 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNafise Sadat Moosavi
Improving QA Generalization by Concurrent Modeling of Multiple Biases
Oct 07, 2020

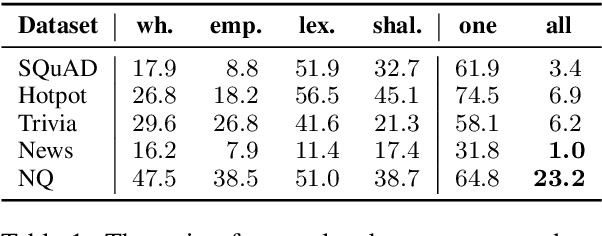
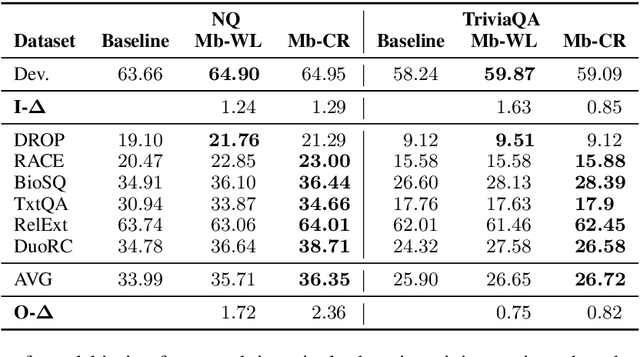
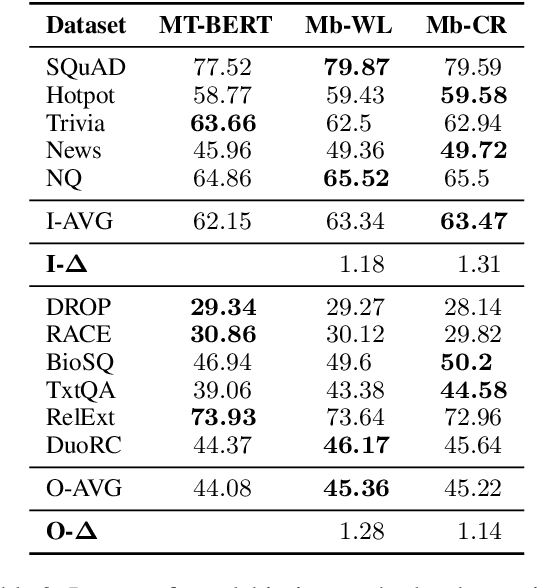
Existing NLP datasets contain various biases that models can easily exploit to achieve high performances on the corresponding evaluation sets. However, focusing on dataset-specific biases limits their ability to learn more generalizable knowledge about the task from more general data patterns. In this paper, we investigate the impact of debiasing methods for improving generalization and propose a general framework for improving the performance on both in-domain and out-of-domain datasets by concurrent modeling of multiple biases in the training data. Our framework weights each example based on the biases it contains and the strength of those biases in the training data. It then uses these weights in the training objective so that the model relies less on examples with high bias weights. We extensively evaluate our framework on extractive question answering with training data from various domains with multiple biases of different strengths. We perform the evaluations in two different settings, in which the model is trained on a single domain or multiple domains simultaneously, and show its effectiveness in both settings compared to state-of-the-art debiasing methods.
Towards Debiasing NLU Models from Unknown Biases
Sep 25, 2020
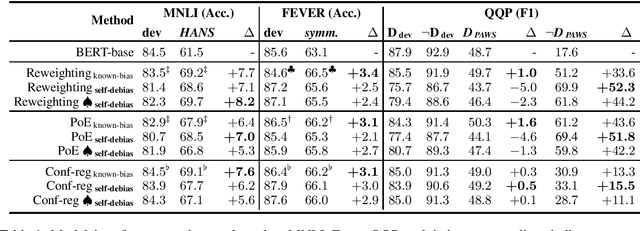
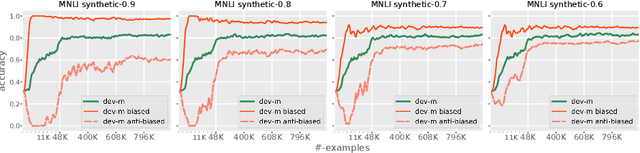
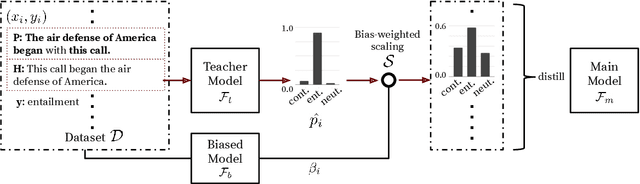
NLU models often exploit biases to achieve high dataset-specific performance without properly learning the intended task. Recently proposed debiasing methods are shown to be effective in mitigating this tendency. However, these methods rely on a major assumption that the types of bias are \emph{known} a-priori, which limits their application to many NLU tasks and datasets. In this work, we present the first step to bridge this gap by introducing a self-debiasing framework that prevents models from mainly utilizing biases without knowing them in advance. The proposed framework is general and complementary to the existing debiasing methods. We show that it allows these existing methods to retain the improvement on the challenge datasets (i.e., sets of examples designed to expose models' reliance on biases) without specifically targeting certain biases. Furthermore, the evaluation suggests that applying the framework results in improved overall robustness. We include the code in the supplementary material.
