 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Low Dimensional State Spaces with Overparameterized Recurrent Neural Network
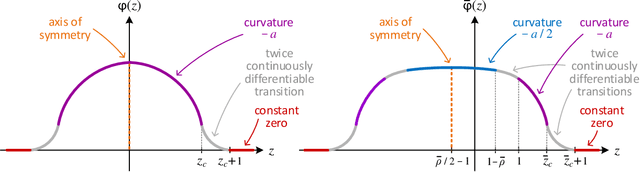
Oct 25, 2022Overparameterization in deep learning typically refers to settings where a trained Neural Network (NN) has representational capacity to fit the training data in many ways, some of which generalize well, while others do not. In the case of Recurrent Neural Networks (RNNs), there exists an additional layer of overparameterization, in the sense that a model may exhibit many solutions that generalize well for sequence lengths seen in training, some of which extrapolate to longer sequences, while others do not. Numerous works studied the tendency of Gradient Descent (GD) to fit overparameterized NNs with solutions that generalize well. On the other hand, its tendency to fit overparameterized RNNs with solutions that extrapolate has been discovered only lately, and is far less understood. In this paper, we analyze the extrapolation properties of GD when applied to overparameterized linear RNNs. In contrast to recent arguments suggesting an implicit bias towards short-term memory, we provide theoretical evidence for learning low dimensional state spaces, which can also model long-term memory. Our result relies on a dynamical characterization which shows that GD (with small step size and near-zero initialization) strives to maintain a certain form of balancedness, as well as on tools developed in the context of the moment problem from statistics (recovery of a probability distribution from its moments). Experiments corroborate our theory, demonstrating extrapolation via learning low dimensional state spaces with both linear and non-linear RNNs
Deep Linear Networks for Matrix Completion -- An Infinite Depth Limit
Oct 22, 2022



The deep linear network (DLN) is a model for implicit regularization in gradient based optimization of overparametrized learning architectures. Training the DLN corresponds to a Riemannian gradient flow, where the Riemannian metric is defined by the architecture of the network and the loss function is defined by the learning task. We extend this geometric framework, obtaining explicit expressions for the volume form, including the case when the network has infinite depth. We investigate the link between the Riemannian geometry and the training asymptotics for matrix completion with rigorous analysis and numerics. We propose that implicit regularization is a result of bias towards high state space volume.
BeamsNet: A data-driven Approach Enhancing Doppler Velocity Log Measurements for Autonomous Underwater Vehicle Navigation
Jun 27, 2022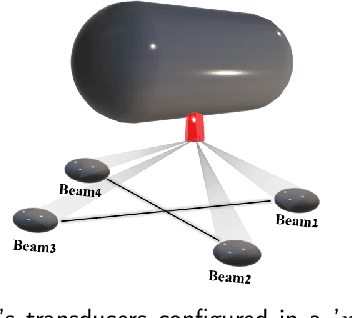
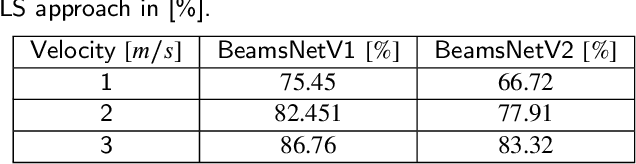
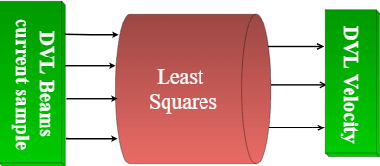

Autonomous underwater vehicles (AUV) perform various applications such as seafloor mapping and underwater structure health monitoring. Commonly, an inertial navigation system aided by a Doppler velocity log (DVL) is used to provide the vehicle's navigation solution. In such fusion, the DVL provides the velocity vector of the AUV, which determines the navigation solution's accuracy and helps estimate the navigation states. This paper proposes BeamsNet, an end-to-end deep learning framework to regress the estimated DVL velocity vector that improves the accuracy of the velocity vector estimate, and could replace the model-based approach. Two versions of BeamsNet, differing in their input to the network, are suggested. The first uses the current DVL beam measurements and inertial sensors data, while the other utilizes only DVL data, taking the current and past DVL measurements for the regression process. Both simulation and sea experiments were made to validate the proposed learning approach relative to the model-based approach. Sea experiments were made with the Snapir AUV in the Mediterranean Sea, collecting approximately four hours of DVL and inertial sensor data. Our results show that the proposed approach achieved an improvement of more than 60% in estimating the DVL velocity vector.
