we also add a perceptual loss term to the coupling loss function. An ablation study is performed to show the effectiveness of different loss functions for optimizing the proposed method. Moreover, the superiority of the model compared to the state-of-the-art models is demonstrated using polarimetric dataset.
Adversarial Examples to Fool Iris Recognition Systems
Jul 18, 2019
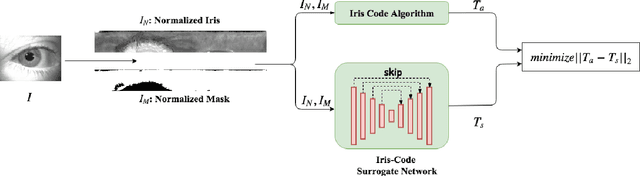
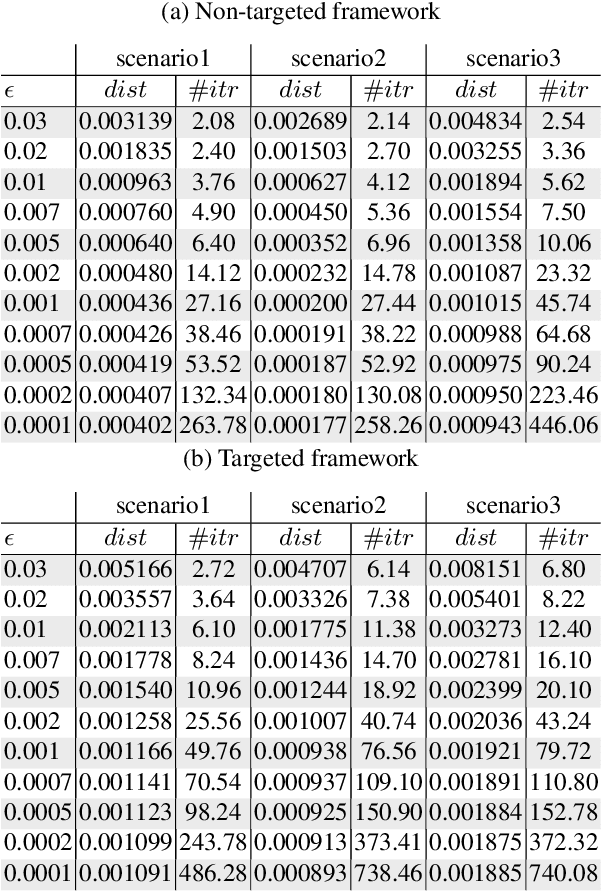
Adversarial examples have recently proven to be able to fool deep learning methods by adding carefully crafted small perturbation to the input space image. In this paper, we study the possibility of generating adversarial examples for code-based iris recognition systems. Since generating adversarial examples requires back-propagation of the adversarial loss, conventional filter bank-based iris-code generation frameworks cannot be employed in such a setup. Therefore, to compensate for this shortcoming, we propose to train a deep auto-encoder surrogate network to mimic the conventional iris code generation procedure. This trained surrogate network is then deployed to generate the adversarial examples using the iterative gradient sign method algorithm. We consider non-targeted and targeted attacks through three attack scenarios. Considering these attacks, we study the possibility of fooling an iris recognition system in white-box and black-box frameworks.
Learning to Authenticate with Deep Multibiometric Hashing and Neural Network Decoding
Mar 07, 2019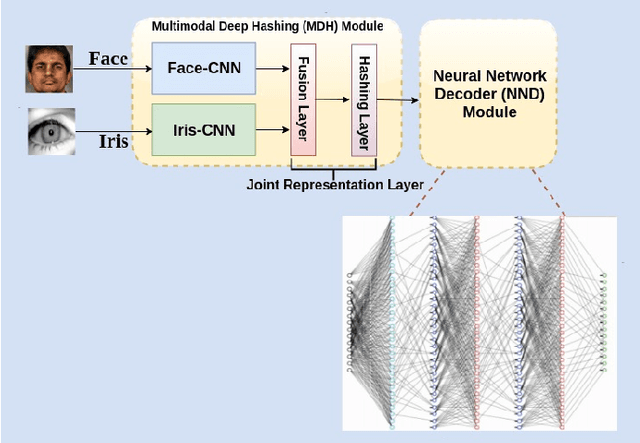
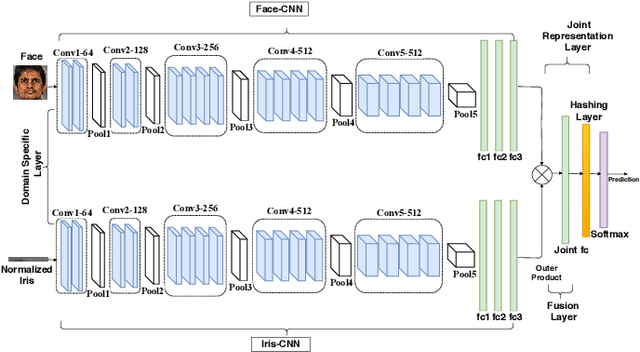
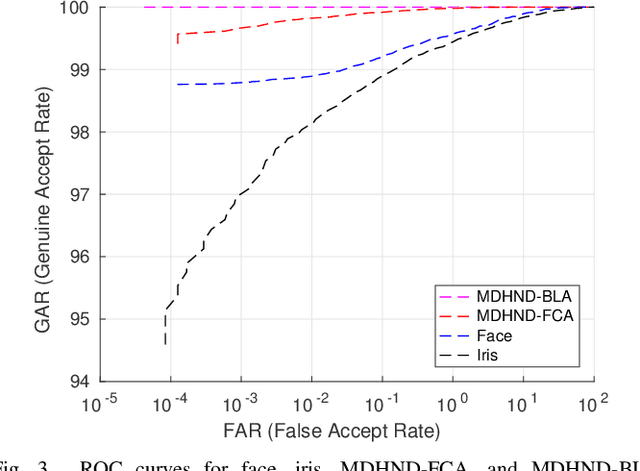
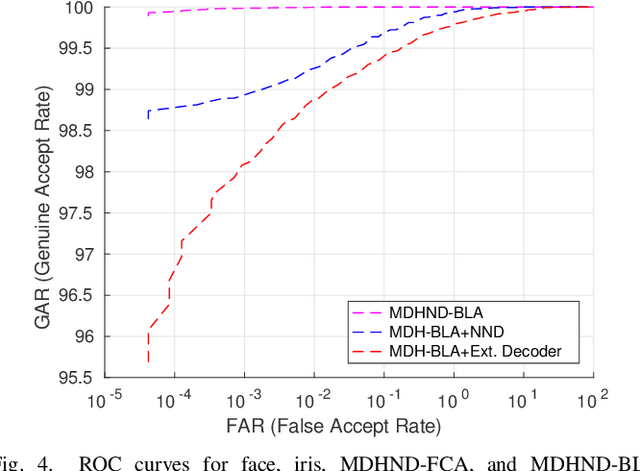
In this paper, we propose a novel multimodal deep hashing neural decoder (MDHND) architecture, which integrates a deep hashing framework with a neural network decoder (NND) to create an effective multibiometric authentication system. The MDHND consists of two separate modules: a multimodal deep hashing (MDH) module, which is used for feature-level fusion and binarization of multiple biometrics, and a neural network decoder (NND) module, which is used to refine the intermediate binary codes generated by the MDH and compensate for the