Mind the Trade-off: Debiasing NLU Models without Degrading the In-distribution Performance
May 01, 2020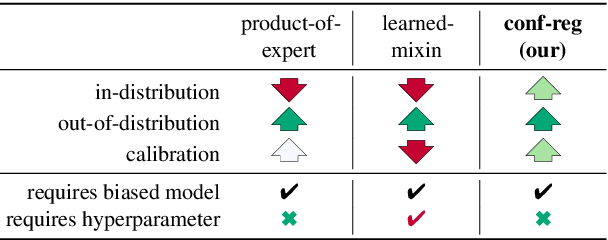
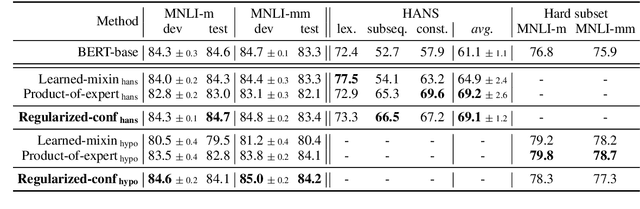
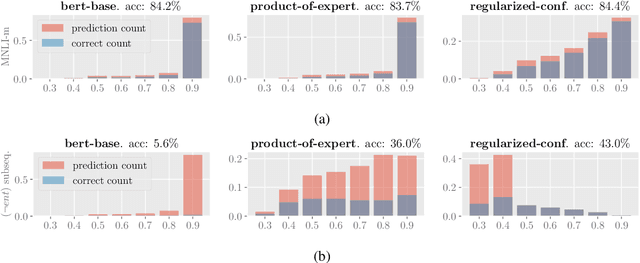
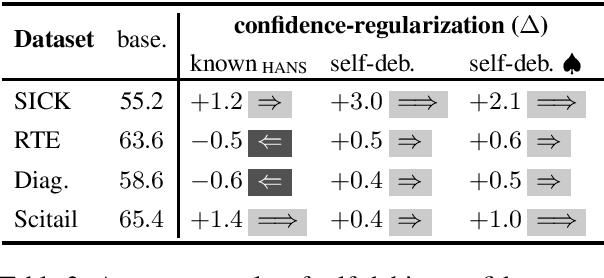
Models for natural language understanding (NLU) tasks often rely on the idiosyncratic biases of the dataset, which make them brittle against test cases outside the training distribution. Recently, several proposed debiasing methods are shown to be very effective in improving out-of-distribution performance. However, their improvements come at the expense of performance drop when models are evaluated on the in-distribution data, which contain examples with higher diversity. This seemingly inevitable trade-off may not tell us much about the changes in the reasoning and understanding capabilities of the resulting models on broader types of examples beyond the small subset represented in the out-of-distribution data. In this paper, we address this trade-off by introducing a novel debiasing method, called confidence regularization, which discourage models from exploiting biases while enabling them to receive enough incentive to learn from all the training examples. We evaluate our method on three NLU tasks and show that, in contrast to its predecessors, it improves the performance on out-of-distribution datasets (e.g., 7pp gain on HANS dataset) while maintaining the original in-distribution accuracy.
