 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNasser M. Nasrabadi
CCFace: Classification Consistency for Low-Resolution Face Recognition
Aug 18, 2023
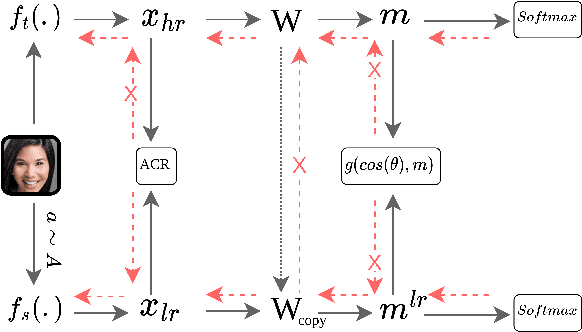


In recent years, deep face recognition methods have demonstrated impressive results on in-the-wild datasets. However, these methods have shown a significant decline in performance when applied to real-world low-resolution benchmarks like TinyFace or SCFace. To address this challenge, we propose a novel classification consistency knowledge distillation approach that transfers the learned classifier from a high-resolution model to a low-resolution network. This approach helps in finding discriminative representations for low-resolution instances. To further improve the performance, we designed a knowledge distillation loss using the adaptive angular penalty inspired by the success of the popular angular margin loss function. The adaptive penalty reduces overfitting on low-resolution samples and alleviates the convergence issue of the model integrated with data augmentation. Additionally, we utilize an asymmetric cross-resolution learning approach based on the state-of-the-art semi-supervised representation learning paradigm to improve discriminability on low-resolution instances and prevent them from forming a cluster. Our proposed method outperforms state-of-the-art approaches on low-resolution benchmarks, with a three percent improvement on TinyFace while maintaining performance on high-resolution benchmarks.
AAFACE: Attribute-aware Attentional Network for Face Recognition
Aug 14, 2023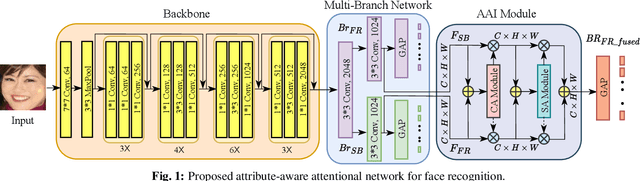
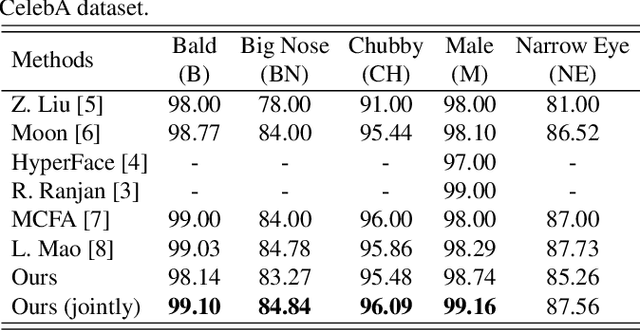
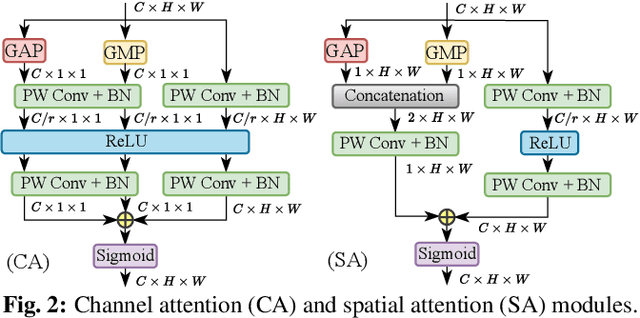
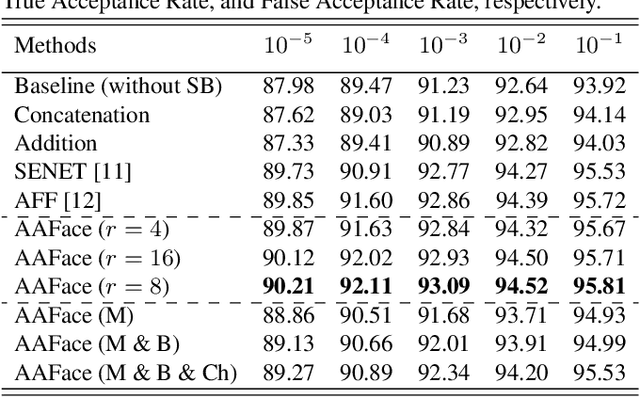
In this paper, we present a new multi-branch neural network that simultaneously performs soft biometric (SB) prediction as an auxiliary modality and face recognition (FR) as the main task. Our proposed network named AAFace utilizes SB attributes to enhance the discriminative ability of FR representation. To achieve this goal, we propose an attribute-aware attentional integration (AAI) module to perform weighted integration of FR with SB feature maps. Our proposed AAI module is not only fully context-aware but also capable of learning complex relationships between input features by means of the sequential multi-scale channel and spatial sub-modules. Experimental results verify the superiority of our proposed network compared with the state-of-the-art (SoTA) SB prediction and FR methods.
