 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Maximization on Disentangled Representations for Differential Morph Detection
Dec 02, 2020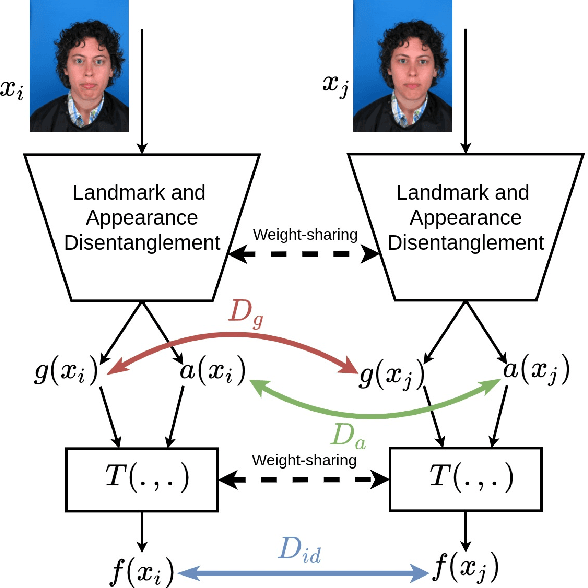
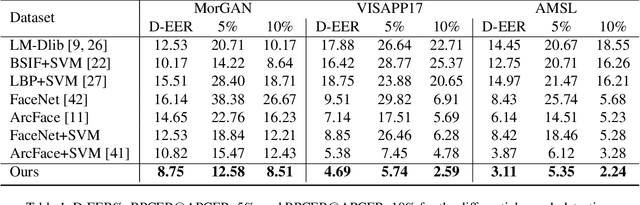
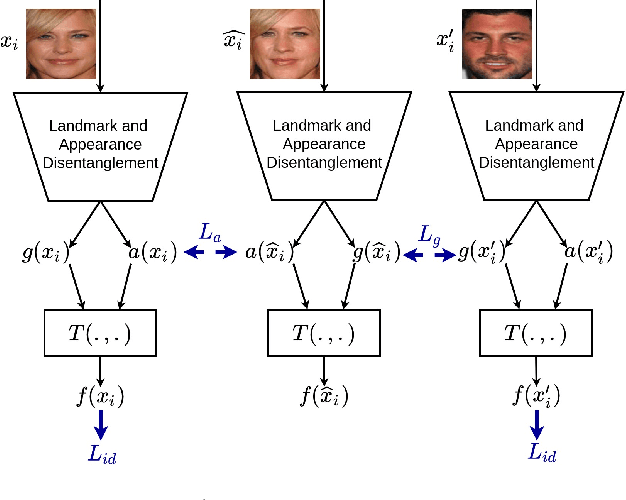
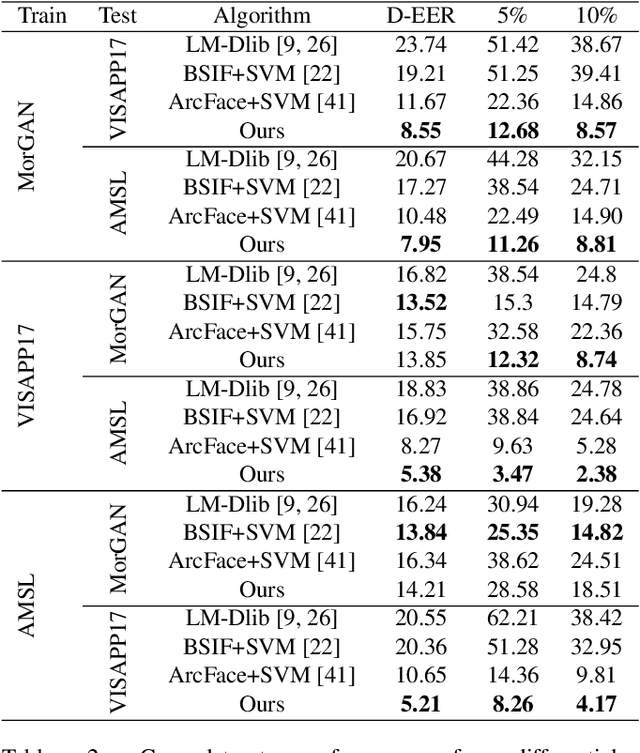
In this paper, we present a novel differential morph detection framework, utilizing landmark and appearance disentanglement. In our framework, the face image is represented in the embedding domain using two disentangled but complementary representations. The network is trained by triplets of face images, in which the intermediate image inherits the landmarks from one image and the appearance from the other image. This initially trained network is further trained for each dataset using contrastive representations. We demonstrate that, by employing appearance and landmark disentanglement, the proposed framework can provide state-of-the-art differential morph detection performance. This functionality is achieved by the using distances in landmark, appearance, and ID domains. The performance of the proposed framework is evaluated using three morph datasets generated with different methodologies.