Neural Duplicate Question Detection without Labeled Training Data
Nov 13, 2019
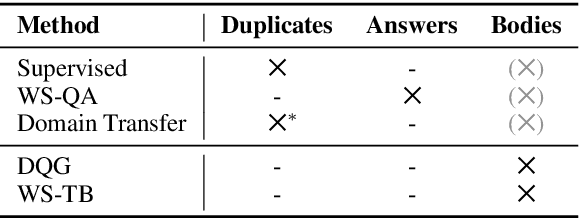
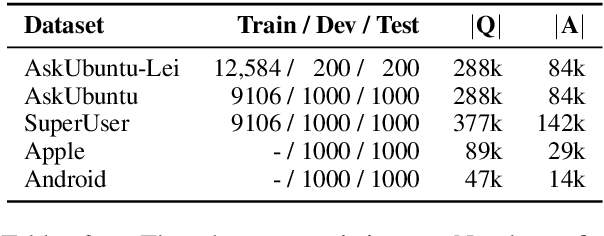
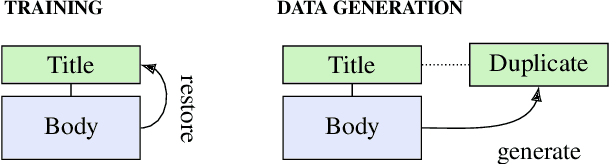
Supervised training of neural models to duplicate question detection in community Question Answering (cQA) requires large amounts of labeled question pairs, which can be costly to obtain. To minimize this cost, recent works thus often used alternative methods, e.g., adversarial domain adaptation. In this work, we propose two novel methods---weak supervision using the title and body of a question, and the automatic generation of duplicate questions---and show that both can achieve improved performances even though they do not require any labeled data. We provide a comparison of popular training strategies and show that our proposed approaches are more effective in many cases because they can utilize larger amounts of data from the cQA forums. Finally, we show that weak supervision with question title and body information is also an effective method to train cQA answer selection models without direct answer supervision.
Improving Generalization by Incorporating Coverage in Natural Language Inference
Sep 19, 2019
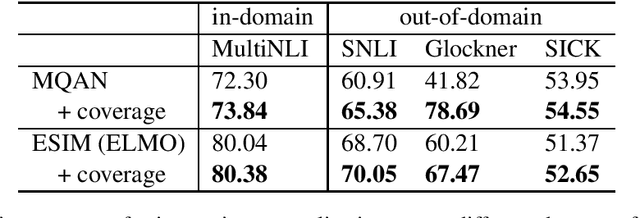
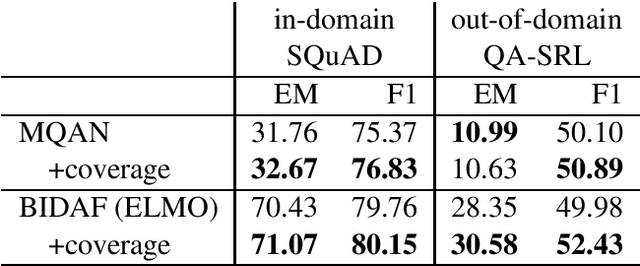
The task of natural language inference (NLI) is to identify the relation between the given premise and hypothesis. While recent NLI models achieve very high performance on individual datasets, they fail to generalize across similar datasets. This indicates that they are solving NLI datasets instead of the task itself. In order to improve generalization, we propose to extend the input representations with an abstract view of the relation between the hypothesis and the premise, i.e., how well the individual words, or word n-grams, of the hypothesis are covered by the premise. Our experiments show that the use of this information considerably improves generalization across different NLI datasets without requiring any external knowledge or additional data. Finally, we show that using the coverage information is not only beneficial for improving the performance across different datasets of the same task. The resulting generalization improves the performance across datasets that belong to similar but not the same tasks.
Using Automatically Extracted Minimum Spans to Disentangle Coreference Evaluation from Boundary Detection
Jun 16, 2019
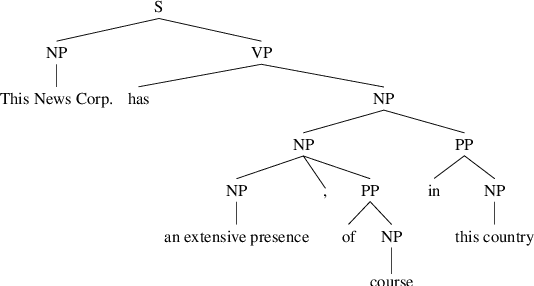

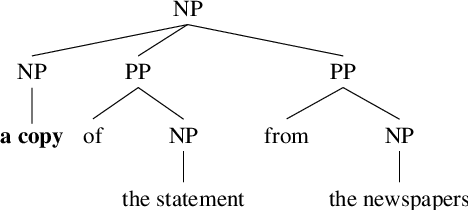
The common practice in coreference resolution is to identify and evaluate the maximum span of mentions. The use of maximum spans tangles coreference evaluation with the challenges of mention boundary detection like prepositional phrase attachment. To address this problem, minimum spans are manually annotated in smaller corpora. However, this additional annotation is costly and therefore, this solution does not scale to large corpora. In this paper, we propose the MINA algorithm for automatically extracting minimum spans to benefit from minimum span evaluation in all corpora. We show that the extracted minimum spans by MINA are consistent with those that are manually annotated by experts. Our experiments show that using minimum spans is in particular important in cross-dataset coreference evaluation, in which detected mention boundaries are noisier due to domain shift. We will integrate MINA into https://github.com/ns-moosavi/coval for reporting standard coreference scores based on both maximum and automatically detected minimum spans.