Frequency Disentangled Features in Neural Image Compression
Aug 04, 2023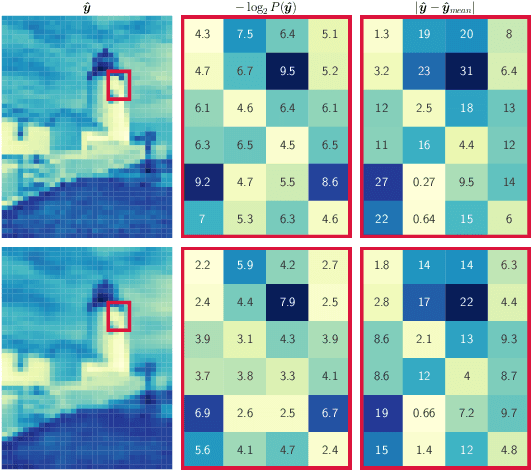

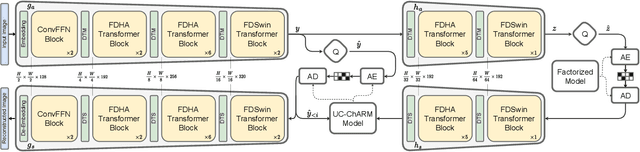
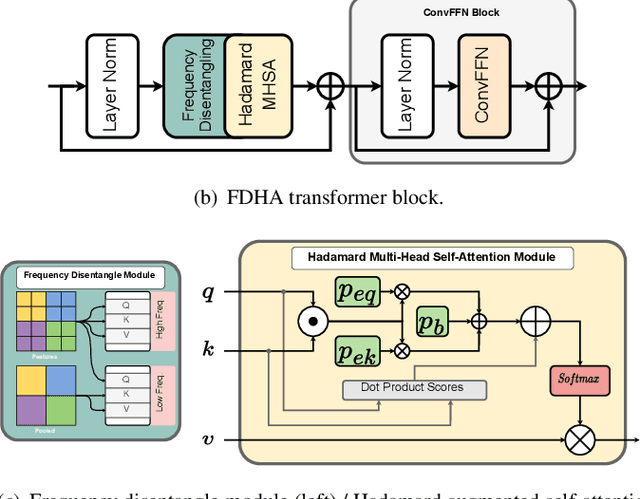
The design of a neural image compression network is governed by how well the entropy model matches the true distribution of the latent code. Apart from the model capacity, this ability is indirectly under the effect of how close the relaxed quantization is to the actual hard quantization. Optimizing the parameters of a rate-distortion variational autoencoder (R-D VAE) is ruled by this approximated quantization scheme. In this paper, we propose a feature-level frequency disentanglement to help the relaxed scalar quantization achieve lower bit rates by guiding the high entropy latent features to include most of the low-frequency texture of the image. In addition, to strengthen the de-correlating power of the transformer-based analysis/synthesis transform, an augmented self-attention score calculation based on the Hadamard product is utilized during both encoding and decoding. Channel-wise autoregressive entropy modeling takes advantage of the proposed frequency separation as it inherently directs high-informational low-frequency channels to the first chunks and conditions the future chunks on it. The proposed network not only outperforms hand-engineered codecs, but also neural network-based codecs built on computation-heavy spatially autoregressive entropy models.