Cross-Spectral Iris Matching Using Conditional Coupled GAN
Oct 09, 2020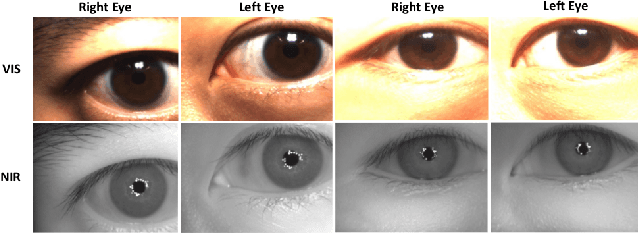
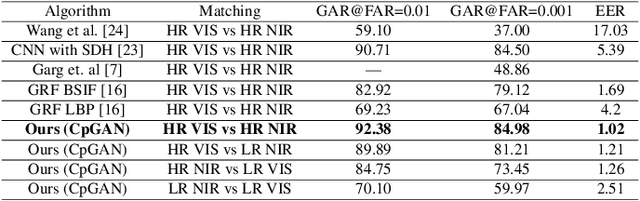
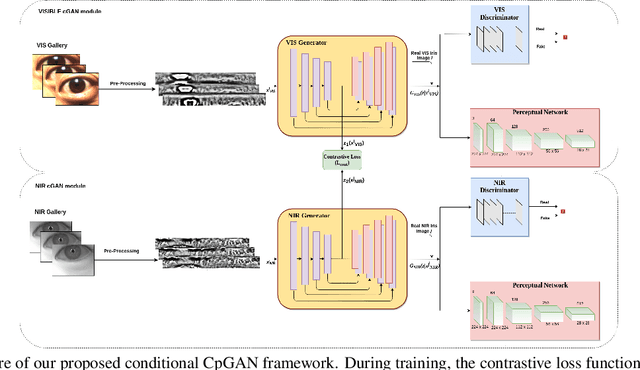

Cross-spectral iris recognition is emerging as a promising biometric approach to authenticating the identity of individuals. However, matching iris images acquired at different spectral bands shows significant performance degradation when compared to single-band near-infrared (NIR) matching due to the spectral gap between iris images obtained in the NIR and visual-light (VIS) spectra. Although researchers have recently focused on deep-learning-based approaches to recover invariant representative features for more accurate recognition performance, the existing methods cannot achieve the expected accuracy required for commercial applications. Hence, in this paper, we propose a conditional coupled generative adversarial network (CpGAN) architecture for cross-spectral iris recognition by projecting the VIS and NIR iris images into a low-dimensional embedding domain to explore the hidden relationship between them. The conditional CpGAN framework consists of a pair of GAN-based networks, one responsible for retrieving images in the visible domain and other responsible for retrieving images in the NIR domain. Both networks try to map the data into a common embedding subspace to ensure maximum pair-wise similarity between the feature vectors from the two iris modalities of the same subject. To prove the usefulness of our proposed approach, extensive experimental results obtained on the PolyU dataset are compared to existing state-of-the-art cross-spectral recognition methods.