Semantic Segmentation in Art Paintings
Mar 07, 2022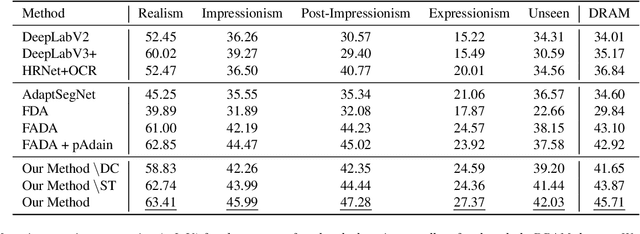
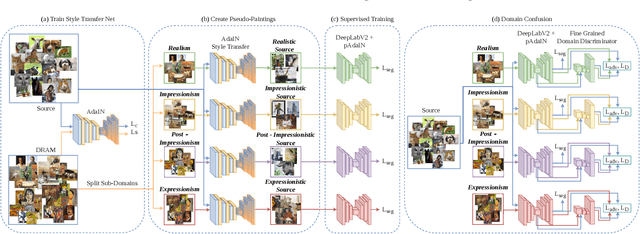
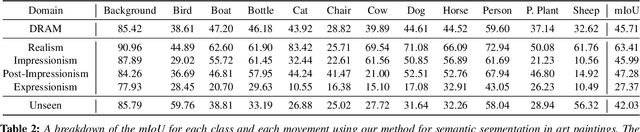
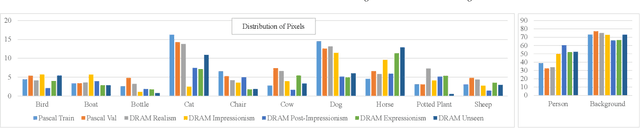
Semantic segmentation is a difficult task even when trained in a supervised manner on photographs. In this paper, we tackle the problem of semantic segmentation of artistic paintings, an even more challenging task because of a much larger diversity in colors, textures, and shapes and because there are no ground truth annotations available for segmentation. We propose an unsupervised method for semantic segmentation of paintings using domain adaptation. Our approach creates a training set of pseudo-paintings in specific artistic styles by using style-transfer on the PASCAL VOC 2012 dataset, and then applies domain confusion between PASCAL VOC 2012 and real paintings. These two steps build on a new dataset we gathered called DRAM (Diverse Realism in Art Movements) composed of figurative art paintings from four movements, which are highly diverse in pattern, color, and geometry. To segment new paintings, we present a composite multi-domain adaptation method that trains on each sub-domain separately and composes their solutions during inference time. Our method provides better segmentation results not only on the specific artistic movements of DRAM, but also on other, unseen ones. We compare our approach to alternative methods and show applications of semantic segmentation in art paintings. The code and models for our approach are publicly available at: https://github.com/Nadavc220/SemanticSegmentationInArtPaintings.
On the Implicit Bias of Gradient Descent for Temporal Extrapolation
Feb 09, 2022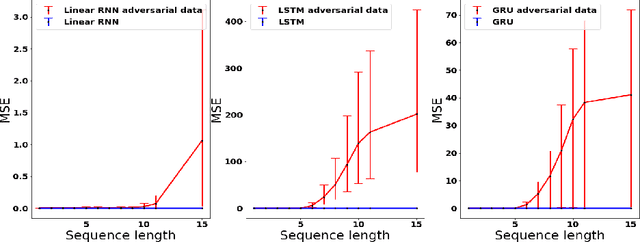
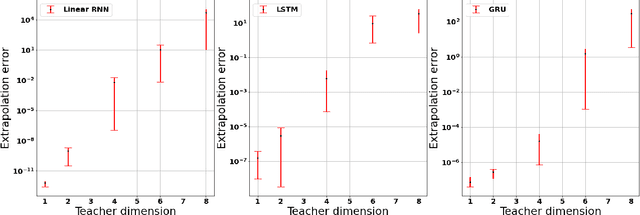
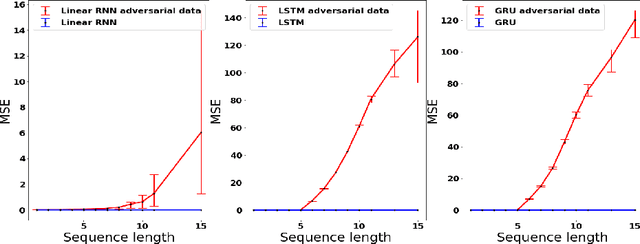
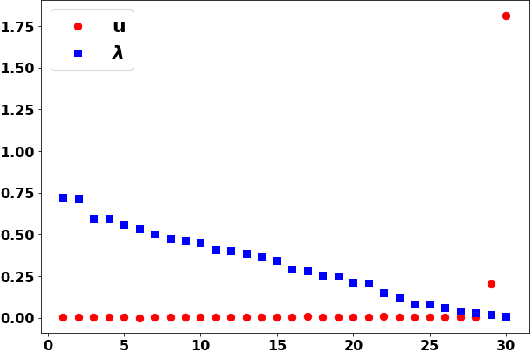