A Quality Aware Sample-to-Sample Comparison for Face Recognition
Jun 06, 2023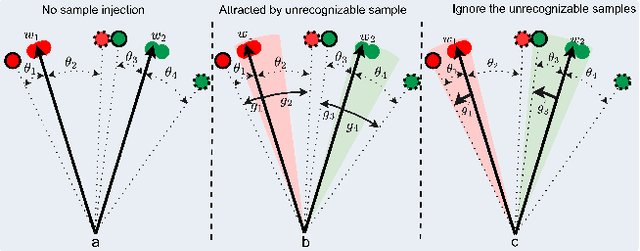
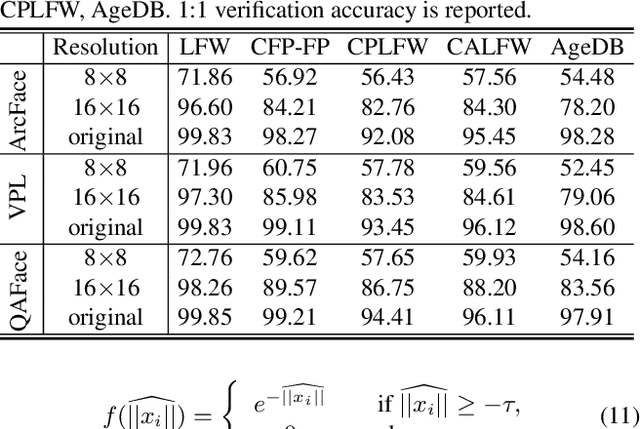

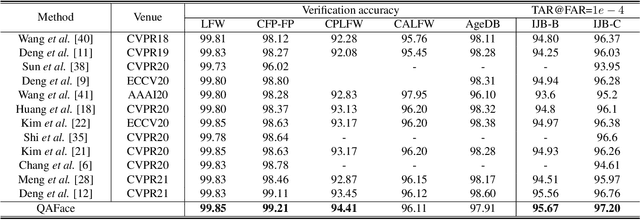
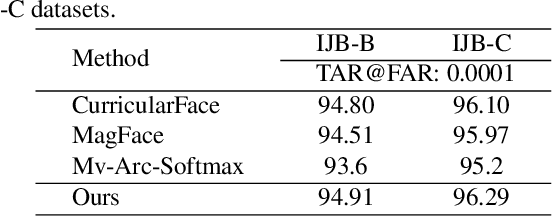
Currently available face datasets mainly consist of a large number of high-quality and a small number of low-quality samples. As a result, a Face Recognition (FR) network fails to learn the distribution of low-quality samples since they are less frequent during training (underrepresented). Moreover, current state-of-the-art FR training paradigms are based on the sample-to-center comparison (i.e., Softmax-based classifier), which results in a lack of uniformity between train and test metrics. This work integrates a quality-aware learning process at the sample level into the classification training paradigm (QAFace). In this regard, Softmax centers are adaptively guided to pay more attention to low-quality samples by using a quality-aware function. Accordingly, QAFace adds a quality-based adjustment to the updating procedure of the Softmax-based classifier to improve the performance on the underrepresented low-quality samples. Our method adaptively finds and assigns more attention to the recognizable low-quality samples in the training datasets. In addition, QAFace ignores the unrecognizable low-quality samples using the feature magnitude as a proxy for quality. As a result, QAFace prevents class centers from getting distracted from the optimal direction. The proposed method is superior to the state-of-the-art algorithms in extensive experimental results on the CFP-FP, LFW, CPLFW, CALFW, AgeDB, IJB-B, and IJB-C datasets.