Attribute Adaptive Margin Softmax Loss using Privileged Information
Sep 04, 2020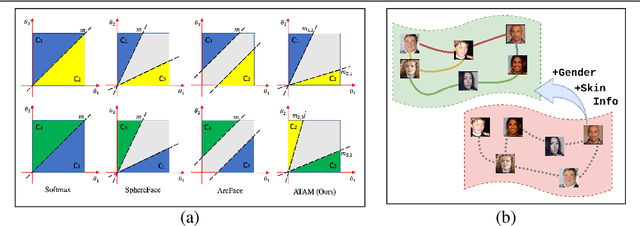
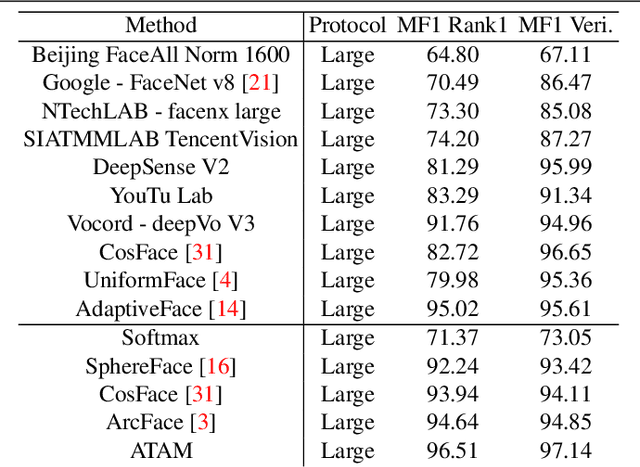
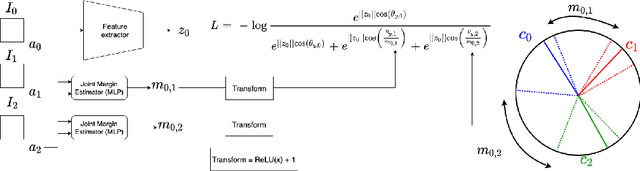
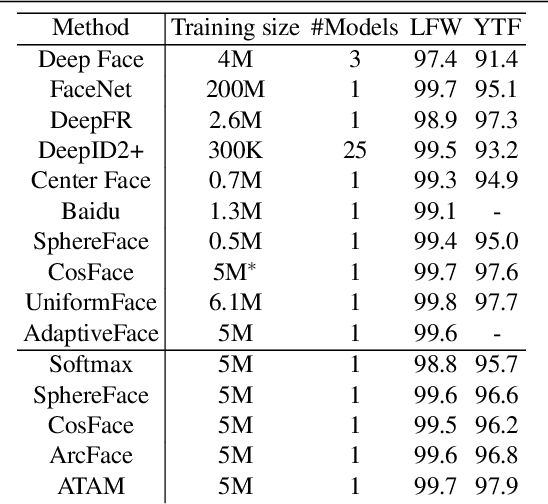
We present a novel framework to exploit privileged information for recognition which is provided only during the training phase. Here, we focus on recognition task where images are provided as the main view and soft biometric traits (attributes) are provided as the privileged data (only available during training phase). We demonstrate that more discriminative feature space can be learned by enforcing a deep network to adjust adaptive margins between classes utilizing attributes. This tight constraint also effectively reduces the class imbalance inherent in the local data neighborhood, thus carving more balanced class boundaries locally and using feature space more efficiently. Extensive experiments are performed on five different datasets and the results show the superiority of our method compared to the state-of-the-art models in both tasks of face recognition and person re-identification.