Common practice when using recurrent neural networks (RNNs) is to apply a model to sequences longer than those seen in training. This "extrapolating" usage deviates from the traditional statistical learning setup where guarantees are provided under the assumption that train and test distributions are identical. Here we set out to understand when RNNs can extrapolate, focusing on a simple case where the data generating distribution is memoryless. We first show that even with infinite training data, there exist RNN models that interpolate perfectly (i.e., they fit the training data) yet extrapolate poorly to longer sequences. We then show that if gradient descent is used for training, learning will converge to perfect extrapolation under certain assumption on initialization. Our results complement recent studies on the implicit bias of gradient descent, showing that it plays a key role in extrapolation when learning temporal prediction models.
Implicit Regularization in Hierarchical Tensor Factorization and Deep Convolutional Neural Networks
Jan 27, 2022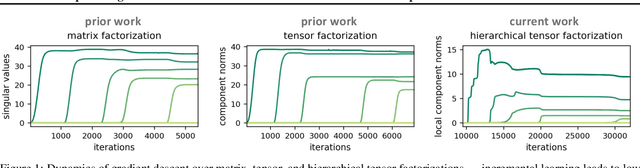
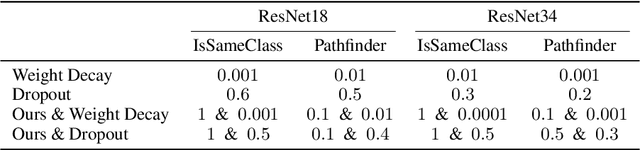
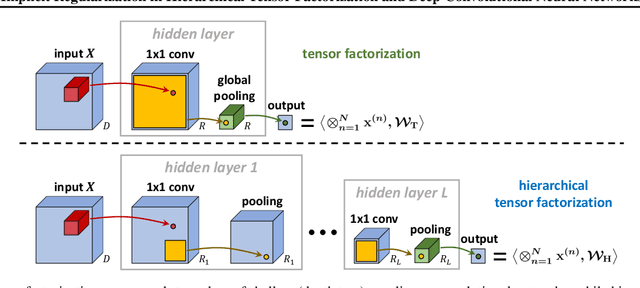
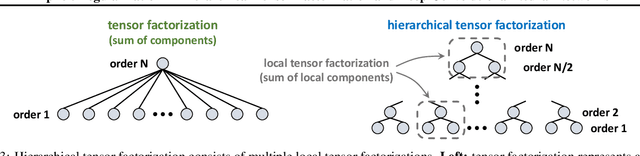
In the pursuit of explaining implicit regularization in deep learning, prominent focus was given to matrix and tensor factorizations, which correspond to simplified neural networks. It was shown that these models exhibit implicit regularization towards low matrix and tensor ranks, respectively. Drawing closer to practical deep learning, the current paper theoretically analyzes the implicit regularization in hierarchical tensor factorization, a model equivalent to certain deep convolutional neural networks. Through a dynamical systems lens, we overcome challenges associated with hierarchy, and establish implicit regularization towards low hierarchical tensor rank. This translates to an implicit regularization towards locality for the associated convolutional networks. Inspired by our theory, we design explicit regularization discouraging locality, and demonstrate its ability to improve performance of modern convolutional networks on non-local tasks, in defiance of conventional wisdom by which architectural changes are needed. Our work highlights the potential of enhancing neural networks via theoretical analysis of their implicit regularization.