Deep Transductive Transfer Learning for Automatic Target Recognition
May 23, 2023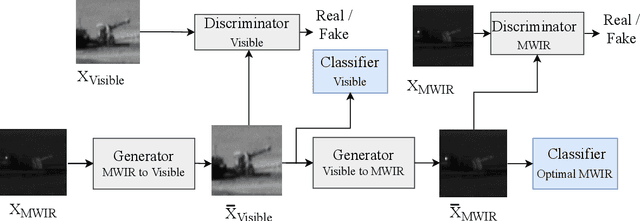
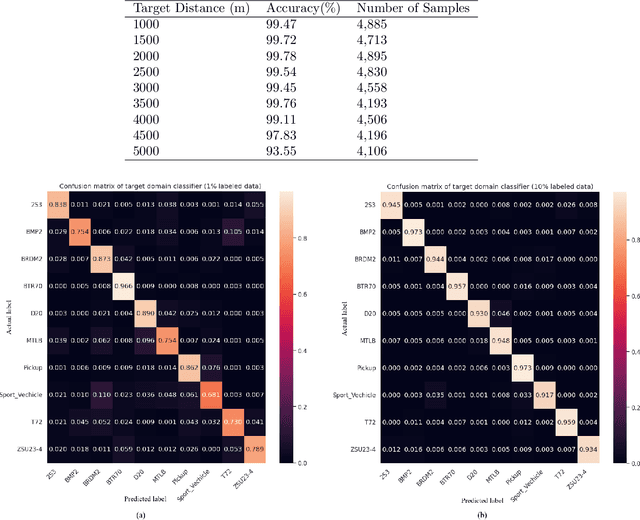
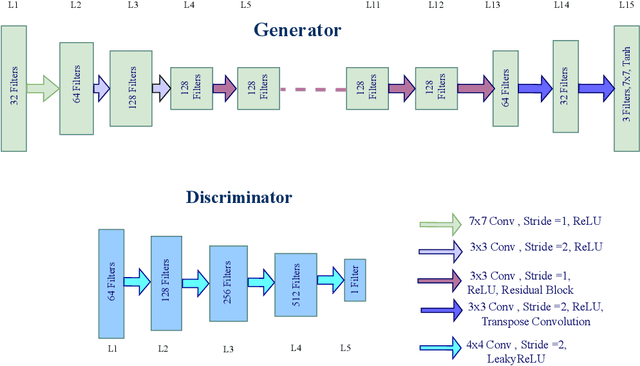
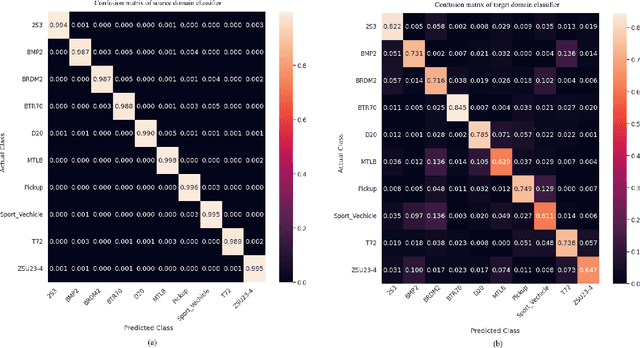
One of the major obstacles in designing an automatic target recognition (ATR) algorithm, is that there are often labeled images in one domain (i.e., infrared source domain) but no annotated images in the other target domains (i.e., visible, SAR, LIDAR). Therefore, automatically annotating these images is essential to build a robust classifier in the target domain based on the labeled images of the source domain. Transductive transfer learning is an effective way to adapt a network to a new target domain by utilizing a pretrained ATR network in the source domain. We propose an unpaired transductive transfer learning framework where a CycleGAN model and a well-trained ATR classifier in the source domain are used to construct an ATR classifier in the target domain without having any labeled data in the target domain. We employ a CycleGAN model to transfer the mid-wave infrared (MWIR) images to visible (VIS) domain images (or visible to MWIR domain). To train the transductive CycleGAN, we optimize a cost function consisting of the adversarial, identity, cycle-consistency, and categorical cross-entropy loss for both the source and target classifiers. In this paper, we perform a detailed experimental analysis on the challenging DSIAC ATR dataset. The dataset consists of ten classes of vehicles at different poses and distances ranging from 1-5 kilometers on both the MWIR and VIS domains. In our experiment, we assume that the images in the VIS domain are the unlabeled target dataset. We first detect and crop the vehicles from the raw images and then project them into a common distance of 2 kilometers. Our proposed transductive CycleGAN achieves 71.56% accuracy in classifying the visible domain vehicles in the DSIAC ATR dataset.