Joint-SRVDNet: Joint Super Resolution and Vehicle Detection Network
May 03, 2020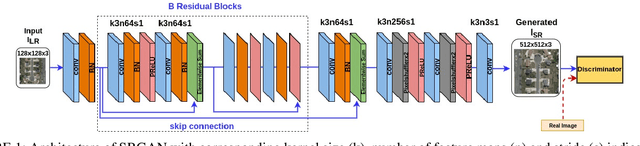

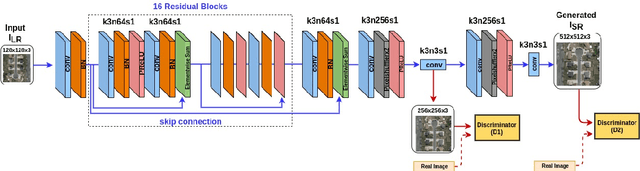
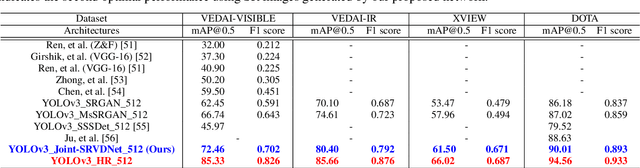
In many domestic and military applications, aerial vehicle detection and super-resolutionalgorithms are frequently developed and applied independently. However, aerial vehicle detection on super-resolved images remains a challenging task due to the lack of discriminative information in the super-resolved images. To address this problem, we propose a Joint Super-Resolution and Vehicle DetectionNetwork (Joint-SRVDNet) that tries to generate discriminative, high-resolution images of vehicles fromlow-resolution aerial images. First, aerial images are up-scaled by a factor of 4x using a Multi-scaleGenerative Adversarial Network (MsGAN), which has multiple intermediate outputs with increasingresolutions. Second, a detector is trained on super-resolved images that are upscaled by factor 4x usingMsGAN architecture and finally, the detection loss is minimized jointly with the super-resolution loss toencourage the target detector to be sensitive to the subsequent super-resolution training. The network jointlylearns hierarchical and discriminative features of targets and produces optimal super-resolution results. Weperform both quantitative and qualitative evaluation of our proposed network on VEDAI, xView and DOTAdatasets. The experimental results show that our proposed framework achieves better visual quality than thestate-of-the-art methods for aerial super-resolution with 4x up-scaling factor and improves the accuracy ofaerial vehicle detection.
PF-cpGAN: Profile to Frontal Coupled GAN for Face Recognition in the Wild
Apr 25, 2020
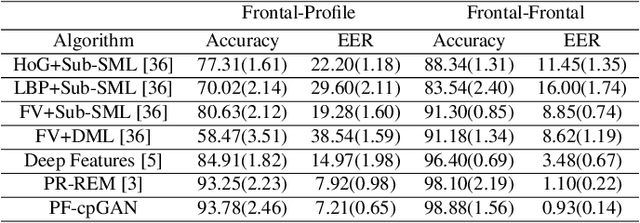
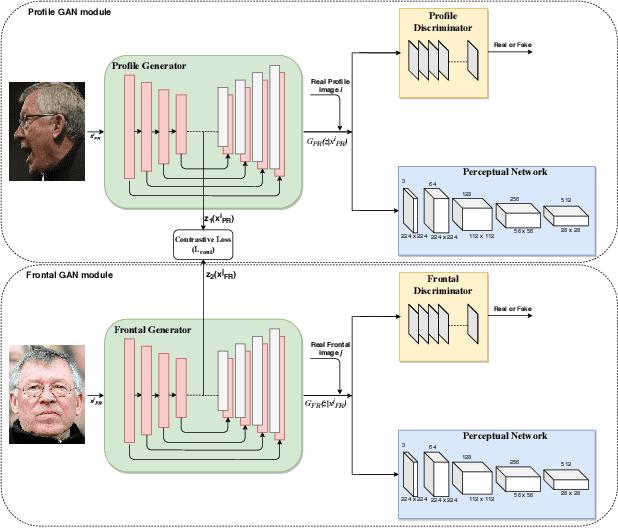
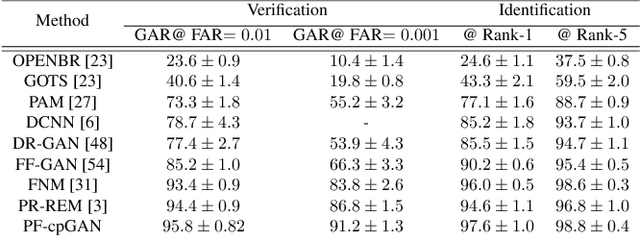
In recent years, due to the emergence of deep learning, face recognition has achieved exceptional success. However, many of these deep face recognition models perform relatively poorly in handling profile faces compared to frontal faces. The major reason for this poor performance is that it is inherently difficult to learn large pose invariant deep representations that are useful for profile face recognition. In this paper, we hypothesize that the profile face domain possesses a gradual connection with the frontal face domain