Continuous vs. Discrete Optimization of Deep Neural Networks
Jul 14, 2021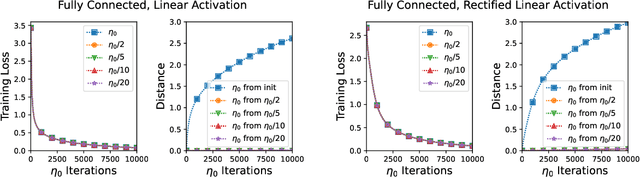
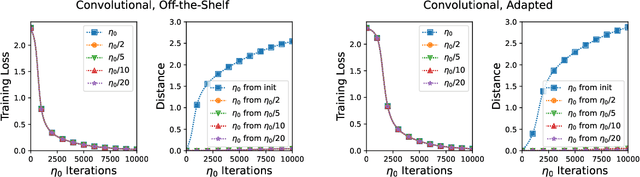
Existing analyses of optimization in deep learning are either continuous, focusing on (variants of) gradient flow, or discrete, directly treating (variants of) gradient descent. Gradient flow is amenable to theoretical analysis, but is stylized and disregards computational efficiency. The extent to which it represents gradient descent is an open question in deep learning theory. The current paper studies this question. Viewing gradient descent as an approximate numerical solution to the initial value problem of gradient flow, we find that the degree of approximation depends on the curvature along the latter's trajectory. We then show that over deep neural networks with homogeneous activations, gradient flow trajectories enjoy favorable curvature, suggesting they are well approximated by gradient descent. This finding allows us to translate an analysis of gradient flow over deep linear neural networks into a guarantee that gradient descent efficiently converges to global minimum almost surely under random initialization. Experiments suggest that over simple deep neural networks, gradient descent with conventional step size is indeed close to the continuous limit. We hypothesize that the theory of gradient flows will be central to unraveling mysteries behind deep learning.
Implicit Regularization in Tensor Factorization
Feb 26, 2021

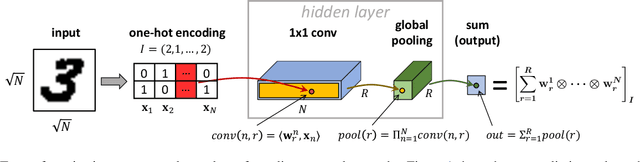

Implicit regularization in deep learning is perceived as a tendency of gradient-based optimization to fit training data with predictors of minimal "complexity." The fact that only some types of data give rise to generalization is understood to result from them being especially amenable to fitting with low complexity predictors. A major challenge in formalizing this intuition is to define complexity measures that are quantitative yet capture the essence of data that admits generalization. With an eye towards this challenge, we provide the first analysis of implicit regularization in tensor factorization, equivalent to a certain non-linear neural network. We characterize the dynamics that gradient descent induces on the factorization, and establish a bias towards low tensor rank, in compliance with empirical evidence. Then, motivated by tensor rank capturing implicit regularization of a non-linear neural network, we empirically explore it as a measure of complexity, and find that it stays extremely low when fitting standard datasets. This leads us to believe that tensor rank may pave way to explaining both implicit regularization of neural networks, and the properties of real-world data translating this implicit regularization to generalization.