* 10 pages, 5 figures
Landmark Enforcement and Style Manipulation for Generative Morphing
Oct 18, 2022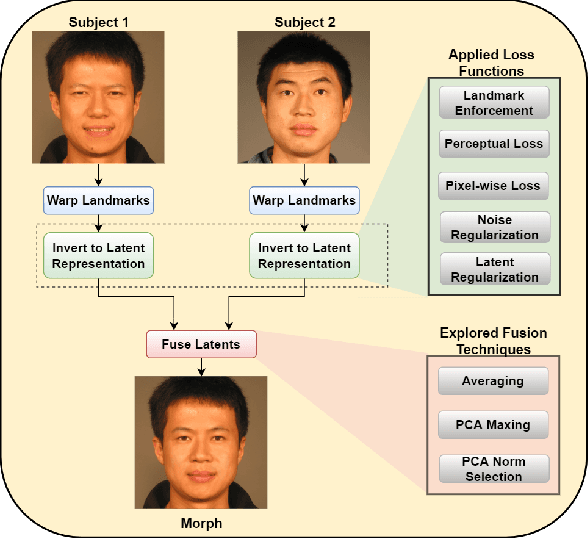
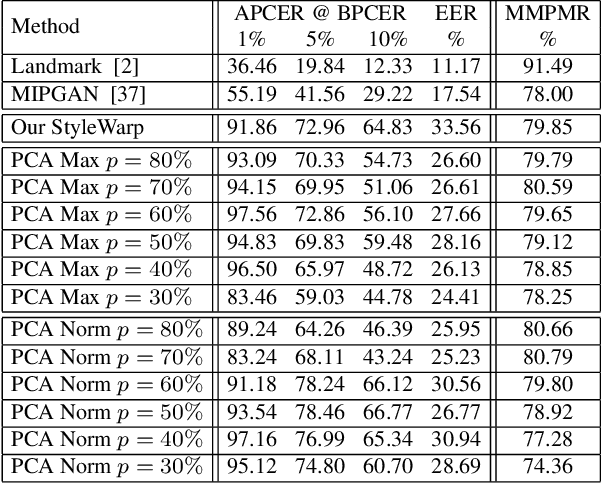

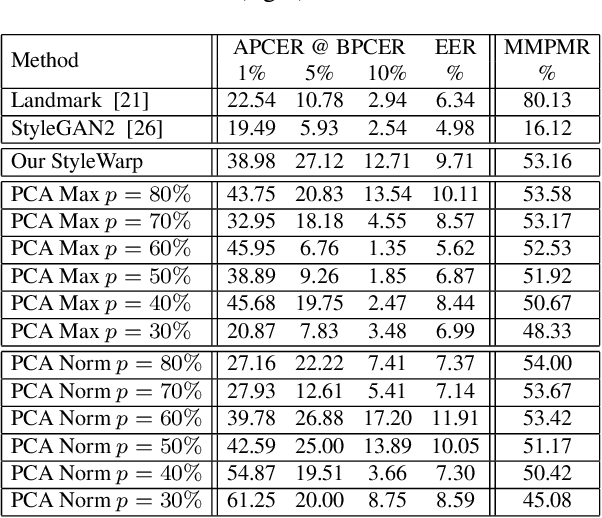
Morph images threaten Facial Recognition Systems (FRS) by presenting as multiple individuals, allowing an adversary to swap identities with another subject. Morph generation using generative adversarial networks (GANs) results in high-quality morphs unaffected by the spatial artifacts caused by landmark-based methods, but there is an apparent loss in identity with standard GAN-based morphing methods. In this paper, we propose a novel StyleGAN morph generation technique by introducing a landmark enforcement method to resolve this issue. Considering this method, we aim to enforce the landmarks of the morph image to represent the spatial average of the landmarks of the bona fide faces and subsequently the morph images to inherit the geometric identity of both bona fide faces. Exploration of the latent space of our model is conducted using Principal Component Analysis (PCA) to accentuate the effect of both the bona fide faces on the morphed latent representation and address the identity loss issue with latent domain averaging. Additionally, to improve high frequency reconstruction in the morphs, we study the train-ability of the noise input for the StyleGAN2 model.