in the deep feature space. We look to exploit this connection by projecting the profile faces and frontal faces into a common latent space and perform verification or retrieval in the latent domain. We leverage a coupled generative adversarial network (cpGAN) structure to find the hidden relationship between the profile and frontal images in a latent common embedding subspace. Specifically, the cpGAN framework consists of two GAN-based sub-networks, one dedicated to the frontal domain and the other dedicated to the profile domain. Each sub-network tends to find a projection that maximizes the pair-wise correlation between two feature domains in a common embedding feature subspace. The efficacy of our approach compared with the state-of-the-art is demonstrated using the CFP, CMU MultiPIE, IJB-A, and IJB-C datasets.
Error-Corrected Margin-Based Deep Cross-Modal Hashing for Facial Image Retrieval
Apr 03, 2020
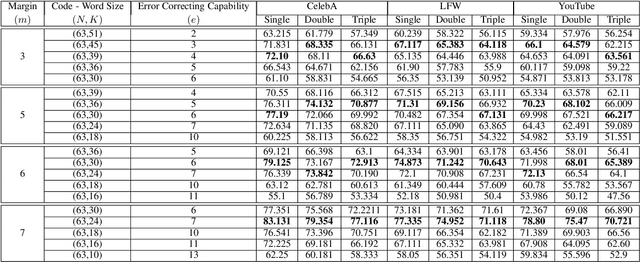
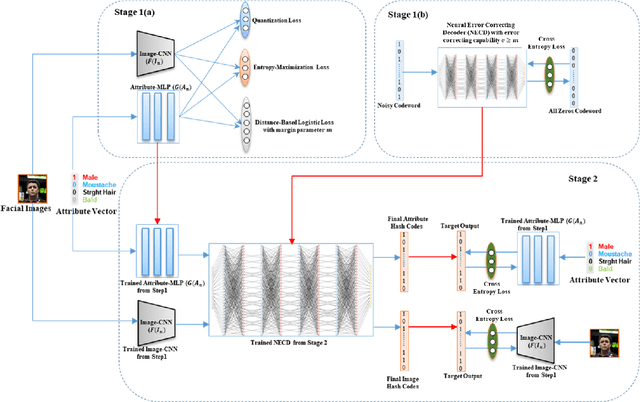
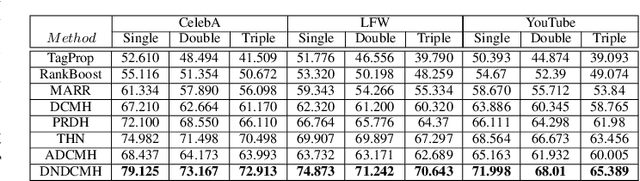
Cross-modal hashing facilitates mapping of heterogeneous multimedia data into a common Hamming space, which can beutilized for fast and flexible retrieval across different modalities. In this paper, we propose a novel cross-modal hashingarchitecture-deep neural decoder cross-modal hashing (DNDCMH), which uses a binary vector specifying the presence of certainfacial attributes as an input query to retrieve relevant face images from a database. The DNDCMH network consists of two separatecomponents: an attribute-based deep cross-modal hashing (ADCMH) module, which uses a margin (m)-based loss function toefficiently learn compact binary codes to preserve similarity between modalities in the Hamming space, and a neural error correctingdecoder (NECD), which is an error correcting decoder implemented with a neural network. The goal of NECD network in DNDCMH isto error correct the hash codes generated by ADCMH to improve the retrieval efficiency. The NECD network is trained such that it hasan error correcting capability greater than or equal to the margin (m) of the margin-based loss function. This results in NECD cancorrect the corrupted hash codes generated by ADCMH up to the Hamming distance of m. We have evaluated and comparedDNDCMH with state-of-the-art cross-modal hashing methods on standard datasets to demonstrate the superiority of our method.