difference between enrollment and probe biometrics (variations in pose, illumination, etc.). Use of NND helps to improve the performance of the overall multimodal authentication system. The MDHND framework is trained in 3 steps using joint optimization of the two modules. In Step 1, the MDH parameters are trained and learned to generate a shared multimodal latent code; in Step 2, the latent codes from Step 1 are passed through a conventional error-correcting code (ECC) decoder to generate the ground truth to train a neural network decoder (NND); in Step 3, the NND decoder is trained using the ground truth from Step 2 and the MDH and NND are jointly optimized. Experimental results on a standard multimodal dataset demonstrate the superiority of our method relative to other current multimodal authentication systems
Using Deep Cross Modal Hashing and Error Correcting Codes for Improving the Efficiency of Attribute Guided Facial Image Retrieval
Feb 11, 2019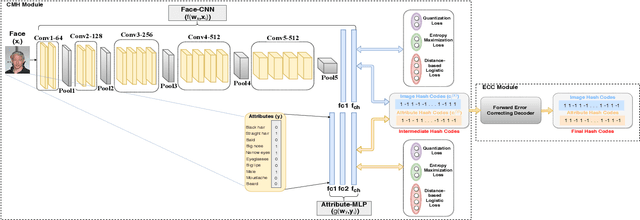

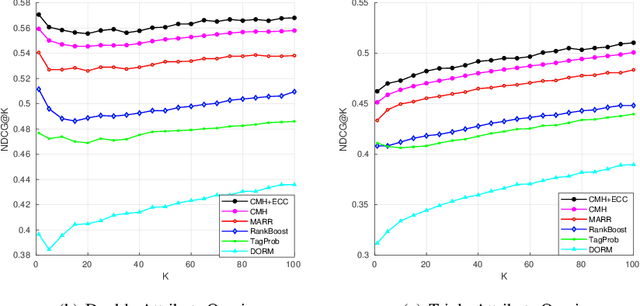
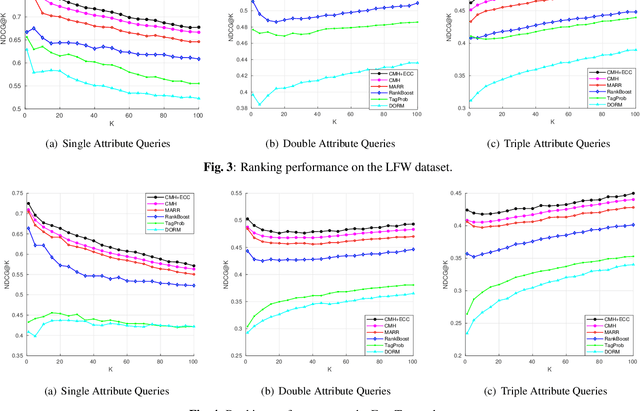
With benefits of fast query speed and low storage cost, hashing-based image retrieval approaches have garnered considerable attention from the research community. In this paper, we propose a novel Error-Corrected Deep Cross Modal Hashing (CMH-ECC) method which uses a bitmap specifying the presence of certain facial attributes as an input query to retrieve relevant face images from the database. In this architecture, we generate compact hash codes using an end-to-end deep learning module, which effectively captures the inherent relationships between the face and attribute modality. We also integrate our deep learning module with forward error correction codes to further reduce the distance between different modalities of the same subject. Specifically, the properties of deep hashing and forward error correction codes are exploited to design a cross modal hashing framework with high retrieval performance. Experimental results using two standard datasets with facial attributes-image modalities indicate that our CMH-ECC face image retrieval model outperforms most of the current attribute-based face image retrieval approaches.