Attention-Based Generative Neural Image Compression on Solar Dynamics Observatory
Oct 12, 2022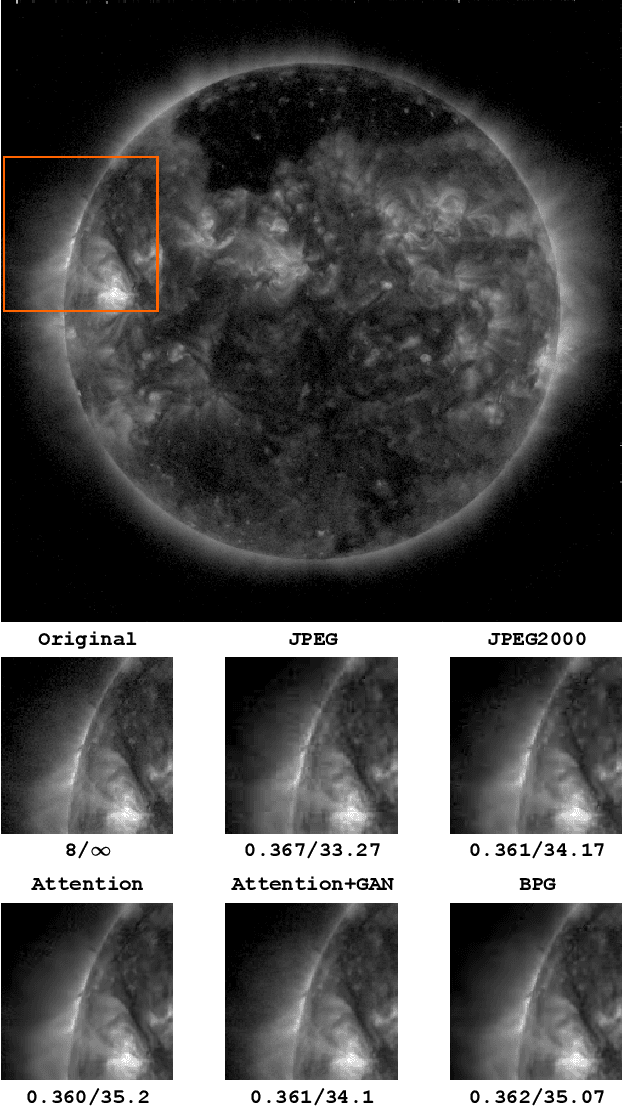
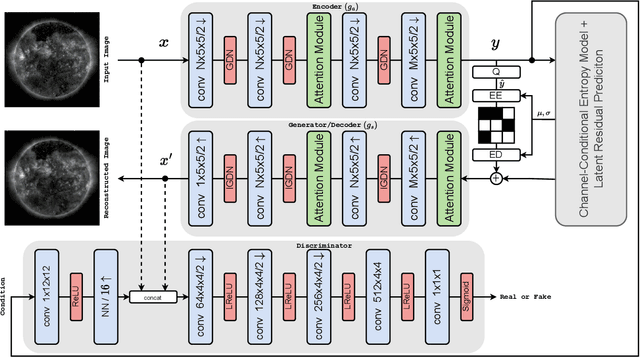
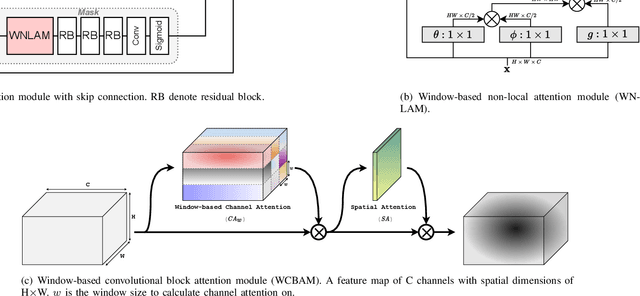
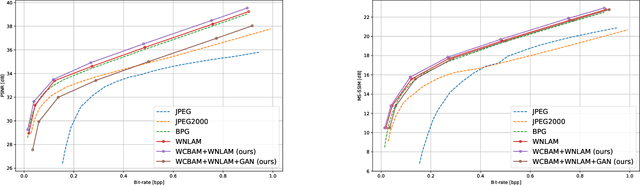
NASA's Solar Dynamics Observatory (SDO) mission gathers 1.4 terabytes of data each day from its geosynchronous orbit in space. SDO data includes images of the Sun captured at different wavelengths, with the primary scientific goal of understanding the dynamic processes governing the Sun. Recently, end-to-end optimized artificial neural networks (ANN) have shown great potential in performing image compression. ANN-based compression schemes have outperformed conventional hand-engineered algorithms for lossy and lossless image compression. We have designed an ad-hoc ANN-based image compression scheme to reduce the amount of data needed to be stored and retrieved on space missions studying solar dynamics. In this work, we propose an attention module to make use of both local and non-local attention mechanisms in an adversarially trained neural image compression network. We have also demonstrated the superior perceptual quality of this neural image compressor. Our proposed algorithm for compressing images downloaded from the SDO spacecraft performs better in rate-distortion trade-off than the popular currently-in-use image compression codecs such as JPEG and JPEG2000. In addition we have shown that the proposed method outperforms state-of-the art lossy transform coding compression codec, i.e., BPG.