Using Linguistic Features to Improve the Generalization Capability of Neural Coreference Resolvers
Oct 12, 2018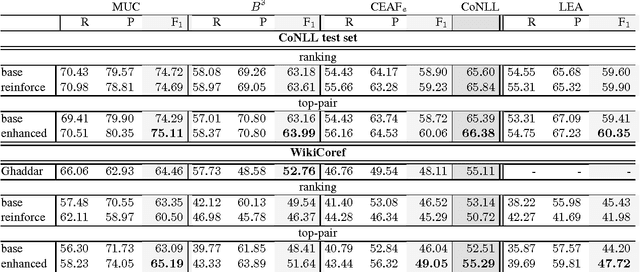
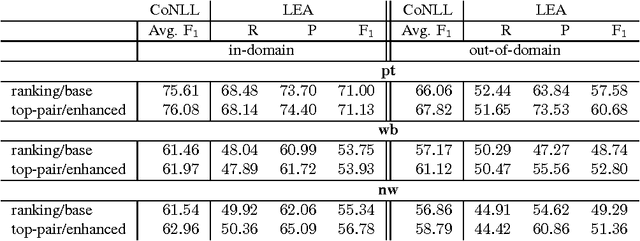
Coreference resolution is an intermediate step for text understanding. It is used in tasks and domains for which we do not necessarily have coreference annotated corpora. Therefore, generalization is of special importance for coreference resolution. However, while recent coreference resolvers have notable improvements on the CoNLL dataset, they struggle to generalize properly to new domains or datasets. In this paper, we investigate the role of linguistic features in building more generalizable coreference resolvers. We show that generalization improves only slightly by merely using a set of additional linguistic features. However, employing features and subsets of their values that are informative for coreference resolution, considerably improves generalization. Thanks to better generalization, our system achieves state-of-the-art results in out-of-domain evaluations, e.g., on WikiCoref, our system, which is trained on CoNLL, achieves on-par performance with a system designed for this dataset.
Revisiting Selectional Preferences for Coreference Resolution
Jul 20, 2017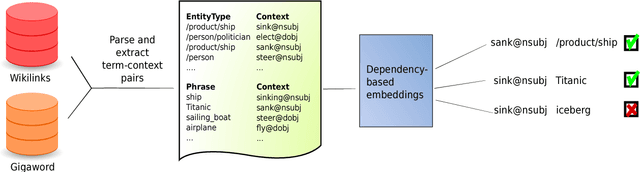
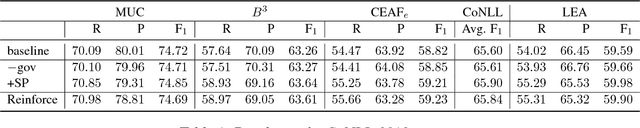
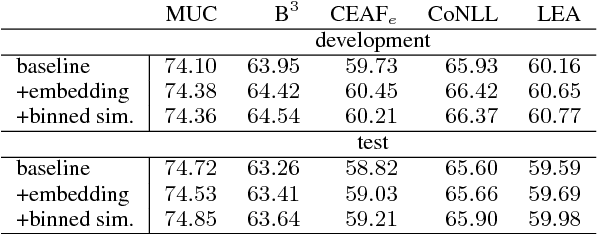
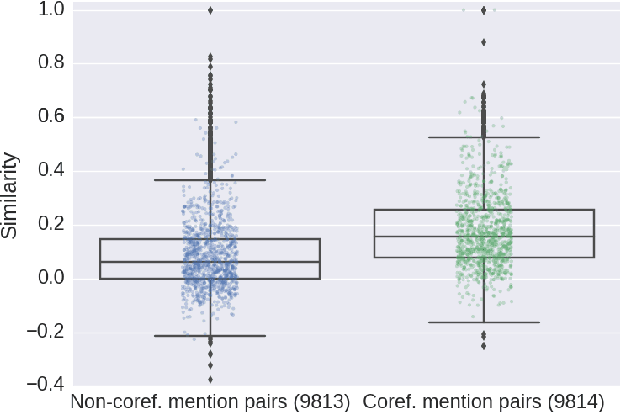
Selectional preferences have long been claimed to be essential for coreference resolution. However, they are mainly modeled only implicitly by current coreference resolvers. We propose a dependency-based embedding model of selectional preferences which allows fine-grained compatibility judgments with high coverage. We show that the incorporation of our model improves coreference resolution performance on the CoNLL dataset, matching the state-of-the-art results of a more complex system. However, it comes with a cost that makes it debatable how worthwhile such improvements are.