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
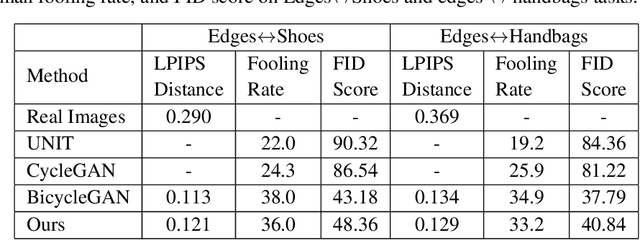
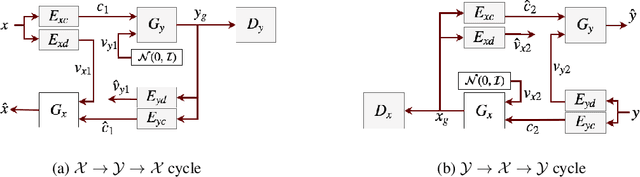
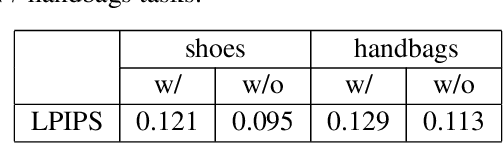
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Style and Content Disentanglement in Generative Adversarial Networks
Nov 14, 2018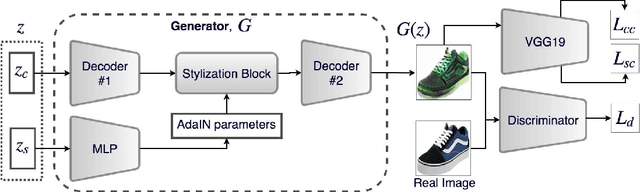
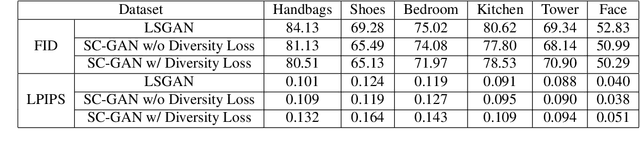
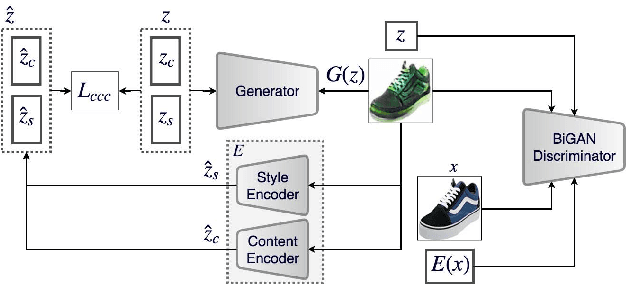
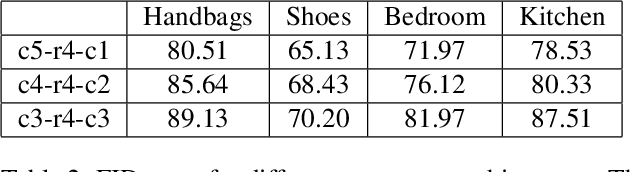
Disentangling factors of variation within data has become a very challenging problem for image generation tasks. Current frameworks for training a Generative Adversarial Network (GAN), learn to disentangle the representations of the data in an unsupervised fashion and capture the most significant factors of the data variations. However, these approaches ignore the principle of content and style disentanglement in image generation, which means their learned latent code may alter the content and style of the generated images at the same time. This paper describes the Style and Content Disentangled GAN (SC-GAN), a new unsupervised algorithm for training GANs that learns disentangled style and content representations of the data. We assume that the representation of an image can be decomposed into a content code that represents the geometrical information of the data, and a style code that captures textural properties. Consequently, by fixing the style portion of the latent representation, we can generate diverse images in a particular style. Reversely, we can set the content code and generate a specific scene in a variety of styles. The proposed SC-GAN has two components: a content code which is the input to the generator, and a style code which modifies the scene style through modification of the Adaptive Instance Normalization (AdaIN) layers' parameters. We evaluate the proposed SC-GAN framework on a set of baseline datasets.