Robust Ensemble Morph Detection with Domain Generalization
Sep 16, 2022
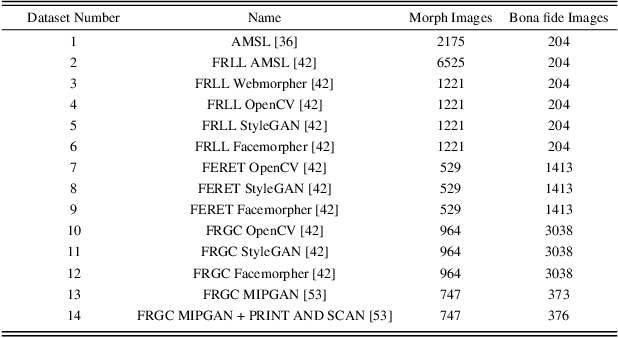
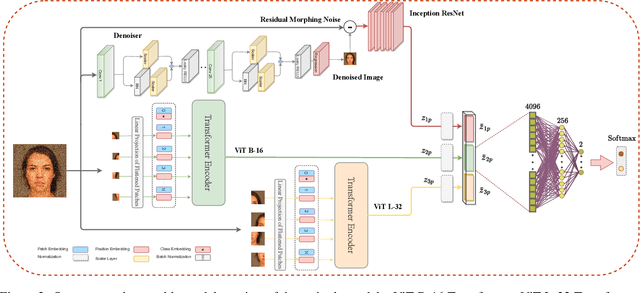
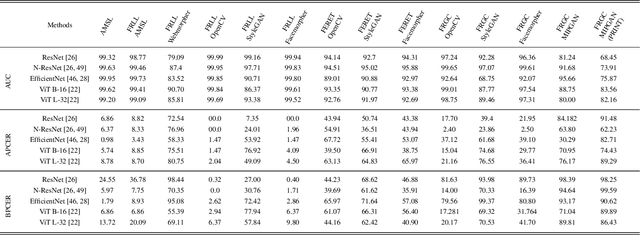
Although a substantial amount of studies is dedicated to morph detection, most of them fail to generalize for morph faces outside of their training paradigm. Moreover, recent morph detection methods are highly vulnerable to adversarial attacks. In this paper, we intend to learn a morph detection model with high generalization to a wide range of morphing attacks and high robustness against different adversarial attacks. To this aim, we develop an ensemble of convolutional neural networks (CNNs) and Transformer models to benefit from their capabilities simultaneously. To improve the robust accuracy of the ensemble model, we employ multi-perturbation adversarial training and generate adversarial examples with high transferability for several single models. Our exhaustive evaluations demonstrate that the proposed robust ensemble model generalizes to several morphing attacks and face datasets. In addition, we validate that our robust ensemble model gain better robustness against several adversarial attacks while outperforming the state-of-the-art studies.
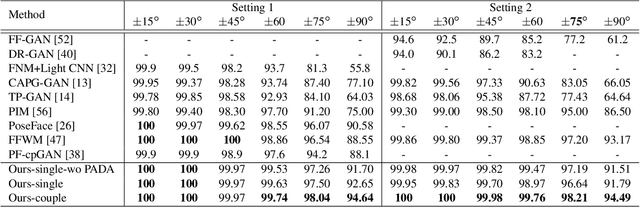
Pose Attention-Guided Profile-to-Frontal Face Recognition
Sep 15, 2022
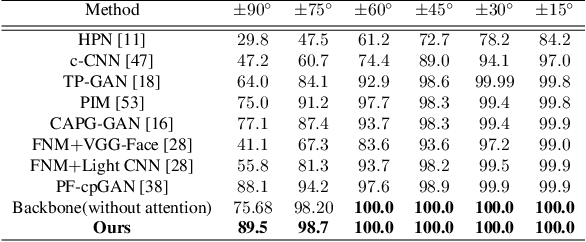
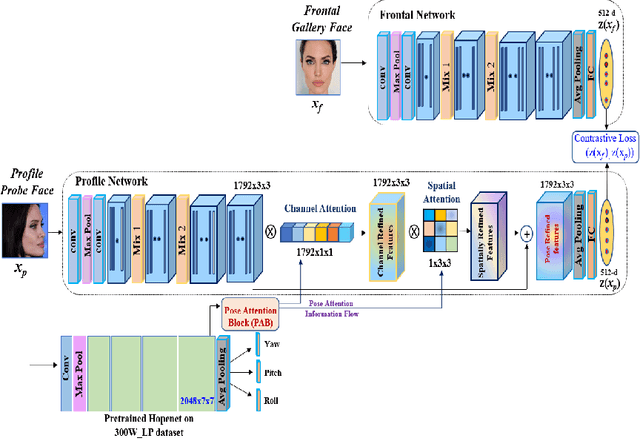
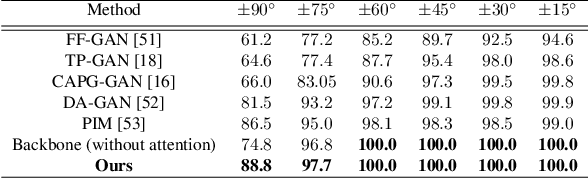
In recent years, face recognition systems have achieved exceptional success due to promising advances in deep learning architectures. However, they still fail to achieve expected accuracy when matching profile images against a gallery of frontal images. Current approaches either perform pose normalization (i.e., frontalization) or disentangle pose information for face recognition. We instead propose a new approach to utilize pose as an auxiliary information via an attention mechanism. In this paper, we hypothesize that pose attended information using an attention mechanism can guide contextual and distinctive feature extraction from profile faces, which further benefits a better representation learning in an embedded domain. To achieve this, first, we design a unified coupled profile-to-frontal face recognition