Lexical Features in Coreference Resolution: To be Used With Caution
Apr 22, 2017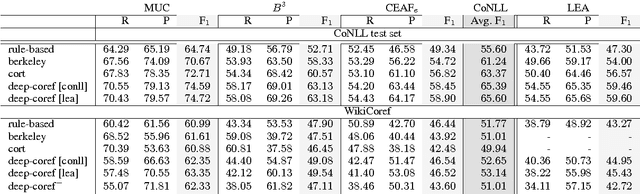

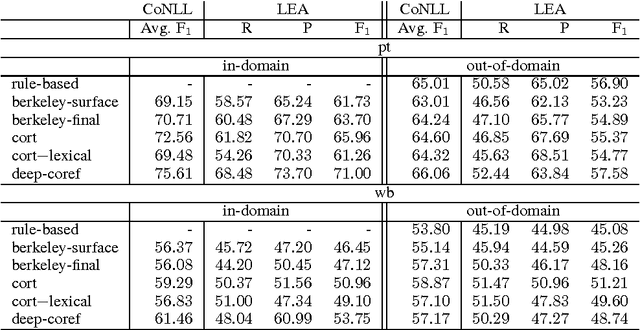

Lexical features are a major source of information in state-of-the-art coreference resolvers. Lexical features implicitly model some of the linguistic phenomena at a fine granularity level. They are especially useful for representing the context of mentions. In this paper we investigate a drawback of using many lexical features in state-of-the-art coreference resolvers. We show that if coreference resolvers mainly rely on lexical features, they can hardly generalize to unseen domains. Furthermore, we show that the current coreference resolution evaluation is clearly flawed by only evaluating on a specific split of a specific dataset in which there is a notable overlap between the training, development and test sets.
Use Generalized Representations, But Do Not Forget Surface Features
Feb 24, 2017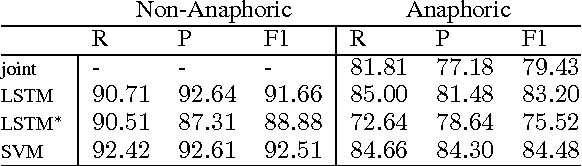
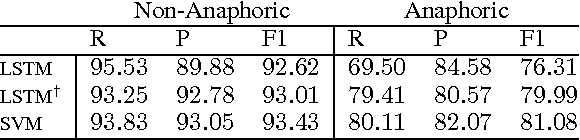
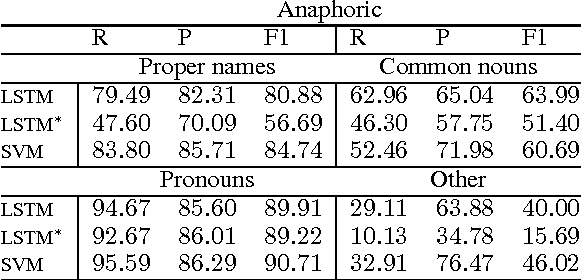
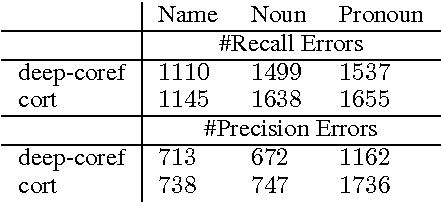
Only a year ago, all state-of-the-art coreference resolvers were using an extensive amount of surface features. Recently, there was a paradigm shift towards using word embeddings and deep neural networks, where the use of surface features is very limited. In this paper, we show that a simple SVM model with surface features outperforms more complex neural models for detecting anaphoric mentions. Our analysis suggests that using generalized representations and surface features have different strength that should be both taken into account for improving coreference resolution.