Implicit Regularization in Deep Learning May Not Be Explainable by Norms
May 13, 2020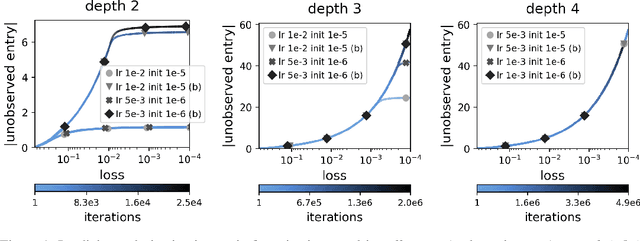
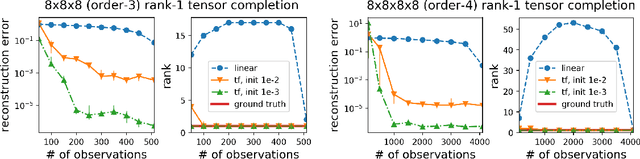
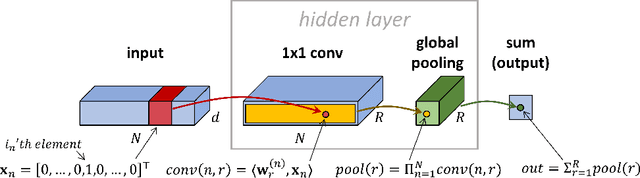
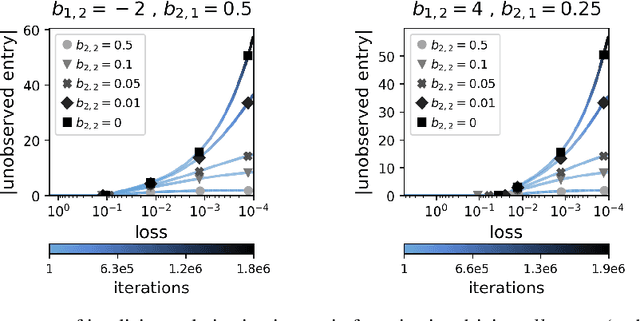
Mathematically characterizing the implicit regularization induced by gradient-based optimization is a longstanding pursuit in the theory of deep learning. A widespread hope is that a characterization based on minimization of norms may apply, and a standard test-bed for studying this prospect is matrix factorization (matrix completion via linear neural networks). It is an open question whether norms can explain the implicit regularization in matrix factorization. The current paper resolves this open question in the negative, by proving that there exist natural matrix factorization problems on which the implicit regularization drives all norms (and quasi-norms) towards infinity. Our results suggest that, rather than perceiving the implicit regularization via norms, a potentially more useful interpretation is minimization of rank. We demonstrate empirically that this interpretation extends to a certain class of non-linear neural networks, and hypothesize that it may be key to explaining generalization in deep learning.
Implicit Regularization in Deep Matrix Factorization
Jun 04, 2019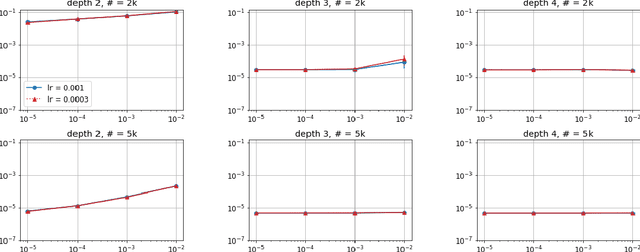
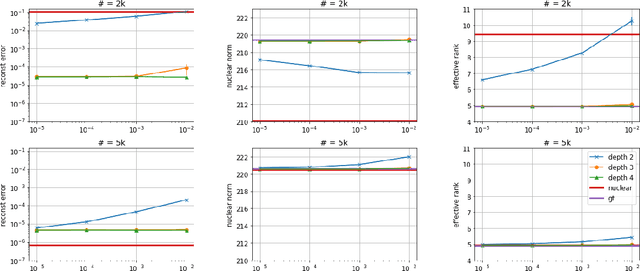
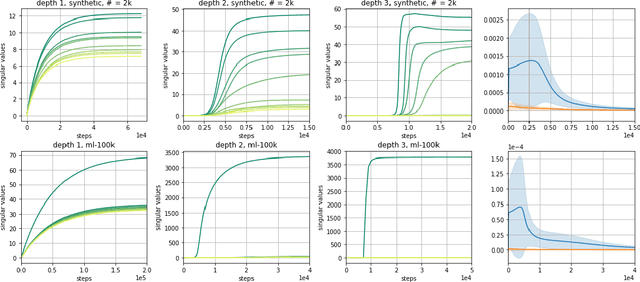
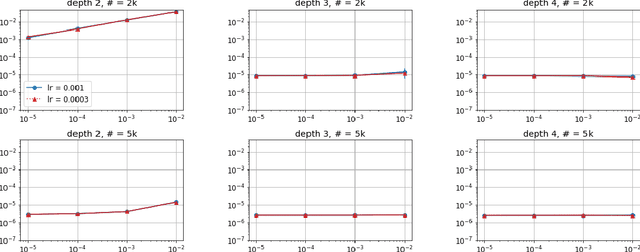
Efforts to understand the generalization mystery in deep learning have led to the belief that gradient-based optimization induces a form of implicit regularization, a bias towards models of low "complexity." We study the implicit regularization of gradient descent over deep linear neural networks for matrix completion and sensing, a model referred to as deep matrix factorization. Our first finding, supported by theory and experiments, is that adding depth to a matrix factorization enhances an implicit tendency towards low-rank solutions, oftentimes leading to more accurate recovery. Secondly, we present theoretical and empirical arguments questioning a nascent view by which implicit regularization in matrix factorization can be captured using simple mathematical norms. Our results point to the possibility that the language of standard regularizers may not be rich enough to fully encompass the implicit regularization brought forth by gradient-based optimization.