network. It learns the mapping from faces to a compact embedding subspace via a class-specific contrastive loss. Second, we develop a novel pose attention block (PAB) to specially guide the pose-agnostic feature extraction from profile faces. To be more specific, PAB is designed to explicitly help the network to focus on important features along both channel and spatial dimension while learning discriminative yet pose invariant features in an embedding subspace. To validate the effectiveness of our proposed method, we conduct experiments on both controlled and in the wild benchmarks including Multi-PIE, CFP, IJBC, and show superiority over the state of the arts.
Information Maximization for Extreme Pose Face Recognition
Sep 07, 2022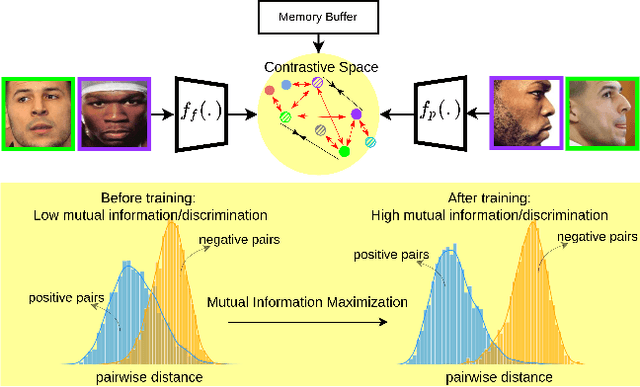
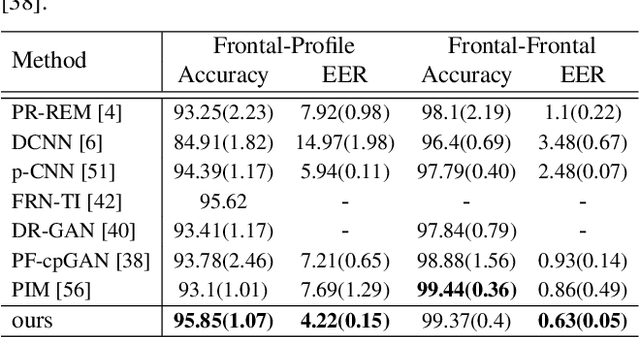
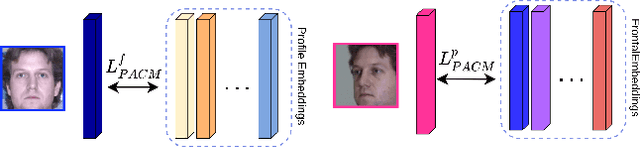
In this paper, we seek to draw connections between the frontal and profile face images in an abstract embedding space. We exploit this connection using a coupled-encoder network to project frontal/profile face images into a common latent embedding space. The proposed model forces the similarity of representations in the embedding space by maximizing the mutual information between two views of the face. The proposed coupled-encoder benefits from three contributions for matching faces with extreme pose disparities. First, we leverage our pose-aware contrastive learning to maximize the mutual information between frontal and profile representations of identities. Second, a memory buffer, which consists of latent representations accumulated over past iterations, is integrated into the model so it can refer to relatively much more instances than the mini-batch size. Third, a novel pose-aware adversarial domain adaptation method forces the model to learn an asymmetric mapping from profile to frontal representation. In our framework, the coupled-encoder learns to enlarge the margin between the distribution of genuine and imposter faces, which results in high mutual information between different views of the same identity. The effectiveness of the proposed model is investigated through extensive experiments, evaluations, and ablation studies on four benchmark datasets, and comparison with the compelling state-of-the-art algorithms.