SuperMix: Supervising the Mixing Data Augmentation
Mar 10, 2020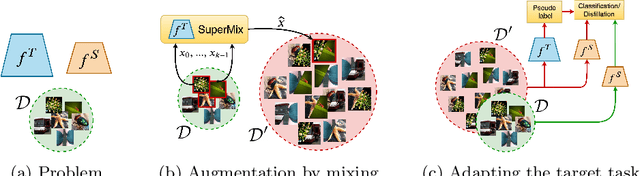
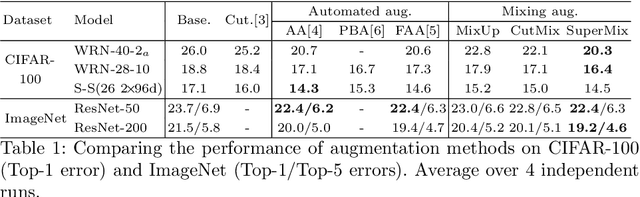
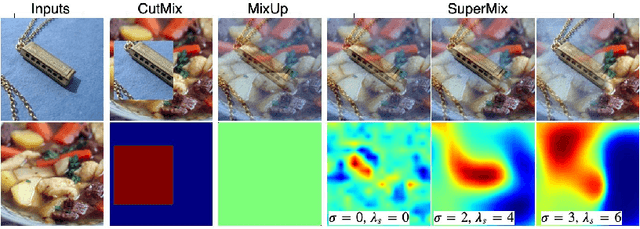
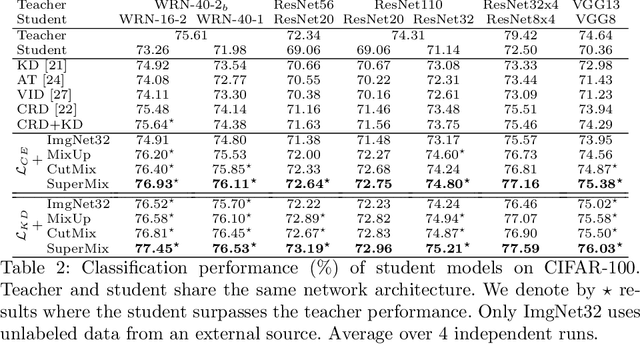
In this paper, we propose a supervised mixing augmentation method, termed SuperMix, which exploits the knowledge of a teacher to mix images based on their salient regions. SuperMix optimizes a mixing objective that considers: i) forcing the class of input images to appear in the mixed image, ii) preserving the local structure of images, and iii) reducing the risk of suppressing important features. To make the mixing suitable for large-scale applications, we develop an optimization technique, $65\times$ faster than gradient descent on the same problem. We validate the effectiveness of SuperMix through extensive evaluations and ablation studies on two tasks of object classification and knowledge distillation. On the classification task, SuperMix provides the same performance as the advanced augmentation methods, such as AutoAugment. On the distillation task, SuperMix sets a new state-of-the-art with a significantly simplified distillation method. Particularly, in six out of eight teacher-student setups from the same architectures, the students trained on the mixed data surpass their teachers with a notable margin.
Boosting Deep Face Recognition via Disentangling Appearance and Geometry
Jan 13, 2020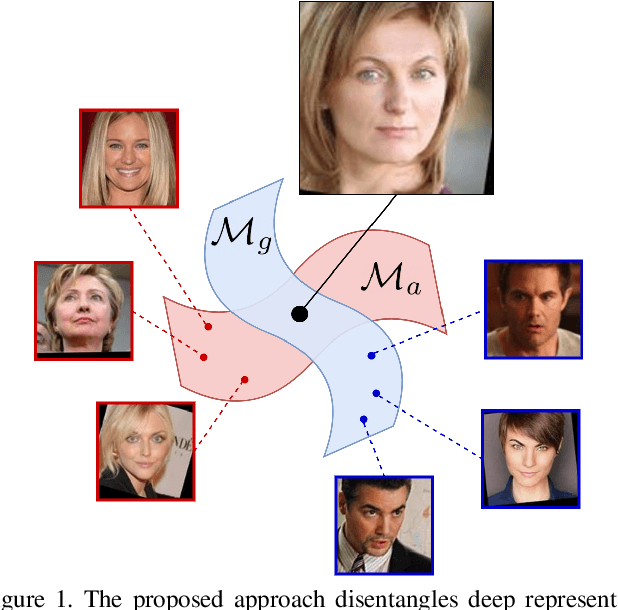
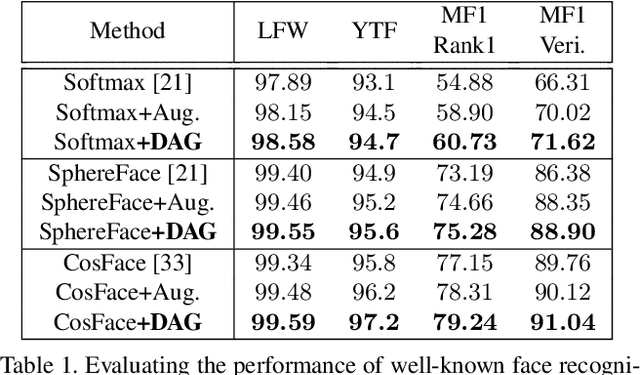

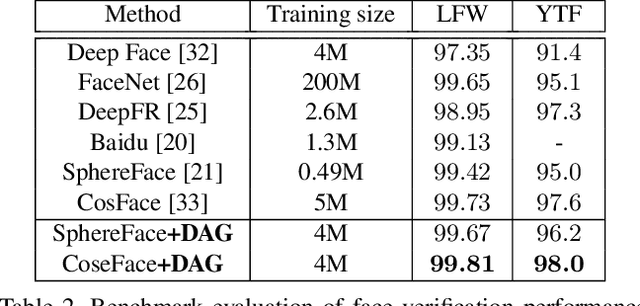
In this paper, we propose a framework for disentangling the appearance and geometry representations in the face recognition task. To provide supervision for this aim, we generate geometrically identical faces by incorporating spatial transformations. We demonstrate that the proposed approach enhances the performance of deep face recognition models by assisting the training process in two ways. First, it enforces the early and intermediate convolutional layers to learn more representative features that satisfy the properties of disentangled embeddings. Second, it augments the training set by altering faces geometrically. Through extensive experiments, we demonstrate that integrating the proposed approach into state-of-the-art face recognition methods effectively improves their performance on challenging datasets, such as LFW, YTF, and MegaFace. Both theoretical and practical aspects of the method are analyzed rigorously by concerning ablation studies and knowledge transfer tasks. Furthermore, we show that the knowledge leaned by the proposed method can favor other face-related tasks, such as attribute prediction.
Robust Facial Landmark Detection via Aggregation on Geometrically Manipulated Faces
Jan 07, 2020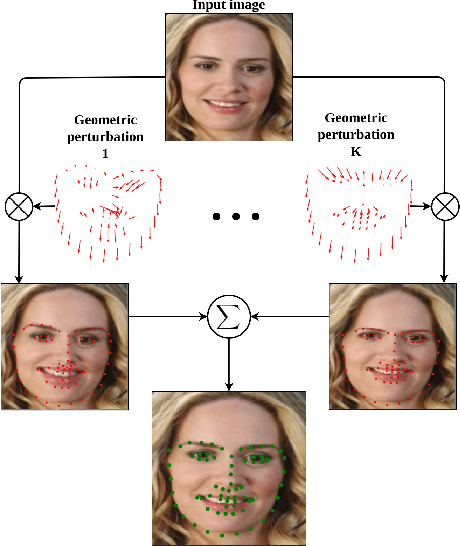

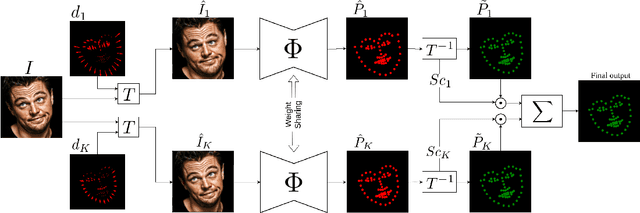
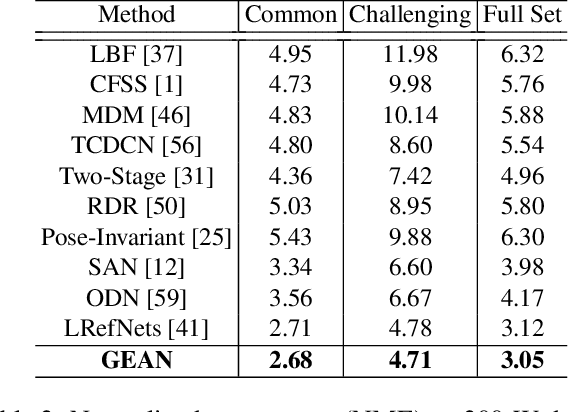
In this work, we present a practical approach to the problem of facial landmark detection. The proposed method can deal with large shape and appearance variations under the rich shape deformation. To handle the shape variations we equip our method with the aggregation of manipulated face images. The proposed framework generates different manipulated faces using only one given face image. The approach utilizes the fact that small but carefully crafted geometric manipulation in the input domain can fool deep face recognition models. We propose three different approaches to generate manipulated faces in which two of them perform the manipulations via adversarial attacks and the other one uses known transformations. Aggregating the manipulated faces provides a more robust landmark detection approach which is able to capture more important deformations and variations of the face shapes. Our approach is demonstrated its superiority compared to the state-of-the-art method on benchmark datasets AFLW, 300-W, and COFW.
SmoothFool: An Efficient Framework for Computing Smooth Adversarial Perturbations
Oct 08, 2019
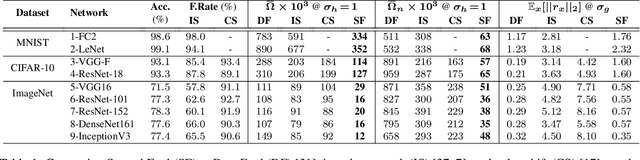
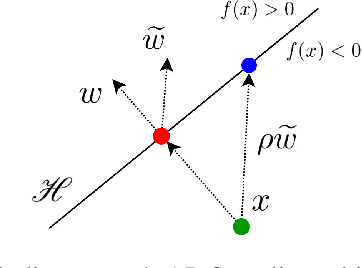
Deep neural networks are susceptible to adversarial manipulations in the input domain. The extent of vulnerability has been explored intensively in cases of $\ell_p$-bounded and $\ell_p$-minimal adversarial perturbations. However, the vulnerability of DNNs to adversarial perturbations with specific statistical properties or frequency-domain characteristics has not been sufficiently explored. In this paper, we study the smoothness of perturbations and propose SmoothFool, a general and computationally efficient framework for computing smooth adversarial perturbations. Through extensive experiments, we validate the efficacy of the proposed method for both the white-box and black-box attack scenarios. In particular, we demonstrate that: (i) there exist extremely smooth adversarial perturbations for well-established and widely used network architectures, (ii) smoothness significantly enhances the robustness of perturbations against state-of-the-art defense mechanisms, (iii) smoothness improves the transferability of adversarial perturbations across both data points and network architectures, and (iv) class categories exhibit a variable range of susceptibility to smooth perturbations. Our results suggest that smooth APs can play a significant role in exploring the vulnerability extent of DNNs to adversarial examples.